Xem tổng quan về các cơ chế có sẵn để sao lưu dữ liệu được lưu trữ trong Apache HBase và cách khôi phục dữ liệu đó trong trường hợp có nhiều tình huống khôi phục / chuyển đổi dự phòng khác nhau
Với việc tăng cường áp dụng và tích hợp HBase vào các hệ thống kinh doanh quan trọng, nhiều doanh nghiệp cần bảo vệ tài sản kinh doanh quan trọng này bằng cách xây dựng các chiến lược sao lưu và phục hồi sau thảm họa (BDR) mạnh mẽ cho các cụm HBase của họ. Nghe có vẻ khó khăn khi sao lưu và khôi phục hàng petabyte dữ liệu tiềm năng một cách nhanh chóng và dễ dàng, HBase và hệ sinh thái Apache Hadoop cung cấp nhiều cơ chế tích hợp để thực hiện điều đó.
Trong bài đăng này, bạn sẽ có được tổng quan cấp cao về các cơ chế có sẵn để sao lưu dữ liệu được lưu trữ trong HBase và cách khôi phục dữ liệu đó trong trường hợp có nhiều tình huống khôi phục / chuyển đổi dự phòng dữ liệu khác nhau. Sau khi đọc bài đăng này, bạn sẽ có thể đưa ra quyết định có hiểu biết về chiến lược BDR nào là tốt nhất cho nhu cầu kinh doanh của bạn. Bạn cũng nên hiểu những ưu, nhược điểm và ý nghĩa hiệu suất của từng cơ chế. (Chi tiết ở đây áp dụng cho CDH 4.3.0 / HBase 0.94.6 trở lên.)
Lưu ý:Tại thời điểm viết bài này, Cloudera Enterprise 4 cung cấp chức năng sao lưu và khôi phục thảm họa sẵn sàng cho sản xuất cho HDFS và Hive Metastore qua Cloudera BDR 1.0 dưới dạng một tính năng được cấp phép riêng. HBase không được bao gồm trong bản phát hành GA đó; do đó, các cơ chế khác nhau được mô tả trong blog này là bắt buộc. (Cloudera Enterprise 5, hiện đang trong giai đoạn thử nghiệm, cung cấp tính năng quản lý ảnh chụp nhanh HBase thông qua Cloudera BDR.)
Sao lưu
HBase là một kho lưu trữ dữ liệu phân tán cây hợp nhất có cấu trúc nhật ký với các cơ chế nội bộ phức tạp để đảm bảo dữ liệu chính xác, nhất quán, tạo phiên bản, v.v. Vậy làm thế nào trên thế giới này, bạn có thể có được một bản sao lưu nhất quán của dữ liệu này nằm trong sự kết hợp của HFiles và Write-Ahead-Logs (WALs) trên HDFS và trong bộ nhớ trên hàng chục máy chủ khu vực?
Hãy bắt đầu với ít gián đoạn nhất, dấu vết dữ liệu nhỏ nhất, cơ chế ít ảnh hưởng đến hiệu suất nhất và làm việc theo cách của chúng tôi để đạt được công cụ kiểu xe nâng, gây rối loạn nhất:
- Ảnh chụp nhanh
- Nhân rộng
- Xuất
- CopyTable
- API HTable
- Sao lưu ngoại tuyến dữ liệu HDFS
Bảng sau cung cấp một cái nhìn tổng quan để so sánh nhanh các cách tiếp cận này, mà tôi sẽ mô tả chi tiết bên dưới.
