Bài đăng trên blog này là phần tiếp theo của phần 1 trước đó, nơi chúng tôi đã trình bày những kiến thức cơ bản về tích hợp SNMP với ClusterControl.
Trong bài đăng trên blog này, chúng tôi sẽ tập trung vào các bẫy và cảnh báo SNMP. Bẫy SNMP là các thông báo cảnh báo được sử dụng thường xuyên nhất được gửi từ thiết bị hỗ trợ SNMP từ xa (một tác nhân) đến bộ thu tập trung, “trình quản lý SNMP”. Trong trường hợp của ClusterControl, một cái bẫy có thể là một cảnh báo sau khi cảnh báo quan trọng cho một cụm không phải là 0, cho thấy điều gì đó tồi tệ đang xảy ra.
Như được hiển thị trong bài đăng trên blog trước, với mục đích là bằng chứng về khái niệm này, chúng tôi có hai định nghĩa thông báo bẫy SNMP:
criticalAlarmNotification NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification if critical alarm is not 0"
::= { alarmNotification 1 }
criticalAlarmNotificationEnded NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification ended - Critical alarm is 0"
::= { alarmNotification 2 }Các thông báo (hoặc bẫy) là quan trọngAlarmNotification và quan trọngAlarmNotificationEnded. Cả hai sự kiện thông báo đều có thể được sử dụng để báo hiệu dịch vụ Nagios của chúng tôi, cho dù cụm có đang chủ động có các cảnh báo quan trọng hay không. Trong Nagios, thuật ngữ cho điều này là kiểm tra thụ động, theo đó Nagios không cố gắng xác định xem hoặc máy chủ / dịch vụ là DOWN hay UNREACHABLE. Chúng tôi cũng sẽ định cấu hình các kiểm tra đang hoạt động, trong đó các kiểm tra được bắt đầu bởi logic kiểm tra trong daemon Nagios bằng cách sử dụng định nghĩa dịch vụ để cũng giám sát các cảnh báo quan trọng / cảnh báo do cụm của chúng tôi báo cáo.
Lưu ý rằng bài đăng trên blog này yêu cầu tác nhân Somenines MIB và SNMP được định cấu hình chính xác như được hiển thị trong phần đầu tiên của loạt bài blog này.
Cài đặt Nagios Core
Nagios Core là phiên bản miễn phí của bộ giám sát Nagios. Đầu tiên và quan trọng nhất, chúng ta phải cài đặt nó và tất cả các gói cần thiết, tiếp theo là các plugin Nagios, snmptrapd và snmptt. Lưu ý rằng hướng dẫn trong bài đăng trên blog này giả định rằng tất cả các nút đang chạy trên CentOS 7.
Cài đặt các gói cần thiết để chạy Nagios:
$ yum -y install httpd php gcc glibc glibc-common wget perl gd gd-devel unzip zip sendmail net-snmp-utils net-snmp-perlTạo người dùng nagios và nhóm nagcmd để cho phép thực thi các lệnh bên ngoài thông qua giao diện web, thêm người dùng nagios và apache để trở thành một phần của nhóm nagcmd:
$ useradd nagios
$ groupadd nagcmd
$ usermod -a -G nagcmd nagios
$ usermod -a -G nagcmd apacheTải xuống phiên bản mới nhất của Nagios Core từ đây, biên dịch và cài đặt nó:
$ cd ~
$ wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.6.tar.gz
$ tar -zxvf nagios-4.4.6.tar.gz
$ cd nagios-4.4.6
$ ./configure --with-nagios-group=nagios --with-command-group=nagcmd
$ make all
$ make install
$ make install-init
$ make install-config
$ make install-commandmodeCài đặt cấu hình web Nagios:
$ make install-webconfTùy chọn cài đặt chủ đề tẩy da chết Nagios (hoặc bạn có thể sử dụng chủ đề mặc định):
$ make install-exfoliationTạo tài khoản người dùng (nagiosadmin) để đăng nhập vào giao diện web Nagios. Hãy nhớ mật khẩu mà bạn chỉ định cho người dùng này:
$ htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminKhởi động lại máy chủ web Apache để cài đặt mới có hiệu lực:
$ systemctl restart httpd
$ systemctl enable httpdTải xuống Plugin Nagios từ đây, biên dịch và cài đặt nó:
$ cd ~
$ wget https://nagios-plugins.org/download/nagios-plugins-2.3.3.tar.gz
$ tar -zxvf nagios-plugins-2.3.3.tar.gz
$ cd nagios-plugins-2.3.3
$ ./configure --with-nagios-user=nagios --with-nagios-group=nagios
$ make
$ make installXác minh tệp cấu hình Nagios mặc định:
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
Nagios Core 4.4.6
Copyright (c) 2009-present Nagios Core Development Team and Community Contributors
Copyright (c) 1999-2009 Ethan Galstad
Last Modified: 2020-04-28
License: GPL
Website: https://www.nagios.org
Reading configuration data...
