Làm việc trong ngành CNTT, chắc hẳn chúng ta đã không ít lần nghe đến từ “chuyển đổi dự phòng”, nhưng cũng có thể đặt ra những câu hỏi như:Chuyển đổi dự phòng thực sự là gì? Chúng ta có thể sử dụng nó để làm gì? Điều quan trọng là phải có nó? Làm thế nào chúng ta có thể làm điều đó?
Mặc dù chúng có vẻ là những câu hỏi khá cơ bản, nhưng điều quan trọng là phải tính đến chúng trong bất kỳ môi trường cơ sở dữ liệu nào. Và thường xuyên hơn không, chúng tôi không tính đến những điều cơ bản ...
Để bắt đầu, hãy xem xét một số khái niệm cơ bản.
Chuyển đổi dự phòng là gì?
Chuyển đổi dự phòng là khả năng hệ thống tiếp tục hoạt động ngay cả khi một số lỗi xảy ra. Nó gợi ý rằng các chức năng của hệ thống được đảm nhận bởi các thành phần thứ cấp nếu các thành phần chính bị lỗi.
Trong trường hợp của PostgreSQL, có các công cụ khác nhau cho phép bạn triển khai một cụm cơ sở dữ liệu có khả năng phục hồi khi gặp lỗi. Một cơ chế dự phòng có sẵn trong PostgreSQL là sao chép. Và điểm mới trong PostgreSQL 10 là việc thực hiện sao chép hợp lý.
Replication là gì?
Đây là quá trình sao chép và cập nhật dữ liệu trong một hoặc nhiều nút cơ sở dữ liệu. Nó sử dụng khái niệm về nút chính nhận các sửa đổi và các nút phụ nơi chúng được sao chép.
Chúng tôi có một số cách phân loại sao chép:
- Sao chép đồng bộ:Không mất dữ liệu ngay cả khi nút chính của chúng ta bị mất, nhưng các cam kết trong chính phải đợi xác nhận từ máy chủ, điều này có thể ảnh hưởng đến hiệu suất.
- Sao chép không đồng bộ:Có khả năng mất dữ liệu trong trường hợp chúng tôi mất nút chính. Nếu bản sao vì một lý do nào đó không được cập nhật tại thời điểm xảy ra sự cố, thông tin chưa được sao chép có thể bị mất.
- Sao chép vật lý:Các khối đĩa được sao chép.
- Sao chép lôgic:Luồng dữ liệu thay đổi.
- Nô lệ ở chế độ chờ ấm:Chúng không hỗ trợ kết nối.
- Hot Standby Slaves:Hỗ trợ kết nối chỉ đọc, hữu ích cho các báo cáo hoặc truy vấn.
Chuyển đổi dự phòng được sử dụng để làm gì?
Có một số cách sử dụng chuyển đổi dự phòng có thể xảy ra. Hãy xem một số ví dụ.
Di chuyển
Nếu chúng ta muốn di chuyển từ trung tâm dữ liệu này sang trung tâm dữ liệu khác bằng cách giảm thiểu thời gian chết, chúng ta có thể sử dụng chuyển đổi dự phòng.
Giả sử rằng cái chủ của chúng ta đang ở trong trung tâm dữ liệu A và chúng tôi muốn di chuyển hệ thống của mình sang trung tâm dữ liệu B.
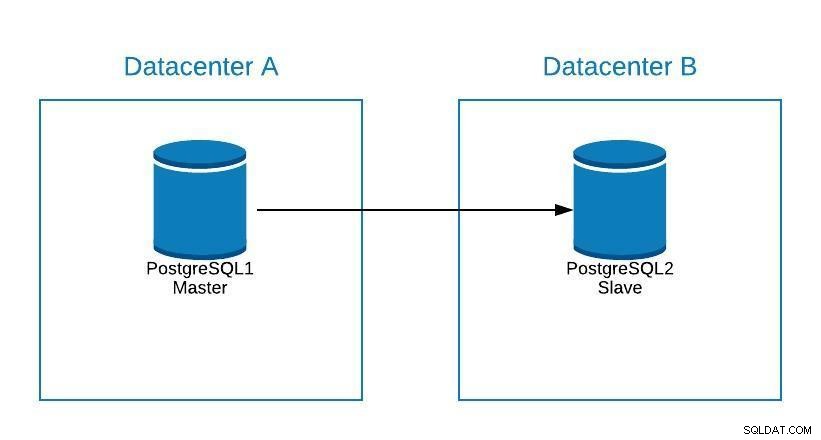 Sơ đồ di chuyển 1
Sơ đồ di chuyển 1 Chúng ta có thể tạo một bản sao trong trung tâm dữ liệu B. Khi nó được đồng bộ hóa, chúng ta phải dừng hệ thống của mình, chuyển bản sao của mình lên bản chính mới và chuyển đổi dự phòng, trước khi chúng ta trỏ hệ thống của mình đến bản chính mới trong trung tâm dữ liệu B.
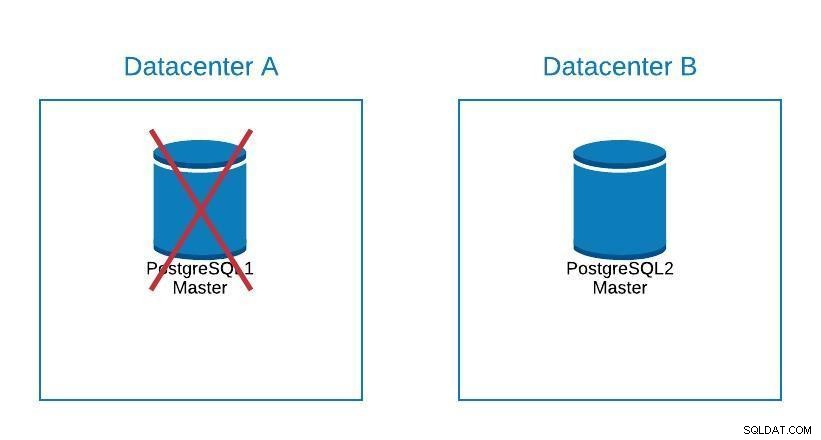 Sơ đồ di chuyển 2
Sơ đồ di chuyển 2 Chuyển đổi dự phòng không chỉ về cơ sở dữ liệu mà còn cả (các) ứng dụng. Làm thế nào để họ biết cơ sở dữ liệu nào để kết nối? Chúng tôi chắc chắn không muốn phải sửa đổi ứng dụng của mình, vì điều này sẽ chỉ kéo dài thời gian ngừng hoạt động của chúng tôi .. Vì vậy, chúng tôi có thể định cấu hình bộ cân bằng tải để khi chúng tôi gỡ xuống chủ của mình, nó sẽ tự động trỏ đến máy chủ tiếp theo được xúc tiến.
