Tôi tiếp tục một loạt bài viết về những kiến thức cơ bản về GIẢI THÍCH trong PostgreSQL, đây là một bài đánh giá ngắn về Hiểu GIẢI THÍCH của Guillaume Lelarge.
Để hiểu rõ hơn về vấn đề này, tôi thực sự khuyên bạn nên xem lại bản gốc “Hiểu GIẢI THÍCH” của Guillaume Lelarge và đọc bài báo đầu tiên và thứ hai của tôi.
ĐẶT HÀNG BỞI
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Đầu tiên, bạn thực hiện quét tuần tự (Seq Scan) bảng foo và sau đó, thực hiện việc sắp xếp (Sort). Dấu -> của lệnh EXPLAIN cho biết thứ bậc của các bước (nút). Bước được thực thi càng sớm, thì bước thụt lề càng lớn.
Khóa sắp xếp là một điều kiện của việc sắp xếp.
Phương pháp sắp xếp:kết hợp bên ngoài Đĩa một tệp tạm thời trên đĩa có dung lượng 4592 kB được sử dụng khi sắp xếp.
Kiểm tra với tùy chọn BUFFERS:
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;
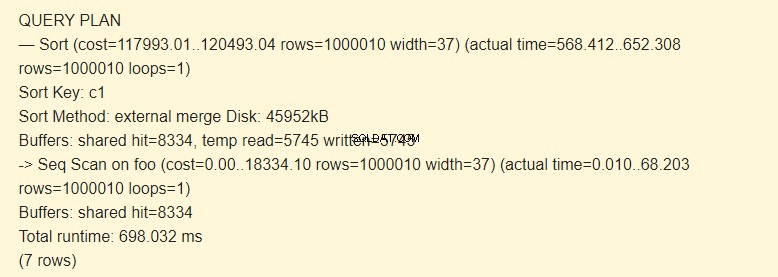
Thật vậy, dòng tạm thời read =5745 write =5745 có nghĩa là 45960Kb (5745 khối 8 Kb mỗi khối) đã được lưu trữ và đọc trong tệp tạm thời. Các hoạt động với 8334 khối đã được thực thi trong bộ nhớ cache.
Các hoạt động với hệ thống tệp chậm hơn các hoạt động trong RAM.
Hãy cố gắng tăng dung lượng bộ nhớ của work_mem:
SET work_mem TO '200MB'; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Phương pháp sắp xếp:nhanh chóng Bộ nhớ:102702kB - toàn bộ việc sắp xếp được thực hiện trong RAM.
Chỉ số như sau:
CREATE INDEX ON foo(c1); EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Chúng tôi chỉ còn lại Quét lập chỉ mục, điều này ảnh hưởng đáng kể đến tốc độ của truy vấn.
GIỚI HẠN
Xóa chỉ mục đã tạo trước đó:
DROP INDEX foo_c2_idx1; EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%';
Như mong đợi, Seq Scan và Filter được sử dụng.
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%' LIMIT 10;

Seq Scan đọc các hàng của bảng và so sánh chúng (Bộ lọc) với điều kiện. Ngay sau khi có 10 bản ghi đáp ứng điều kiện, quá trình quét sẽ kết thúc. Trong trường hợp của chúng tôi, để có được 10 hàng kết quả, chúng tôi chỉ phải đọc 3063 bản ghi chứ không phải toàn bộ bảng. 3053 hàng trong số này đã bị từ chối (Hàng được Bộ lọc xóa).
Điều tương tự cũng xảy ra với Quét chỉ mục.
THAM GIA
Tạo một bảng mới và tạo thống kê cho nó:
CREATE TABLE bar (c1 integer, c2 boolean); INSERT INTO bar SELECT i, i%2=1 FROM generate_series(1, 500000) AS i; ANALYZE bar;
Truy vấn cho hai bảng như sau:
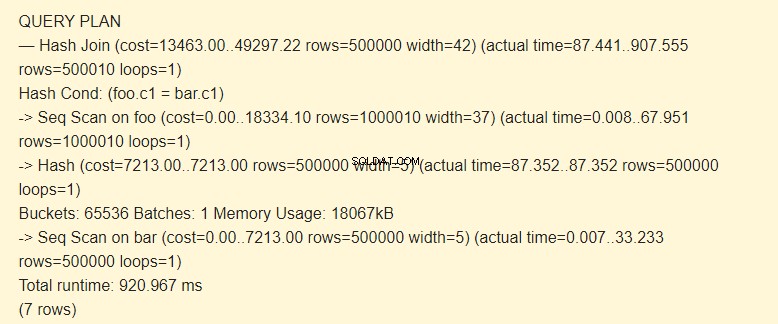
EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;
Đầu tiên, quét tuần tự (Seq Scan) đọc bảng thanh. Một hàm băm (Hash) được tính cho mỗi hàng.
