Nhiều THAM GIA trong một truy vấn duy nhất
Nhiều THAM GIA thường được liên kết với nhiều bộ sưu tập, nhưng bạn phải có hiểu biết cơ bản về cách thức hoạt động của INNER JOIN (xem các bài viết trước của tôi về chủ đề này). Ngoài hai bộ sưu tập của chúng tôi mà chúng tôi đã có trước đây; đơn vị và sinh viên, hãy thêm bộ sưu tập thứ ba và gắn nhãn thể thao. Điền vào bộ sưu tập thể thao với dữ liệu bên dưới:
{
"_id" : 1,"tournamentsPlayed" : 6,
"gamesParticipated" : [{"hockey" : "midfielder","football" : "stricker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge","South Africa", "Rio Brazil"]
}
{
"_id" : 2,"tournamentsPlayed" : 3,
"gamesParticipated" : [{"hockey" : "goalkeeper","football" : "stricker", "handball" : "midfielder"}],
"sportPlaces" : ["Ukraine","India", "Argentina"]
}
{
"_id" : 3,"tournamentsPlayed" : 10,
"gamesParticipated" : [{"hockey" : "stricker","football" : "goalkeeper","tabletennis" : "doublePlayer"}],
"sportPlaces" : ["China","Korea","France"]
}Ví dụ:chúng tôi muốn trả về tất cả dữ liệu cho một sinh viên có giá trị trường _id bằng 1. Thông thường, chúng tôi sẽ viết một truy vấn để tìm nạp giá trị trường _id từ tập hợp sinh viên, sau đó sử dụng giá trị trả về để truy vấn dữ liệu trong hai bộ sưu tập khác. Do đó, đây sẽ không phải là lựa chọn tốt nhất, đặc biệt nếu liên quan đến một bộ tài liệu lớn. Một cách tiếp cận tốt hơn sẽ là sử dụng tính năng SQL của chương trình Studio3T. Chúng tôi có thể truy vấn MongoDB của mình bằng khái niệm SQL thông thường và sau đó cố gắng điều chỉnh thô mã Mongo shell kết quả cho phù hợp với đặc điểm kỹ thuật của chúng tôi. Ví dụ:hãy tìm nạp tất cả dữ liệu có _id bằng 1 từ tất cả các bộ sưu tập:
SELECT *
FROM students
INNER JOIN units
ON students._id = units._id
INNER JOIN sports
ON students._id = sports._id
WHERE students._id = 1;Tài liệu kết quả sẽ là:
{
"students" : {"_id" : NumberInt(1),"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5},
"units" : {"_id" : NumberInt(1),"grades" : {Maths" : "A","English" : "A","Science" : "A","History" : "B"}
},
"sports" : {
"_id" : NumberInt(1),"tournamentsPlayed" : NumberInt(6),
"gamesParticipated" : [{"hockey" : "midfielder", "football" : "striker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge","South Africa","Rio Brazil"]
}
}Từ tab Mã truy vấn, mã MongoDB tương ứng sẽ là:
db.getCollection("students").aggregate(
[{ "$project" : {"_id" : NumberInt(0),"students" : "$$ROOT"}},
{ "$lookup" : {"localField" : "students._id","from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$unwind" : {"path" : "$units","preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id","from" : "sports", "foreignField" : "_id","as" : "sports"}},
{ "$unwind" : {"path" : "$sports", "preserveNullAndEmptyArrays" : false}},
{ "$match" : {"students._id" : NumberLong(1)}}
]
);Nhìn vào tài liệu trả về, cá nhân tôi không quá hài lòng với cấu trúc dữ liệu, đặc biệt là với các tài liệu nhúng. Như bạn có thể thấy, có các trường _id được trả về và đối với các đơn vị, chúng tôi có thể không cần nhúng trường điểm vào bên trong các đơn vị.
Chúng tôi muốn có một trường đơn vị với các đơn vị được nhúng chứ không phải bất kỳ trường nào khác. Điều này dẫn chúng ta đến phần giai điệu thô. Giống như trong các bài viết trước, sao chép mã bằng biểu tượng sao chép được cung cấp và chuyển đến ngăn tổng hợp, dán nội dung bằng biểu tượng dán.