Read main config file okay...
Read object config files okay...
Running pre-flight check on configuration data...
Checking objects...
Checked 8 services.
Checked 1 hosts.
Checked 1 host groups.
Checked 0 service groups.
Checked 1 contacts.
Checked 1 contact groups.
Checked 24 commands.
Checked 5 time periods.
Checked 0 host escalations.
Checked 0 service escalations.
Checking for circular paths...
Checked 1 hosts
Checked 0 service dependencies
Checked 0 host dependencies
Checked 5 timeperiods
Checking global event handlers...
Checking obsessive compulsive processor commands...
Checking misc settings...
Total Warnings: 0
Total Errors: 0
Things look okay - No serious problems were detected during the pre-flight check
If everything looks okay, start Nagios and configure it to start on boot:
$ systemctl start nagios
$ systemctl enable nagiosMở trình duyệt và truy cập https:// {IPaddress} / nagios và bạn sẽ thấy xác thực cơ bản HTTP bật lên, nơi bạn cần chỉ định tên người dùng là nagiosadmin với mật khẩu bạn đã chọn đã tạo trước đó.
Thêm máy chủ ClusterControl vào Nagios
Tạo tệp định nghĩa máy chủ Nagios cho ClusterControl:
$ vim /usr/local/nagios/etc/objects/clustercontrol.cfgVà thêm các dòng sau:
define host {
use linux-server
host_name clustercontrol.local
alias clustercontrol.mydomain.org
address 192.168.10.50
}
define service {
use generic-service
host_name clustercontrol.local
service_description Critical alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.2 -c0
}
define service {
use generic-service
host_name clustercontrol.local
service_description Warning alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.3 -w0
}
define service {
use snmp_trap_template
host_name clustercontrol.local
service_description Critical alarm traps
check_interval 60 ; Don't clear for 1 hour
}
Một số giải thích:
-
Trong phần đầu tiên, chúng tôi xác định máy chủ của mình, với tên máy chủ và địa chỉ của máy chủ ClusterControl.
-
Các phần dịch vụ mà chúng tôi đặt các định nghĩa dịch vụ của mình sẽ được Nagios giám sát. Hai cách đầu tiên về cơ bản là yêu cầu dịch vụ kiểm tra đầu ra SNMP cho một ID đối tượng cụ thể. Dịch vụ đầu tiên là về cảnh báo quan trọng, do đó chúng tôi thêm -c0 trong lệnh check_snmp để chỉ ra rằng đó phải là một cảnh báo quan trọng trong Nagios nếu giá trị vượt quá 0. Trong khi đối với các cảnh báo cảnh báo, chúng tôi sẽ chỉ ra nó bằng một cảnh báo nếu giá trị là 1 và cao hơn.
-
Định nghĩa dịch vụ cuối cùng là về các bẫy SNMP mà chúng tôi mong đợi đến từ máy chủ ClusterControl nếu báo động nghiêm trọng cao hơn 0. Phần này sẽ sử dụng định nghĩa snmp_trap_template, như được hiển thị trong bước tiếp theo.
