Đôi khi thật khó để quản lý một lượng lớn dữ liệu trong một công ty, đặc biệt là với sự gia tăng theo cấp số nhân của việc sử dụng Phân tích dữ liệu và IoT. Tùy thuộc vào kích thước, lượng dữ liệu này có thể ảnh hưởng đến hiệu suất của hệ thống của bạn và bạn có thể sẽ cần phải mở rộng cơ sở dữ liệu của mình hoặc tìm cách khắc phục điều này. Có nhiều cách khác nhau để mở rộng cơ sở dữ liệu PostgreSQL của bạn và một trong số đó là Sharding. Trong blog này, chúng ta sẽ xem Sharding là gì và cách định cấu hình nó trong PostgreSQL bằng cách sử dụng ClusterControl để đơn giản hóa tác vụ.
Sharding là gì?
Sharding là hành động tối ưu hóa cơ sở dữ liệu bằng cách tách dữ liệu từ một bảng lớn thành nhiều bảng nhỏ. Các bảng nhỏ hơn là Shards (hoặc phân vùng). Phân vùng và Sharding là những khái niệm tương tự. Sự khác biệt chính là sharding ngụ ý rằng dữ liệu được trải rộng trên nhiều máy tính trong khi phân vùng là về việc nhóm các tập hợp con dữ liệu trong một phiên bản cơ sở dữ liệu duy nhất.
Có hai loại Sharding:
-
Horizontal Sharding:Mỗi bảng mới có cùng một lược đồ với bảng lớn nhưng các hàng duy nhất. Nó hữu ích khi các truy vấn có xu hướng trả về một tập hợp con các hàng thường được nhóm lại với nhau.
-
Vertical Sharding:Mỗi bảng mới có một giản đồ là một tập con của lược đồ ban đầu. Nó hữu ích khi các truy vấn có xu hướng chỉ trả về một tập hợp con các cột của dữ liệu.
Hãy xem một ví dụ:
Bảng gốc
| ID | Tên | Tuổi | Quốc gia |
|---|---|---|---|
| 1 | James Smith | 26 | Hoa Kỳ |
| 2 | Mary Johnson | 31 | Đức |
| 3 | Robert Williams | 54 | Canada |
| 4 | Jennifer Brown | 47 | Pháp |
Mài theo chiều dọc
| Shard1 | Shard2 | |||
|---|---|---|---|---|
| ID | Tên | Tuổi | ID | Quốc gia |
| 1 | James Smith | 26 | 1 | Hoa Kỳ |
| 2 | Mary Johnson | 31 | 2 | Đức |
| 3 | Robert Williams | 54 | 3 | Canada |
| 4 | Jennifer Brown | 47 | 4 | Pháp |
Mài ngang
| Shard1 | Shard2 | ||||||
|---|---|---|---|---|---|---|---|
| ID | Tên | Tuổi | Quốc gia | ID | Tên | Tuổi | Quốc gia |
| 1 | James Smith | 26 | Hoa Kỳ | 3 | Robert Williams | 54 | Canada |
| 2 | Mary Johnson | 31 | Đức | 4 | Jennifer Brown | 47 | Pháp |
Bây giờ chúng ta đã xem xét một số khái niệm về Sharding, hãy tiến hành bước tiếp theo.
Cách triển khai Cụm PostgreSQL?
Chúng tôi sẽ sử dụng ClusterControl cho tác vụ này. Nếu bạn chưa sử dụng ClusterControl, bạn có thể cài đặt nó và triển khai hoặc nhập cơ sở dữ liệu PostgreSQL hiện tại của mình bằng cách chọn tùy chọn “Nhập” và làm theo các bước để tận dụng tất cả các tính năng của ClusterControl như sao lưu, chuyển đổi dự phòng tự động, cảnh báo, giám sát, v.v. .
Để thực hiện triển khai từ ClusterControl, chỉ cần chọn tùy chọn "Triển khai" và làm theo hướng dẫn xuất hiện.
