Bạn có thể sử dụng tính toán truy vấn con đệ quy (còn được gọi là CTE đệ quy):
with tmp as (
select t.*,
row_number() over (order by t.id) as rn
from t
),
r (id, n, x, y, rn) as (
select id, n, 0, 0, rn
from tmp
where rn = 1
union all
select tmp.id, tmp.n, r.y - 1, (tmp.n * 2) + r.y - 1, tmp.rn
from r
join tmp on tmp.rn = r.rn + 1
)
select id, n, x, y
from r
order by rn;
ID N X Y
---------- ---------- ---------- ----------
2 0 0 0
3 1 -1 1
5 1 0 2
7 2 1 5
11 3 4 10
13 5 9 19
17 8 18 34
19 13 33 59
Về cơ bản, nó đi qua các bước thủ công của bạn. Thành viên liên kết là bước thủ công đầu tiên của bạn, thiết lập x và y cả về 0 cho hàng đầu tiên. Sau đó thành viên đệ quy thực hiện phép tính mà bạn đã chỉ định. (Bạn không thể tham khảo x mới được tính giá trị khi tính toán y của hàng đó , vì vậy bạn phải lặp lại điều đó dưới dạng (tmp.n * 2) + r.y - 1 ). rn chỉ là giữ cho các hàng được sắp xếp theo ID trong khi giúp tìm hàng tiếp theo dễ dàng hơn - vì vậy bạn có thể tìm rn + 1 thay vì tìm trực tiếp giá trị ID cao nhất tiếp theo.
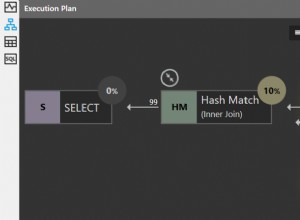
Không có sự khác biệt đáng kể về hiệu suất với dữ liệu mẫu của bạn, nhưng với một nghìn hàng được thêm vào, mệnh đề mô hình mất khoảng 5 giây và CTE đệ quy mất khoảng 1 giây; với mô hình nghìn hàng khác mất ~ 20 giây và CTE mất ~ 3 giây; với mô hình nghìn hàng khác mất ~ 40 giây và CTE mất ~ 6 giây; và với một nghìn hàng khác (tổng cộng là 4,008) mô hình mất ~ 75 giây và CTE mất ~ 10 giây. (Tôi đã chán khi chờ đợi phiên bản mô hình có nhiều hàng hơn thế; giết nó sau năm phút với 10.000). Tôi thực sự không thể nói điều này sẽ hoạt động như thế nào với dữ liệu thực của bạn, nhưng trên cơ sở đó, nó có thể đáng để thử.