Tìm hiểu về kiến trúc nhập dữ liệu gần thời gian thực để chuyển đổi và làm phong phú các luồng dữ liệu bằng Apache Flume, Apache Kafka và RocksDB tại Santander UK.
Cloudera Professional Services đã làm việc với Santander Vương quốc Anh để xây dựng hệ thống phân tích giao dịch gần thời gian thực (NRT) trên Apache Hadoop. Mục tiêu là nắm bắt, chuyển đổi, làm giàu, đếm và lưu trữ một giao dịch trong vòng vài giây sau khi thực hiện mua thẻ. Hệ thống nhận các giao dịch thẻ khách hàng bán lẻ của ngân hàng và tính toán thông tin xu hướng liên quan được tổng hợp bởi chủ tài khoản và qua một số thứ nguyên và phân loại. Sau đó, thông tin này được cung cấp một cách an toàn tới ứng dụng “Spendlytics” của Santander (xem bên dưới) để cho phép khách hàng phân tích các kiểu chi tiêu mới nhất của họ.
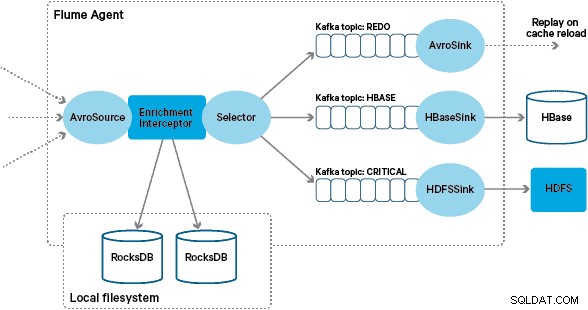
Apache HBase được chọn làm giải pháp lưu trữ cơ bản vì khả năng hỗ trợ ghi ngẫu nhiên thông lượng cao và đọc ngẫu nhiên có độ trễ thấp. Tuy nhiên, yêu cầu NRT loại trừ việc thực hiện các chuyển đổi và làm phong phú các giao dịch theo lô, vì vậy chúng phải được thực hiện trong khi các giao dịch được truyền trực tuyến vào HBase. Điều này bao gồm việc chuyển đổi các thông điệp từ XML sang Avro và làm phong phú chúng bằng thông tin có xu hướng, chẳng hạn như thông tin thương hiệu và người bán.
Bài đăng này mô tả cách Santander sử dụng Apache Flume, Apache Kafka và RocksDB để chuyển đổi, phong phú hóa và truyền trực tuyến các giao dịch vào HBase. Đây là cách triển khai Xử lý sự kiện NRT với bối cảnh bên ngoài mô hình phát trực tuyến được Ted Malaska mô tả trong bài đăng này.
Flafka
Quyết định đầu tiên mà Santander phải đưa ra là cách tốt nhất để truyền dữ liệu vào HBase. Flume hầu như luôn là sự lựa chọn tốt nhất để truyền trực tuyến quá trình nhập vào Hadoop do tính đơn giản, độ tin cậy, nhiều nguồn và phần chìm phong phú cũng như khả năng mở rộng vốn có.
Gần đây, khả năng tích hợp tuyệt vời vào Kafka đã được thêm vào dẫn đến cái tên chắc chắn là Flafka. Flume nguyên bản có thể cung cấp phân phối sự kiện được đảm bảo thông qua kênh tệp của nó, nhưng khả năng phát lại các sự kiện và tính linh hoạt bổ sung và khả năng kiểm soát trong tương lai mà Kafka mang lại là động lực chính cho việc tích hợp.
Trong kiến trúc này, Santander sử dụng các kênh Kafka để cung cấp một bộ đệm nhập đáng tin cậy, tự cân bằng và có thể mở rộng, trong đó tất cả các chuyển đổi và xử lý được thể hiện trong các chủ đề Kafka theo chuỗi. Đặc biệt, chúng tôi sử dụng rộng rãi nguồn và thiết bị chìm của Flafka cũng như khả năng của Flume để thực hiện xử lý trong chuyến bay bằng Thiết bị đánh chặn. Điều này giúp chúng tôi không phải viết mã nhà sản xuất và người tiêu dùng Kafka của riêng mình, đồng thời cho phép Santander tận dụng toàn bộ lợi thế của Trình quản lý Cloudera để định cấu hình, triển khai và giám sát các đại lý và nhà môi giới.
