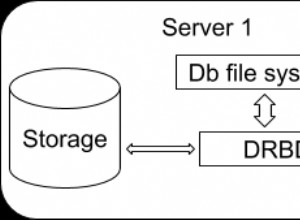
QUY TẮC ĐẦU TIÊN: Bạn không nâng cấp PostgreSQL bằng bản sao dựa trên trình kích hoạt
QUY TẮC thứ 2: Bạn KHÔNG nâng cấp PostgreSQL bằng bản sao dựa trên trình kích hoạt
QUY TẮC THỨ 3: Nếu bạn nâng cấp PostgreSQL với tính năng sao chép dựa trên trình kích hoạt, hãy chuẩn bị sẵn sàng để chịu đựng. Và chuẩn bị tốt.
Phải có một lý do rất nghiêm trọng để không sử dụng pg_upgrade để nâng cấp PostgreSQL.
OK, giả sử bạn không thể dành nhiều hơn giây thời gian ngừng hoạt động. Sau đó sử dụng pglogical.
OK, giả sử bạn chạy 9.3 và do đó không thể sử dụng pglogical. Sử dụng Londiste.
Không tìm thấy README có thể đọc được? Sử dụng SLONY.
Quá phức tạp? Sử dụng nhân rộng phát trực tuyến - quảng bá nô lệ và chạy pg_upgrade trên đó - sau đó chuyển đổi ứng dụng để hoạt động với máy chủ quảng cáo mới.
Ứng dụng của bạn luôn phải viết nhiều? Bạn đã xem xét tất cả các giải pháp khả thi và vẫn muốn thiết lập sao chép dựa trên trình kích hoạt tùy chỉnh? Có những điều bạn nên chú ý sau đó:
- Tất cả các bảng cần PK. Bạn không nên dựa vào ctid (ngay cả khi tắt autovacuum)
- Bạn sẽ cần kích hoạt trình kích hoạt cho tất cả các bảng ngoại quan ràng buộc (và có thể cần FK hoãn lại)
- Các chuỗi cần đồng bộ hóa thủ công
- Quyền không được sao chép (trừ khi bạn cũng thiết lập trình kích hoạt sự kiện)
- Trình kích hoạt sự kiện có thể giúp tự động hóa hỗ trợ cho các bảng mới, nhưng tốt hơn là không làm phức tạp quá một quy trình vốn đã phức tạp. (như tạo trình kích hoạt và bảng ngoại trên tạo bảng, cũng tạo bảng tương tự trên máy chủ nước ngoài hoặc thay đổi bảng máy chủ từ xa với cùng một thay đổi, bạn thực hiện trên db cũ)
- Đối với mỗi trình kích hoạt câu lệnh ít đáng tin cậy hơn nhưng có thể đơn giản hơn
- Bạn nên hình dung một cách sinh động về quy trình di chuyển dữ liệu hiện có của mình
- Bạn nên lập kế hoạch khả năng tiếp cận các bảng hạn chế trong khi thiết lập và bật tính năng sao chép dựa trên trình kích hoạt
- Bạn hoàn toàn nên biết rõ về mối quan hệ phụ thuộc và ràng buộc của bạn trước khi bạn đi theo hướng này.
Cảnh báo đủ chưa? Bạn muốn chơi đã? Sau đó, hãy bắt đầu với một số mã.
Trước khi viết bất kỳ trình kích hoạt nào, chúng ta phải xây dựng một số tập dữ liệu giả lập. Tại sao? Sẽ dễ dàng hơn nhiều nếu có một trình kích hoạt trước khi chúng ta có dữ liệu? Vì vậy, dữ liệu sẽ sao chép vào cụm "nâng cấp" cùng một lúc? Chắc chắn nó sẽ. Nhưng sau đó chúng ta muốn nâng cấp những gì? Chỉ cần tạo tập dữ liệu trên phiên bản mới hơn. Vì vậy, có, nếu bạn có kế hoạch nâng cấp lên phiên bản cao hơn và cần thêm một số bảng, hãy tạo trình kích hoạt sao chép trước khi đưa dữ liệu vào, nó sẽ loại bỏ nhu cầu đồng bộ hóa dữ liệu không được sao chép sau này. Nhưng những bảng mới như vậy, chúng tôi có thể nói, là một phần dễ dàng. Vì vậy, trước tiên chúng ta hãy mô phỏng trường hợp này khi chúng ta có dữ liệu trước khi quyết định nâng cấp.
