Bạn có đang thắc mắc các lược đồ Postgresql là gì và tại sao chúng lại quan trọng và cách bạn có thể sử dụng các lược đồ để làm cho việc triển khai cơ sở dữ liệu của mình mạnh mẽ hơn và dễ bảo trì hơn? Bài viết này sẽ giới thiệu những điều cơ bản về lược đồ trong Postgresql và hướng dẫn bạn cách tạo chúng với một số ví dụ cơ bản. Các bài viết trong tương lai sẽ đi sâu vào các ví dụ về cách bảo mật và sử dụng lược đồ cho các ứng dụng thực.
Trước tiên, để giải quyết sự nhầm lẫn thuật ngữ tiềm ẩn, hãy hiểu rằng trong thế giới Postgresql, thuật ngữ “lược đồ” có thể hơi quá tải một cách đáng tiếc. Trong ngữ cảnh rộng hơn của hệ quản trị cơ sở dữ liệu quan hệ (RDBMS), thuật ngữ “lược đồ” có thể được hiểu là để chỉ thiết kế logic hoặc vật lý tổng thể của cơ sở dữ liệu, tức là định nghĩa của tất cả các bảng, cột, dạng xem và các đối tượng khác cấu thành định nghĩa cơ sở dữ liệu. Trong ngữ cảnh rộng hơn đó, một lược đồ có thể được thể hiện trong một biểu đồ mối quan hệ-thực thể (ER) hoặc một tập lệnh của các câu lệnh ngôn ngữ định nghĩa dữ liệu (DDL) được sử dụng để khởi tạo cơ sở dữ liệu ứng dụng.
Trong thế giới Postgresql, thuật ngữ “lược đồ” có thể được hiểu rõ hơn là “không gian tên”. Trên thực tế, trong các bảng của hệ thống Postgresql, các lược đồ được ghi lại trong các cột của bảng được gọi là “không gian tên”, IMHO, là thuật ngữ chính xác hơn. Như một vấn đề thực tế, bất cứ khi nào tôi nhìn thấy "lược đồ" trong ngữ cảnh của Postgresql, tôi âm thầm diễn giải lại nó thành "không gian tên".
Nhưng bạn có thể hỏi:"Không gian tên là gì?" Nói chung, không gian tên là một phương tiện khá linh hoạt để tổ chức và xác định thông tin theo tên. Ví dụ, hãy tưởng tượng hai hộ gia đình lân cận, Smiths, Alice và Bob, và Jones, Bob và Cathy (xem Hình 1). Nếu chúng tôi chỉ sử dụng tên riêng, nó có thể gây nhầm lẫn về người mà chúng tôi muốn nói đến khi nói về Bob. Nhưng bằng cách thêm tên họ, Smith hoặc Jones, chúng tôi xác định duy nhất ý của chúng tôi là người nào.
Thông thường, không gian tên được tổ chức theo hệ thống phân cấp lồng nhau. Điều này cho phép phân loại hiệu quả lượng lớn thông tin thành cấu trúc rất chi tiết, chẳng hạn như hệ thống tên miền internet chẳng hạn. Ở cấp cao nhất, “.com”, “.net”, “.org”, “.edu”, v.v. xác định không gian tên rộng trong đó là tên đã đăng ký cho các thực thể cụ thể, chẳng hạn như “vàinines.com” và “postgresql.org” được định nghĩa duy nhất. Nhưng bên dưới mỗi tên miền đó có một số tên miền phụ phổ biến như “www”, “mail” và “ftp” chẳng hạn, chỉ riêng các tên miền này là trùng lặp, nhưng trong các khoảng trống tên tương ứng là duy nhất.
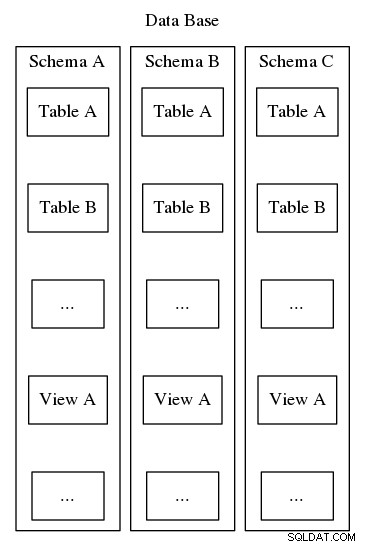
Các lược đồ Postgresql phục vụ cùng mục đích tổ chức và xác định này, tuy nhiên, không giống như ví dụ thứ hai ở trên, các lược đồ Postgresql không thể được lồng trong một hệ thống phân cấp. Mặc dù cơ sở dữ liệu có thể chứa nhiều lược đồ, nhưng chỉ có một mức duy nhất và vì vậy trong cơ sở dữ liệu, tên lược đồ phải là duy nhất. Ngoài ra, mọi cơ sở dữ liệu phải bao gồm ít nhất một lược đồ. Bất cứ khi nào một cơ sở dữ liệu mới được khởi tạo, một lược đồ mặc định có tên là “công khai” sẽ được tạo. Nội dung của một lược đồ bao gồm tất cả các đối tượng cơ sở dữ liệu khác như bảng, dạng xem, thủ tục được lưu trữ, trình kích hoạt, v.v. Để hình dung, hãy tham khảo Hình 2, mô tả một lồng giống như búp bê matryoshka cho thấy nơi các lược đồ phù hợp với cấu trúc của một Cơ sở dữ liệu postgresql.