Định cấu hình snmp_trap_template bằng cách thêm các dòng sau vào /usr/local/nagios/etc/objects/templates.cfg:
define service {
name snmp_trap_template
service_description SNMP Trap Template
active_checks_enabled 1 ; Active service checks are enabled
passive_checks_enabled 1 ; Passive service checks are enabled/accepted
parallelize_check 1 ; Active service checks should be parallelized
process_perf_data 0
obsess_over_service 0 ; We should obsess over this service (if necessary)
check_freshness 0 ; Default is to NOT check service 'freshness'
notifications_enabled 1 ; Service notifications are enabled
event_handler_enabled 1 ; Service event handler is enabled
flap_detection_enabled 1 ; Flap detection is enabled
process_perf_data 1 ; Process performance data
retain_status_information 1 ; Retain status information across program restarts
retain_nonstatus_information 1 ; Retain non-status information across program restarts
check_command check-host-alive ; This will be used to reset the service to "OK"
is_volatile 1
check_period 24x7
max_check_attempts 1
normal_check_interval 1
retry_check_interval 1
notification_interval 60
notification_period 24x7
notification_options w,u,c,r
contact_groups admins ; Modify this to match your Nagios contactgroup definitions
register 0
}
Bao gồm tệp cấu hình ClusterControl vào Nagios, bằng cách thêm dòng sau vào bên trong
/usr/local/nagios/etc/nagios.cfg:
cfg_file=/usr/local/nagios/etc/objects/clustercontrol.cfgChạy kiểm tra cấu hình trước chuyến bay:
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgĐảm bảo rằng bạn nhận được dòng sau ở cuối đầu ra:
"Things look okay - No serious problems were detected during the pre-flight check"Khởi động lại Nagios để tải thay đổi:
$ systemctl restart nagiosBây giờ, nếu chúng ta nhìn vào trang Nagios trong phần Dịch vụ (menu bên trái), chúng ta sẽ thấy một cái gì đó như thế này:
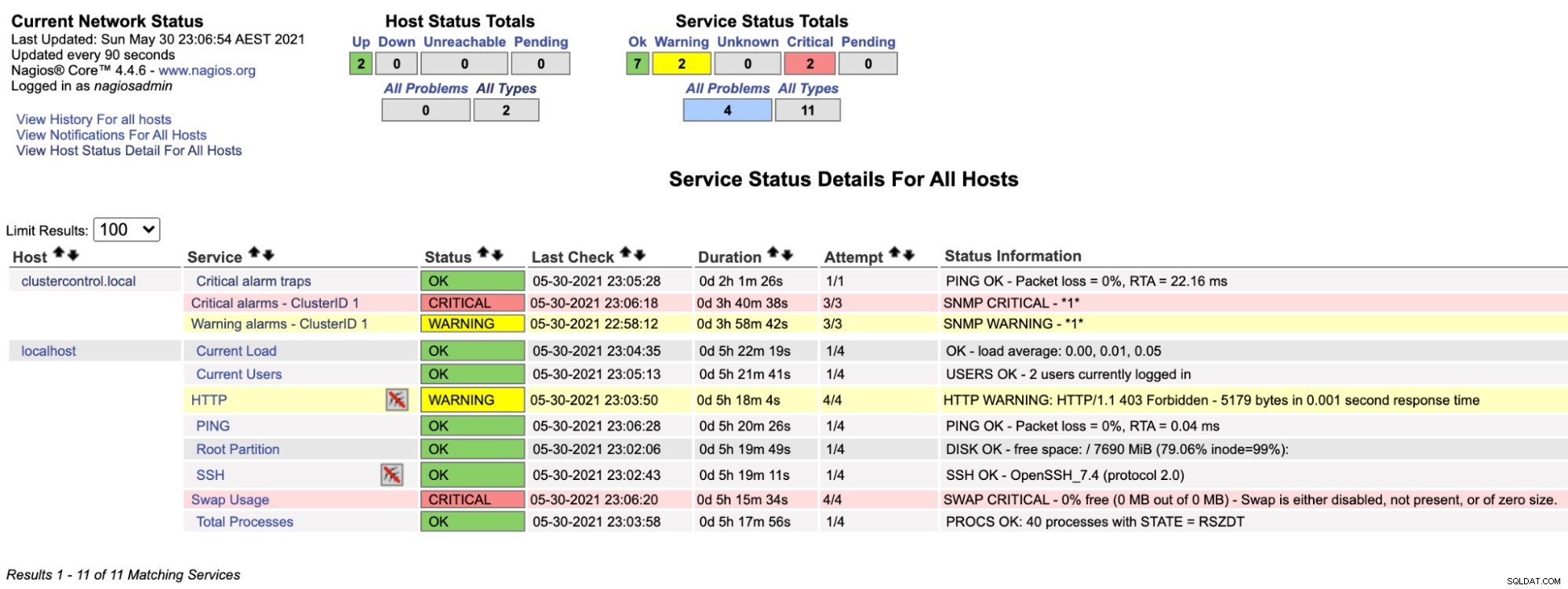
Lưu ý hàng "Cảnh báo tới hạn - ClusterID 1" chuyển sang màu đỏ nếu giá trị cảnh báo tới hạn được ClusterControl báo cáo lớn hơn 0, trong khi "Cảnh báo tới hạn - ClusterID 1" có màu vàng, cho biết rằng có một cảnh báo đã được nâng lên. Trong trường hợp không có gì thú vị xảy ra, bạn sẽ thấy mọi thứ đều có màu xanh lục cho clustercontrol.local.
