Bảo trì là điều mà một nhóm vận hành không thể tránh khỏi. Máy chủ phải cập nhật phần mềm, phần cứng và công nghệ mới nhất để đảm bảo hệ thống ổn định và chạy với rủi ro thấp nhất có thể, đồng thời tận dụng các tính năng mới hơn để cải thiện hiệu suất tổng thể.
Không nghi ngờ gì nữa, có một danh sách dài các nhiệm vụ bảo trì phải được thực hiện bởi quản trị viên hệ thống, đặc biệt là khi liên quan đến các hệ thống quan trọng. Một số nhiệm vụ phải được thực hiện định kỳ, như hàng ngày, hàng tuần, hàng tháng và hàng năm. Một số phải được thực hiện ngay, khẩn trương. Tuy nhiên, bất kỳ hoạt động bảo trì nào không được dẫn đến một vấn đề lớn hơn và bất kỳ hoạt động bảo trì nào cũng phải được xử lý cẩn thận để tránh bất kỳ sự gián đoạn nào đối với công việc kinh doanh.
Nhận được trạng thái có vấn đề và cảnh báo sai là phổ biến trong khi bảo trì đang diễn ra. Điều này được mong đợi bởi vì trong thời gian bảo trì, máy chủ sẽ không hoạt động như bình thường cho đến khi nhiệm vụ bảo trì hoàn thành. ClusterControl, nền tảng quản lý và giám sát toàn diện dành cho cơ sở dữ liệu nguồn mở của bạn, có thể được định cấu hình để hiểu những trường hợp này nhằm đơn giản hóa quy trình bảo trì của bạn mà không phải hy sinh các tính năng giám sát và tự động hóa mà nó cung cấp.
Chế độ bảo trì
ClusterControl đã giới thiệu chế độ bảo trì trong phiên bản 1.4.0, nơi bạn có thể đưa một nút riêng lẻ vào bảo trì, ngăn ClusterControl tăng cảnh báo và gửi thông báo trong khoảng thời gian được chỉ định. Chế độ bảo trì có thể được cấu hình từ ClusterControl UI và cũng có thể sử dụng công cụ ClusterControl CLI được gọi là "s9s". Từ giao diện người dùng, chỉ cần đi tới Nút -> chọn một nút -> Hành động nút -> Chế độ bảo trì lập lịch :
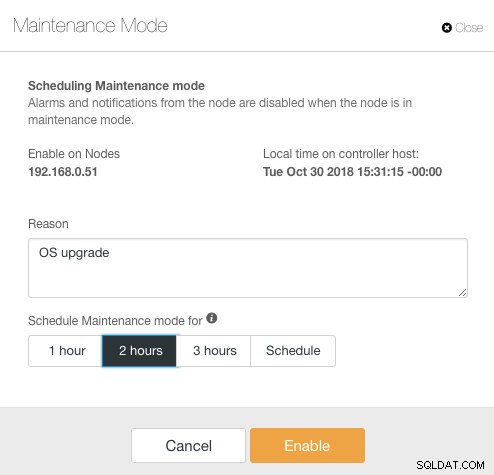
Tại đây, người ta có thể đặt thời gian bảo trì trong một khoảng thời gian xác định trước hoặc lên lịch cho phù hợp. Bạn cũng có thể viết ra lý do lên lịch nâng cấp, hữu ích cho mục đích kiểm tra. Bạn sẽ thấy thông báo sau khi chế độ bảo trì đang hoạt động:
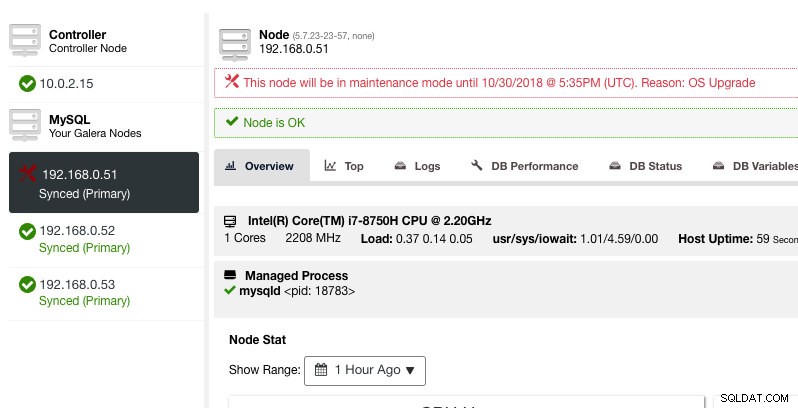
ClusterControl sẽ không làm suy giảm nút, do đó trạng thái của nút vẫn như cũ trừ khi bạn thực hiện bất kỳ hành động nào làm thay đổi trạng thái. Cảnh báo và thông báo cho nút này sẽ được kích hoạt lại sau khi thời gian bảo trì kết thúc hoặc người điều hành vô hiệu hóa nó một cách rõ ràng bằng cách đi tới Node Actions -> Disable Maintenance Mode .