Giả sử rằng một máy chủ đã lỗi thời có tên là p93 (được hỗ trợ lâu đời nhất) và máy chủ mà chúng tôi tái tạo có tên là p10 (11 đã được triển khai trong quý này, nhưng vẫn chưa xảy ra):
\c PostgreSQL
select pg_terminate_backend(pid) from pg_stat_activity where datname in ('p93','p10');
drop database if exists p93;
drop database if exists p10;Ở đây tôi sử dụng psql, do đó có thể sử dụng \ c meta-command để kết nối với db khác. Nếu bạn muốn làm theo mã này với một ứng dụng khách khác, bạn cần phải kết nối lại. Tất nhiên bạn không cần bước này nếu chạy lần đầu tiên. Tôi đã phải tạo lại hộp cát của mình nhiều lần, do đó tôi đã lưu các báo cáo…
create database p93; --old db (I use 9.3 as oldest supported ATM version)
create database p10; --new db Vì vậy, chúng tôi tạo hai cơ sở dữ liệu mới. Bây giờ tôi sẽ kết nối với cái mà chúng tôi muốn nâng cấp và sẽ tạo một số kiểu dữ liệu phím chức năng và sử dụng chúng để điền vào bảng mà chúng tôi sẽ coi là có sẵn sau này:
\c p93
create type myenum as enum('a', 'b');--adding some complex types
create type mycomposit as (a int, b text); --and again...
create table t(i serial not null primary key, ts timestamptz(0) default now(), j json, t text, e myenum, c mycomposit);
insert into t values(0, now(), '{"a":{"aa":[1,3,2]}}', 'foo', 'b', (3,'aloha'));
insert into t (j,e) values ('{"b":null}', 'a');
insert into t (t) select chr(g) from generate_series(100,240) g;--add some more data
delete from t where i > 3 and i < 142; --mockup activity and mix tuples to be not sequential
insert into t (t) select null;Bây giờ chúng ta có gì?
ctid | i | ts | j | t | e | c
---------+-----+------------------------+----------------------+-----+---+-----------
(0,1) | 0 | 2018-07-08 08:03:00+03 | {"a":{"aa":[1,3,2]}} | foo | b | (3,aloha)
(0,2) | 1 | 2018-07-08 08:03:00+03 | {"b":null} | | a |
(0,3) | 2 | 2018-07-08 08:03:00+03 | | d | |
(0,4) | 3 | 2018-07-08 08:03:00+03 | | e | |
(0,143) | 142 | 2018-07-08 08:03:00+03 | | ð | |
(0,144) | 143 | 2018-07-08 08:03:00+03 | | | |
(6 rows)OK, một số dữ liệu - tại sao tôi lại chèn và sau đó xóa quá nhiều? Chà, chúng tôi cố gắng mô phỏng một tập dữ liệu đã tồn tại trong một thời gian. Vì vậy, tôi đang cố gắng làm cho nó phân tán một chút. Hãy di chuyển thêm một hàng (0,3) đến cuối trang (0,145):
update t set j = '{}' where i =3; --(0,4)Bây giờ, giả sử chúng ta sẽ sử dụng PostgreSQL_fdw (sử dụng dblink ở đây về cơ bản giống nhau và có thể nhanh hơn cho 9.3, vì vậy hãy làm như vậy nếu bạn muốn).
