Với Phục hồi sau thảm họa, chúng tôi mong muốn thiết lập hệ thống để xử lý bất kỳ điều gì có thể xảy ra với cơ sở dữ liệu của chúng tôi. Điều gì xảy ra nếu cơ sở dữ liệu bị treo? Điều gì sẽ xảy ra nếu một nhà phát triển vô tình cắt bớt một bảng? Điều gì sẽ xảy ra nếu chúng tôi phát hiện ra một số dữ liệu đã bị xóa vào tuần trước nhưng chúng tôi không nhận thấy nó cho đến hôm nay? Những điều này xảy ra và việc có một kế hoạch và hệ thống vững chắc sẽ khiến DBA trông giống như một anh hùng khi trái tim của những người khác đã ngừng đập khi một thảm họa ập đến với cái đầu xấu xí của họ.
Bất kỳ cơ sở dữ liệu nào có bất kỳ loại giá trị nào đều phải có cách triển khai một hoặc nhiều tùy chọn Khôi phục sau thảm họa. PostgreSQL có một hệ thống sao chép rất vững chắc được tích hợp sẵn và đủ linh hoạt để được thiết lập trong nhiều cấu hình để hỗ trợ Khôi phục thảm họa, nếu có bất kỳ sự cố nào xảy ra. Chúng tôi sẽ tập trung vào các tình huống như đã hỏi ở trên, cách thiết lập các tùy chọn Khôi phục sau thảm họa và lợi ích của từng giải pháp.
Tính khả dụng cao
Với tính năng sao chép trực tuyến trong PostgreSQL, Tính sẵn sàng cao rất đơn giản để thiết lập và duy trì. Mục đích là cung cấp một trang web chuyển đổi dự phòng có thể được nâng cấp thành trang chủ nếu cơ sở dữ liệu chính gặp sự cố vì bất kỳ lý do gì, chẳng hạn như lỗi phần cứng, lỗi phần mềm hoặc thậm chí là mất mạng. Lưu trữ một bản sao trên một máy chủ khác là điều tuyệt vời, nhưng lưu trữ nó trong một trung tâm dữ liệu khác thậm chí còn tốt hơn.
Để biết thông tin chi tiết cụ thể về cách thiết lập tính năng sao chép phát trực tuyến, Somenines có thông tin chi tiết về các thông tin chi tiết tại đây. Tài liệu chính thức của PostgreSQL Streaming Replication có thông tin chi tiết về giao thức sao chép streaming và cách thức hoạt động của tất cả.
Một thiết lập tiêu chuẩn sẽ giống như thế này, một cơ sở dữ liệu chính chấp nhận các kết nối đọc / ghi, với một cơ sở dữ liệu bản sao nhận tất cả hoạt động WAL trong thời gian gần thực, phát lại tất cả các hoạt động thay đổi dữ liệu cục bộ.
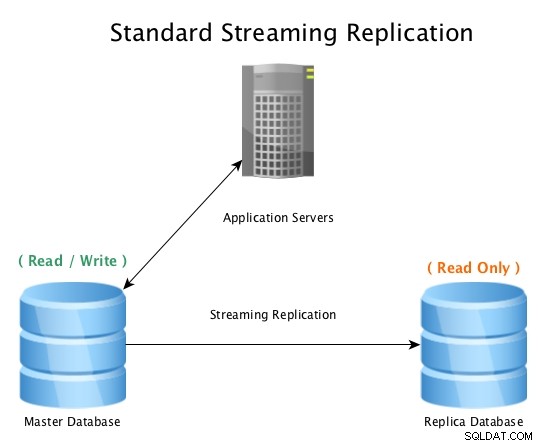 Sao chép phát trực tuyến tiêu chuẩn với PostgreSQL
Sao chép phát trực tuyến tiêu chuẩn với PostgreSQL Khi cơ sở dữ liệu chính trở nên không sử dụng được, một quy trình chuyển đổi dự phòng được bắt đầu để đưa nó ngoại tuyến và thúc đẩy cơ sở dữ liệu bản sao trở thành chủ, sau đó trỏ tất cả các kết nối đến máy chủ mới được thăng cấp. Điều này có thể được thực hiện bằng cách định cấu hình lại bộ cân bằng tải, cấu hình ứng dụng, bí danh IP hoặc các cách thông minh khác để chuyển hướng lưu lượng truy cập.