Lưu ý rằng nếu tính năng khôi phục nút tự động được bật, ClusterControl sẽ luôn khôi phục một nút bất kể trạng thái chế độ bảo trì. Đừng quên tắt khôi phục nút để tránh ClusterControl can thiệp vào nhiệm vụ bảo trì của bạn, điều này có thể được thực hiện từ thanh tóm tắt trên cùng.
Chế độ bảo trì cũng có thể được cấu hình thông qua ClusterControl CLI hoặc "s9s". Bạn có thể sử dụng lệnh "bảo trì s9s" để liệt kê và thao tác các khoảng thời gian bảo trì. Dòng lệnh sau lên lịch cho cửa sổ bảo trì kéo dài một giờ cho nút 192.168.1.121 vào ngày mai:
$ s9s maintenance --create \
--nodes=192.168.1.121 \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="Upgrading software."Để biết thêm chi tiết và ví dụ, hãy xem tài liệu bảo trì s9s.
Chế độ bảo trì toàn cụm
Tại thời điểm viết bài này, cấu hình chế độ bảo trì phải được định cấu hình cho mỗi nút được quản lý. Để bảo trì toàn cụm, người ta phải lặp lại quy trình lập lịch cho mọi nút được quản lý của cụm. Điều này có thể không thực tế nếu bạn có nhiều nút trong cụm của mình hoặc nếu khoảng thời gian bảo trì giữa hai nhiệm vụ rất ngắn.
May mắn thay, ClusterControl CLI (còn gọi là s9s) có thể được sử dụng như một giải pháp thay thế để khắc phục hạn chế này. Bạn có thể sử dụng "các nút s9s" để liệt kê và thao tác các nút được quản lý trong một cụm. Danh sách này có thể được lặp lại để lập lịch cho chế độ bảo trì toàn cụm tại một thời điểm nhất định bằng cách sử dụng lệnh "bảo trì s9s".
Hãy xem một ví dụ để hiểu điều này tốt hơn. Hãy xem xét Cụm Percona XtraDB ba nút sau đây mà chúng ta có:
$ s9s nodes --list --cluster-name='PXC57' --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PXC57 10.0.2.15 9500 Up and running.
go-M 5.7.23 1 PXC57 192.168.0.51 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.52 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.53 3306 Up and running.
Total: 4Cụm có tổng cộng 4 nút - 3 nút cơ sở dữ liệu với một nút ClusterControl. Cột đầu tiên, STAT hiển thị vai trò và trạng thái của nút. Ký tự đầu tiên là vai trò của nút - "c" có nghĩa là bộ điều khiển và "g" có nghĩa là nút cơ sở dữ liệu Galera. Giả sử chúng ta chỉ muốn lên lịch cho các nút cơ sở dữ liệu để bảo trì, chúng ta có thể lọc ra đầu ra để lấy tên máy chủ hoặc địa chỉ IP nơi STAT được báo cáo có "g" ở đầu:
$ s9s nodes --list --cluster-name='PXC57' --long --batch | grep ^g | awk {'print $5'}
192.168.0.51
192.168.0.52
192.168.0.53Với một lần lặp lại đơn giản, sau đó chúng ta có thể lên lịch cho một cửa sổ bảo trì toàn cụm cho mọi nút trong cụm. Lệnh sau lặp lại việc tạo bảo trì dựa trên tất cả các địa chỉ IP được tìm thấy trong cụm bằng vòng lặp for, nơi chúng tôi dự định bắt đầu hoạt động bảo trì vào ngày mai và kết thúc một giờ sau:
$ for host in $(s9s nodes --list --cluster-id='PXC57' --long --batch | grep ^g | awk {'print $5'}); do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="OS upgrade"; done
f92c5370-004d-4735-bba0-8c1bd26b9b98
9ff7dd8c-f2cb-4446-b14b-a5c2b915b853
103d715d-d0bc-4402-9326-1a053bc5d36bBạn sẽ thấy bản in gồm 3 UUID, chuỗi duy nhất xác định mọi khoảng thời gian bảo trì. Sau đó, chúng tôi có thể xác minh bằng lệnh sau:
$ s9s maintenance --list --long
ST UUID OWNER GROUP START END HOST/CLUSTER REASON
-h f92c537 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.51 OS upgrade
-h 9ff7dd8 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.52 OS upgrade
-h 103d715 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.53 OS upgrade
Total: 3Từ kết quả đầu ra ở trên, chúng tôi nhận được danh sách thời gian bảo trì theo lịch trình cho mọi nút cơ sở dữ liệu. Trong thời gian đã lên lịch, ClusterControl sẽ không báo động cũng như không gửi thông báo nếu phát hiện thấy những bất thường đối với cụm.