create extension PostgreSQL_fdw;
create server p10 foreign data wrapper PostgreSQL_fdw options (host 'localhost', dbname 'p10'); --I know it's the same 9.3 server - change host to other version and use other cluster if you wish. It's not important for the sandbox...
create user MAPPING FOR vao SERVER p10 options(user 'vao', password 'tsun');Bây giờ chúng ta có thể sử dụng pg_dump -s để lấy DDL, nhưng tôi chỉ có nó ở trên. Chúng tôi phải tạo cùng một bảng trong cụm phiên bản cao hơn để sao chép dữ liệu sang:
\c p10
create type myenum as enum('a', 'b');--adding some complex types
create type mycomposit as (a int, b text); --and again...
create table t(i serial not null primary key, ts timestamptz(0) default now(), j json, t text, e myenum, c mycomposit);Bây giờ chúng ta quay lại 9.3 và sử dụng các bảng ngoại để di chuyển dữ liệu (Tôi sẽ sử dụng f_ quy ước cho tên bảng ở đây, f là viết tắt của nước ngoài):
\c p93
create foreign table f_t(i serial, ts timestamptz(0) default now(), j json, t text, e myenum, c mycomposit) server p10 options (TABLE_name 't');Cuối cùng! Chúng tôi tạo chức năng chèn và trình kích hoạt.
create or replace function tgf_i() returns trigger as $$
begin
execute format('insert into %I select ($1).*','f_'||TG_RELNAME) using NEW;
return NEW;
end;
$$ language plpgsql;Ở đây và sau này tôi sẽ sử dụng các liên kết để có mã dài hơn. Đầu tiên, để văn bản nói không chìm trong ngôn ngữ máy. Thứ hai vì tôi sử dụng một số phiên bản của các chức năng giống nhau để phản ánh cách mã sẽ phát triển theo yêu cầu.
--OK - first table ready - lets try logical trigger based replication on inserts:
insert into t (t) select 'one';
--and now transactional:
begin;
insert into t (t) select 'two';
select ctid, * from f_t;
select ctid, * from t;
rollback;
select ctid, * from f_t where i > 143;
select ctid, * from t where i > 143;Kết quả:
INSERT 0 1
BEGIN
INSERT 0 1
ctid | i | ts | j | t | e | c
-------+-----+------------------------+---+-----+---+---
(0,1) | 144 | 2018-07-08 08:27:15+03 | | one | |
(0,2) | 145 | 2018-07-08 08:27:15+03 | | two | |
(2 rows)
ctid | i | ts | j | t | e | c
---------+-----+------------------------+----------------------+-----+---+-----------
(0,1) | 0 | 2018-07-08 08:27:15+03 | {"a":{"aa":[1,3,2]}} | foo | b | (3,aloha)
(0,2) | 1 | 2018-07-08 08:27:15+03 | {"b":null} | | a |
(0,3) | 2 | 2018-07-08 08:27:15+03 | | d | |
(0,143) | 142 | 2018-07-08 08:27:15+03 | | ð | |
(0,144) | 143 | 2018-07-08 08:27:15+03 | | | |
(0,145) | 3 | 2018-07-08 08:27:15+03 | {} | e | |
