Lớp proxy có thể khá hữu ích trong việc tăng tính khả dụng của lớp cơ sở dữ liệu của bạn. Nó có thể làm giảm số lượng mã ở phía ứng dụng để xử lý các lỗi cơ sở dữ liệu và thay đổi cấu trúc liên kết sao chép. Trong bài đăng trên blog này, chúng ta sẽ thảo luận về cách thiết lập HAProxy để hoạt động trên PostgreSQL.
Điều đầu tiên trước tiên - HAProxy hoạt động với cơ sở dữ liệu như một proxy lớp mạng. Không có hiểu biết về cấu trúc liên kết cơ bản, đôi khi phức tạp. Tất cả những gì HAProxy làm là gửi các gói theo kiểu vòng lặp đến các phần phụ trợ đã xác định. Nó không kiểm tra các gói cũng như không hiểu giao thức mà các ứng dụng nói chuyện với PostgreSQL. Do đó, không có cách nào để HAProxy thực hiện phân tách đọc / ghi trên một cổng duy nhất - nó sẽ yêu cầu phân tích cú pháp các truy vấn. Miễn là ứng dụng của bạn có thể tách các lần đọc khỏi các lần ghi và gửi chúng đến các IP hoặc cổng khác nhau, bạn có thể thực hiện phân tách R / W bằng cách sử dụng hai phụ trợ. Hãy xem cách nó có thể được thực hiện.
Cấu hình HAProxy
Dưới đây, bạn có thể tìm thấy một ví dụ về hai phần phụ trợ PostgreSQL được định cấu hình trong HAProxy.
listen haproxy_10.0.0.101_3307_rw
bind *:3307
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string master\ is\ running
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 check
listen haproxy_10.0.0.101_3308_ro
bind *:3308
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running.
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 checkNhư chúng ta thấy, chúng sử dụng cổng 3307 để ghi và 3308 để đọc. Trong thiết lập này có ba máy chủ - một bản sao đang hoạt động và hai bản sao ở chế độ chờ. Điều quan trọng, kiểm tra tcp được sử dụng để theo dõi tình trạng của các nút. HAProxy sẽ kết nối với cổng 9201 và nó hy vọng sẽ thấy một chuỗi được trả về. Các thành viên lành mạnh của chương trình phụ trợ sẽ trả về nội dung mong đợi, những người không trả lại chuỗi sẽ được đánh dấu là không khả dụng.
Thiết lập Xinetd
Khi HAProxy kiểm tra cổng 9201, một số thứ phải lắng nghe trên đó. Chúng tôi có thể sử dụng xinetd để nghe ở đó và chạy một số tập lệnh cho chúng tôi. Cấu hình ví dụ của dịch vụ như vậy có thể trông giống như sau:
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITED
}Bạn cần đảm bảo rằng bạn thêm dòng:
postgreschk 9201/tcptới / etc / services.
Xinetd bắt đầu một tập lệnh postgreschk, có nội dung như sau:
#!/bin/bash
#
# This script checks if a PostgreSQL server is healthy running on localhost. It will
# return:
# "HTTP/1.x 200 OK\r" (if postgres is running smoothly)
# - OR -
# "HTTP/1.x 500 Internal Server Error\r" (else)
#
# The purpose of this script is make haproxy capable of monitoring PostgreSQL properly
#
export PGHOST='10.0.0.101'
export PGUSER='someuser'
export PGPASSWORD='somepassword'
export PGPORT='5432'
export PGDATABASE='postgres'
export PGCONNECT_TIMEOUT=10
FORCE_FAIL="/dev/shm/proxyoff"
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"
return_ok()
{
echo -e "HTTP/1.1 200 OK\r\n"
echo -e "Content-Type: text/html\r\n"
if [ "$1x" == "masterx" ]; then
echo -e "Content-Length: 56\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL master is running.</body></html>\r\n"
elif [ "$1x" == "slavex" ]; then
echo -e "Content-Length: 55\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL slave is running.</body></html>\r\n"
else
echo -e "Content-Length: 49\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is running.</body></html>\r\n"
fi
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 0
}
return_fail()
{
echo -e "HTTP/1.1 503 Service Unavailable\r\n"
echo -e "Content-Type: text/html\r\n"
echo -e "Content-Length: 48\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is *down*.</body></html>\r\n"
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 1
}
if [ -f "$FORCE_FAIL" ]; then
return_fail;
fi
# check if in recovery mode (that means it is a 'slave')
SLAVE=$(psql -qt -c "$SLAVE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $SLAVE | egrep -i "(t|true|on|1)" 2>/dev/null >/dev/null; then
return_ok "slave"
fi
# check if writable (then we consider it as a 'master')
READONLY=$(psql -qt -c "$WRITABLE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $READONLY | egrep -i "(f|false|off|0)" 2>/dev/null >/dev/null; then
return_ok "master"
fi
return_ok "none";Logic của kịch bản diễn ra như sau. Có hai truy vấn được sử dụng để phát hiện trạng thái của nút.
