Tính điểm dựa trên số lượng trận đấu gốc, nhưng cũng có một hệ số tích hợp để điều chỉnh điểm số cho các trận đấu liên quan đến tổng chiều dài trường (đã loại bỏ các từ dừng). Nếu văn bản dài hơn của bạn bao gồm nhiều từ liên quan hơn cho một truy vấn, điều này sẽ thêm vào điểm số. Văn bản dài hơn không khớp với truy vấn sẽ làm giảm điểm.
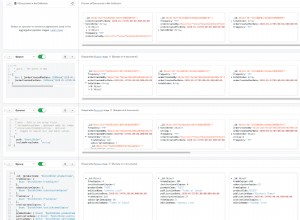
Đoạn mã từ mã nguồn MongoDB 3.2 trên GitHub ( src / mongo / db / fts / fts_spec.cpp ):
for (ScoreHelperMap::const_iterator i = terms.begin(); i != terms.end(); ++i) {
const string& term = i->first;
const ScoreHelperStruct& data = i->second;
// in order to adjust weights as a function of term count as it
// relates to total field length. ie. is this the only word or
// a frequently occuring term? or does it only show up once in
// a long block of text?
double coeff = (0.5 * data.count / numTokens) + 0.5;
// if term is identical to the raw form of the
// field (untokenized) give it a small boost.
double adjustment = 1;
if (raw.size() == term.length() && raw.equalCaseInsensitive(term))
adjustment += 0.1;
double& score = (*docScores)[term];
score += (weight * data.freq * coeff * adjustment);
verify(score <= MAX_WEIGHT);
}
}
Thiết lập một số dữ liệu thử nghiệm để xem ảnh hưởng của hệ số độ dài trên một ví dụ rất đơn giản:
db.articles.insert([
{ headline: "Rock" },
{ headline: "Rocks" },
{ headline: "Rock paper" },
{ headline: "Rock paper scissors" },
])
db.articles.createIndex({ "headline": "text"})
db.articles.find(
{ $text: { $search: "rock" }},
{ _id:0, headline:1, score: { $meta: "textScore" }}
).sort({ score: { $meta: "textScore" }})
Kết quả được chú thích:
// Exact match of raw term to indexed field
// Coefficent is 1, plus 0.1 bonus for identical match of raw term
{
"headline": "Rock",
"score": 1.1
}
// Match of stemmed term to indexed field ("rocks" stems to "rock")
// Coefficent is 1
{
"headline": "Rocks",
"score": 1
}
// Two terms, one matching
// Coefficient is 0.75: (0.5 * 1 match / 2 terms) + 0.5
{
"headline": "Rock paper",
"score": 0.75
}
// Three terms, one matching
// Coefficient is 0.66: (0.5 * 1 match / 3 terms) + 0.5
{
"headline": "Rock paper scissors",
"score": 0.6666666666666666
}