Điều đầu tiên, toán tử $ match phải là giai đoạn đầu tiên, vì vậy hãy di chuyển nó đến vị trí đầu tiên và có một cái gì đó như sau:
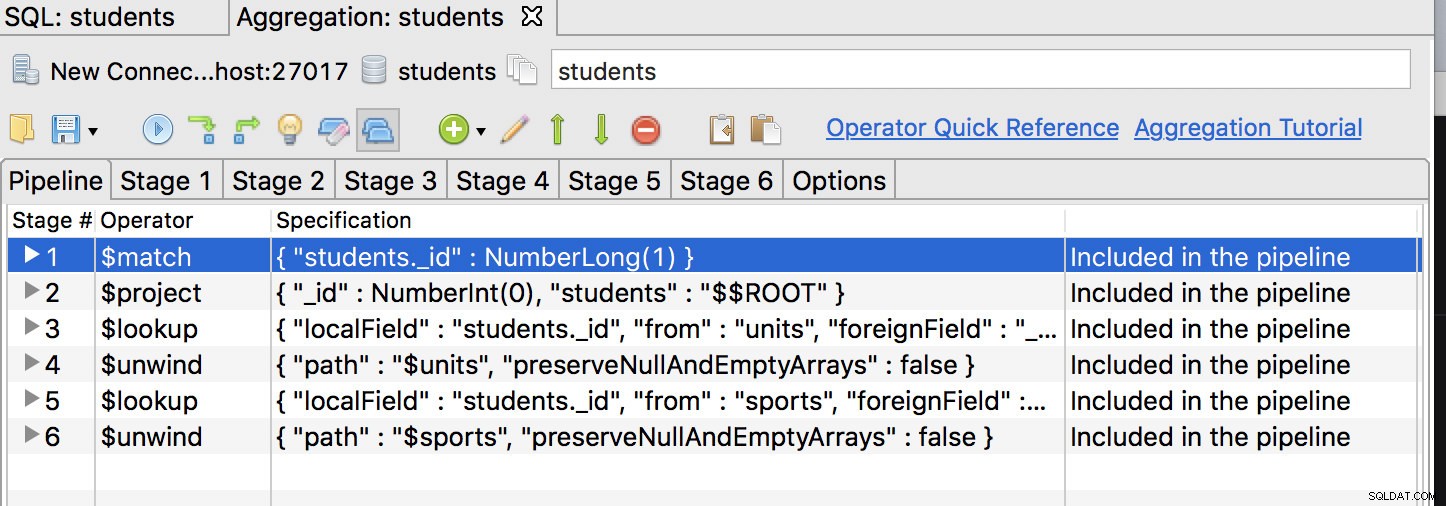
Nhấp vào tab giai đoạn đầu tiên và sửa đổi truy vấn thành:
{
"_id" : NumberLong(1)
}Sau đó, chúng tôi cần sửa đổi thêm truy vấn để loại bỏ nhiều giai đoạn nhúng dữ liệu của chúng tôi. Để làm như vậy, chúng tôi thêm các trường mới để thu thập dữ liệu cho các trường mà chúng tôi muốn loại bỏ, tức là:
db.getCollection("students").aggregate(
[
{ "$project" : { "_id" : NumberInt(0), "students" : "$$ROOT"}},
{ "$match" : {"students._id" : NumberLong(1)}},
{ "$lookup" : { "localField" : "students._id", "from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$addFields" : { "_id": "$students._id","units" : "$units.grades"}},
{ "$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id", "from" : "sports", "foreignField" : "_id", "as" : "sports"}},
{ "$unwind" : { "path" : "$sports","preserveNullAndEmptyArrays" : false}},
{ "$project" : {"sports._id" : 0.0}}
]
);Như bạn có thể thấy, trong quá trình tinh chỉnh, chúng tôi đã giới thiệu các đơn vị trường mới sẽ ghi đè lên nội dung của đường ống tổng hợp trước đó với các cấp dưới dạng một trường nhúng. Hơn nữa, chúng tôi đã tạo trường _id để chỉ ra rằng dữ liệu có liên quan đến bất kỳ tài liệu nào trong bộ sưu tập có cùng giá trị. Giai đoạn cuối cùng của dự án $ là xóa trường _id trong tài liệu thể thao để chúng tôi có thể có dữ liệu được trình bày gọn gàng như bên dưới.