Sau đó, nó quét bảng foo và đối với mỗi hàng, một hàm băm được tính toán được so sánh (Hash Join) với hàm băm của bảng thanh theo điều kiện Hash Cond. Nếu chúng khớp nhau, một chuỗi kết quả sẽ được xuất ra.
18067kB bộ nhớ được sử dụng để lưu trữ các hàm băm cho thanh.
Thêm chỉ mục:
CREATE INDEX ON bar(c1); EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;

Hash không còn được sử dụng. Hợp nhất Tham gia và Quét chỉ mục trên các chỉ mục của cả hai bảng cải thiện hiệu suất rất nhiều.
THAM GIA TRÁI:
EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
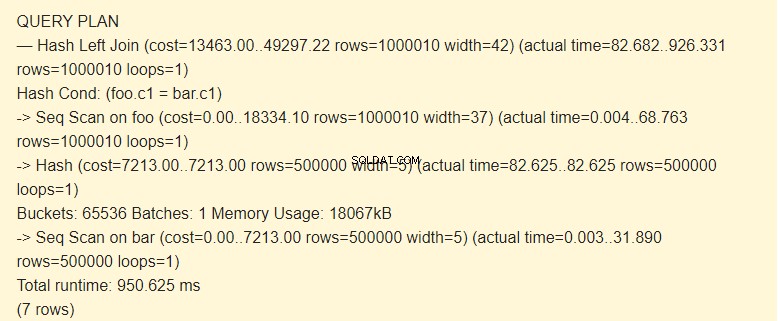
Quét Seq?
Hãy xem chúng ta sẽ có kết quả gì nếu chúng ta vô hiệu hóa Seq Scan.
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Theo bộ lập lịch, việc sử dụng các chỉ mục sẽ tốn kém hơn so với việc sử dụng hàm băm. Điều này có thể thực hiện được với một lượng bộ nhớ được cấp phát đủ lớn. Bạn có nhớ chúng tôi đang tăng work_mem không?
Tuy nhiên, nếu bạn không có đủ bộ nhớ, bộ lập lịch sẽ hoạt động khác:
SET work_mem TO '15MB'; SET enable_seqscan TO ON; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Nếu chúng tôi tắt chức năng Quét chỉ mục, kết quả EXPLAIN sẽ hiển thị là gì?
SET work_mem TO '15MB'; SET enable_indexscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
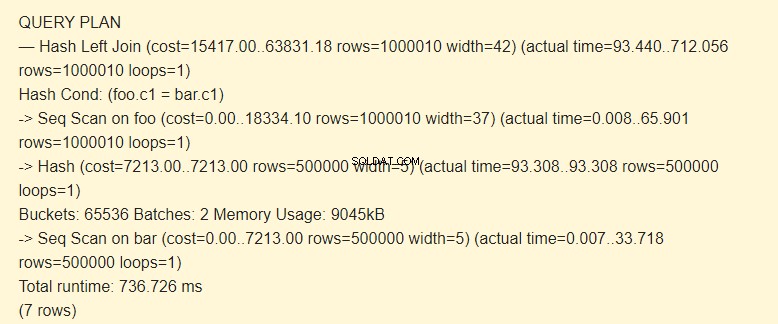
Lô:2 đã tăng chi phí. Toàn bộ hàm băm không vừa với bộ nhớ; chúng tôi đã phải chia nó thành hai gói 9045kB.
Cảm ơn bạn đã đọc những bài viết của tôi! Tôi hy vọng chúng hữu ích. Nếu bạn có bất kỳ nhận xét hoặc phản hồi nào, vui lòng cho tôi biết.