| Tác động đến Hiệu suất | Dấu chân dữ liệu | Thời gian ngừng hoạt động | Sao lưu gia tăng | Dễ triển khai | Thời gian trung bình để khôi phục (MTTR) | |
| Ảnh chụp nhanh | Tối thiểu | Nhỏ xíu | Tóm tắt (Chỉ khi Khôi phục) | Không | Dễ dàng | Giây |
| Nhân rộng | Tối thiểu | Lớn | Không có | Nội tại | Trung bình | Giây |
| Xuất | Cao | Lớn | Không có | Có | Dễ dàng | Cao |
| CopyTable | Cao | Lớn | Không có | Có | Dễ dàng | Cao |
| API | Trung bình | Lớn | Không có | Có | Khó | Tùy thuộc vào bạn |
| Thủ công | Không có | Lớn | Dài | Không | Trung bình | Cao |
Ảnh chụp nhanh
Kể từ CDH 4.3.0, ảnh chụp nhanh HBase có đầy đủ chức năng, tính năng phong phú và không yêu cầu thời gian ngừng hoạt động cụm trong quá trình tạo. Đồng nghiệp của tôi, Matteo Bertozzi đã đưa ra rất tốt các bức ảnh chụp nhanh trong mục nhập blog của anh ấy và sau đó là phần lặn sâu. Ở đây tôi sẽ chỉ cung cấp tổng quan cấp cao.
Ảnh chụp nhanh chỉ cần ghi lại kịp thời một khoảnh khắc cho bảng của bạn bằng cách tạo các liên kết cứng UNIX tương đương với các tệp lưu trữ trên bảng của bạn trên HDFS (Hình 1). Các ảnh chụp nhanh này hoàn thành trong vòng vài giây, hầu như không có chi phí hiệu suất trên cụm và tạo ra một dấu vết dữ liệu nhỏ. Dữ liệu của bạn hoàn toàn không bị sao chép mà chỉ được lập danh mục trong các tệp siêu dữ liệu nhỏ, điều này cho phép hệ thống quay trở lại thời điểm đó nếu bạn cần khôi phục ảnh chụp nhanh đó.
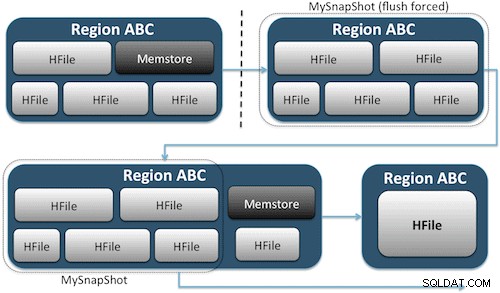
Tạo ảnh chụp nhanh của bảng đơn giản như chạy lệnh này từ vỏ HBase:
hbase(main):001:0> snapshot 'myTable', 'MySnapShot'
Sau khi phát hành lệnh này, bạn sẽ tìm thấy một số tệp dữ liệu nhỏ nằm trong /hbase/.snapshot/myTable (CDH4) hoặc /hbase/.hbase-snapshots (Apache 0.94.6.1) trong HDFS bao gồm thông tin cần thiết để khôi phục ảnh chụp nhanh của bạn . Việc khôi phục cũng đơn giản như phát hành các lệnh này từ shell:
hbase(main):002:0> disable 'myTable' hbase(main):003:0> restore_snapshot 'MySnapShot' hbase(main):004:0> enable 'myTable'
Lưu ý:Như bạn có thể thấy, việc khôi phục ảnh chụp nhanh yêu cầu tạm ngừng hoạt động vì bảng phải ngoại tuyến. Mọi dữ liệu được thêm / cập nhật sau khi chụp ảnh chụp nhanh khôi phục được thực hiện sẽ bị mất.
Nếu yêu cầu kinh doanh của bạn đến mức bạn phải có bản sao lưu dữ liệu bên ngoài, bạn có thể sử dụng lệnh exportSnapshot để sao chép dữ liệu của bảng vào cụm HDFS cục bộ hoặc cụm HDFS từ xa mà bạn chọn.
Ảnh chụp nhanh là hình ảnh đầy đủ về bàn của bạn mỗi lần; hiện không có chức năng chụp nhanh gia tăng nào.
Bản sao HBase
Nhân bản HBase là một công cụ sao lưu chi phí rất thấp khác. (Đồng nghiệp của tôi Himanshu Vashishtha trình bày chi tiết về quá trình sao chép trong bài đăng trên blog này.) Tóm lại, sao chép có thể được xác định ở cấp cột-họ, hoạt động trong nền và giữ tất cả các chỉnh sửa đồng bộ giữa các cụm trong chuỗi sao chép.