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"Lần đầu tiên kiểm tra xem PostgreSQL có đang trong quá trình phục hồi hay không - nó sẽ là ‘false’ đối với máy chủ đang hoạt động và ‘true’ đối với máy chủ dự phòng. Lần thứ hai kiểm tra xem PostgreSQL có ở chế độ chỉ đọc hay không. Máy chủ đang hoạt động sẽ trả về trạng thái ‘tắt’ trong khi máy chủ ở chế độ chờ sẽ trả về ‘bật’. Dựa trên kết quả, tập lệnh gọi hàm return_ok () với một tham số bên phải (‘master’ hoặc ‘slave’, tùy thuộc vào những gì đã được phát hiện). Nếu truy vấn không thành công, một hàm ‘return_fail’ sẽ được thực thi.
Hàm return_ok trả về một chuỗi dựa trên đối số được chuyển cho nó. Nếu máy chủ lưu trữ là một máy chủ đang hoạt động, tập lệnh sẽ trả về “PostgreSQL master đang chạy”. Nếu đó là chế độ chờ, chuỗi được trả về sẽ là:“PostgreSQL slave is running”. Nếu trạng thái không rõ ràng, nó sẽ trả về:“PostgreSQL đang chạy”. Đây là nơi mà vòng lặp kết thúc. HAProxy kiểm tra trạng thái bằng cách kết nối với xinetd. Sau đó bắt đầu một tập lệnh, sau đó trả về một chuỗi mà HAProxy phân tích cú pháp.
Như bạn có thể nhớ, HAProxy mong đợi các chuỗi sau:
tcp-check expect string master\ is\ runningcho phần phụ trợ ghi và
tcp-check expect string is\ running.cho phần phụ trợ chỉ đọc. Điều này làm cho máy chủ đang hoạt động trở thành máy chủ duy nhất có sẵn trong phần phụ trợ ghi trong khi ở phần phụ trợ đọc, cả máy chủ đang hoạt động và dự phòng đều có thể được sử dụng.
PostgreSQL và HAProxy trong ClusterControl
Việc thiết lập ở trên không phức tạp, nhưng sẽ mất một khoảng thời gian để thiết lập nó. ClusterControl có thể được sử dụng để thiết lập tất cả những điều này cho bạn.