Chuyển đổi
Các giao dịch được hệ thống ngân hàng lõi nắm bắt được chuyển đến Flume dưới dạng thông điệp XML, được đọc từ cơ sở dữ liệu nguồn thông qua bản sao nhật ký. (Điều chỉnh nhật ký cơ sở dữ liệu thành các chủ đề Kafka theo cách này là một mẫu ngày càng phổ biến và kết hợp với nén nhật ký, có thể cung cấp “chế độ xem gần đây nhất” của cơ sở dữ liệu để thay đổi các trường hợp sử dụng thu thập dữ liệu.)
Flume lưu trữ các thông điệp XML này trong một chủ đề Kafka "thô". Từ đây, và là tiền thân của tất cả các quá trình xử lý khác, nó đã được quyết định chuyển đổi XML bán cấu trúc thành các bản ghi nhị phân có cấu trúc để tạo điều kiện thuận lợi cho quá trình xử lý xuôi dòng được chuẩn hóa. Quá trình xử lý này được thực hiện bởi một Flume Interceptor tùy chỉnh chuyển đổi các thông điệp XML thành một biểu diễn Avro chung, áp dụng các kiểu cụ thể nếu thích hợp và trở lại biểu diễn chuỗi nếu không. Tất cả các quá trình xử lý NRT tiếp theo sau đó sẽ lưu trữ các kết quả thu được trong Avro trong các chủ đề Kafka chuyên dụng, giúp bạn dễ dàng khai thác luồng và nhận nguồn cấp dữ liệu sự kiện tại bất kỳ thời điểm nào trong chuỗi xử lý.
Nếu yêu cầu xử lý sự kiện phức tạp hơn – ví dụ như tổng hợp với Spark Streaming – sẽ là một vấn đề nhỏ nếu sử dụng một hoặc nhiều chủ đề này và xuất bản lên các chủ đề mới bắt nguồn. (Apache Avro là một lựa chọn tự nhiên cho định dạng này:nó là một giao thức nhị phân nhỏ gọn hỗ trợ sự phát triển giản đồ, có định nghĩa giản đồ linh hoạt và được hỗ trợ trong toàn bộ ngăn xếp Hadoop. Avro đang nhanh chóng trở thành một tiêu chuẩn thực tế để lưu trữ dữ liệu tạm thời và dữ liệu chung trong một trung tâm dữ liệu doanh nghiệp và được đặt hoàn hảo để chuyển đổi thành Apache Parquet cho khối lượng công việc phân tích.)
Làm giàu
Cảm hứng cho việc thiết kế giải pháp tăng cường phát trực tuyến đến từ một bài đăng trên O’Reilly Radar do Jay Kreps viết. Trong bài đăng của mình, Jay mô tả lợi ích của việc sử dụng cửa hàng cục bộ để cho phép bộ xử lý luồng truy vấn hoặc sửa đổi trạng thái cục bộ để phản hồi đầu vào của nó, trái ngược với việc thực hiện các cuộc gọi từ xa đến cơ sở dữ liệu phân tán.
Tại Santander, chúng tôi đã điều chỉnh mô hình này để cung cấp các cửa hàng tham chiếu địa phương được sử dụng để truy vấn và làm phong phú thêm các giao dịch khi chúng truyền qua Flume. Tại sao không chỉ sử dụng HBase làm kho tham chiếu? Chà, một mô hình điển hình cho loại vấn đề này là chỉ cần lưu trữ trạng thái trong HBase và có cơ chế làm giàu truy vấn trực tiếp. Chúng tôi đã quyết định chống lại cách tiếp cận này vì một vài lý do. Đầu tiên, dữ liệu tham chiếu tương đối nhỏ và sẽ vừa với một vùng HBase duy nhất, có thể gây ra điểm phát sóng trong vùng. Thứ hai, HBase phục vụ ứng dụng Spendlytics hướng tới khách hàng và Santander không muốn tải thêm ảnh hưởng đến độ trễ của ứng dụng hoặc ngược lại. Đây cũng là lý do tại sao chúng tôi quyết định không sử dụng HBase để khởi động các cửa hàng địa phương khi khởi động.