Một tùy chọn khác là sử dụng DNS. Bằng cách quảng bá bản sao chính trong trung tâm dữ liệu mới, chúng tôi trực tiếp sửa đổi địa chỉ IP của tên máy chủ trỏ đến bản chính. Bằng cách này, chúng tôi tránh phải sửa đổi ứng dụng của mình và mặc dù nó không thể được thực hiện tự động, nhưng nó là một giải pháp thay thế nếu chúng tôi không muốn triển khai bộ cân bằng tải.
Có một phiên bản cân bằng tải duy nhất không phải là tuyệt vời vì nó có thể trở thành một điểm lỗi duy nhất. Do đó, bạn cũng có thể thực hiện chuyển đổi dự phòng cho bộ cân bằng tải bằng cách sử dụng một dịch vụ như keepalived. Theo cách này, nếu chúng tôi gặp sự cố với bộ cân bằng tải chính của mình, keepalived chịu trách nhiệm di chuyển IP sang bộ cân bằng tải thứ cấp của chúng tôi và mọi thứ tiếp tục hoạt động minh bạch.
Bảo trì
Nếu chúng tôi phải thực hiện bất kỳ bảo trì nào trên máy chủ cơ sở dữ liệu chính postgreSQL của mình, chúng tôi có thể thúc đẩy máy chủ của mình, thực hiện tác vụ và tạo lại máy chủ trên máy chủ cũ của chúng ta.
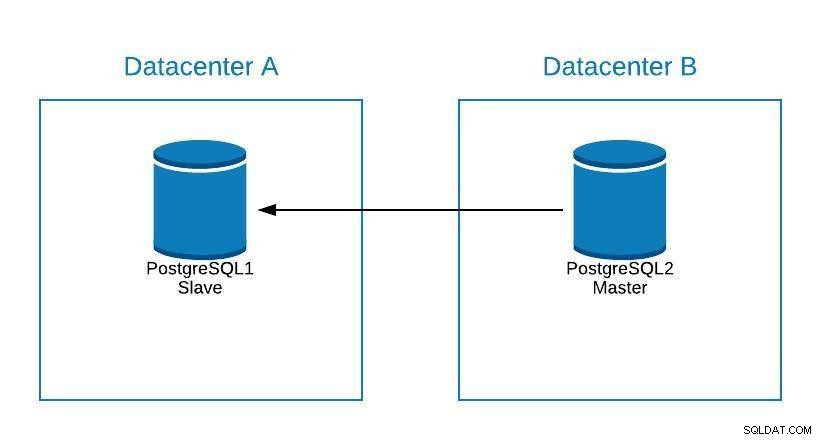 Sơ đồ bảo trì 1
Sơ đồ bảo trì 1 Sau đó, chúng ta có thể thăng cấp lại cho chủ nhân cũ và lặp lại quá trình xây dựng lại nô lệ, trở về trạng thái ban đầu.
Sơ đồ bảo trì 2 Bằng cách này, chúng tôi có thể làm việc trên máy chủ của mình mà không gặp rủi ro ngoại tuyến hoặc mất thông tin khi thực hiện bảo trì.
Nâng cấp
Mặc dù PostgreSQL 11 chưa có sẵn, về mặt kỹ thuật, có thể nâng cấp từ PostgreSQL phiên bản 10, sử dụng bản sao lôgic, vì nó có thể được thực hiện với các công cụ khác.
Các bước sẽ giống như để di chuyển sang một trung tâm dữ liệu mới (Xem phần Di chuyển), chỉ khác là nô lệ của chúng tôi sẽ ở trong PostgreSQL 11.
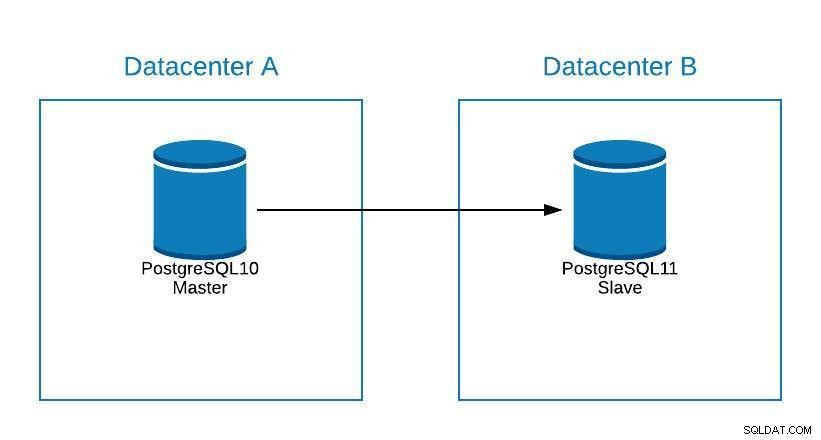 Nâng cấp Sơ đồ 1
Nâng cấp Sơ đồ 1 Vấn đề
Chức năng quan trọng nhất của chuyển đổi dự phòng là giảm thiểu thời gian chết của chúng tôi hoặc tránh mất thông tin khi gặp sự cố với cơ sở dữ liệu chính của chúng tôi.
Nếu vì lý do nào đó, chúng tôi đánh mất cơ sở dữ liệu chính của mình, chúng tôi có thể thực hiện chuyển đổi dự phòng để thúc đẩy nô lệ của chúng tôi thành chủ và giữ cho hệ thống của chúng tôi hoạt động.
Để làm điều này, PostgreSQL không cung cấp cho chúng tôi bất kỳ giải pháp tự động nào. Chúng tôi có thể làm điều đó theo cách thủ công hoặc tự động hóa bằng tập lệnh hoặc công cụ bên ngoài.
Để thăng cấp nô lệ của chúng ta thành chủ nhân:
-
Chạy quảng cáo pg_ctl
bash-4.2$ pg_ctl promote -D /var/lib/pgsql/10/data/ waiting for server to promote.... done server promoted - Tạo một tệp trigger_file mà chúng tôi phải thêm vào recovery.conf của thư mục dữ liệu của chúng tôi.
bash-4.2$ cat /var/lib/pgsql/10/data/recovery.conf standby_mode = 'on' primary_conninfo = 'application_name=pgsql_node_0 host=postgres1 port=5432 user=replication password=****' recovery_target_timeline = 'latest' trigger_file = '/tmp/failover.trigger' bash-4.2$ touch /tmp/failover.trigger
Để thực hiện chiến lược chuyển đổi dự phòng, chúng ta cần lập kế hoạch và kiểm tra kỹ lưỡng thông qua các tình huống thất bại khác nhau. Vì lỗi có thể xảy ra theo nhiều cách khác nhau và giải pháp lý tưởng nên hoạt động cho hầu hết các tình huống phổ biến. Nếu chúng tôi đang tìm cách để tự động hóa việc này, chúng tôi có thể xem những gì ClusterControl phải cung cấp.