Nhân bản có ba chế độ:master-> slave, master <-> master và cyclic. Cách tiếp cận này giúp bạn linh hoạt trong việc nhập dữ liệu từ bất kỳ trung tâm dữ liệu nào và đảm bảo rằng nó được sao chép trên tất cả các bản sao của bảng đó trong các trung tâm dữ liệu khác. Trong trường hợp xảy ra sự cố nghiêm trọng ở một trung tâm dữ liệu, các ứng dụng khách có thể được chuyển hướng đến một vị trí thay thế cho dữ liệu sử dụng các công cụ DNS.
Sao chép là một quy trình mạnh mẽ, có khả năng chịu lỗi, cung cấp "tính nhất quán cuối cùng", nghĩa là bất kỳ lúc nào, các chỉnh sửa gần đây đối với một bảng có thể không khả dụng trong tất cả các bản sao của bảng đó nhưng được đảm bảo cuối cùng sẽ đạt được điều đó.
Lưu ý:Đối với các bảng hiện có, trước tiên bạn phải sao chép thủ công bảng nguồn vào bảng đích thông qua một trong các phương tiện khác được mô tả trong bài đăng này. Việc sao chép chỉ hoạt động trên các lần viết / chỉnh sửa mới sau khi bạn bật nó.

(Từ trang Bản sao của Apache)
Xuất
Công cụ HBase’s Export là một tiện ích HBase được tích hợp sẵn cho phép dễ dàng xuất dữ liệu từ bảng HBase sang các tệp SequenceFiles đơn giản trong thư mục HDFS. Nó tạo ra một công việc MapReduce thực hiện một loạt các lệnh gọi API HBase đến cụm của bạn và từng hàng một, lấy từng hàng dữ liệu từ bảng được chỉ định và ghi dữ liệu đó vào thư mục HDFS được chỉ định của bạn. Công cụ này chuyên sâu hơn về hiệu suất cho cụm của bạn vì nó sử dụng MapReduce và API ứng dụng khách HBase, nhưng có nhiều tính năng và hỗ trợ lọc dữ liệu theo phiên bản hoặc phạm vi ngày - do đó cho phép sao lưu gia tăng.
Đây là một mẫu lệnh ở dạng đơn giản nhất:
hbase org.apache.hadoop.hbase.mapreduce.Export
Khi bảng của bạn được xuất, bạn có thể sao chép các tệp dữ liệu kết quả ở bất kỳ đâu bạn muốn (chẳng hạn như lưu trữ ngoại vi / ngoài cụm). Bạn cũng có thể chỉ định một cụm / thư mục HDFS từ xa làm vị trí đầu ra của lệnh và Export sẽ ghi trực tiếp nội dung vào cụm từ xa. Xin lưu ý rằng cách tiếp cận này sẽ đưa một phần tử mạng vào đường dẫn ghi của quá trình xuất, vì vậy bạn nên xác nhận kết nối mạng của mình với cụm từ xa là đáng tin cậy và nhanh chóng.
CopyTable
Tiện ích CopyTable được đề cập kỹ trong mục blog của Jon Hsieh, nhưng tôi sẽ tóm tắt những điều cơ bản ở đây. Tương tự như Export, CopyTable tạo một công việc MapReduce sử dụng API HBase để đọc từ bảng nguồn. Điểm khác biệt chính là CopyTable ghi đầu ra của nó trực tiếp vào bảng đích trong HBase, bảng này có thể là cục bộ đối với cụm nguồn của bạn hoặc trên một cụm từ xa.
Ví dụ về dạng đơn giản nhất của lệnh là:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=testCopy test
Lệnh này sẽ sao chép nội dung của một bảng có tên “test” sang một bảng trong cùng một cụm có tên “testCopy.”
