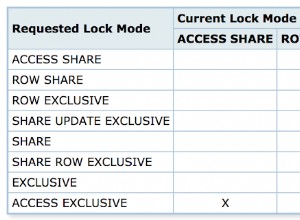
Trước hết, tôi tin rằng nhiệm vụ của bạn có thể được thực hiện (và thực sự nên như vậy) với SQL chắc chắn. Không có con trỏ ưa thích, không có vòng lặp, chỉ cần chọn, chèn và cập nhật. Tôi sẽ bắt đầu với việc bỏ chia dữ liệu nguồn của bạn (không rõ bạn có khóa chính để kết hợp hai tập hợp hay không, tôi đoán là bạn có):
Col0_PK Col1 Col2 Col3 Col4
----------------------------------------
Row1_val A B C D
Row2_val E F G H
Trên đây là dữ liệu nguồn của bạn. Sử dụng UNPIVOT mệnh đề
chúng tôi chuyển đổi nó thành:
Col0_PK Col_Name Col_Value
------------------------------
Row1_val Col1 A
Row1_val Col2 B
Row1_val Col3 C
Row1_val Col4 D
Row2_val Col1 E
Row2_val Col2 F
Row2_val Col3 G
Row2_val Col4 H
Tôi nghĩ rằng bạn có được ý tưởng. Giả sử chúng ta có table1 với một tập dữ liệu và table2 có cấu trúc tương tự với tập dữ liệu thứ hai. Bạn nên sử dụng các bảng được tổ chức theo chỉ mục.
Bước tiếp theo là so sánh các hàng với nhau và lưu trữ các chi tiết khác biệt. Một cái gì đó như:
insert into diff_details(some_service_info_columns_here)
select some_service_info_columns_here_along_with_data_difference
from table1 t1 inner join table2 t2
on t1.Col0_PK = t2.Col0_PK
and t1.Col_name = t2.Col_name
and nvl(t1.Col_value, 'Dummy1') <> nvl(t2.Col_value, 'Dummy2');
Và ở bước cuối cùng, chúng tôi cập nhật bảng tóm tắt sự khác biệt:
insert into diff_summary(summary_columns_here)
select diff_row_id, count(*) as diff_count
from diff_details
group by diff_row_id;
Nó chỉ là bản nháp sơ bộ để thể hiện cách tiếp cận của tôi, tôi chắc chắn rằng còn nhiều chi tiết cần được tính đến. Để tóm tắt, tôi đề nghị hai điều:
-
UNPIVOTdữ liệu - Sử dụng
SQLcâu lệnh thay vì con trỏ