ClusterControl để chuyển đổi dự phòng PostgreSQL
ClusterControl có một số tính năng liên quan đến sao chép PostgreSQL và chuyển đổi dự phòng tự động.
Thêm nô lệ
Nếu chúng tôi muốn thêm một nô lệ trong một trung tâm dữ liệu khác, để dự phòng hoặc để di chuyển hệ thống của bạn, chúng tôi có thể chuyển đến Hành động theo cụm và chọn Thêm nô lệ sao chép.
 ClusterControl Thêm Slave 1
ClusterControl Thêm Slave 1 Chúng tôi sẽ cần nhập một số dữ liệu cơ bản, chẳng hạn như IP hoặc tên máy chủ, thư mục dữ liệu (tùy chọn), máy chủ đồng bộ hoặc không đồng bộ. Chúng ta sẽ có nô lệ của mình và chạy sau vài giây.
Trong trường hợp sử dụng một trung tâm dữ liệu khác, chúng tôi khuyên bạn nên tạo một máy chủ không đồng bộ, vì nếu không, độ trễ có thể ảnh hưởng đáng kể đến hiệu suất.
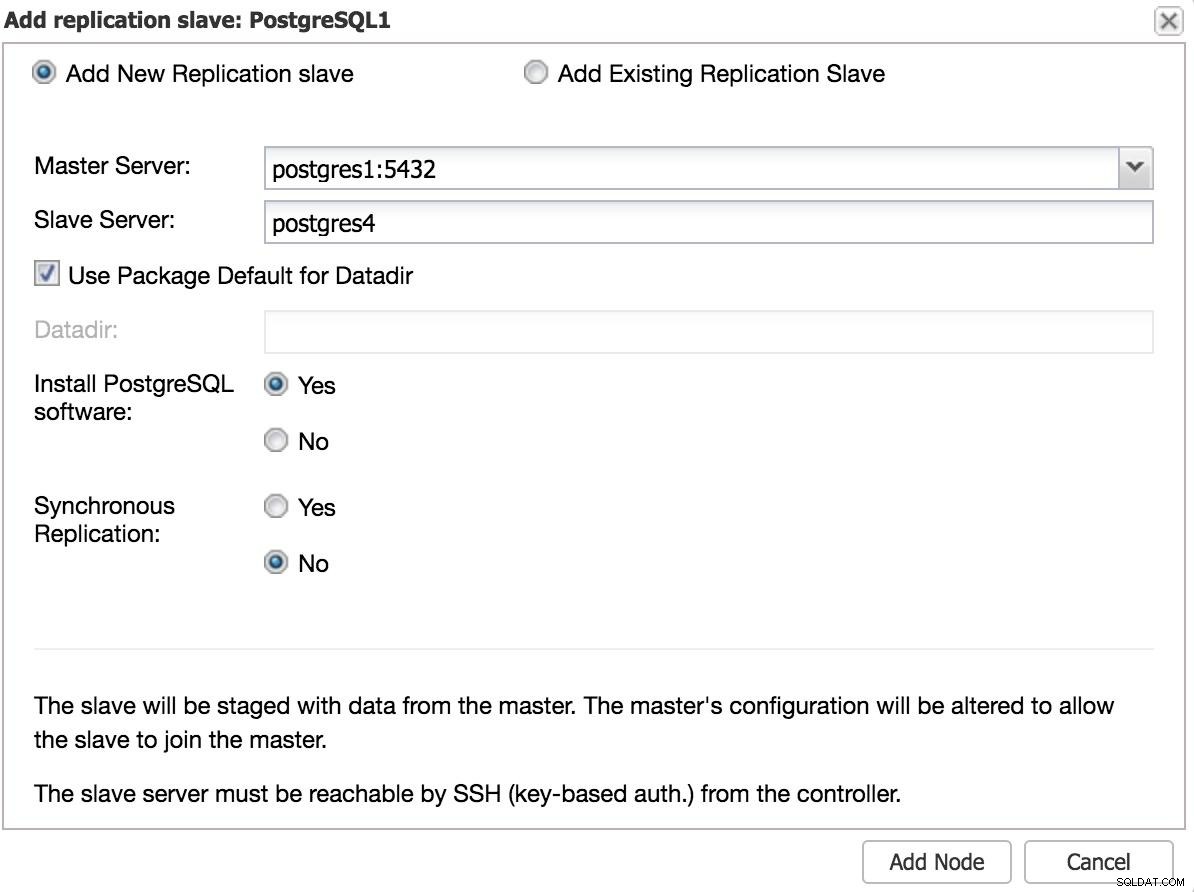 ClusterControl Thêm Slave 2
ClusterControl Thêm Slave 2 Chuyển đổi dự phòng thủ công
Với ClusterControl, chuyển đổi dự phòng có thể được thực hiện thủ công hoặc tự động.