{ "_id" : NumberInt(1),
"students" : {"name" : "James Washington", "age" : 15.0, "grade" : "A", "score" : 10.5},
"units" : {"Maths" : "A","English" : "A", "Science" : "A","History" : "B"},
"sports" : {
"tournamentsPlayed" : NumberInt(6),
"gamesParticipated" : [{"hockey" : "midfielder","football" : "striker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge", "South Africa", "Rio Brazil"]
}
}Chúng tôi cũng có thể hạn chế trường nào nên được trả về theo quan điểm SQL. Ví dụ:chúng ta có thể trả về tên sinh viên, đơn vị mà sinh viên này đang làm và số giải đấu đã chơi bằng cách sử dụng nhiều THAM GIA với mã bên dưới:
SELECT students.name, units.grades, sports.tournamentsPlayed
FROM students
INNER JOIN units
ON students._id = units._id
INNER JOIN sports
ON students._id = sports._id
WHERE students._id = 1;Điều này không cung cấp cho chúng tôi kết quả thích hợp nhất. Vì vậy, như thường lệ, hãy sao chép nó và dán vào ngăn tổng hợp. Chúng tôi tinh chỉnh đoạn mã dưới đây để có kết quả phù hợp.
db.getCollection("students").aggregate(
[
{ "$project" : { "_id" : NumberInt(0), "students" : "$$ROOT"}},
{ "$match" : {"students._id" : NumberLong(1)}},
{ "$lookup" : { "localField" : "students._id", "from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$addFields" : {"units" : "$units.grades"}},
{ "$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id", "from" : "sports", "foreignField" : "_id", "as" : "sports"}},
{ "$unwind" : { "path" : "$sports","preserveNullAndEmptyArrays" : false}},
{ "$project" : {"name" : "$students.name", "grades" : "$units.grades", "tournamentsPlayed" : "$sports.tournamentsPlayed"}
}}
]
);Kết quả tổng hợp này từ khái niệm SQL JOIN cung cấp cho chúng ta một cấu trúc dữ liệu gọn gàng và dễ trình bày được hiển thị bên dưới.
{
"name" : "James Washington",
"grades" : {"Maths" : "A", "English" : "A", "Science" : "A", "History" : "B"},
"tournamentsPlayed" : NumberInt(6)
}Khá đơn giản phải không? Dữ liệu khá hiển thị như thể nó được lưu trữ trong một bộ sưu tập dưới dạng một tài liệu duy nhất.
THAM GIA BÊN NGOÀI TRÁI
LEFT OUTER JOIN thường được sử dụng để hiển thị các tài liệu không tuân theo mối quan hệ được mô tả rõ nhất. Tập hợp kết quả của phép nối LEFT OUTER chứa tất cả các hàng từ cả hai tập hợp đáp ứng tiêu chí mệnh đề WHERE, giống như tập kết quả INNER JOIN. Bên cạnh đó, bất kỳ tài liệu nào từ bộ sưu tập bên trái không có tài liệu phù hợp trong bộ sưu tập bên phải cũng sẽ được đưa vào tập kết quả. Các trường đang được chọn từ bảng bên phải sẽ trả về giá trị NULL. Tuy nhiên, bất kỳ tài liệu nào trong bộ sưu tập bên phải, không có tiêu chí phù hợp với bộ sưu tập bên trái, sẽ không được trả lại.