Định cấu hình Nagios để nhận bẫy
Bẫy được thiết bị từ xa gửi đến máy chủ Nagios, đây được gọi là kiểm tra thụ động. Tốt nhất, chúng tôi không biết khi nào một cái bẫy sẽ được gửi đi vì nó phụ thuộc vào thiết bị gửi quyết định nó sẽ gửi một cái bẫy. Ví dụ với bộ lưu điện (acquy dự phòng), ngay khi thiết bị mất điện, nó sẽ phát ra một cái bẫy để nói rằng “hey, I’m lost power”. Bằng cách này, Nagios được thông báo ngay lập tức.
Để nhận được các bẫy SNMP, chúng ta cần định cấu hình máy chủ Nagios với những điều sau:
-
snmptrapd (daemon thu bẫy SNMP)
-
snmptt (SNMP Trap Translator, trình nền xử lý bẫy)
Sau khi snmptrapd nhận được một cái bẫy, nó sẽ chuyển nó đến snmptt, nơi chúng tôi sẽ cấu hình nó để cập nhật hệ thống Nagios và sau đó Nagios sẽ gửi cảnh báo theo cấu hình nhóm liên hệ.
Cài đặt kho lưu trữ EPEL, theo sau là các gói cần thiết:
$ yum -y install epel-release
$ yum -y install net-snmp snmptt net-snmp-perl perl-Sys-SyslogĐịnh cấu hình daemon bẫy SNMP tại /etc/snmp/snmptrapd.conf và đặt các dòng sau:
disableAuthorization yes
traphandle default /usr/sbin/snmptthandlerỞ trên chỉ đơn giản là các bẫy mà daemon snmptrapd nhận được sẽ được chuyển cho / usr / sbin / snmptthandler.
Thêm SEVERALNINES-CLUSTERCONTROL-MIB.txt vào / usr / share / snmp / mibs bằng cách tạo /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt:
$ ll /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt
-rw-r--r-- 1 root root 4029 May 30 20:08 /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txtTạo /etc/snmp/snmp.conf (thông báo không có "d") và thêm MIB tùy chỉnh của chúng tôi vào đó:
mibs +SEVERALNINES-CLUSTERCONTROL-MIBBắt đầu dịch vụ snmptrapd:
$ systemctl start snmptrapd
$ systemctl enable snmptrapdTiếp theo, chúng ta cần cấu hình các dòng cấu hình sau bên trong /etc/snmp/snmptt.ini:
net_snmp_perl_enable = 1
snmptt_conf_files = <<END
/etc/snmp/snmptt.conf
/etc/snmp/snmptt-cc.conf
ENDLưu ý rằng chúng tôi đã bật mô-đun net_snmp_perl và đã thêm một đường dẫn cấu hình khác, /etc/snmp/snmptt-cc.conf bên trong snmptt.ini. Chúng ta cần xác định các sự kiện ClusterControl snmptt ở đây để chúng có thể được chuyển tới Nagios. Tạo một tệp mới tại /etc/snmp/snmptt-cc.conf và thêm các dòng sau:
MIB: SEVERALNINES-CLUSTERCONTROL-MIB (file:/usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt) converted on Sun May 30 19:17:33 2021 using snmpttconvertmib v1.4.2
EVENT criticalAlarmNotification .1.3.6.1.4.1.57397.1.1.3.1 "Status Events" Critical
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 2 "Critical - Critical alarm is $1 for cluster ID $2"
SDESC
Notification if critical alarm is not 0
Variables:
1: totalCritical
2: clusterId
EDESC
EVENT criticalAlarmNotificationEnded .1.3.6.1.4.1.57397.1.1.3.2 "Status Events" Normal
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 0 "Normal - Critical alarm is $1 for cluster ID $2"
SDESC
Notification ended - critical alarm is 0
Variables:
1: totalCritical
2: clusterId
EDESCMột số giải thích:
-
Chúng tôi đã xác định hai bẫy - criticalAlarmNotification và criticalAlarmNotificationEnded.
