Tôi không biết bất kỳ cách nào để nắm bắt tên tệp trong các tham số truy cập. Để giải quyết vấn đề này, thay vì sửa đổi các tệp gốc, bạn có thể sử dụng bộ xử lý trước để nối tên tệp một cách nhanh chóng. Nếu bạn có hai tệp, hãy nói file_1.csv chứa a,b,1 và file_2.csv chứa c,d,2 , bạn có thể có một tập lệnh shell nhỏ như append_filename.sh :
#!/bin/bash
while read line
do
printf "%s,%s\n" "${line}" "${1##*/}"
done < $1
mà bạn có thể xác minh có hữu ích không bằng cách gọi trực tiếp tập lệnh:
$ ./append_filename.sh file_1.csv
a,b,1,file_1.csv
Sau đó, bạn có thể xác định bảng bên ngoài của mình để gọi bảng đó qua preprocessor mệnh đề, một cái gì đó như:
create table e42 (
col1 varchar2(10),
col2 varchar2(10),
col3 number,
filename varchar2(30)
)
organization external (
type oracle_loader
default directory d42
access parameters (
records delimited by newline
preprocessor 'append_filename.sh'
fields terminated by ','
)
location ('file_1.csv', 'file_2.csv')
);
Table E42 created.
Sau đó, tên tệp được chọn tự động:
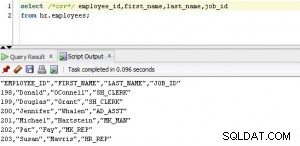
select * from e42;
COL1 COL2 COL3 FILENAME
---------- ---------- ---------- ------------------------------
a b 1 file_1.csv
c d 2 file_2.csv
Tôi đã loại bỏ đường dẫn thư mục để bạn chỉ thấy tên tệp - bạn có thể giữ lại đường dẫn đầy đủ nếu muốn, nhưng điều đó có thể không cần thiết và có thể tiết lộ chi tiết hệ điều hành cho những người chỉ có thể truy vấn bảng. Lưu ý các nguyên tắc bảo mật; Tôi đã giữ nó đơn giản ở đây bằng cách sử dụng một thư mục cho mọi thứ, nhưng bạn nên đặt bộ tiền xử lý ở một nơi khác. Và tất nhiên đây là giả sử nền tảng Unix-y hoặc các công cụ GNU; một cái gì đó tương tự sẽ có thể thực hiện được với một tệp loạt nếu bạn đang sử dụng Windows.
Cách tiếp cận này đọc từng dòng sẽ tương đối chậm đối với các tệp lớn; với một tệp thử nghiệm 1,5 triệu hàng, việc nối tên tệp mất khoảng 80 giây trên nền tảng của tôi. Các công cụ tích hợp khác sẽ nhanh hơn; phiên bản này với sed chỉ mất hơn một giây cho cùng một tệp:
#!/bin/bash
sed -e 's!$!,'"${1##*/}"'!' $1
Bạn có thể thử thay thế khác như awk quá; bạn có thể cần phải kiểm tra một số để xem những gì hoạt động tốt nhất (hoặc đủ nhanh) trong môi trường của bạn.