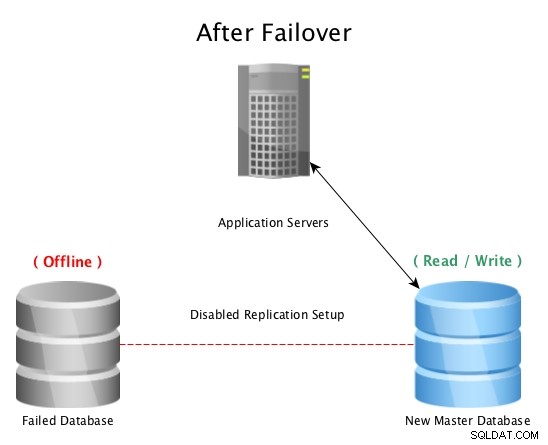 Sau khi chuyển đổi dự phòng với PostgreSQL Streaming Replication
Sau khi chuyển đổi dự phòng với PostgreSQL Streaming Replication Khi thảm họa xảy ra với cơ sở dữ liệu chính (chẳng hạn như lỗi ổ cứng, mất điện hoặc bất cứ điều gì ngăn cản cơ sở dữ liệu chính hoạt động như dự định), việc chuyển sang chế độ chờ nóng là cách nhanh nhất để luôn trực tuyến phục vụ các truy vấn cho ứng dụng hoặc khách hàng mà không nghiêm trọng thời gian chết. Sau đó, cuộc đua bắt đầu để sửa máy chủ cơ sở dữ liệu bị lỗi hoặc đưa một bản sao mới lên mạng để duy trì mạng lưới an toàn luôn sẵn sàng hoạt động. Việc có nhiều standby sẽ đảm bảo rằng cửa sổ sau một sự cố thảm hại cũng sẵn sàng cho một sự cố thứ cấp, tuy nhiên điều đó có vẻ khó xảy ra.
Lưu ý:Khi không thực hiện được bản sao trực tuyến, nó sẽ tiếp tục vị trí của bản sao trước đó đã dừng lại, vì vậy điều này giúp giữ cơ sở dữ liệu trực tuyến nhưng không khôi phục dữ liệu vô tình bị mất.
Khôi phục thời điểm
Một tùy chọn Khôi phục thảm họa khác là Điểm trong Khôi phục TIme (PITR). Với PITR, bản sao của cơ sở dữ liệu có thể được đưa trở lại bất kỳ lúc nào chúng tôi muốn, miễn là chúng tôi có bản sao lưu cơ sở từ trước thời điểm đó và tất cả các phân đoạn WAL cần thiết cho đến thời điểm đó.
Tùy chọn Point In Time Recovery không được đưa lên mạng nhanh chóng như Chế độ chờ nóng, tuy nhiên lợi ích chính là có thể khôi phục ảnh chụp nhanh cơ sở dữ liệu trước một sự kiện lớn như bảng bị xóa, dữ liệu xấu được chèn hoặc thậm chí là hỏng dữ liệu không thể giải thích được . Bất cứ điều gì có thể phá hủy dữ liệu theo cách mà chúng tôi muốn có được một bản sao trước khi phá hủy đó, PITR sẽ tiết kiệm trong ngày.
Point in Time Recovery hoạt động bằng cách tạo ảnh chụp nhanh định kỳ của cơ sở dữ liệu, thường bằng cách sử dụng chương trình pg_basebackup và giữ các bản sao lưu trữ của tất cả các tệp WAL được tạo bởi bản gốc
Thiết lập khôi phục điểm trong thời gian
Thiết lập yêu cầu một số tùy chọn cấu hình được đặt trên bản chính, một số tùy chọn cấu hình phù hợp với các giá trị mặc định trên phiên bản mới nhất hiện tại, PostgreSQL 11. Trong ví dụ này, chúng tôi sẽ sao chép tệp 16MB trực tiếp vào máy chủ PITR từ xa của chúng tôi bằng rsync và nén chúng ở phía bên kia bằng cron job.
Lưu trữ WAL
Làm chủ postgresql.conf
wal_level = replica
archive_mode = on
archive_command = 'rsync -av -z %p example@sqldat.com:/mnt/db/wal_archive/%f'LƯU Ý: Việc thiết lập archive_command có thể là nhiều thứ, mục tiêu chung là gửi tất cả các tệp WAL đã lưu trữ sang một máy chủ khác vì mục đích an toàn. Nếu chúng tôi mất bất kỳ tệp WAL nào, thì việc PITR qua tệp WAL bị mất sẽ không thể thực hiện được. Hãy để sự sáng tạo trong lập trình của bạn trở nên điên cuồng nhưng hãy đảm bảo rằng nó đáng tin cậy.