Lưu ý rằng CopyTable có chi phí hiệu suất đáng kể ở chỗ nó sử dụng các “lần đặt” riêng lẻ để ghi dữ liệu, theo từng hàng, vào bảng đích. Nếu bảng của bạn rất lớn, CopyTable có thể khiến memstore trên các máy chủ của khu vực đích bị lấp đầy, yêu cầu xả memstore, điều này cuối cùng sẽ dẫn đến các giao dịch, thu thập rác, v.v.
Ngoài ra, bạn phải tính đến các tác động về hiệu suất của việc chạy MapReduce qua HBase. Với các tập dữ liệu lớn, cách tiếp cận đó có thể không lý tưởng.
API HTable (chẳng hạn như ứng dụng Java tùy chỉnh)
Như mọi khi xảy ra với Hadoop, bạn luôn có thể viết ứng dụng tùy chỉnh của riêng mình bằng cách sử dụng API công khai và truy vấn bảng trực tiếp. Bạn có thể thực hiện việc này thông qua các công việc MapReduce để tận dụng các lợi thế xử lý hàng loạt phân tán của khung công tác đó hoặc thông qua bất kỳ phương tiện nào khác trong thiết kế của riêng bạn. Tuy nhiên, cách tiếp cận này yêu cầu sự hiểu biết sâu sắc về sự phát triển Hadoop và tất cả các API cũng như ý nghĩa về hiệu suất của việc sử dụng chúng trong cụm sản xuất của bạn.
Sao lưu ngoại tuyến dữ liệu HDFS thô
Cơ chế sao lưu thô bạo nhất - cũng là cơ chế gây rối nhất - liên quan đến dấu vết dữ liệu lớn nhất. Bạn có thể tắt hẳn cụm HBase của mình và sao chép thủ công tất cả các cấu trúc dữ liệu và thư mục nằm trong / hbase trong cụm HDFS của bạn. Vì HBase ngừng hoạt động, điều đó sẽ đảm bảo rằng tất cả dữ liệu đã được lưu vào HFiles trong HDFS và bạn sẽ nhận được một bản sao chính xác của dữ liệu. Tuy nhiên, các bản sao lưu gia tăng sẽ gần như không thể lấy được vì bạn sẽ không thể chắc chắn dữ liệu nào đã thay đổi hoặc được thêm vào khi cố gắng sao lưu trong tương lai.
Điều quan trọng cần lưu ý là khôi phục dữ liệu của bạn sẽ yêu cầu sửa chữa meta ngoại tuyến vì .META. bảng sẽ chứa thông tin có khả năng không hợp lệ tại thời điểm khôi phục. Cách tiếp cận này cũng yêu cầu một mạng nhanh chóng đáng tin cậy để chuyển dữ liệu ra bên ngoài và khôi phục nó sau này nếu cần.
Vì những lý do này, Cloudera thực sự không khuyến khích cách tiếp cận này đối với các bản sao lưu HBase.
Khôi phục sau thảm họa
HBase được thiết kế để trở thành một hệ thống phân tán có khả năng chịu lỗi cực cao với khả năng dự phòng nguyên bản, giả sử phần cứng sẽ thường xuyên bị lỗi. Khôi phục thảm họa trong HBase thường có một số dạng:
- Lỗi nghiêm trọng ở cấp trung tâm dữ liệu, yêu cầu chuyển đổi dự phòng sang vị trí dự phòng
- Cần khôi phục bản sao dữ liệu trước đó của bạn do lỗi của người dùng hoặc do tình cờ xóa
- Khả năng khôi phục bản sao dữ liệu theo thời gian của bạn cho các mục đích kiểm tra
Như với bất kỳ kế hoạch phục hồi sau thảm họa nào, các yêu cầu kinh doanh sẽ thúc đẩy cách thức cấu trúc kế hoạch và số tiền đầu tư vào nó. Khi bạn đã thiết lập các bản sao lưu theo lựa chọn của mình, việc khôi phục diễn ra theo các hình thức khác nhau tùy thuộc vào loại khôi phục được yêu cầu:
- Chuyển đổi dự phòng với cụm sao lưu
- Nhập Bảng / Khôi phục ảnh chụp nhanh
- Trỏ thư mục gốc HBase vào vị trí sao lưu
Nếu chiến lược sao lưu của bạn đến mức bạn đã sao chép dữ liệu HBase của mình sang một cụm sao lưu trong một trung tâm dữ liệu khác, thì việc thất bại cũng dễ dàng như trỏ các ứng dụng người dùng cuối của bạn đến cụm sao lưu bằng các kỹ thuật DNS.
