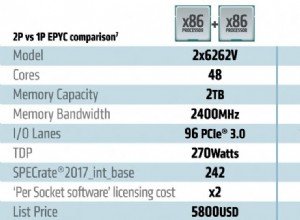
Nói chung, có không nhược điểm của việc sử dụng text về hiệu suất / bộ nhớ. Ngược lại:text là tối ưu. Các loại khác ít nhiều có nhược điểm liên quan. text theo nghĩa đen là kiểu "được ưu tiên" trong số các kiểu chuỗi trong hệ thống kiểu Postgres, có thể ảnh hưởng đến độ phân giải kiểu hàm hoặc toán tử.
Đặc biệt, không bao giờ sử dụng (bí danh cho char(n) ), trừ khi bạn biết mình đang làm gì. character(n) char hoặc character chỉ là viết tắt của character(1) , vì vậy tất cả đều giống nhau. Tên nội bộ là bpchar (viết tắt của "ký tự đệm trống"). Loại chỉ có ở đó để tương thích với mã và tiêu chuẩn cũ. Ngày nay, nó rất ít có ý nghĩa, lãng phí bộ nhớ và có thể gây ra sự cố:
- So sánh varchar với char
- Độ dài trường chuỗi trong Postgres SQL
Bạn có thể sử dụng varchar(n) với công cụ sửa đổi độ dài (bí danh cho character varying(n) ). Nhưng thường chỉ ra một sự hiểu lầm được chuyển sang từ các RDBMS khác, nơi nó có thể là điểm tối ưu cục bộ cho hiệu suất. Trong Postgres, công cụ sửa đổi độ dài varchar(255) (255) không có ý nghĩa đặc biệt và hiếm khi có ý nghĩa.
- Tôi có nên thêm giới hạn độ dài tùy ý cho các cột VARCHAR không?
Các phiên bản cũ hơn gây ra nhiều sự cố khác nhau khi cố gắng thay đổi công cụ sửa đổi độ dài của varchar(n) một lát sau. Hầu hết những điều đó đã được giảm bớt trong Postgres hiện đại, nhưng text hoặc varchar (bí danh cho character varying ) không có mã xác định độ dài (và CHECK thay vào đó) không bao giờ có bất kỳ vấn đề nào trong số này.
CHECK ràng buộc cũng nhanh chóng và ít có khả năng gây ra rắc rối với các khung nhìn, chức năng, ràng buộc FK, v.v. phụ thuộc vào loại cột. Và nó có thể làm được nhiều việc hơn là chỉ thực thi độ dài ký tự tối đa - bất cứ thứ gì bạn có thể đưa vào biểu thức boolean. Xem:
- Thay đổi các cột PostgreSQL được sử dụng trong các chế độ xem
Cuối cùng, còn có "char" (với dấu ngoặc kép):kiểu dữ liệu 1 byte cho một chữ cái ASCII duy nhất được sử dụng làm kiểu liệt kê nội bộ rẻ tiền.
Tôi hiếm khi sử dụng bất cứ thứ gì ngoài text cho dữ liệu ký tự trong Postgres.