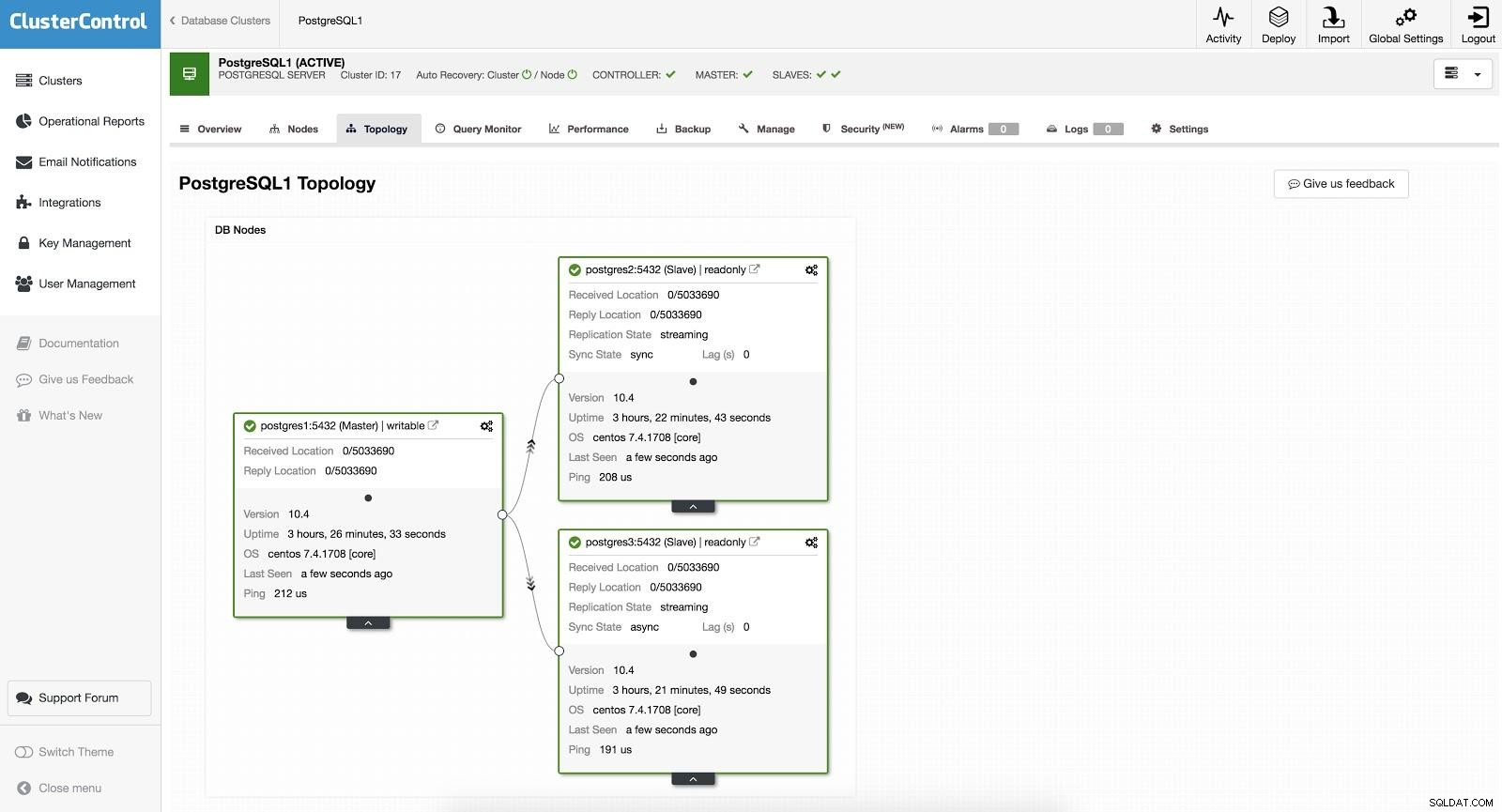 ClusterControl Failover 1
ClusterControl Failover 1 Để thực hiện chuyển đổi dự phòng thủ công, hãy đi tới ClusterControl -> Chọn Cụm -> Nút và trong Nút hành động của một trong các nô lệ của chúng tôi, hãy chọn "Thúc đẩy Slave". Bằng cách này, sau một vài giây, nô lệ của chúng ta trở thành chủ nhân và những gì là chủ của chúng ta trước đây, sẽ bị chuyển thành nô lệ.
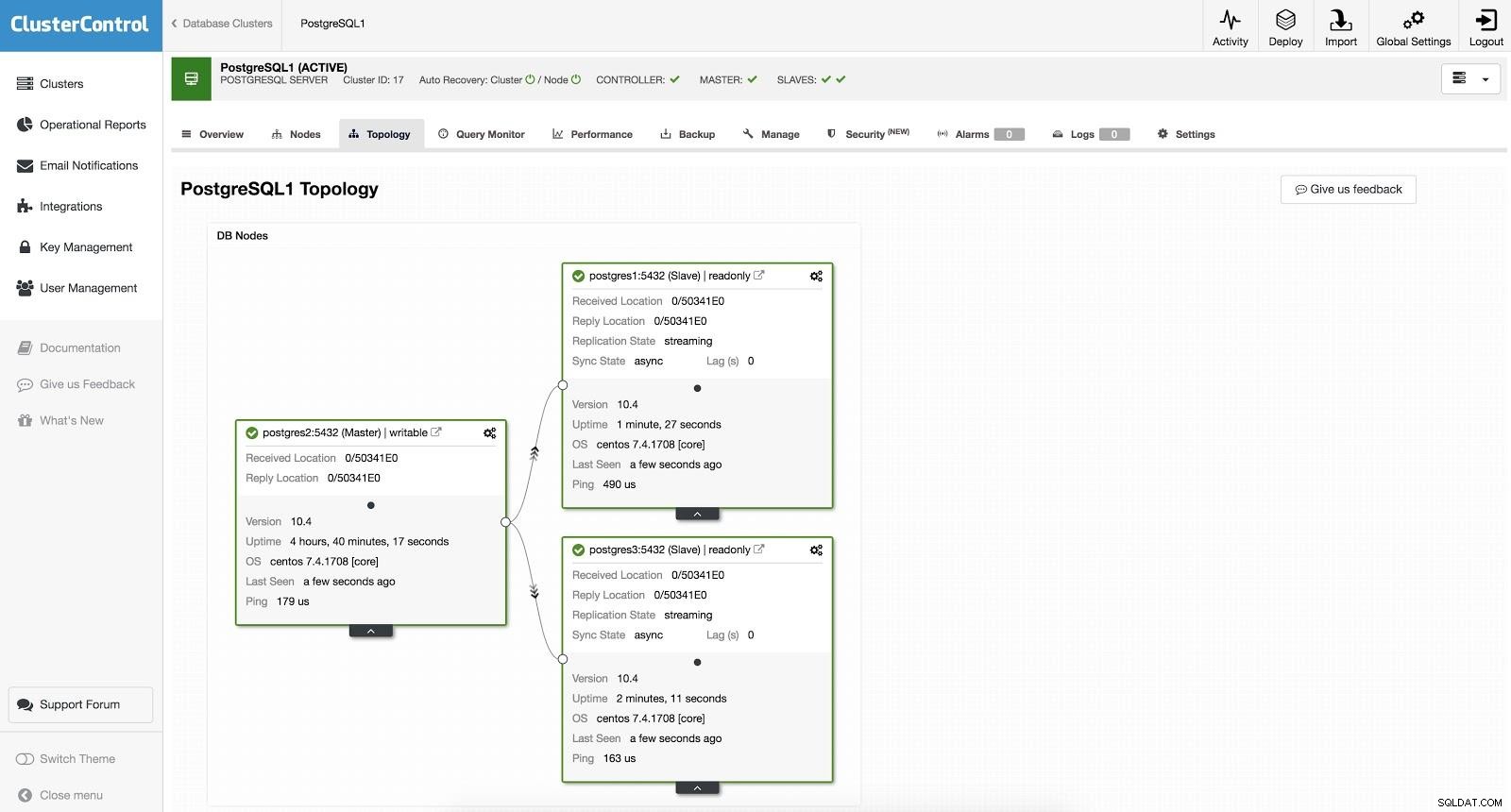 ClusterControl Failover 2
ClusterControl Failover 2 Phần trên hữu ích cho các tác vụ di chuyển, bảo trì và nâng cấp mà chúng tôi đã thấy trước đây.
Tự động chuyển đổi dự phòng
Trong trường hợp tự động chuyển đổi dự phòng, ClusterControl sẽ phát hiện các lỗi trong bản chính và thúc đẩy một phụ có dữ liệu mới nhất làm bản chính mới. Nó cũng hoạt động trên các nô lệ còn lại để chúng sao chép từ chủ mới.