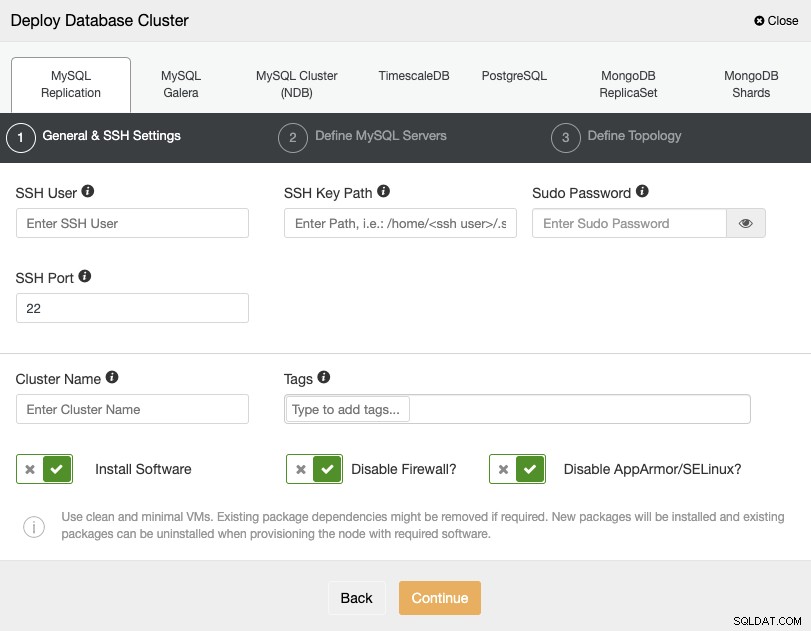
Khi chọn PostgreSQL, bạn phải chỉ định Người dùng, Khóa hoặc Mật khẩu và Cổng kết nối bằng SSH với máy chủ của bạn. Bạn cũng có thể thêm tên cho cụm mới của mình và nếu muốn, bạn cũng có thể sử dụng ClusterControl để cài đặt phần mềm và cấu hình tương ứng cho bạn.
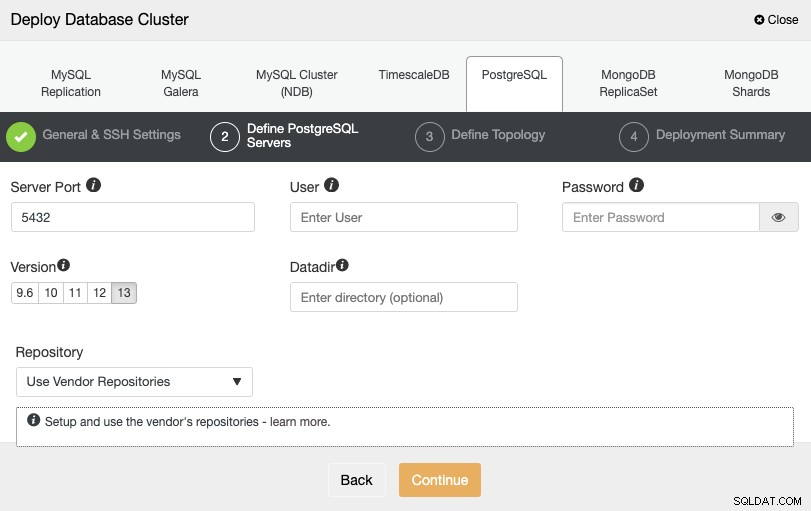
Sau khi thiết lập thông tin truy cập SSH, bạn cần xác định thông tin đăng nhập cơ sở dữ liệu , phiên bản và datadir (tùy chọn). Bạn cũng có thể chỉ định kho lưu trữ nào sẽ sử dụng.
Đối với bước tiếp theo, bạn cần thêm máy chủ của mình vào cụm mà bạn sẽ tạo bằng Địa chỉ IP hoặc Tên máy chủ.