(0,146) | 144 | 2018-07-08 08:27:15+03 | | one | |
(0,147) | 145 | 2018-07-08 08:27:15+03 | | two | |
(8 rows)
ROLLBACK
ctid | i | ts | j | t | e | c
-------+-----+------------------------+---+-----+---+---
(0,1) | 144 | 2018-07-08 08:27:15+03 | | one | |
(1 row)
ctid | i | ts | j | t | e | c
---------+-----+------------------------+---+-----+---+---
(0,146) | 144 | 2018-07-08 08:27:15+03 | | one | |
(1 row)Chúng ta thấy gì ở đây? Chúng tôi thấy rằng dữ liệu mới được chèn được sao chép thành công sang cơ sở dữ liệu p10. Và theo đó sẽ được lùi lại nếu giao dịch không thành công. Càng xa càng tốt. Nhưng bạn không thể nhận thấy (vâng, có - không phải không) rằng bảng trên p93 lớn hơn nhiều - dữ liệu cũ không tái tạo. Làm thế nào để chúng ta có được nó ở đó? Rất đơn giản:
insert into … select local.* from ...outer join foreign where foreign.PK is null sẽ làm. Và đây không phải là mối quan tâm chính ở đây - bạn nên lo lắng làm thế nào bạn sẽ quản lý dữ liệu hiện có trước khi cập nhật và xóa - bởi vì các câu lệnh chạy thành công trên phiên bản db thấp hơn sẽ không thành công hoặc chỉ ảnh hưởng đến không hàng trên cao hơn - chỉ vì không có dữ liệu tồn tại trước ! Và ở đây chúng ta đến với cụm từ thời gian chết tính theo giây. (Nếu đó là một bộ phim, tất nhiên ở đây chúng ta sẽ có một đoạn hồi tưởng, nhưng than ôi - nếu cụm từ “giây chết máy” không thu hút sự chú ý của bạn sớm hơn, bạn sẽ phải lên trên và tìm cụm từ ...)
Để bật tất cả trình kích hoạt câu lệnh, bạn phải đóng băng bảng, sao chép tất cả dữ liệu và sau đó bật trình kích hoạt, vì vậy các bảng trên cơ sở dữ liệu phiên bản thấp hơn và cao hơn sẽ được đồng bộ hóa và tất cả các câu lệnh sẽ giống nhau (hoặc cực kỳ gần, vì lý phân phối sẽ khác, một lần nữa nhìn ở trên ở ví dụ đầu tiên cho cột ctid) ảnh hưởng. Nhưng việc chạy "bật sao chép" như vậy trên bàn trong một giao dịch nhỏ sẽ không phải là thời gian chết vài giây. Có khả năng nó sẽ làm cho trang web ở chế độ chỉ đọc trong nhiều giờ. Đặc biệt là nếu bảng được FK liên kết với các bảng lớn khác.
Chỉ đọc tốt không phải là thời gian chết hoàn toàn. Nhưng sau này, chúng tôi sẽ cố gắng để tất cả các CHỌN và một số CHÈN, XÓA, CẬP NHẬT hoạt động (trên dữ liệu mới, không thành công trên dữ liệu cũ). Việc chuyển bảng hoặc giao dịch sang chế độ chỉ đọc có thể được thực hiện theo nhiều cách - đó có thể là một số cách tiếp cận PostgreSQL, hoặc cấp ứng dụng, hoặc thậm chí tạm thời thu hồi theo quyền. Bản thân những cách tiếp cận này có thể là một chủ đề cho blog của chính nó, vì vậy tôi sẽ chỉ đề cập đến nó.