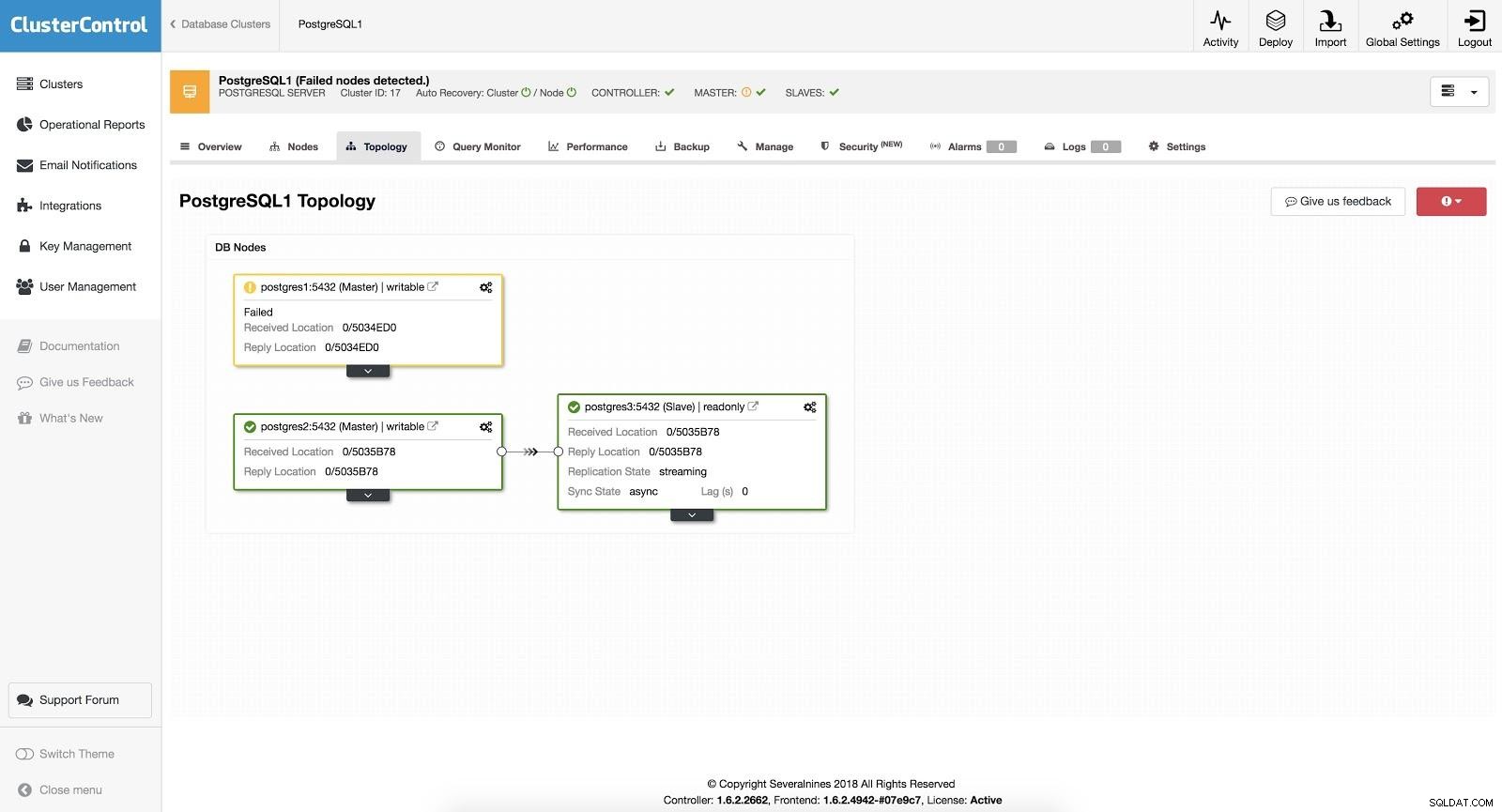 ClusterControl Failover 3
ClusterControl Failover 3 BẬT tùy chọn “Autorecovery”, ClusterControl của chúng tôi sẽ thực hiện chuyển đổi dự phòng tự động cũng như thông báo cho chúng tôi về sự cố. Bằng cách này, hệ thống của chúng tôi có thể khôi phục trong vài giây mà không cần sự can thiệp của chúng tôi.
Kiểm soát cụm cung cấp cho chúng tôi khả năng định cấu hình danh sách trắng / danh sách đen để xác định cách chúng tôi muốn các máy chủ của mình được xem xét (hoặc không được tính đến) khi quyết định một ứng cử viên chính.
Từ những thứ có sẵn theo cấu hình ở trên, ClusterControl sẽ chọn nô lệ nâng cao nhất, sử dụng cho mục đích này là pg_current_xlog_location (PostgreSQL 9+) hoặc pg_current_wal_lsn (PostgreSQL 10+) tùy thuộc vào phiên bản cơ sở dữ liệu của chúng tôi.
ClusterControl cũng thực hiện một số kiểm tra trong quá trình chuyển đổi dự phòng, để tránh một số lỗi phổ biến. Một ví dụ là nếu chúng tôi quản lý để khôi phục chủ cũ bị lỗi, nó sẽ KHÔNG được tự động giới thiệu lại vào cụm, không phải với tư cách là chủ cũng như không phải là nô lệ. Chúng tôi cần phải làm điều đó một cách thủ công. Điều này sẽ tránh khả năng mất dữ liệu hoặc không nhất quán trong trường hợp nô lệ của chúng tôi (mà chúng tôi đã quảng bá) bị trì hoãn tại thời điểm xảy ra sự cố. Chúng tôi cũng có thể muốn phân tích vấn đề một cách chi tiết, nhưng khi thêm nó vào cụm của chúng tôi, chúng tôi có thể sẽ mất thông tin chẩn đoán.
Ngoài ra, nếu chuyển đổi dự phòng không thành công, không có nỗ lực nào khác được thực hiện, thì cần phải có sự can thiệp thủ công để phân tích sự cố và thực hiện các hành động tương ứng. Điều này là để tránh trường hợp ClusterControl, với tư cách là người quản lý tính khả dụng cao, cố gắng thúc đẩy nô lệ tiếp theo và nô lệ tiếp theo. Có thể đã xảy ra sự cố và chúng tôi không muốn làm mọi thứ tồi tệ hơn bằng cách thử nhiều lần chuyển dự phòng.
Cân bằng tải
Như chúng tôi đã đề cập trước đó, bộ cân bằng tải là một công cụ quan trọng cần xem xét cho quá trình chuyển đổi dự phòng của chúng tôi, đặc biệt nếu chúng tôi muốn sử dụng chuyển đổi dự phòng tự động trong cấu trúc liên kết cơ sở dữ liệu của mình.