-
CriticAlarmNotification chỉ cần đưa ra một cảnh báo quan trọng và chuyển nó đến dịch vụ "Bẫy báo động nghiêm trọng" được xác định trong Nagios. $ AA có nghĩa là trả về địa chỉ IP của tác nhân bẫy. Giá trị 2 là giá trị kết quả kiểm tra mà trong trường hợp này là quan trọng (0 =OK, 1 =WARNING, 2 =CRITICAL, 3 =UNKNOWN).
-
CriticAlarmNotificationEnded chỉ cần tăng một cảnh báo OK và chuyển nó đến dịch vụ "Bẫy báo động nghiêm trọng", để hủy bẫy trước sau khi mọi thứ trở lại bình thường. $ AA có nghĩa là trả về địa chỉ IP của tác nhân bẫy. Giá trị 0 là giá trị kết quả kiểm tra, trong trường hợp này là OK. Để biết thêm chi tiết về các thay thế chuỗi được snmptt công nhận, hãy xem bài viết này trong phần "ĐỊNH DẠNG".
-
Bạn có thể sử dụng snmpttconvertmib để tạo tệp xử lý sự kiện snmptt cho MIB cụ thể.
Lưu ý rằng theo mặc định, đường dẫn bộ xử lý sự kiện không được cung cấp bởi Nagios Core. Do đó, chúng tôi phải sao chép thư mục bộ xử lý sự kiện đó từ nguồn Nagios trong thư mục đóng góp, như được hiển thị bên dưới:
$ cp -Rf nagios-4.4.6/contrib/eventhandlers /usr/local/nagios/share/
$ chown -Rf nagios:nagios /usr/local/nagios/share/eventhandlersChúng tôi cũng cần chỉ định nhóm snmptt như một phần của nhóm nagcmd, để nó có thể thực thi nagios.cmd bên trong tập lệnh submit_check_result:
$ usermod -a -G nagcmd snmpttBắt đầu dịch vụ snmptt:
$ systemctl start snmptt
$ systemctl enable snmpttTrình quản lý SNMP (máy chủ Nagios) hiện đã sẵn sàng chấp nhận và xử lý các bẫy SNMP đến của chúng tôi.
Gửi bẫy từ máy chủ ClusterControl
Giả sử một người muốn gửi một bẫy SNMP đến trình quản lý SNMP, 192.168.10.11 (máy chủ Nagios) vì tổng số cảnh báo quan trọng đã đạt đến 2 đối với ID cụm 1, người ta sẽ chạy lệnh sau trên máy chủ ClusterControl (phía máy khách), 192.168.10.50:
$ snmptrap -v2c -c private 192.168.10.11 '' SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification \
SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical i 2 \
SEVERALNINES-CLUSTERCONTROL-MIB::clusterId i 1Hoặc, ở định dạng OID (được khuyến nghị):
$ snmptrap -v2c -c private 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.1 \
.1.3.6.1.4.1.57397.1.1.1.2 i 2 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Trong đó, .1.3.6.1.4.1.57397.1.1.3.1 tương ứng với sự kiện bẫy criticalAlarmNotification và các OID tiếp theo là đại diện của tổng số cảnh báo quan trọng hiện tại và ID cụm, tương ứng .