Dù sao thì. Quay lại trình kích hoạt. Để thực hiện hành động tương tự, yêu cầu thao tác trên hàng riêng biệt (CẬP NHẬT, XÓA) trên bảng từ xa như bạn làm trên cục bộ, chúng tôi cần sử dụng khóa chính, vì vị trí thực sẽ khác. Và các khóa chính được tạo trên các bảng khác nhau với các cột khác nhau, do đó chúng ta phải tạo chức năng duy nhất cho mỗi bảng hoặc thử viết một số chung chung. Hãy giả sử (để đơn giản) giả sử chúng ta chỉ có một PK cột, thì hàm này sẽ hữu ích. Cuối cùng thì! Hãy có một chức năng cập nhật ở đây. Và rõ ràng là một kích hoạt:
create trigger tgu before update on t for each row execute procedure tgf_u();Và hãy xem nó có hoạt động không:
begin;
update t set j = '{"updated":true}' where i = 144;
select * from t where i = 144;
select * from f_t where i = 144;
Rollback;Dẫn đến:
BEGIN
psql:blog.sql:71: INFO: (144,"2018-07-08 09:09:20+03","{""updated"":true}",one,,)
UPDATE 1
i | ts | j | t | e | c
-----+------------------------+------------------+-----+---+---
144 | 2018-07-08 09:09:20+03 | {"updated":true} | one | |
(1 row)
i | ts | j | t | e | c
-----+------------------------+------------------+-----+---+---
144 | 2018-07-08 09:09:20+03 | {"updated":true} | one | |
(1 row)
ROLLBACKĐƯỢC RỒI. Và trong khi nó vẫn còn nóng, hãy thêm chức năng kích hoạt xóa và sao chép nữa:
create trigger tgd before delete on t for each row execute procedure tgf_d();Và kiểm tra:
begin;
delete from t where i = 144;
select * from t where i = 144;
select * from f_t where i = 144;
Rollback;Trao tặng:
DELETE 1
i | ts | j | t | e | c
---+----+---+---+---+---
(0 rows)
i | ts | j | t | e | c
---+----+---+---+---+---
(0 rows)Như chúng tôi nhớ (ai có thể quên điều này!), Chúng tôi không chuyển hỗ trợ "nhân rộng" trong giao dịch. Và chúng ta nên làm nếu chúng ta muốn có dữ liệu nhất quán. Như đã nói ở trên TẤT CẢ các trình kích hoạt câu lệnh trên TẤT CẢ các bảng liên quan đến FK phải được kích hoạt trong một giao dịch, được chuẩn bị trước bằng cách đồng bộ hóa dữ liệu. Nếu không, chúng tôi có thể rơi vào:
begin;
select * from t where i = 3;
delete from t where i = 3;
select * from t where i = 3;
select * from f_t where i = 3;
Rollback;Trao tặng:
p93=# begin;
BEGIN
p93=# select * from t where i = 3;
i | ts | j | t | e | c
---+------------------------+----+---+---+---
3 | 2018-07-08 09:16:27+03 | {} | e | |
(1 row)
p93=# delete from t where i = 3;
DELETE 1
p93=# select * from t where i = 3;
i | ts | j | t | e | c
---+----+---+---+---+---
(0 rows)
p93=# select * from f_t where i = 3;
i | ts | j | t | e | c
---+----+---+---+---+---
(0 rows)
p93=# rollback;Yayki! Chúng tôi đã xóa một hàng trên db phiên bản thấp hơn chứ không phải trên phiên bản mới hơn! Chỉ vì nó không có ở đó. Điều này sẽ không xảy ra nếu chúng tôi làm đúng cách (bắt đầu; đồng bộ hóa; kích hoạt kích hoạt; kết thúc;). Nhưng cách đúng sẽ làm cho các bảng ở chế độ chỉ đọc trong một thời gian dài! Người đọc thông thạo nhất thậm chí sẽ nói "tại sao lúc đó bạn lại kích hoạt sao chép dựa trên?".
Bạn có thể làm điều đó với pg_upgrade như những người “bình thường”. Và trong trường hợp sao chép trực tuyến, bạn có thể đặt tất cả ở chế độ chỉ đọc. Tạm dừng phát lại xlog và nâng cấp chính trong khi ứng dụng vẫn RO là máy chủ.
Một cách chính xác! Tôi đã không bắt đầu với nó?
Nhân rộng dựa trên trình kích hoạt xuất hiện ở giai đoạn khi bạn cần một thứ gì đó rất đặc biệt. Ví dụ:bạn có thể thử cho phép CHỌN và một số sửa đổi trên dữ liệu mới được tạo, không chỉ RO. Giả sử bạn có bảng câu hỏi trực tuyến - người dùng đăng ký, trả lời, nhận điểm thưởng-miễn-phí-khác-không-ai-cần-tuyệt-vời-của anh ta và rời đi. Với cấu trúc như vậy, bạn chỉ có thể cấm sửa đổi dữ liệu chưa có trên phiên bản cao hơn, cho phép toàn bộ luồng dữ liệu cho người dùng mới.