Để chuyển đổi dự phòng được minh bạch cho cả người dùng và ứng dụng, chúng ta cần một thành phần ở giữa, vì nó không đủ để thăng cấp một chủ thành một nô lệ. Đối với điều này, chúng tôi có thể sử dụng HAProxy + Keepalived.
HAProxy là gì?
HAProxy là một bộ cân bằng tải phân phối lưu lượng truy cập từ một điểm gốc đến một hoặc nhiều điểm đến và có thể xác định các quy tắc và / hoặc giao thức cụ thể cho tác vụ này. Nếu bất kỳ điểm đến nào ngừng phản hồi, nó được đánh dấu là ngoại tuyến và lưu lượng truy cập được gửi đến phần còn lại của các điểm đến khả dụng. Điều này ngăn lưu lượng truy cập được gửi đến một điểm đến không thể truy cập được và ngăn chặn việc mất lưu lượng này bằng cách hướng nó đến một điểm đến hợp lệ.
Keepalived là gì?
Keepalived cho phép bạn định cấu hình IP ảo trong một nhóm máy chủ hoạt động / thụ động. IP ảo này được chỉ định cho một máy chủ "Chính" đang hoạt động. Nếu máy chủ này bị lỗi, IP sẽ tự động được di chuyển sang máy chủ "Phụ" được phát hiện là bị động, cho phép nó tiếp tục hoạt động với cùng một IP một cách minh bạch cho hệ thống của chúng tôi.
Để triển khai giải pháp này với ClusterControl, chúng tôi bắt đầu như thể chúng tôi sẽ thêm một nô lệ. Chuyển đến Cluster Actions và chọn Add Load Balancer (xem hình ảnh ClusterControl Add Slave 1).
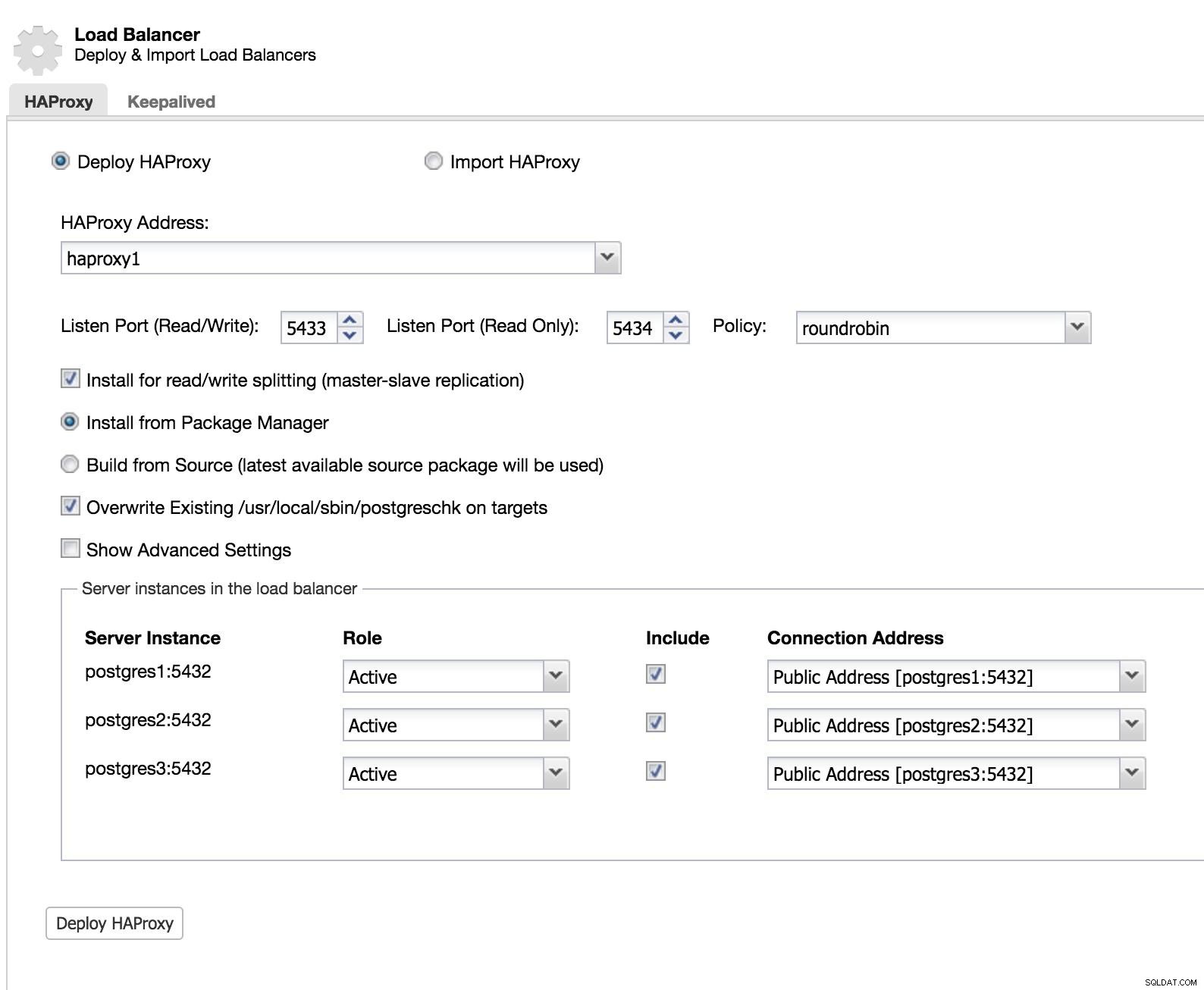 ClusterControl Load Balancer 1
ClusterControl Load Balancer 1 Chúng tôi thêm thông tin về bộ cân bằng tải mới và cách chúng tôi muốn nó hoạt động (Chính sách).
Trong trường hợp muốn triển khai chuyển đổi dự phòng cho bộ cân bằng tải của chúng tôi, chúng tôi phải định cấu hình ít nhất hai phiên bản.
Sau đó, chúng ta có thể cấu hình Keepalived (Chọn Cluster -> Manage -> Load Balancer -> Keepalived).