Vì vậy, bằng cách cung cấp cho mỗi Đại lý Flume một cửa hàng địa phương nhanh chóng để làm phong phú thêm các sự kiện trên chuyến bay, Santander có thể đảm bảo hiệu suất tốt hơn cho cả việc bổ sung trên chuyến bay và ứng dụng Spendlytics. Chúng tôi quyết định sử dụng RocksDB để triển khai các cửa hàng cục bộ vì nó có thể cung cấp quyền truy cập nhanh vào lượng lớn dữ liệu off-heap (loại bỏ gánh nặng cho GC) và thực tế là nó có API Java để giúp việc sử dụng dễ dàng hơn từ một thiết bị đánh chặn ống khói tùy chỉnh. Cách tiếp cận này đã giúp chúng tôi không phải viết mã cửa hàng off-heap của riêng mình. RocksDB có thể dễ dàng được hoán đổi để triển khai một cửa hàng địa phương khác, nhưng trong trường hợp này, nó hoàn toàn phù hợp với trường hợp sử dụng của Santander.
Việc triển khai Bộ đánh chặn làm giàu Flume tùy chỉnh xử lý các sự kiện từ chủ đề "đã chuyển đổi" ở thượng nguồn, truy vấn cửa hàng cục bộ của nó để làm phong phú chúng và ghi kết quả vào các chủ đề Kafka ở hạ lưu tùy thuộc vào kết quả. Quá trình này được minh họa chi tiết hơn bên dưới.
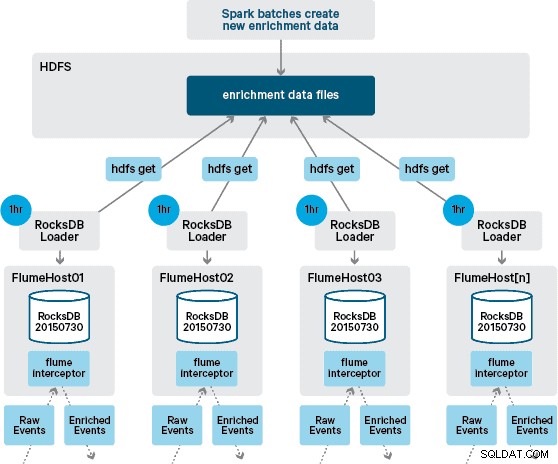
Tại thời điểm này, bạn có thể tự hỏi:Nếu không có sự bền bỉ do HBase cung cấp, các cửa hàng cục bộ được tạo ra như thế nào? Dữ liệu tham chiếu bao gồm một số bộ dữ liệu khác nhau cần được kết hợp với nhau. Các tập dữ liệu này được làm mới trong HDFS hàng ngày và tạo thành đầu vào cho ứng dụng Apache Spark đã lên lịch, ứng dụng này sẽ tạo ra các cửa hàng RocksDB. Các cửa hàng RocksDB mới được tạo được tổ chức trong HDFS cho đến khi chúng được tải xuống bởi Flume Agents để đảm bảo rằng luồng sự kiện đang được bổ sung thêm thông tin mới nhất.
Tốt nhất, chúng tôi sẽ không phải đợi tất cả các bộ dữ liệu này có sẵn trong HDFS trước khi chúng có thể được xử lý. Nếu đúng như vậy, thì các bản cập nhật dữ liệu tham chiếu có thể được truyền trực tuyến qua đường ống Flafka để liên tục duy trì trạng thái dữ liệu tham chiếu cục bộ.
Trong thiết kế ban đầu, chúng tôi đã lên kế hoạch viết và lên lịch thông qua cron a script để thăm dò ý kiến HDFS để kiểm tra các phiên bản mới của cửa hàng RocksDB, tải xuống từ HDFS khi có sẵn. Mặc dù do các kiểm soát nội bộ và quản lý môi trường sản xuất của Santander, cơ chế này phải được kết hợp vào cùng một Flume Interceptor được sử dụng để thực hiện việc bổ sung (nó kiểm tra các bản cập nhật một lần mỗi giờ, vì vậy nó không phải là một hoạt động tốn kém). Khi có phiên bản mới của cửa hàng, một nhiệm vụ sẽ được gửi đến một chuỗi công nhân để tải xuống cửa hàng mới từ HDFS và tải nó vào RocksDB. Quá trình này xảy ra trong nền trong khi Bộ đánh chặn làm giàu tiếp tục xử lý luồng. Khi phiên bản mới của cửa hàng được tải vào RocksDB, Interceptor sẽ chuyển sang phiên bản mới nhất và cửa hàng đã hết hạn sẽ bị xóa. Cơ chế tương tự được sử dụng để khởi động các kho lưu trữ RocksDB từ một lần khởi động nguội trước khi Interceptor bắt đầu cố gắng làm phong phú thêm các sự kiện.
