Tôi thực sự không đồng ý với tác giả của câu trả lời đã chọn rằng Không có id tăng tự động trong MongoDB và có những lý do chính đáng . Chúng tôi không biết lý do tại sao 10gen không khuyến khích sử dụng ID tăng tự động. Đó là suy đoán. Tôi nghĩ rằng 10gen đã đưa ra lựa chọn này vì nó chỉ dễ dàng hơn để đảm bảo tính duy nhất của ID 12 byte trong môi trường phân cụm. Đó là giải pháp mặc định phù hợp với hầu hết những người mới đến, do đó làm tăng mức độ chấp nhận sản phẩm, điều này tốt cho hoạt động kinh doanh của 10gen.
Bây giờ, hãy để tôi kể cho mọi người nghe về trải nghiệm của tôi với ObjectIds trong môi trường thương mại.
Tôi đang xây dựng mạng xã hội. Chúng tôi có khoảng 6 triệu người dùng và mỗi người dùng có khoảng 20 người bạn.
Bây giờ hãy tưởng tượng chúng ta có một bộ sưu tập lưu trữ mối quan hệ giữa những người dùng (ai theo dõi ai). Nó trông giống như thế này
_id : ObjectId
user_id : ObjectId
followee_id : ObjectId
trên đó chúng tôi có chỉ mục tổng hợp duy nhất {user_id, followee_id} . Chúng tôi có thể ước tính kích thước của chỉ mục này là 12 * 2 * 6M * 20 =2GB. Bây giờ đó là chỉ mục để tra cứu nhanh những người tôi theo dõi. Để tra cứu nhanh những người theo dõi tôi, tôi cần chỉ mục ngược lại. Đó là 2GB nữa.
Và điều này chỉ là khởi đầu. Tôi phải mang theo những ID này ở khắp mọi nơi. Chúng tôi có cụm hoạt động nơi chúng tôi lưu trữ Bảng tin của bạn. Đó là mọi sự kiện bạn hoặc bạn bè của bạn làm. Hãy tưởng tượng nó chiếm bao nhiêu dung lượng.
Và cuối cùng, một trong những kỹ sư của chúng tôi đã đưa ra một quyết định vô thức và quyết định lưu trữ các tham chiếu dưới dạng các chuỗi đại diện cho ObjectId, làm tăng gấp đôi kích thước của nó.
Điều gì xảy ra nếu một chỉ mục không vừa với RAM? Không có gì tốt, 10gen nói:
Khi một chỉ mục quá lớn để vừa với RAM, MongoDB phải đọc chỉ mục từ đĩa, đây là một hoạt động chậm hơn nhiều so với đọc từ RAM. Hãy nhớ rằng một chỉ mục phù hợp với RAM khi máy chủ của bạn có sẵn RAM cho chỉ mục kết hợp với phần còn lại của bộ hoạt động.
Điều đó có nghĩa là đọc chậm. Khóa tranh chấp tăng lên. Viết cũng chậm hơn. Tôi không còn bị sốc khi thấy khóa tranh chấp 80%.
Trước khi bạn biết điều đó, bạn đã kết thúc với cụm 460GB mà bạn phải chia thành các mảnh và khá khó để thao tác.
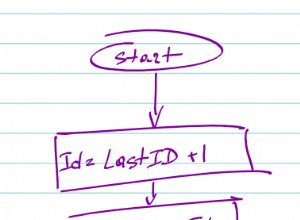
Facebook sử dụng 64-bit dài làm id người dùng :) Có lý do cho điều đó. Bạn có thể tạo ID tuần tự
- sử dụng Lời khuyên của 10gen .
- sử dụng mysql làm nơi lưu trữ bộ đếm (nếu bạn lo lắng về tốc độ, hãy xem handlersocket )
- sử dụng dịch vụ tạo ID mà bạn đã tạo hoặc sử dụng dịch vụ nào đó như Snowflake bởi Twitter.
Vì vậy, đây là lời khuyên chung của tôi cho tất cả mọi người. Vui lòng làm cho dữ liệu của bạn càng nhỏ càng tốt. Khi bạn phát triển nó sẽ giúp bạn tiết kiệm nhiều đêm mất ngủ.