Bên cạnh việc đơn giản tổ chức các đối tượng cơ sở dữ liệu thành các nhóm hợp lý để làm cho chúng dễ quản lý hơn, các lược đồ còn phục vụ mục đích thực tế là tránh xung đột tên. Một mô hình hoạt động liên quan đến việc xác định một lược đồ cho mỗi người dùng cơ sở dữ liệu để cung cấp một số mức độ riêng biệt, một không gian nơi người dùng có thể xác định các bảng và khung nhìn của riêng họ mà không can thiệp vào nhau. Một cách tiếp cận khác là cài đặt các công cụ của bên thứ ba hoặc phần mở rộng cơ sở dữ liệu trong các lược đồ riêng lẻ để giữ tất cả các thành phần liên quan với nhau một cách hợp lý. Bài viết sau của loạt bài này sẽ trình bày chi tiết một cách tiếp cận mới để thiết kế ứng dụng mạnh mẽ, sử dụng các lược đồ như một phương tiện điều hướng để hạn chế sự tiếp xúc của thiết kế vật lý cơ sở dữ liệu và thay vào đó trình bày một giao diện người dùng giải quyết các khóa tổng hợp và tạo điều kiện cho việc quản lý cấu hình và bảo trì lâu dài khi các yêu cầu hệ thống phát triển.
Hãy làm một số mã!
Tải xuống Báo cáo chính thức hôm nay Quản lý &Tự động hóa PostgreSQL với ClusterControlTìm hiểu về những điều bạn cần biết để triển khai, giám sát, quản lý và mở rộng PostgreSQLTải xuống Báo cáo chính thứcLệnh đơn giản nhất để tạo một lược đồ trong cơ sở dữ liệu là
CREATE SCHEMA hollywood;Lệnh này yêu cầu tạo các đặc quyền trong cơ sở dữ liệu và lược đồ mới được tạo “hollywood” sẽ thuộc sở hữu của người dùng gọi lệnh. Một lời gọi phức tạp hơn có thể bao gồm các phần tử tùy chọn chỉ định một chủ sở hữu khác và thậm chí có thể bao gồm các câu lệnh DDL khởi tạo các đối tượng cơ sở dữ liệu trong lược đồ, tất cả trong một lệnh!
Định dạng chung là
CREATE SCHEMA schemaname [ AUTHORIZATION username ] [ schema_element [ ... ] ]trong đó “tên người dùng” là người sẽ sở hữu lược đồ và “schema_element” có thể là một trong các lệnh DDL nhất định (tham khảo tài liệu Postgresql để biết chi tiết cụ thể). Cần có đặc quyền của người dùng cấp cao để sử dụng tùy chọn AUTHORIZATION.
Vì vậy, ví dụ:để tạo một lược đồ có tên “hollywood” chứa một bảng có tên “phim” và chế độ xem có tên “người chiến thắng” trong một lệnh, bạn có thể thực hiện
CREATE SCHEMA hollywood
CREATE TABLE films (title text, release date, awards text[])
CREATE VIEW winners AS
SELECT title, release FROM films WHERE awards IS NOT NULL;Các đối tượng cơ sở dữ liệu bổ sung sau đó có thể được tạo trực tiếp, ví dụ:một bảng bổ sung sẽ được thêm vào lược đồ với
CREATE TABLE hollywood.actors (name text, dob date, gender text);Lưu ý trong ví dụ trên, tiền tố của tên bảng với tên lược đồ. Điều này là bắt buộc vì theo mặc định, không có đặc tả lược đồ rõ ràng, các đối tượng cơ sở dữ liệu mới được tạo trong bất kỳ lược đồ hiện tại nào, mà chúng ta sẽ đề cập tiếp theo.