Lặp lại chế độ bảo trì
Một số quy trình bảo trì phải được thực hiện định kỳ, chẳng hạn như các công việc sao lưu, dọn dẹp nhà cửa và dọn dẹp. Trong thời gian bảo trì, chúng tôi hy vọng máy chủ sẽ hoạt động khác. Tuy nhiên, bất kỳ lỗi dịch vụ nào, không thể truy cập tạm thời hoặc tải cao chắc chắn sẽ gây ảnh hưởng xấu đến hệ thống giám sát của chúng tôi. Đối với các khoảng thời gian bảo trì thường xuyên và khoảng thời gian ngắn, điều này có thể rất khó chịu và việc bỏ qua các báo động giả được nâng lên có thể mang lại cho bạn giấc ngủ ngon hơn vào ban đêm.
Tuy nhiên, việc bật chế độ bảo trì cũng có thể khiến máy chủ gặp rủi ro lớn hơn vì việc giám sát nghiêm ngặt bị bỏ qua trong một khoảng thời gian. Do đó, có lẽ nên hiểu bản chất của hoạt động bảo trì mà chúng tôi muốn thực hiện trước khi bật chế độ bảo trì. Danh sách kiểm tra sau sẽ giúp chúng tôi xác định chính sách chế độ bảo trì của mình:
- Các nút bị ảnh hưởng - Những nút nào tham gia vào quá trình bảo trì?
- Hậu quả - Điều gì xảy ra với nút khi hoạt động bảo trì đang diễn ra? Nó sẽ không thể truy cập được, tải cao hay phải khởi động lại?
- Thời lượng - Mất bao nhiêu thời gian để hoàn thành hoạt động bảo trì?
- Tần suất - Hoạt động bảo trì nên chạy thường xuyên như thế nào?
Hãy đặt nó vào một trường hợp sử dụng. Hãy xem xét chúng ta có một Cụm Percona XtraDB ba nút với một nút ClusterControl. Giả sử các máy chủ của chúng tôi đều đang chạy trên máy ảo và chính sách sao lưu VM yêu cầu tất cả các máy ảo phải được sao lưu hàng ngày bắt đầu từ 1:00 sáng, mỗi lần một nút. Trong quá trình sao lưu này, nút sẽ bị đóng băng tối đa khoảng 10 phút và nút đang được quản lý và giám sát bởi ClusterControl sẽ không thể truy cập được cho đến khi quá trình sao lưu kết thúc. Từ quan điểm của Cụm Galera, thao tác này không đưa toàn bộ cụm xuống vì cụm vẫn ở số đại biểu và thành phần chính không bị ảnh hưởng.
Dựa trên bản chất của nhiệm vụ bảo trì, chúng tôi có thể tóm tắt nó như sau:
- Các nút bị ảnh hưởng - Tất cả các nút cho ID cụm 1 (3 nút cơ sở dữ liệu và 1 nút ClusterControl).
- Do đó - Máy ảo đang được sao lưu sẽ không thể truy cập được cho đến khi hoàn tất.
- Thời lượng - Mỗi thao tác sao lưu máy ảo mất khoảng 5 đến 10 phút để hoàn thành.
- Tần suất - Bản sao lưu VM được lên lịch chạy hàng ngày, bắt đầu từ 1:00 sáng trên nút đầu tiên.