Vì vậy, bạn bỏ rơi một vài người làm việc ATM trực tuyến, để những người mới đến làm việc mà không hề nhận ra rằng bạn đang trong quá trình nâng cấp. Nghe có vẻ kinh khủng, nhưng tôi không nói giả thuyết sao? Tôi đã không? Chà, ý tôi là vậy.
Bất kể trường hợp thực tế có thể là gì, hãy xem cách bạn có thể triển khai nó. Các chức năng xóa và cập nhật sẽ thay đổi. Và bây giờ chúng ta hãy kiểm tra tình huống cuối cùng:
BEGIN
psql:blog.sql:86: ERROR: This data is not replicated yet, thus can't be deleted
psql:blog.sql:87: ERROR: current transaction is aborted, commands ignored until end of transaction block
psql:blog.sql:88: ERROR: current transaction is aborted, commands ignored until end of transaction block
ROLLBACKHàng không bị xóa trên phiên bản thấp hơn vì không tìm thấy hàng trên phiên bản cao hơn. Điều tương tự sẽ xảy ra với cập nhật. Hãy thử nó cho mình. Giờ đây, bạn có thể bắt đầu đồng bộ hóa dữ liệu mà không cần dừng nhiều sửa đổi trên bảng mà bạn đưa vào sao chép dựa trên trình kích hoạt.
Nó có tốt hơn không? Tệ hơn? Nó khác - nó có nhiều sai sót và một số lợi ích so với hệ thống RO toàn cầu. Mục tiêu của tôi là chứng minh tại sao ai đó lại muốn sử dụng phương pháp phức tạp như vậy hơn bình thường - để có được những khả năng cụ thể thông qua một quy trình ổn định, nổi tiếng. Tất nhiên, với một số chi phí…
Vì vậy, bây giờ khi chúng ta cảm thấy an toàn hơn một chút về tính nhất quán của dữ liệu và trong khi dữ liệu hiện có trước đó của chúng ta trong bảng t đang đồng bộ hóa với p10, chúng ta có thể nói về các bảng khác. Tất cả sẽ hoạt động như thế nào với FK (sau khi tất cả tôi đã đề cập đến FK rất nhiều lần, tôi phải đưa nó vào ví dụ). Chà, tại sao phải đợi?
create table c (i serial, t int references t(i), x text);
--and accordingly a foreign table - the one on newer version...
\c p10
create table c (i serial, t int references t(i), x text);
\c p93
create foreign table f_c(i serial, t int, x text) server p10 options (TABLE_name 'c');
--let’s pretend it had some data before we decided to migrate with triggers to a higher version
insert into c (t,x) values (1,'FK');
--- so now we add triggers to replicate DML:
create trigger tgi before insert on c for each row execute procedure tgf_i();
create trigger tgu before update on c for each row execute procedure tgf_u();
create trigger tgd before delete on c for each row execute procedure tgf_d();Chắc chắn giá trị của việc gói ba cái đó thành một hàm với mục đích "kích hoạt" nhiều bảng. Nhưng tôi sẽ không. Vì tôi sẽ không thêm bất kỳ bảng nào nữa - hai cơ sở dữ liệu quan hệ được tham chiếu đã là một mạng hỗn độn như vậy!
--now, what would happen if we tr inserting referenced FK, that does not exist on remote db?..
insert into c (t,x) values (2,'FK');
/* it fails with:
psql:blog.sql:139: ERROR: insert or update on table "c" violates foreign key constraint "c_t_fkey"
a new row isn't inserted neither on remote, nor local db, so we have safe data consistencyy, but inserts are blocked?..