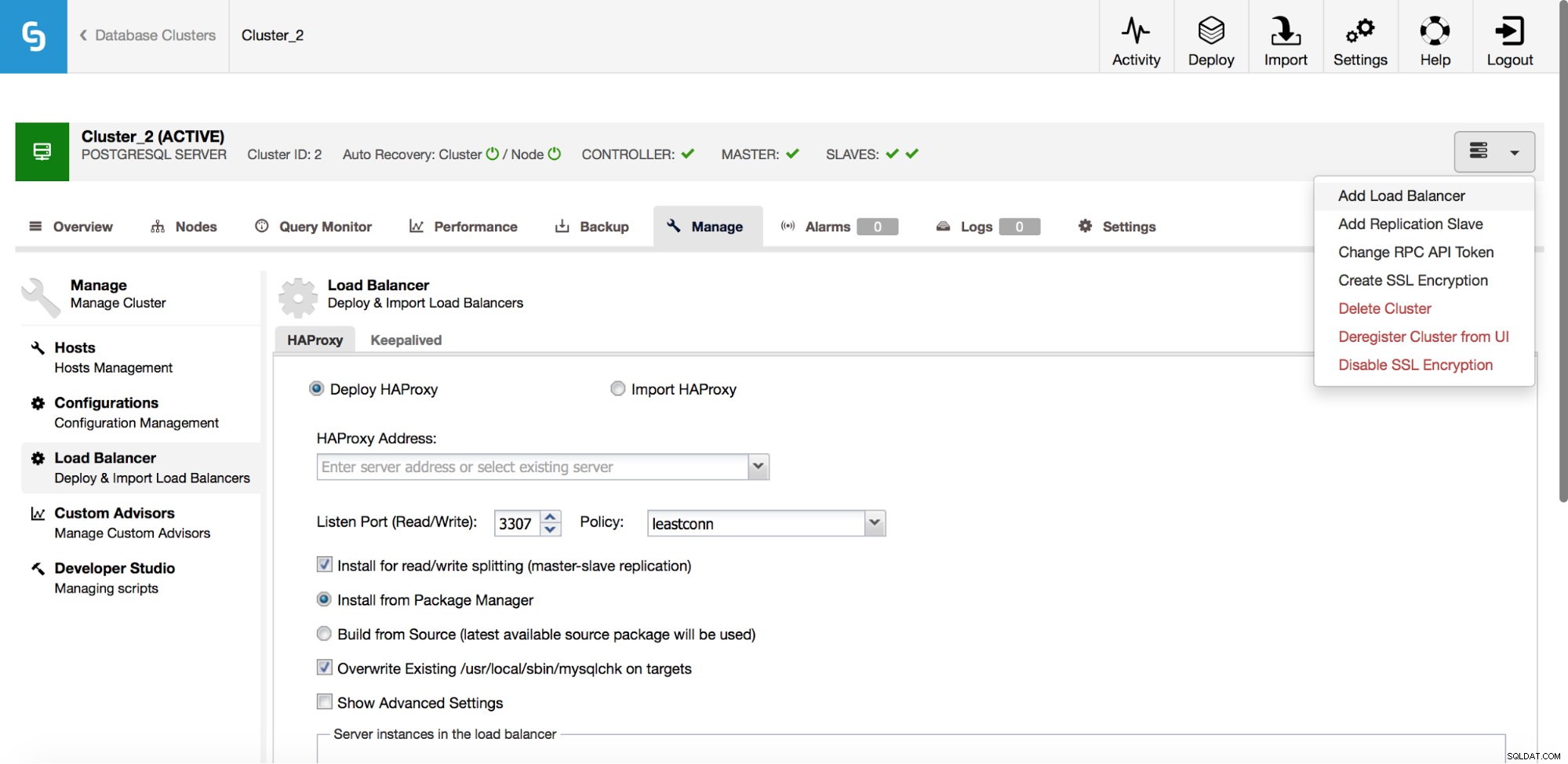
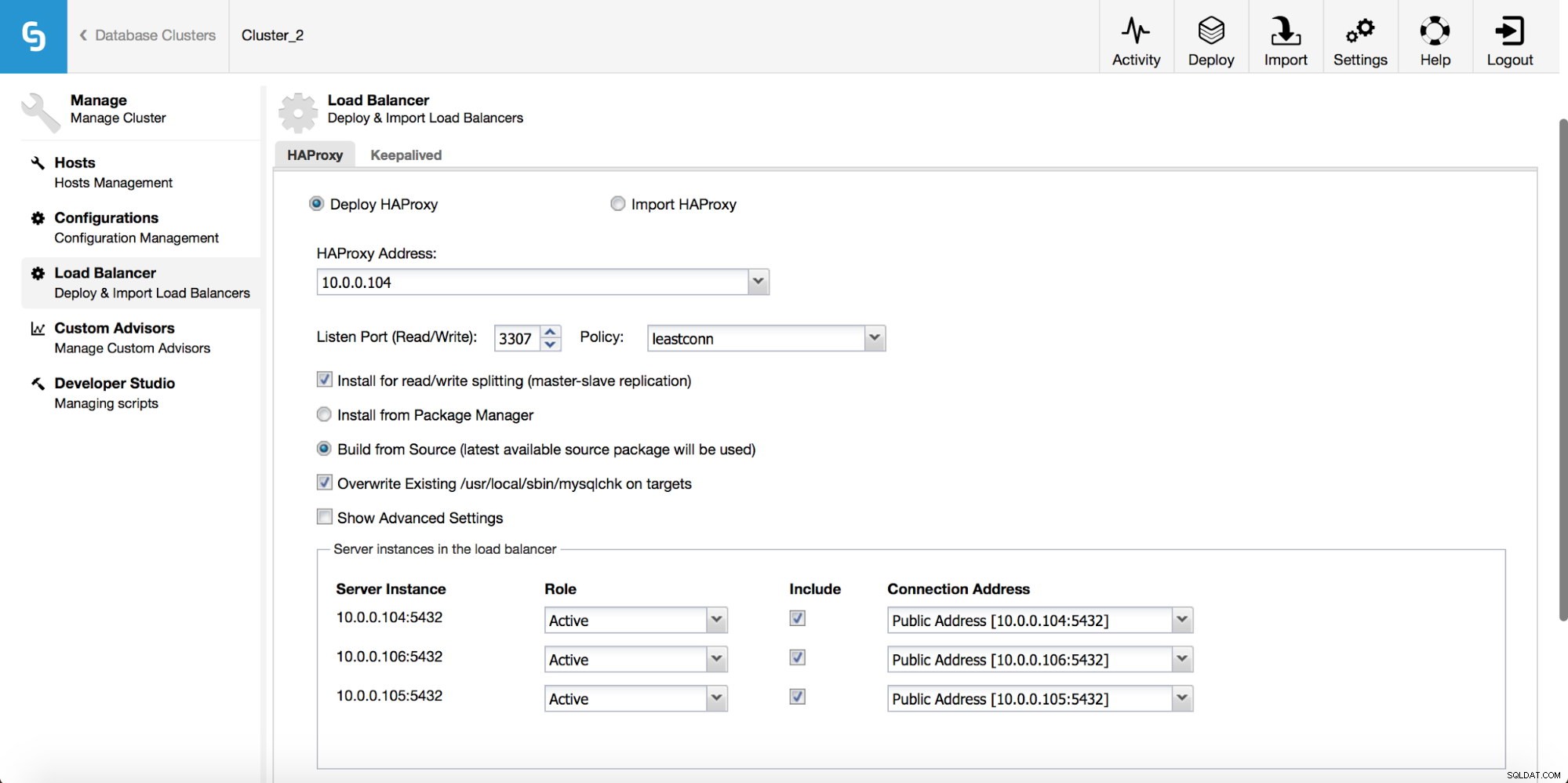
Trong menu thả xuống công việc cụm, bạn có tùy chọn để thêm bộ cân bằng tải. Sau đó, một tùy chọn để triển khai HAProxy hiển thị. Bạn cần điền vào nơi bạn muốn cài đặt nó và đưa ra một số quyết định:từ kho lưu trữ mà bạn đã định cấu hình trên máy chủ lưu trữ hoặc phiên bản mới nhất, được biên dịch từ mã nguồn. Bạn cũng sẽ cần định cấu hình những nút nào trong cụm mà bạn muốn thêm vào HAProxy.
Sau khi phiên bản HAProxy được triển khai, bạn có thể truy cập một số thống kê trong tab “Nút”:
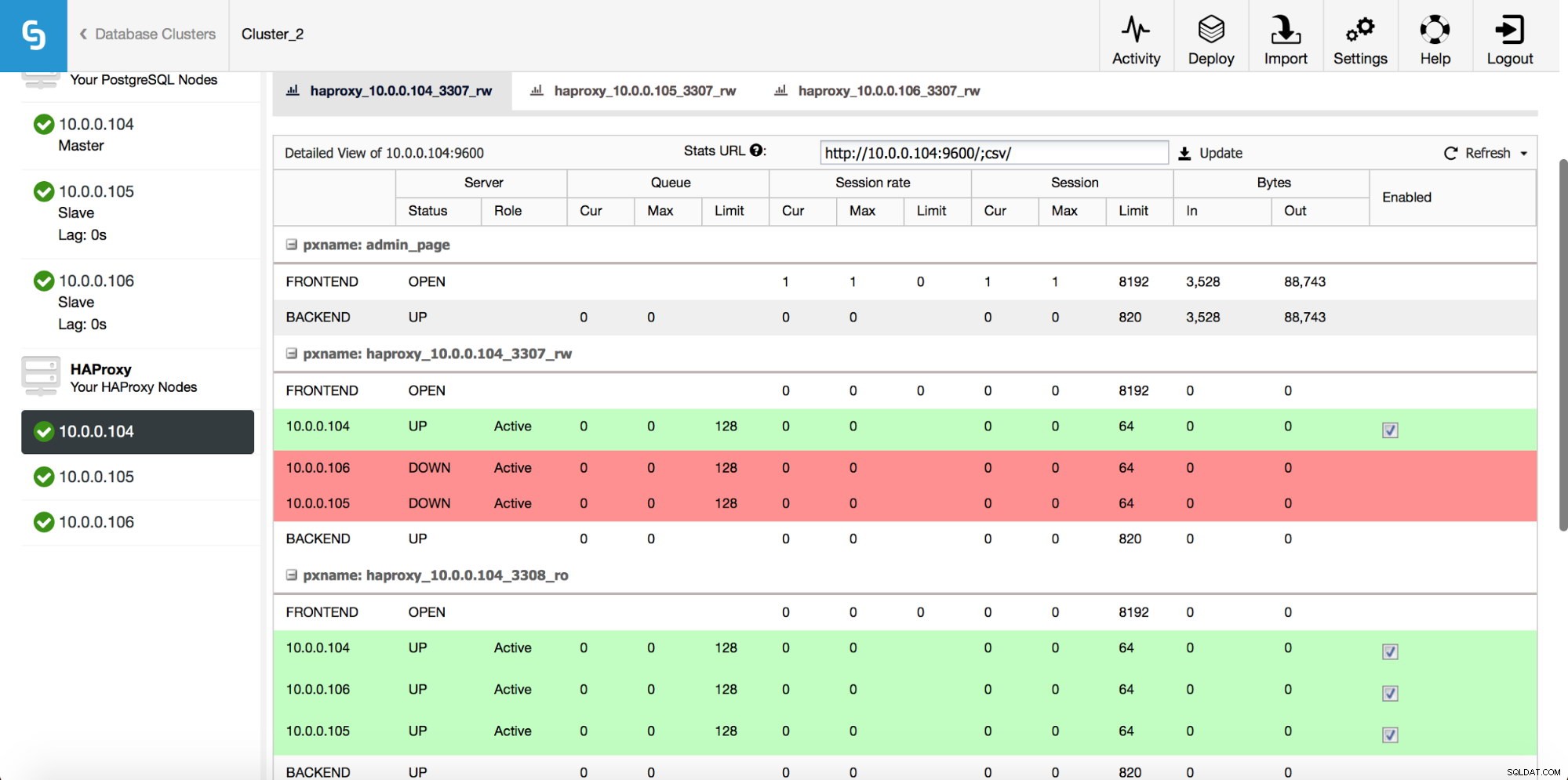
Như chúng ta có thể thấy, đối với phần phụ trợ R / W, chỉ một máy chủ lưu trữ (máy chủ đang hoạt động) được đánh dấu là lên. Đối với phần phụ trợ chỉ đọc, tất cả các nút đều hoạt động.
Tải xuống Báo cáo chính thức hôm nay Quản lý &Tự động hóa PostgreSQL với ClusterControlTìm hiểu về những điều bạn cần biết để triển khai, giám sát, quản lý và mở rộng PostgreSQLTải xuống Báo cáo chính thứcGiữ đủ tiêu chuẩn
HAProxy sẽ nằm giữa các ứng dụng và cá thể cơ sở dữ liệu của bạn, vì vậy nó sẽ đóng vai trò trung tâm. Thật không may, nó cũng có thể trở thành một điểm lỗi duy nhất, nếu nó bị lỗi, sẽ không có đường dẫn đến cơ sở dữ liệu. Để tránh trường hợp như vậy, bạn có thể triển khai nhiều phiên bản HAProxy. Nhưng câu hỏi đặt ra là - làm thế nào để quyết định kết nối với máy chủ proxy nào. Nếu bạn đã triển khai HAProxy từ ClusterControl, thì việc này đơn giản như chạy một công việc “Thêm Load Balancer” khác, lần này là triển khai Keepalived.