[Tùy chọn] Nén tệp WAL đã lưu trữ:
Mọi thiết lập sẽ khác nhau đôi chút, nhưng trừ khi cơ sở dữ liệu được đề cập rất nhẹ trong việc cập nhật dữ liệu, việc tích hợp các tệp 16MB sẽ lấp đầy dung lượng ổ đĩa khá nhanh chóng. Một tập lệnh nén dễ dàng, được thiết lập thông qua cron, có thể trông giống như bên dưới.
nén_WAL_archive.sh:
#!/bin/bash
# Compress any WAL files found that are not yet compressed
gzip /mnt/db/wal_archive/*[0-F]LƯU Ý: Trong bất kỳ phương pháp khôi phục nào, bất kỳ tệp nén nào sẽ cần được giải nén sau đó. Một số quản trị viên chọn chỉ nén các tệp sau khi chúng được X số ngày, giữ cho dung lượng tổng thể ở mức thấp, nhưng cũng giữ cho các tệp WAL gần đây hơn sẵn sàng để khôi phục mà không cần làm thêm. Chọn tùy chọn tốt nhất cho cơ sở dữ liệu được đề cập để tối đa hóa tốc độ khôi phục của bạn.
Bản sao lưu cơ sở
Một trong những thành phần quan trọng của bản sao lưu PITR là bản sao lưu cơ sở và tần suất sao lưu cơ sở. Đây có thể là hàng giờ, hàng ngày, hàng tuần, hàng tháng, nhưng đã chọn tùy chọn tốt nhất dựa trên nhu cầu khôi phục cũng như lưu lượng truy cập dữ liệu cơ sở dữ liệu. Nếu chúng tôi có các bản sao lưu hàng tuần vào Chủ nhật hàng tuần và chúng tôi cần khôi phục đến chiều thứ Bảy, thì chúng tôi đưa bản sao lưu cơ sở của Chủ nhật trước đó lên mạng cùng với tất cả các tệp WAL giữa bản sao lưu đó và chiều thứ Bảy. Nếu quá trình khôi phục này mất 10 giờ để xử lý, điều này có thể là quá lâu không thể tránh khỏi, Sao lưu cơ sở hàng ngày sẽ giảm thời gian khôi phục đó, vì sao lưu cơ sở sẽ được thực hiện từ sáng hôm đó, nhưng cũng tăng khối lượng công việc trên máy chủ để sao lưu cơ sở chính nó.
Nếu quá trình khôi phục các tệp WAL kéo dài một tuần chỉ mất vài phút, vì cơ sở dữ liệu nhận thấy sự gián đoạn thấp, thì các bản sao lưu hàng tuần vẫn ổn. Cuối cùng thì cùng một dữ liệu nhưng bạn có thể truy cập dữ liệu đó nhanh đến mức nào mới là yếu tố then chốt.
Trong ví dụ của chúng tôi, chúng tôi sẽ thiết lập một bản sao lưu cơ sở hàng tuần và vì chúng tôi đang sử dụng tính năng Streaming Replication để có tính khả dụng cao, cũng như giảm tải trên bản chính, chúng tôi sẽ tạo bản sao lưu cơ sở từ cơ sở dữ liệu bản sao.
base_backup.sh:
#!/bin/bash
backup_dir="$(date +'%Y-%m-%d')_backup"
cd /mnt/db/backups
mkdir $backup_dir
pg_basebackup -h <replica host> -p <replica port> -U replication -D $backup_dir -Ft -zLƯU Ý: Lệnh pg_basebackup giả sử máy chủ này được thiết lập để truy cập không cần mật khẩu để người dùng 'nhân bản' trên máy chủ, có thể được thực hiện bằng cách 'tin cậy' trong pg_hba cho máy chủ sao lưu PITR này, mật khẩu trong tệp .pgpass hoặc các cách khác an toàn hơn . Hãy lưu ý đến bảo mật khi thiết lập sao lưu.