Yes untill data that existed untill trigerising gets to remote db - ou cant insert FK with before triggerising keys, yet - a new (both t and c tables) data will be accepted:
*/
insert into t(i) values(4); --I use gap we got by deleting data above, so I dont need to "returning" and know the exact id -less coding in sample script
insert into c(t) values(4);
select * from c;
select * from f_c;Kết quả là:
psql:blog.sql:109: ERROR: insert or update on table "c" violates foreign key constraint "c_t_fkey"
DETAIL: Key (t)=(2) is not present in table "t".
CONTEXT: Remote SQL command: INSERT INTO public.c(i, t, x) VALUES ($1, $2, $3)
SQL statement "insert into f_c select ($1).*"
PL/pgSQL function tgf_i() line 3 at EXECUTE statement
INSERT 0 1
INSERT 0 1
i | t | x
---+---+----
1 | 1 | FK
3 | 4 |
(2 rows)
i | t | x
---+---+---
3 | 4 |
(1 row)Lần nữa. Có vẻ như dữ liệu đã được thống nhất. Bạn cũng có thể bắt đầu đồng bộ hóa dữ liệu cho bảng c mới…
Mệt nhọc? Tôi chắc chắn là như vậy.
Kết luận
Kết luận, tôi muốn nêu bật một số sai lầm mà tôi đã mắc phải khi xem xét cách tiếp cận này. Trong khi tôi đang xây dựng câu lệnh cập nhật, liệt kê động tất cả các cột từ pg_attribute, tôi đã mất khá nhiều giờ. Hãy tưởng tượng tôi đã thất vọng như thế nào khi thấy sau đó tôi hoàn toàn quên mất cấu trúc UPDATE (list) =(list)! Và hàm chuyển sang trạng thái ngắn hơn và dễ đọc hơn nhiều.
Vì vậy, sai lầm số một là - cố gắng tự mình xây dựng mọi thứ, chỉ vì nó trông rất dễ tiếp cận. Vẫn là như vậy, nhưng như mọi khi, có lẽ ai đó đã làm điều đó tốt hơn - dành hai phút chỉ để kiểm tra xem nó có thực sự như vậy có thể giúp bạn tiết kiệm hàng giờ suy nghĩ sau này không.
Và thứ hai - đối với tôi mọi thứ trông đơn giản hơn nhiều khi chúng hóa ra sâu hơn nhiều và tôi đã phức tạp hóa nhiều trường hợp được mô hình giao dịch PostgreSQL nắm giữ một cách hoàn hảo.
Vì vậy, chỉ sau khi cố gắng xây dựng hộp cát, tôi đã hiểu được phần nào rõ ràng về các ước tính phương pháp này.
Vì vậy, rõ ràng là cần lập kế hoạch, nhưng đừng lập kế hoạch nhiều hơn những gì bạn có thể làm.
Kinh nghiệm đi đôi với thực hành.
Hộp cát của tôi gợi nhớ cho tôi về một chiến lược máy tính - bạn ngồi vào nó sau bữa trưa và nghĩ - “aha, ở đây tôi xây dựng Pyramyd, ở đó tôi bắn cung, sau đó tôi chuyển đổi thành Sons of Ra và chế tạo 20 người cung tên, và ở đây tôi tấn công kẻ thảm hại người hàng xóm. Hai giờ vinh quang ”. Và chắc chắn bạn sẽ thấy mình vào sáng hôm sau, hai giờ trước khi làm việc với “Làm thế nào tôi đến được đây? Tại sao tôi phải ký kết liên minh nhục nhã này với những kẻ man rợ chưa được rửa sạch để cứu người đàn ông cung tên cuối cùng của mình và tôi có thực sự cần phải bán Kim tự tháp được xây dựng rất khó của mình để lấy nó không? ”
Bài đọc:
- https://www.PostgreSQL.org/docs/current/static/dierence-replication-solutions.html
- https://stackoverflow.com/questions/15343075/update-multiple-columns-in-a-trigger- Chức năng-in-plpgsql