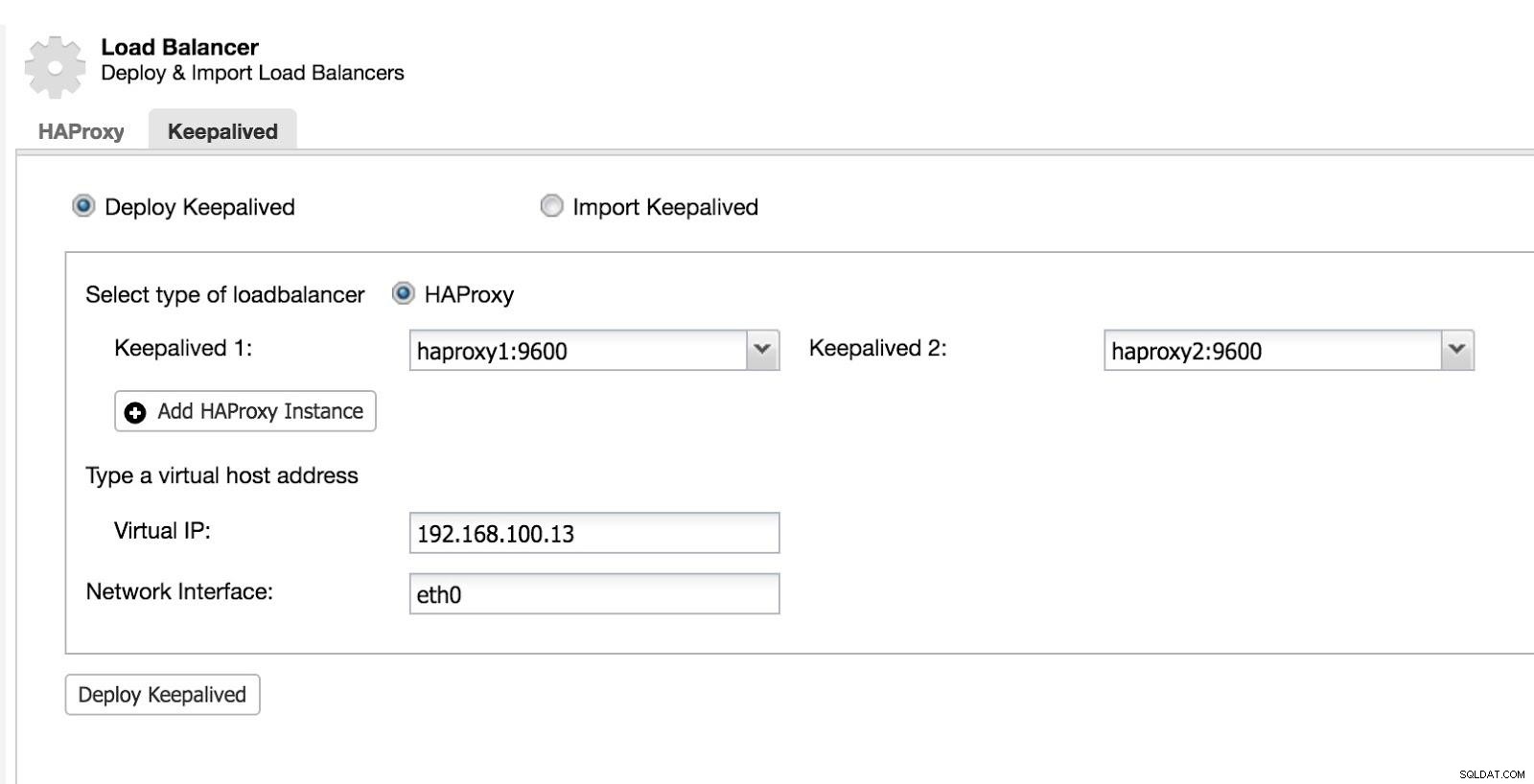 ClusterControl Load Balancer 2
ClusterControl Load Balancer 2 Sau đó, chúng tôi có cấu trúc liên kết sau:
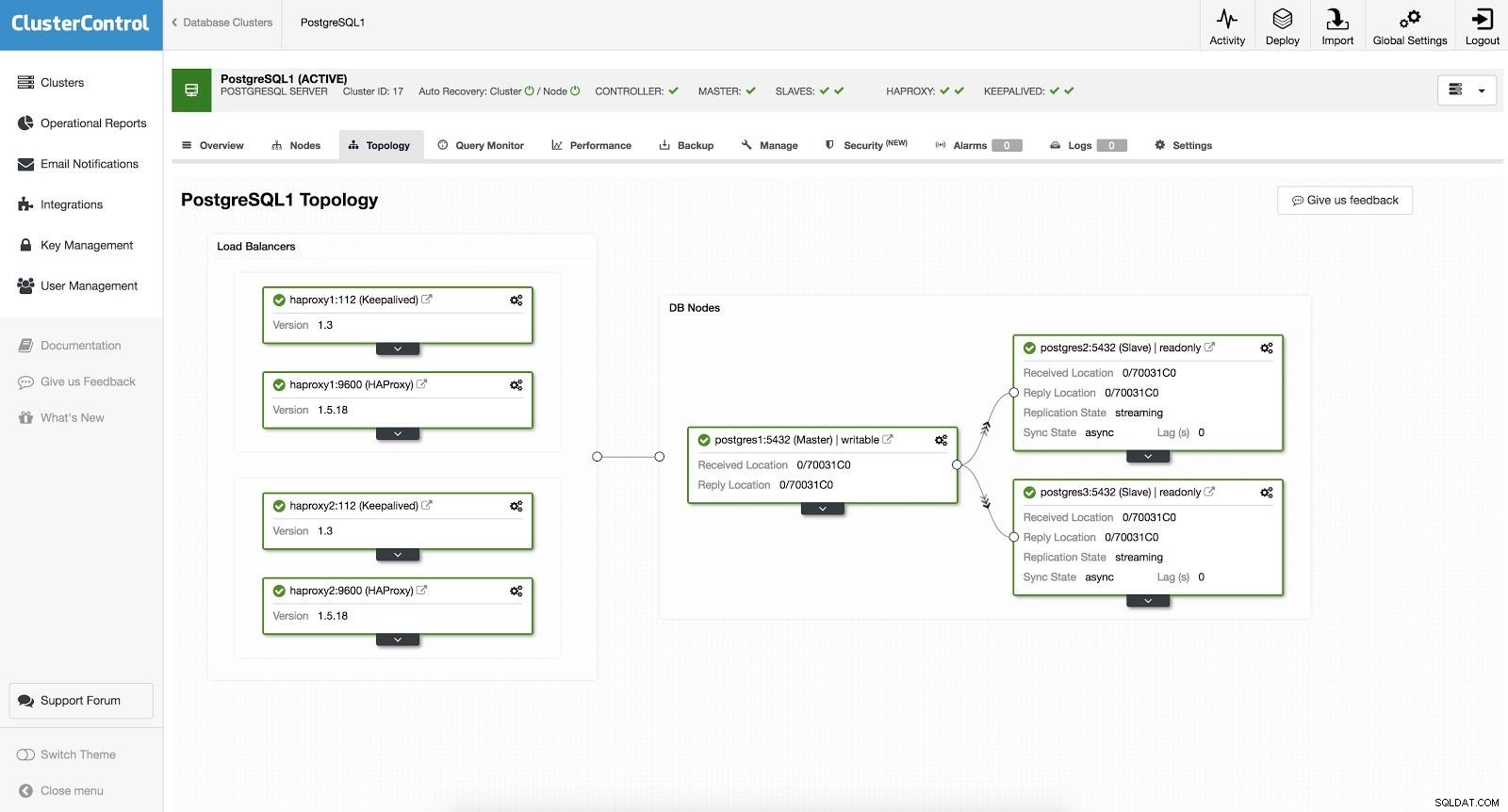 ClusterControl Load Balancer 3
ClusterControl Load Balancer 3 HAProxy được định cấu hình với hai cổng khác nhau, một cổng đọc-ghi và một cổng chỉ đọc.