Trên máy chủ Nagios, bạn sẽ thấy dịch vụ bẫy đã chuyển sang màu đỏ:
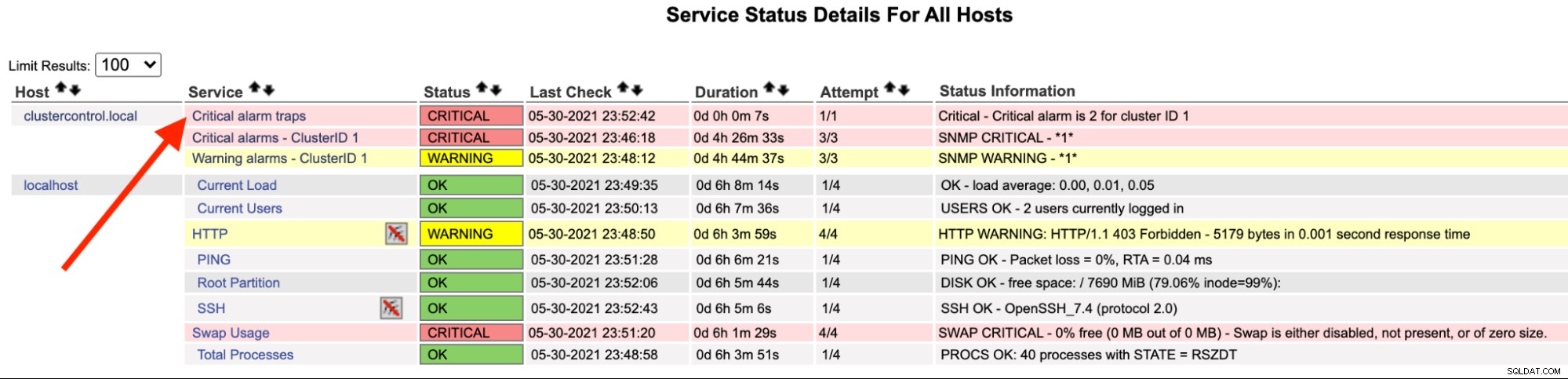
Bạn cũng có thể thấy nó trong / var / log / messages của dòng sau:
May 30 23:52:39 ip-10-15-2-148 snmptrapd[27080]: 2021-05-30 23:52:39 UDP: [192.168.10.50]:33151->[192.168.10.11]:162 [UDP: [192.168.10.50]:33151->[192.168.10.11]:162]:#012DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (2423020) 6:43:50.20#011SNMPv2-MIB::snmpTrapOID.0 = OID: SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification#011SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical = INTEGER: 2#011SEVERALNINES-CLUSTERCONTROL-MIB::clusterId = INTEGER: 1
May 30 23:52:42 nagios.local snmptt[29557]: .1.3.6.1.4.1.57397.1.1.3.1 Critical "Status Events" UDP192.168.10.5033151-192.168.10.11162 - Notification if critical alarm is not 0
May 30 23:52:42 nagios.local nagios: EXTERNAL COMMAND: PROCESS_SERVICE_CHECK_RESULT;192.168.10.50;Critical alarm traps;2;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: PASSIVE SERVICE CHECK: clustercontrol.local;Critical alarm traps;0;PING OK - Packet loss = 0%, RTA = 22.16 ms
May 30 23:52:42 nagios.local nagios: SERVICE NOTIFICATION: nagiosadmin;clustercontrol.local;Critical alarm traps;CRITICAL;notify-service-by-email;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: SERVICE ALERT: clustercontrol.local;Critical alarm traps;CRITICAL;HARD;1;Critical - Critical alarm is 2 for cluster ID 1Khi cảnh báo đã được giải quyết, để gửi một bẫy bình thường, chúng tôi có thể thực hiện lệnh sau:
$ snmptrap -c private -v2c 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.2 \
.1.3.6.1.4.1.57397.1.1.1.2 i 0 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Trong đó, .1.3.6.1.4.1.57397.1.1.3.2 bằng với sự kiện criticalAlarmNotificationEnded và các OID tiếp theo là đại diện cho tổng số các cảnh báo quan trọng hiện tại (phải là 0 cho trường hợp này ) và ID cụm, tương ứng.
