Tôi sẽ bắt đầu với câu hỏi thứ hai, dễ hơn. Sử dụng dplyr gói, bạn có thể sử dụng top_n để lấy n hàng lớn nhất cho một cột nhất định. Ví dụ:
> top_n(p_ash_r_100a, 3, SMPL_CNT) %>% arrange(desc(SMPL_CNT))
# A tibble: 3 × 5
SMPL_TIME SQL_ID MODULE EVENT SMPL_CNT
<dttm> <chr> <chr> <chr> <int>
1 2017-04-11 09:01:00 NO_SQL GoldenGate CPU 7
2 2017-04-11 09:00:00 dgzp3at57cagd GoldenGate db file sequential read 2
3 2017-04-11 09:01:00 37cspa0acgqxp GoldenGate db file sequential read 2
Lưu ý rằng bạn sẽ nhận được nhiều hơn n hàng nếu có ràng buộc cho vị trí thứ n. Do đó top_n(p_ash_r_100, 10, SMPL_CNT) sẽ trả về toàn bộ tập dữ liệu mẫu do ràng buộc 17 chiều cho thứ 4.
Đối với câu hỏi đầu tiên, tài liệu cho geom_area cung cấp manh mối:
Điều này cho thấy rằng geom_area mong rằng cột được ánh xạ tới x phải là số. Dựa trên danh sách cho p_ash_r_100 , SMPL_TIME dường như là một vectơ ký tự. Với lubridate gói, chúng tôi có thể chuyển đổi SMPL_TIME đến một ngày-giờ với dmy_hm :
p_ash_r_100a <- p_ash_r_100 %>%
mutate_at(vars(SMPL_TIME), dmy_hm)
Tuy nhiên, điều này không đủ để có được cốt truyện bạn muốn vì có nhiều giá trị của y cho mỗi kết hợp x và fill (thẩm mỹ chính xác cho geom_area , không phải "col "). Chúng tôi cần tóm tắt dữ liệu trước khi vẽ biểu đồ:
p_ash_r_100a %>%
group_by(SMPL_TIME, EVENT) %>%
summarise(total = sum(SMPL_CNT)) %>%
ggplot(aes(SMPL_TIME, total, fill = EVENT)) +
geom_area()
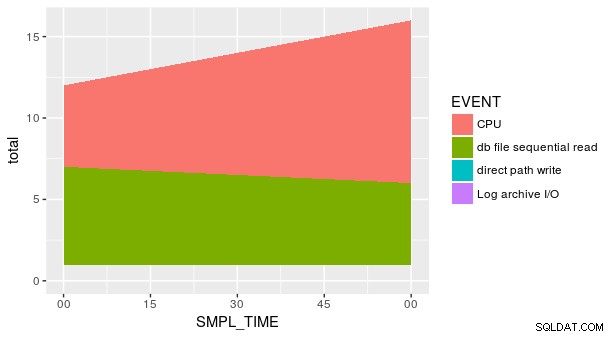
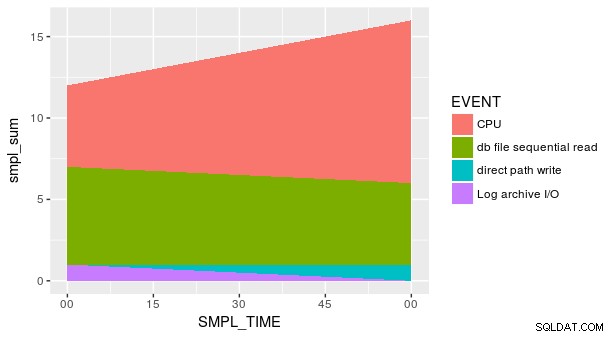
Tuy nhiên, cốt truyện vẫn không đúng. Điều này là do mọi kết hợp của SMPL_TIME và EVENT không được đại diện trong tập dữ liệu. Chúng ta cần nói rõ ràng với geom_area y đó bằng 0 cho các hàng bị thiếu đó. Một cách là sử dụng fill tiện dụng đối số trong tidyr::spread .
group_by(p_ash_r_100a, SMPL_TIME, EVENT) %>%
summarise(smpl_sum = sum(SMPL_CNT)) %>%
spread(EVENT, smpl_sum, fill = 0) %>%
gather(EVENT, smpl_sum, CPU, `db file sequential read`,
`direct path write`,
`Log archive I/O`) %>%
ggplot(aes(x = SMPL_TIME, y = smpl_sum, fill = EVENT)) +
geom_area()