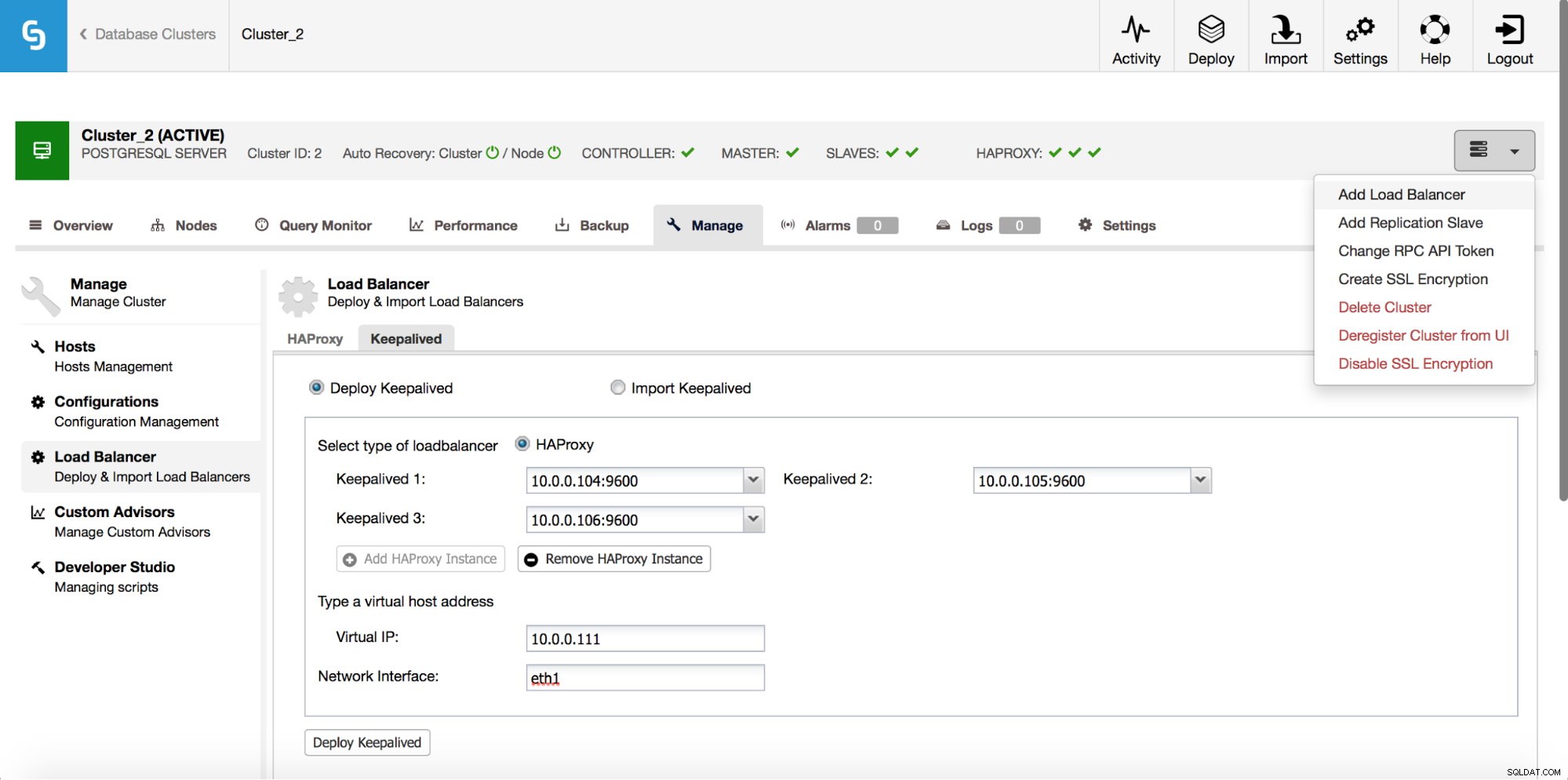
Như chúng ta có thể thấy trong ảnh chụp màn hình ở trên, bạn có thể chọn tối đa ba máy chủ HAProxy và Keepalived sẽ được triển khai trên đầu chúng, theo dõi trạng thái của chúng. Một IP ảo (VIP) sẽ được chỉ định cho một trong số họ. Ứng dụng của bạn nên sử dụng VIP này để kết nối với cơ sở dữ liệu. Nếu HAProxy “đang hoạt động” không khả dụng, VIP sẽ được chuyển sang máy chủ khác.
Như chúng ta đã thấy, khá dễ dàng để triển khai một ngăn xếp tính sẵn sàng cao đầy đủ cho PostgreSQL. Hãy thử và cho chúng tôi biết nếu bạn có bất kỳ phản hồi nào.