Nhớ lại cách trong ví dụ về không gian tên đầu tiên ở trên, chúng ta có hai người tên là Bob, và chúng ta đã mô tả cách tách hoặc phân biệt họ bằng cách bao gồm họ. Nhưng trong mỗi hộ gia đình Smith và Jones riêng biệt, mỗi gia đình hiểu “Bob” để chỉ người đi với hộ gia đình cụ thể đó. Vì vậy, chẳng hạn trong bối cảnh của từng hộ gia đình tương ứng, Alice không cần phải xưng hô chồng mình là Bob Jones và Cathy không cần gọi chồng mình là Bob Smith:mỗi người có thể chỉ nói “Bob”.
Lược đồ hiện tại Postgresql giống như hộ gia đình trong ví dụ trên. Các đối tượng trong lược đồ hiện tại có thể được tham chiếu không đủ tiêu chuẩn, nhưng việc tham chiếu đến các đối tượng có tên tương tự trong các lược đồ khác yêu cầu phải xác định tên bằng cách thêm tiền tố vào tên lược đồ như trên.
Lược đồ hiện tại bắt nguồn từ tham số cấu hình “search_path”. Tham số này lưu trữ danh sách tên lược đồ được phân tách bằng dấu phẩy và có thể được kiểm tra bằng lệnh
SHOW search_path;hoặc đặt thành giá trị mới với
SET search_path TO schema [, schema, ...];Tên lược đồ đầu tiên trong danh sách là "lược đồ hiện tại" và là nơi các đối tượng mới được tạo nếu được chỉ định mà không có điều kiện về tên lược đồ.
Danh sách tên lược đồ được phân tách bằng dấu phẩy cũng dùng để xác định thứ tự tìm kiếm mà hệ thống định vị các đối tượng được đặt tên không đủ tiêu chuẩn hiện có. Ví dụ, trở lại vùng lân cận Smith và Jones, một gói giao hàng chỉ gửi cho “Bob” sẽ yêu cầu đến từng hộ gia đình cho đến khi người dân đầu tiên có tên là “Bob” được tìm thấy. Lưu ý, đây có thể không phải là người nhận dự định. Logic tương tự cũng áp dụng cho Postgresql. Hệ thống tìm kiếm các bảng, dạng xem và các đối tượng khác trong các lược đồ theo thứ tự của đường dẫn tìm kiếm, sau đó đối tượng khớp tên được tìm thấy đầu tiên được sử dụng. Các đối tượng có tên đủ điều kiện của lược đồ được sử dụng trực tiếp mà không cần tham chiếu đến đường dẫn tìm kiếm.
Trong cấu hình mặc định, truy vấn biến cấu hình search_path sẽ hiển thị giá trị này
SHOW search_path;
Search_path
--------------
"$user", publicHệ thống diễn giải giá trị đầu tiên được hiển thị ở trên dưới dạng tên người dùng đã đăng nhập hiện tại và đáp ứng trường hợp sử dụng được đề cập trước đó, trong đó mỗi người dùng được cấp phát một lược đồ có tên người dùng cho một không gian làm việc tách biệt với những người dùng khác. Nếu không có lược đồ nào do người dùng đặt tên như vậy được tạo, mục nhập đó sẽ bị bỏ qua và lược đồ "công khai" trở thành lược đồ hiện tại nơi các đối tượng mới được tạo.
Do đó, trở lại ví dụ trước đó của chúng tôi về việc tạo bảng “hollywood.actors”, nếu chúng tôi chưa đủ điều kiện đặt tên bảng với tên lược đồ, thì bảng sẽ được tạo trong lược đồ công khai. Nếu chúng tôi dự đoán sẽ tạo tất cả các đối tượng trong một lược đồ cụ thể, thì có thể thuận tiện để đặt biến search_path chẳng hạn như
SET search_path TO hollywood,public;tạo điều kiện thuận lợi cho việc nhập các tên không đủ tiêu chuẩn để tạo hoặc truy cập các đối tượng cơ sở dữ liệu.
Ngoài ra còn có một hàm thông tin hệ thống trả về lược đồ hiện tại với một truy vấn
select current_schema();Trong trường hợp sai chính tả, chủ sở hữu giản đồ có thể thay đổi tên, miễn là người dùng cũng có đặc quyền tạo cho cơ sở dữ liệu, với
ALTER SCHEMA old_name RENAME TO new_name;Và cuối cùng, để xóa một lược đồ khỏi cơ sở dữ liệu, có một lệnh thả
DROP SCHEMA schema_name;Lệnh DROP sẽ không thành công nếu lược đồ chứa bất kỳ đối tượng nào, vì vậy chúng phải được xóa trước tiên hoặc bạn có thể tùy chọn xóa một cách đệ quy tất cả nội dung của lược đồ bằng tùy chọn CASCADE
DROP SCHEMA schema_name CASCADE;Những điều cơ bản này sẽ giúp bạn bắt đầu với việc hiểu các lược đồ!