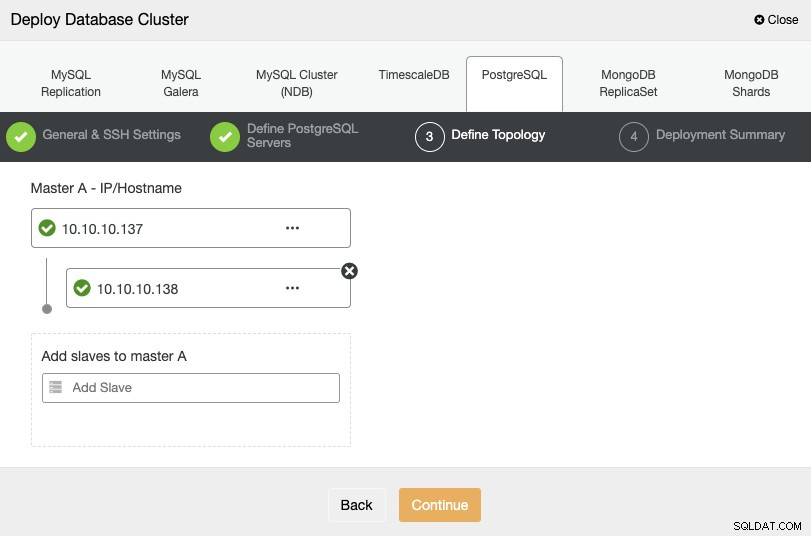
Trong bước cuối cùng, bạn có thể chọn xem bản sao của mình sẽ là Đồng bộ hay Không đồng bộ, sau đó chỉ cần nhấn vào “Triển khai”.
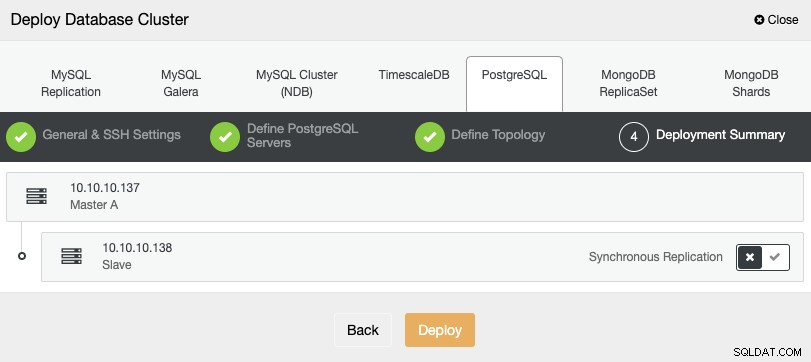
Khi nhiệm vụ hoàn thành, bạn sẽ thấy cụm PostgreSQL mới của mình trong màn hình ClusterControl chính.

Bây giờ bạn đã tạo cụm của mình, bạn có thể thực hiện một số tác vụ trên đó như thêm bộ cân bằng tải (HAProxy), bộ gộp kết nối (pgBouncer) hoặc một bản sao mới.
Lặp lại quy trình để có ít nhất hai cụm PostgreSQL riêng biệt để định cấu hình Sharding, đây là bước tiếp theo.
Cách định cấu hình PostgreSQL Sharding?
Bây giờ chúng ta sẽ cấu hình Sharding bằng PostgreSQL Partitions và Foreign Data Wrapper (FDW). Chức năng này cho phép PostgreSQL truy cập dữ liệu được lưu trữ trong các máy chủ khác. Nó là một phần mở rộng có sẵn theo mặc định trong cài đặt PostgreSQL thông thường.