Sau đó, chúng tôi có thể đưa ra kế hoạch thực hiện để lên lịch cho chế độ bảo trì của chúng tôi:
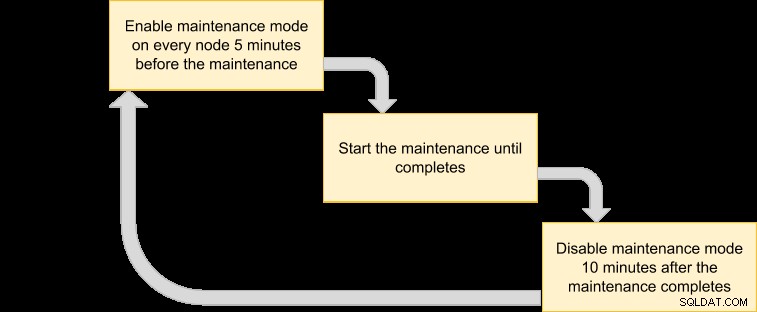
Vì chúng tôi muốn tất cả các nút trong cụm được sao lưu bởi trình quản lý máy ảo, chỉ cần liệt kê các nút cho ID cụm tương ứng:
$ s9s nodes --list --cluster-id=1
192.168.0.51 10.0.2.15 192.168.0.52 192.168.0.53Kết quả đầu ra trên có thể được sử dụng để lên lịch bảo trì trên toàn bộ cụm. Ví dụ:nếu bạn chạy lệnh sau, ClusterControl sẽ kích hoạt chế độ bảo trì cho tất cả các nút dưới ID cụm 1 từ bây giờ cho đến 50 phút tiếp theo:
$ for host in $(s9s nodes --list --cluster-id=1); do \
s9s maintenance --create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="Backup VM"; doneSử dụng lệnh trên, chúng ta có thể chuyển đổi nó thành một tệp thực thi bằng cách đưa nó vào một tập lệnh. Tạo tệp:
$ vim /usr/local/bin/enable_maintenance_modeVà thêm các dòng sau:
for host in $(s9s nodes --list --cluster-id=1)
do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="VM Backup"
doneLưu nó và đảm bảo quyền tệp có thể thực thi được:
$ chmod 755 /usr/local/bin/enable_maintenance_modeSau đó, sử dụng cron để lập lịch chạy tập lệnh lúc 5 phút đến 1 giờ sáng hàng ngày, ngay trước khi hoạt động sao lưu máy ảo bắt đầu lúc 1 giờ sáng:
$ crontab -e
55 0 * * * /usr/local/bin/enable_maintenance_modeTải lại daemon cron để đảm bảo tập lệnh của chúng tôi đang được xếp hàng đợi:
$ systemctl reload crond # or service crond reloadĐó là nó. Giờ đây, chúng tôi có thể thực hiện hoạt động bảo trì hàng ngày của mình mà không bị nghe trộm bởi các cảnh báo sai và thông báo qua thư cho đến khi quá trình bảo trì hoàn tất.
Tính năng bảo trì phần thưởng - Bỏ qua khôi phục nút
Với tính năng tự động khôi phục được bật, ClusterControl đủ thông minh để phát hiện lỗi nút và sẽ cố gắng khôi phục nút bị lỗi sau thời gian gia hạn 30 giây, bất kể trạng thái chế độ bảo trì. Bạn có biết rằng ClusterControl có thể được định cấu hình để cố tình bỏ qua khôi phục nút cho một nút cụ thể không? Điều này có thể rất hữu ích khi bạn phải thực hiện bảo trì khẩn cấp mà không biết khoảng thời gian và kết quả của việc bảo trì.
Ví dụ, hãy tưởng tượng một lỗi hệ thống tệp đã xảy ra và việc kiểm tra và sửa chữa hệ thống tệp được yêu cầu sau khi khởi động lại cứng. Thật khó để xác định trước cần bao nhiêu thời gian để hoàn thành thao tác này. Do đó, chúng ta có thể chỉ cần sử dụng một tệp cờ để báo hiệu ClusterControl bỏ qua quá trình khôi phục cho nút.
Đầu tiên, thêm dòng sau vào bên trong /etc/cmon.d/cmon_X.cnf (trong đó X là ID cụm) trên nút ClusterControl:
node_recovery_lock_file=/root/do_not_recoverSau đó, khởi động lại dịch vụ cmon để tải thay đổi:
$ systemctl restart cmon # service cmon restartCuối cùng, đảm bảo tệp được chỉ định có trên nút mà chúng ta muốn bỏ qua để khôi phục ClusterControl:
$ touch /root/do_not_recoverBất kể trạng thái chế độ bảo trì và khôi phục tự động, ClusterControl sẽ chỉ khôi phục nút khi tệp cờ này không tồn tại. Sau đó, quản trị viên có trách nhiệm tạo và xóa tệp trên nút cơ sở dữ liệu.
Đó là nó, folks. Chúc bạn bảo trì vui vẻ!