Các tin nhắn đã được bổ sung chi tiết thành công được viết cho một chủ đề Kafka để được viết một cách lý tưởng cho HBase bằng cách sử dụng HBaseEventSerializer.
Trong khi luồng sự kiện được xử lý liên tục, các phiên bản mới của cửa hàng địa phương chỉ có thể được tạo hàng ngày. Ngay sau khi Flume tải một phiên bản mới của cửa hàng địa phương, nó được coi là mới ”, mặc dù nó ngày càng trở nên cũ kỹ trước khi có phiên bản mới. Do đó, số lượng "lỗi bộ nhớ cache" tăng lên cho đến khi có phiên bản mới hơn của cửa hàng cục bộ. Ví dụ:thông tin thương hiệu và người bán mới và cập nhật có thể được thêm vào dữ liệu tham khảo, nhưng cho đến khi nó được cung cấp cho các giao dịch của Flume's Interceptor làm giàu có thể không được bổ sung hoặc được bổ sung bằng thông tin lỗi thời mà sau này phải được được điều chỉnh sau khi nó vẫn tồn tại trong HBase.
Để xử lý trường hợp này, các lần bỏ sót bộ nhớ cache (các sự kiện không được làm giàu) được ghi vào chủ đề Kafka “làm lại” bằng cách sử dụng Flume Selector. Chủ đề làm lại sau đó được phát lại thành chủ đề nguồn của Interceptor làm giàu khi có cửa hàng địa phương mới.
Để ngăn chặn "thông báo độc" (các sự kiện liên tục không làm giàu), chúng tôi quyết định thêm bộ đếm vào tiêu đề của sự kiện trước khi thêm nó vào chủ đề làm lại. Các sự kiện liên tục xuất hiện về chủ đề đó cuối cùng được chuyển hướng đến chủ đề “quan trọng”, chủ đề này được gửi tới HDFS để kiểm tra và khắc phục sau này. Cách tiếp cận này được minh họa trong sơ đồ đầu tiên.
Kết luận
Để tóm tắt những điểm đáng lưu ý chính từ bài đăng này:
- Sử dụng một chuỗi các chủ đề Kafka để lưu trữ dữ liệu được chia sẻ trung gian như một phần của quy trình nhập của bạn là một mô hình hiệu quả.
- Bạn có nhiều tùy chọn cho trạng thái duy trì và truy vấn hoặc dữ liệu tham chiếu trong đường dẫn nhập NRT của mình. Ủng hộ HBase cho mục đích này như một mô hình phổ biến khi dữ liệu bổ sung lớn, nhưng hãy cân nhắc việc sử dụng các kho lưu trữ cục bộ được nhúng (chẳng hạn như RocksDB) hoặc bộ nhớ JVM khi sử dụng HBase là không thực tế.
- Xử lý lỗi rất quan trọng. (Xem # 1 để được trợ giúp về điều đó.)
Trong một bài đăng tiếp theo, chúng tôi sẽ mô tả cách chúng tôi sử dụng bộ đồng xử lý HBase để cung cấp cho mỗi khách hàng tổng hợp các xu hướng mua hàng trước đây và cách các giao dịch ngoại tuyến được xử lý hàng loạt bằng cách sử dụng SparkOnHBase (dự án Cloudera Labs) (gần đây đã được cam kết vào Thân HBase). Chúng tôi cũng sẽ mô tả cách giải pháp được thiết kế để đáp ứng các yêu cầu về tính khả dụng cao, trung tâm dữ liệu của khách hàng.
James Kinley, Ian Buss và Rob Siwicki là Kiến trúc sư giải pháp tại Cloudera.