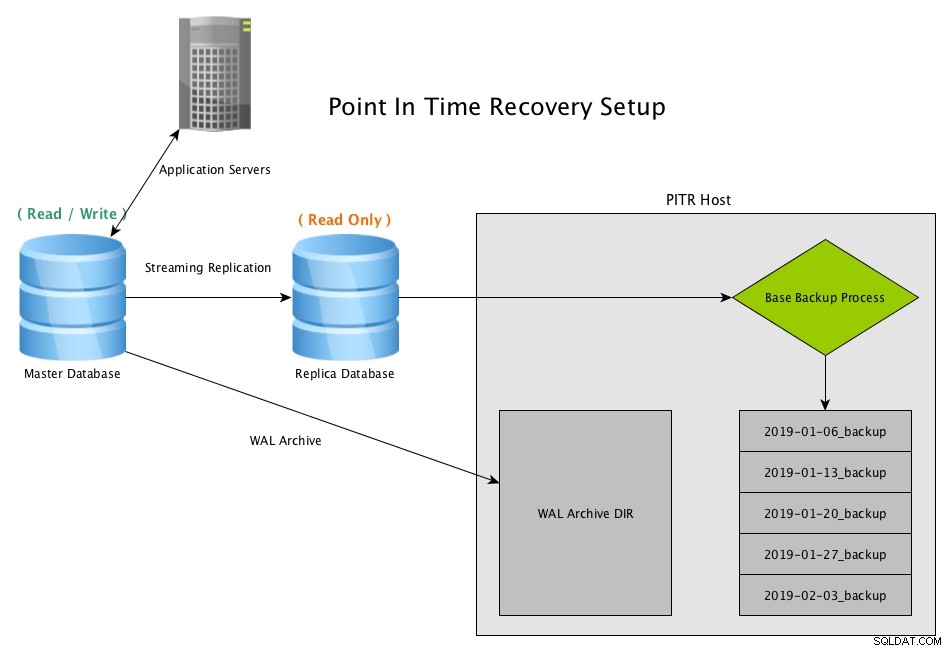 Point In Time Recovery (PITR) tắt bản sao truyền trực tuyến với PostgreSQLTải xuống báo cáo hôm nay Quản lý và tự động hóa PostgreSQL với ClusterControlTìm hiểu về những điều bạn cần biết để triển khai, giám sát, quản lý và mở rộng PostgreSQL
Point In Time Recovery (PITR) tắt bản sao truyền trực tuyến với PostgreSQLTải xuống báo cáo hôm nay Quản lý và tự động hóa PostgreSQL với ClusterControlTìm hiểu về những điều bạn cần biết để triển khai, giám sát, quản lý và mở rộng PostgreSQL Tình huống khôi phục PITR
Thiết lập Point In Time Recovery chỉ là một phần của công việc, phải khôi phục dữ liệu mới là phần khác. Chúc may mắn, điều này có thể không bao giờ phải xảy ra, tuy nhiên, chúng tôi khuyên bạn nên thực hiện định kỳ khôi phục bản sao lưu PITR để xác thực rằng hệ thống có hoạt động hay không và để đảm bảo quy trình được biết / viết đúng tập lệnh.
Trong tình huống thử nghiệm của chúng tôi, chúng tôi sẽ chọn một thời điểm để khôi phục và bắt đầu quá trình khôi phục. Ví dụ:Sáng thứ Sáu, một nhà phát triển đẩy một thay đổi mã mới vào sản xuất mà không cần qua xem xét mã và nó phá hủy một loạt dữ liệu khách hàng quan trọng. Vì Chế độ chờ nóng của chúng tôi luôn đồng bộ với chế độ chính, nên việc không thực hiện được sẽ không khắc phục được bất kỳ điều gì, vì đó sẽ là cùng một dữ liệu. Sao lưu PITR là thứ sẽ giúp chúng ta tiết kiệm.
Quá trình đẩy mã bắt đầu vào lúc 11 giờ sáng, vì vậy chúng tôi cần khôi phục cơ sở dữ liệu về ngay trước thời điểm đó, 10:59 sáng chúng tôi quyết định và may mắn là chúng tôi thực hiện sao lưu hàng ngày nên chúng tôi có bản sao lưu từ nửa đêm sáng nay. Vì chúng tôi không biết tất cả những gì đã bị phá hủy, chúng tôi cũng quyết định khôi phục toàn bộ cơ sở dữ liệu này trên máy chủ PITR của chúng tôi và đưa nó trực tuyến dưới dạng máy chủ, vì nó có cùng thông số kỹ thuật phần cứng với máy chủ, đề phòng trường hợp này kịch bản đã xảy ra.
Tắt máy chủ
Vì chúng tôi đã quyết định khôi phục toàn bộ từ bản sao lưu và thăng cấp thành bản chính, nên không cần phải giữ bản sao lưu này trực tuyến. Chúng tôi đã tắt nó, nhưng vẫn giữ nó trong trường hợp chúng ta cần lấy bất cứ thứ gì từ nó sau này, đề phòng.