Tuy nhiên, hãy nhớ rằng nếu bạn định cho phép ghi dữ liệu vào cụm sao lưu của mình trong thời gian ngừng hoạt động, bạn sẽ cần đảm bảo rằng dữ liệu quay trở lại cụm chính khi thời gian ngừng hoạt động kết thúc. Sao chép từ master-to-master hoặc theo chu kỳ sẽ tự động xử lý quá trình này cho bạn, nhưng sơ đồ sao chép master-slave sẽ khiến cụm chính của bạn không đồng bộ, cần có sự can thiệp thủ công sau khi ngừng hoạt động.
Cùng với tính năng Xuất được mô tả trước đó, có một công cụ Nhập tương ứng có thể lấy dữ liệu đã sao lưu trước đó bằng Xuất và khôi phục dữ liệu đó vào bảng HBase. Các hàm ý về hiệu suất áp dụng cho Xuất cũng giống như Nhập. Nếu chương trình sao lưu của bạn liên quan đến việc chụp ảnh nhanh, việc hoàn nguyên về bản sao dữ liệu trước đó của bạn cũng đơn giản như khôi phục ảnh chụp nhanh đó.
Bạn cũng có thể khôi phục sau thảm họa bằng cách chỉ cần sửa đổi thuộc tính hbase.root.dir trong hbase-site.xml và trỏ nó vào bản sao lưu của thư mục / hbase nếu bạn đã thực hiện sao chép ngoại tuyến brute-force của cấu trúc dữ liệu HDFS . Tuy nhiên, đây cũng là tùy chọn khôi phục ít mong muốn nhất vì nó yêu cầu ngừng hoạt động kéo dài trong khi bạn sao chép toàn bộ cấu trúc dữ liệu trở lại cụm sản xuất của mình và như đã đề cập trước đó, .META. có thể không đồng bộ.
Kết luận
Tóm lại, việc khôi phục dữ liệu sau một số dạng mất mát hoặc ngừng hoạt động đòi hỏi một kế hoạch BDR được thiết kế tốt. Tôi thực sự khuyên bạn nên hiểu kỹ các yêu cầu kinh doanh của mình về thời gian hoạt động, độ chính xác / tính khả dụng của dữ liệu và khôi phục sau thảm họa. Được trang bị kiến thức chi tiết về các yêu cầu kinh doanh của mình, bạn có thể cẩn thận lựa chọn các công cụ đáp ứng tốt nhất các nhu cầu đó.
Tuy nhiên, việc lựa chọn các công cụ chỉ là bước khởi đầu. Bạn nên chạy các thử nghiệm quy mô lớn đối với chiến lược BDR của mình để đảm bảo rằng nó hoạt động đúng chức năng trong cơ sở hạ tầng của bạn, đáp ứng nhu cầu kinh doanh của bạn và rằng các nhóm vận hành của bạn đã rất quen thuộc với các bước cần thiết trước khi xảy ra sự cố và bạn tìm ra cách khó kế hoạch BDR của bạn sẽ không hoạt động.
Nếu bạn muốn nhận xét hoặc thảo luận thêm về chủ đề này, hãy sử dụng diễn đàn cộng đồng của chúng tôi dành cho HBase.
Đọc thêm:
- Bản trình bày của Jon Hsieh’s Strata + Hadoop World 2012
- HBase:Hướng dẫn Cuối cùng (Lars George)
- HBase In Action (Nick Dimiduk / Amandeep Khurana)