Trên máy chủ Nagios, bạn sẽ thấy dịch vụ bẫy trở lại màu xanh lục:
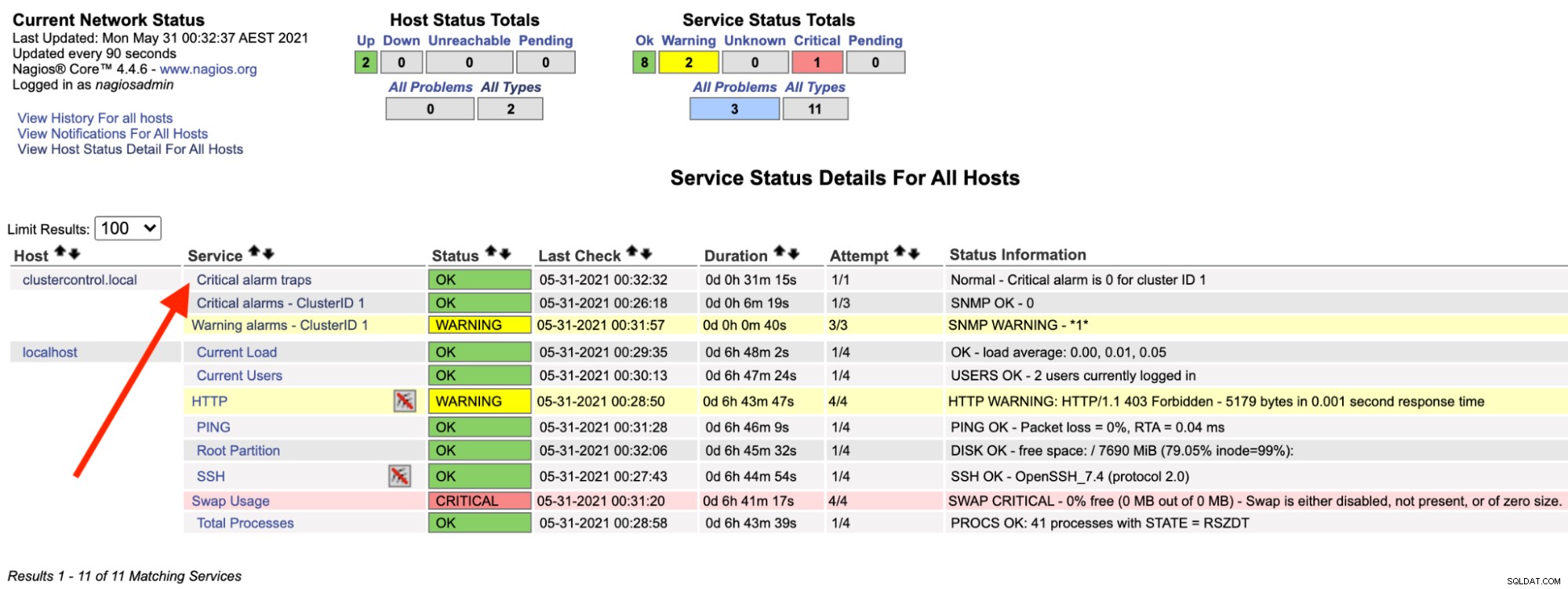
Phần trên có thể được tự động hóa bằng một tập lệnh bash đơn giản:
#!/bin/bash
# alarmtrapper.bash - SNMP trapper for ClusterControl alarms
CLUSTER_ID=1
SNMP_MANAGER=192.168.10.11
INTERVAL=10
send_critical_snmp_trap() {
# send critical trap
local val=$1
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.1 .1.3.6.1.4.1.57397.1.1.1.1 i ${val} .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
send_zero_critical_snmp_trap() {
# send OK trap
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.2 .1.3.6.1.4.1.57397.1.1.1.1 i 0 .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
while true; do
count=$(s9s alarm --list --long --cluster-id=${CLUSTER_ID} --batch | grep CRITICAL | wc -l)
[ $count -ne 0 ] && send_critical_snmp_trap $count || send_zero_critical_snmp_trap
sleep $INTERVAL
doneĐể chạy tập lệnh trong nền, chỉ cần thực hiện:
$ bash alarmtrapper.bash &Tại thời điểm này, chúng tôi sẽ có thể thấy dịch vụ "Bẫy báo động nghiêm trọng" của Nagios đang hoạt động nếu có lỗi trong cụm của chúng tôi tự động.
Lời kết
Trong loạt bài blog này, chúng tôi đã giới thiệu khái niệm bằng chứng về cách ClusterControl có thể được định cấu hình để giám sát, tạo / xử lý bẫy và cảnh báo bằng giao thức SNMP. Điều này cũng đánh dấu sự khởi đầu của hành trình kết hợp SNMP trong các bản phát hành trong tương lai của chúng tôi. Hãy theo dõi vì chúng tôi sẽ cập nhật thêm về tính năng thú vị này.