Trong cổng đọc-ghi của chúng tôi, chúng tôi có máy chủ chính của chúng tôi trực tuyến và phần còn lại của các nút của chúng tôi là ngoại tuyến. Trong cổng chỉ đọc, chúng tôi có cả chủ và nô lệ trực tuyến. Bằng cách này, chúng tôi có thể cân bằng lưu lượng đọc giữa các nút của chúng tôi. Khi viết, cổng đọc-ghi sẽ được sử dụng, cổng này sẽ trỏ đến cổng cái.
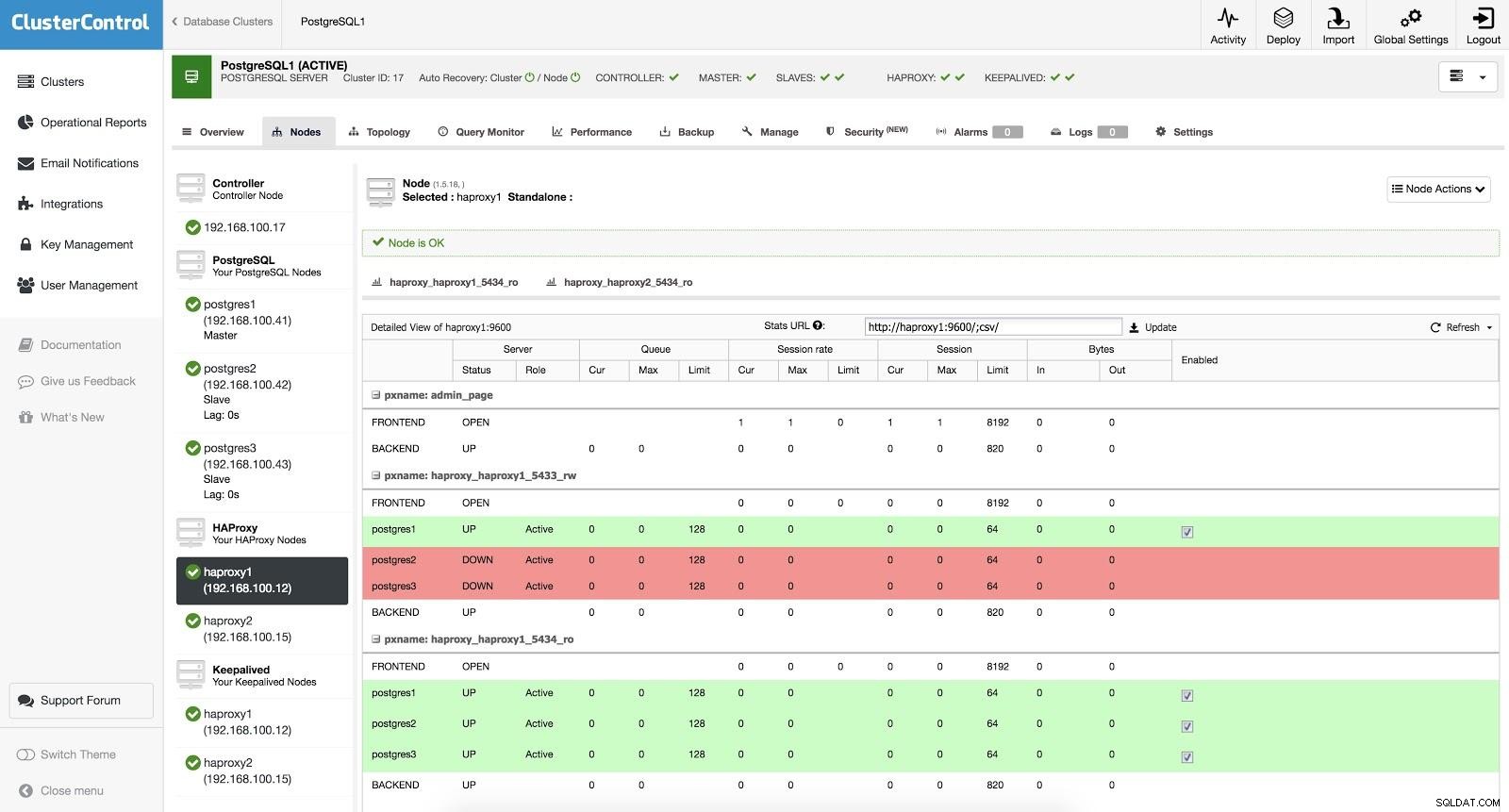 ClusterControl Load Balancer 3
ClusterControl Load Balancer 3 Khi HAProxy phát hiện ra rằng một trong các nút của chúng ta, cả nút chính hoặc nút phụ, không thể truy cập được, nó sẽ tự động đánh dấu nút đó là ngoại tuyến. HAProxy sẽ không gửi bất kỳ lưu lượng nào đến nó. Việc kiểm tra này được thực hiện bằng các tập lệnh kiểm tra tình trạng được cấu hình bởi ClusterControl tại thời điểm triển khai. Những điều này sẽ kiểm tra xem các phiên bản đã hoạt động chưa, chúng đang trong quá trình khôi phục hay ở chế độ chỉ đọc.
Khi ClusterControl thúc đẩy một nô lệ để làm chủ, HAProxy của chúng tôi đánh dấu trang chủ cũ là ngoại tuyến (cho cả hai cổng) và đặt nút được quảng bá trực tuyến (trong cổng đọc-ghi). Bằng cách này, hệ thống của chúng tôi tiếp tục hoạt động bình thường.
Nếu HAProxy hoạt động của chúng tôi (được chỉ định một địa chỉ IP Ảo mà hệ thống của chúng tôi kết nối) không thành công, Keepalived sẽ tự động di chuyển IP này sang HAProxy thụ động của chúng tôi. Điều này có nghĩa là hệ thống của chúng tôi sau đó có thể tiếp tục hoạt động bình thường.
Kết luận
Như chúng ta có thể thấy, chuyển đổi dự phòng là một phần cơ bản của bất kỳ cơ sở dữ liệu sản xuất nào. Nó có thể hữu ích khi thực hiện các nhiệm vụ bảo trì thông thường hoặc di chuyển. Chúng tôi hy vọng rằng blog này hữu ích như một phần giới thiệu về chủ đề, vì vậy bạn có thể tiếp tục nghiên cứu và tạo ra các chiến lược chuyển đổi dự phòng của riêng mình.