Chúng tôi sẽ sử dụng môi trường sau:
Servers: Shard1 - 10.10.10.137, Shard2 - 10.10.10.138
Database User: admindb
Table: customersĐể bật tiện ích mở rộng FDW, bạn chỉ cần chạy lệnh sau trong máy chủ chính của mình, trong trường hợp này là Shard1:
postgres=# CREATE EXTENSION postgres_fdw;
CREATE EXTENSIONBây giờ hãy tạo bảng khách hàng được phân chia theo ngày đã đăng ký:
postgres=# CREATE TABLE customers (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL
)
PARTITION BY RANGE (registered);Và các phân vùng sau:
postgres=# CREATE TABLE customers_2021
PARTITION OF customers
FOR VALUES FROM ('2021-01-01') TO ('2022-01-01');
postgres=# CREATE TABLE customers_2020
PARTITION OF customers
FOR VALUES FROM ('2020-01-01') TO ('2021-01-01');Các phân khu này là địa phương. Bây giờ, hãy chèn một số giá trị thử nghiệm và kiểm tra chúng:
postgres=# INSERT INTO customers (id, name, registered) VALUES (1, 'James', '2020-05-01');
postgres=# INSERT INTO customers (id, name, registered) VALUES (2, 'Mary', '2021-03-01');Tại đây bạn có thể truy vấn phân vùng chính để xem tất cả dữ liệu:
postgres=# SELECT * FROM customers;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(2 rows)Hoặc thậm chí truy vấn phân vùng tương ứng:
postgres=# SELECT * FROM customers_2021;
id | name | registered
----+------+------------
2 | Mary | 2021-03-01
(1 row)
postgres=# SELECT * FROM customers_2020;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
(1 row)
Như bạn thấy, dữ liệu được chèn vào các phân vùng khác nhau, theo ngày đã đăng ký. Bây giờ, trong nút từ xa, trong trường hợp này là Shard2, hãy tạo một bảng khác:
postgres=# CREATE TABLE customers_2019 (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL);Bạn cần tạo máy chủ Shard2 này trong Shard1 theo cách sau:
postgres=# CREATE SERVER shard2 FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host '10.10.10.138', dbname 'postgres');Và người dùng để truy cập nó:
postgres=# CREATE USER MAPPING FOR admindb SERVER shard2 OPTIONS (user 'admindb', password 'Passw0rd');Bây giờ, hãy tạo BẢNG NGOẠI GIAO trong Shard1:
postgres=# CREATE FOREIGN TABLE customers_2019
PARTITION OF customers
FOR VALUES FROM ('2019-01-01') TO ('2020-01-01')
SERVER shard2;Và hãy chèn dữ liệu vào bảng từ xa mới này từ Shard1:
postgres=# INSERT INTO customers (id, name, registered) VALUES (3, 'Robert', '2019-07-01');
INSERT 0 1
postgres=# INSERT INTO customers (id, name, registered) VALUES (4, 'Jennifer', '2019-11-01');
INSERT 0 1Nếu mọi thứ suôn sẻ, bạn sẽ có thể truy cập dữ liệu từ cả Shard1 và Shard2:
Shard1:
postgres=# SELECT * FROM customers;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(4 rows)
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)Phân đoạn 2:
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)Thế là xong. Bây giờ bạn đang sử dụng Sharding trong Cụm PostgreSQL của mình.
Kết luận
Phân vùng và Sharding trong PostgreSQL là những tính năng tốt. Nó giúp bạn trong trường hợp bạn cần tách dữ liệu trong một bảng lớn để cải thiện hiệu suất hoặc thậm chí để xóa dữ liệu một cách dễ dàng, trong số các tình huống khác. Một điểm quan trọng khi bạn đang sử dụng Sharding là chọn một khóa phân đoạn tốt để phân phối dữ liệu giữa các nút một cách tốt nhất. Ngoài ra, bạn có thể sử dụng ClusterControl để đơn giản hóa việc triển khai PostgreSQL và tận dụng một số tính năng như giám sát, cảnh báo, chuyển đổi dự phòng tự động, sao lưu, khôi phục tại thời điểm và hơn thế nữa.