Hãy xem hai bộ sưu tập này:
sinh viên
{"_id" : 1,"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5}
{"_id" : 2,"name" : "Clinton Ariango","age" : 14.0,"grade" : "B","score" : 7.5}
{"_id" : 4,"name" : "Mary Muthoni","age" : 16.0,"grade" : "A","score" : 11.5}Đơn vị
{"_id" : 1,"Maths" : "A","English" : "A","Science" : "A","History" : "B"}
{"_id" : 2,"Maths" : "B","English" : "B","Science" : "A","History" : "B"}
{"_id" : 3,"Maths" : "A","English" : "A","Science" : "A","History" : "A"}Trong tập hợp sinh viên, chúng tôi không đặt giá trị trường _id thành 3 nhưng trong tập hợp đơn vị, chúng tôi có. Tương tự như vậy, không có giá trị trường _id 4 trong bộ sưu tập đơn vị. Nếu chúng tôi sử dụng tập hợp sinh viên làm tùy chọn bên trái của chúng tôi trong phương pháp JOIN với truy vấn bên dưới:
SELECT *
FROM students
LEFT OUTER JOIN units
ON students._id = units._idVới đoạn mã này, chúng ta sẽ nhận được kết quả sau:
{
"students" : {"_id" : 1,"name" : "James Washington","age" : 15,"grade" : "A","score" : 10.5},
"units" : {"_id" : 1,"grades" : {"Maths" : "A","English" : "A", "Science" : "A","History" : "B"}}
}
{
"students" : {"_id" : 2,"name" : "Clinton Ariango", "age" : 14,"grade" : "B", "score" : 7.5 }
}
{
"students" : {"_id" : 3,"name" : "Mary Muthoni","age" : 16,"grade" : "A","score" : 11.5},
"units" : {"_id" : 3,"grades" : {"Maths" : "A","English" : "A","Science" : "A","History" : "A"}}
}Tài liệu thứ hai không có trường đơn vị vì không có tài liệu phù hợp trong tập hợp đơn vị. Đối với truy vấn SQL này, Mã Mongo tương ứng sẽ là
db.getCollection("students").aggregate(
[
{
"$project" : {"_id" : NumberInt(0), "students" : "$$ROOT"}},
{
"$lookup" : {"localField" : "students._id", "from" : "units", "foreignField" : "_id", "as" : "units"}
},
{
"$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : true}
}
]
);Tất nhiên, chúng tôi đã tìm hiểu về cách tinh chỉnh, vì vậy bạn có thể tiếp tục và cấu trúc lại quy trình tổng hợp để đưa ra kết quả cuối cùng mà bạn muốn. SQL là một công cụ rất mạnh trong lĩnh vực quản lý cơ sở dữ liệu. Bản thân nó là một chủ đề rộng, bạn cũng có thể thử sử dụng mệnh đề IN và GROUP BY để lấy mã tương ứng cho MongoDB và xem nó hoạt động như thế nào.
Kết luận
Làm quen với một công nghệ (cơ sở dữ liệu) mới ngoài công nghệ bạn đã quen làm việc có thể mất rất nhiều thời gian. Cơ sở dữ liệu quan hệ vẫn phổ biến hơn so với cơ sở dữ liệu không quan hệ. Tuy nhiên, với sự ra đời của MongoDB, mọi thứ đã thay đổi và mọi người muốn tìm hiểu nó càng nhanh càng tốt vì hiệu suất mạnh mẽ liên quan của nó.
Học MongoDB từ đầu có thể hơi tẻ nhạt, nhưng chúng ta có thể sử dụng kiến thức về SQL để thao tác dữ liệu trong MongoDB, lấy mã MongoDB tương đối và tinh chỉnh nó để có kết quả phù hợp nhất. Một trong những công cụ có sẵn để cải thiện điều này là Studio 3T. Nó cung cấp hai tính năng quan trọng tạo điều kiện thuận lợi cho hoạt động của dữ liệu phức tạp, đó là:tính năng truy vấn SQL và trình soạn thảo tổng hợp. Các truy vấn tinh chỉnh sẽ không chỉ đảm bảo bạn nhận được kết quả tốt nhất mà còn cải thiện hiệu suất về mặt tiết kiệm thời gian.