Thiết lập sao lưu cơ sở để phục hồi
Tiếp theo, trên máy chủ PITR của chúng tôi, chúng tôi tìm nạp bản sao lưu cơ sở gần đây nhất của mình từ trước sự kiện, đó là bản sao lưu ‘2018-12-21_backup’.
mkdir /var/lib/pgsql/11/data
chmod 700 /var/lib/pgsql/11/data
cd /var/lib/pgsql/11/data
tar -xzvf /mnt/db/backups/2018-12-21_backup/base.tar.gz
cd pg_wal
tar -xzvf /mnt/db/backups/2018-12-21_backup/pg_wal.tar.gz
mkdir /mnt/db/wal_archive/pitr_restore/Với điều này, bản sao lưu cơ sở, cũng như các tệp WAL được cung cấp bởi pg_basebackup đã sẵn sàng hoạt động, nếu chúng tôi đưa nó trực tuyến ngay bây giờ, nó sẽ khôi phục tại thời điểm sao lưu đã diễn ra, nhưng chúng tôi muốn khôi phục tất cả các giao dịch WAL giữa nửa đêm và 11:59 sáng, vì vậy chúng tôi đã thiết lập tệp recovery.conf của mình.
Tạo recovery.conf
Vì bản sao lưu này thực sự đến từ một bản sao phát trực tuyến, nên có thể đã có một tệp recovery.conf với cài đặt bản sao. Chúng tôi sẽ ghi đè nó bằng các cài đặt mới. Danh sách thông tin chi tiết cho tất cả các tùy chọn khác nhau có sẵn trong tài liệu của PostgreSQL tại đây.
Cẩn thận với các tệp WAL, lệnh khôi phục sẽ sao chép các tệp nén mà nó cần vào thư mục khôi phục, giải nén chúng, sau đó di chuyển đến nơi PostgreSQL cần chúng để khôi phục. Các tệp WAL gốc sẽ vẫn ở nơi chúng được đặt trong trường hợp cần thiết vì bất kỳ lý do nào khác.
recovery.conf mới:
recovery_target_time = '2018-12-21 11:59:00-07'
restore_command = 'cp /mnt/db/wal_archive/%f.gz /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && gunzip /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && mv /var/lib/pgsql/test_recovery/pitr_restore/%f "%p"'Bắt đầu quá trình khôi phục
Bây giờ mọi thứ đã được thiết lập, chúng tôi sẽ bắt đầu quá trình khôi phục. Khi điều này xảy ra, bạn nên chỉnh sửa nhật ký cơ sở dữ liệu để đảm bảo rằng nó đang khôi phục như dự định.
Khởi động DB:
pg_ctl -D /var/lib/pgsql/11/data startĐuôi nhật ký:
Sẽ có nhiều mục nhật ký cho thấy cơ sở dữ liệu đang khôi phục từ các tệp lưu trữ và tại một thời điểm nhất định, nó sẽ hiển thị một dòng cho biết “ngừng khôi phục trước khi cam kết giao dịch…”
2018-12-22 04:21:30 UTC [20565]: [705-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000074" from archive
2018-12-22 04:21:30 UTC [20565]: [706-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000075" from archive
2018-12-22 04:21:31 UTC [20565]: [707-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000076" from archive
2018-12-22 04:21:31 UTC [20565]: [708-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000077" from archive
2018-12-22 04:21:31 UTC [20565]: [709-1] user=,db=,app=,client= LOG: recovery stopping before commit of transaction 611765, time 2018-12-21 11:59:01.45545+07Tại thời điểm này, quá trình khôi phục đã nhập tất cả các tệp WAL, nhưng cũng cần được xem xét trước khi nó xuất hiện trực tuyến như một tệp chính. Trong ví dụ này, nhật ký lưu ý rằng giao dịch tiếp theo sau thời gian mục tiêu khôi phục 11:59:00 là 11:59:01 và nó chưa được phục hồi. Để xác minh, hãy đăng nhập vào cơ sở dữ liệu và xem xét, cơ sở dữ liệu đang chạy phải là ảnh chụp nhanh chính xác là 11:59.
Khi mọi thứ có vẻ ổn, đã đến lúc thúc đẩy quá trình khôi phục với tư cách là một bậc thầy.
postgres=# SELECT pg_wal_replay_resume();
pg_wal_replay_resume
----------------------
(1 row)Bây giờ, cơ sở dữ liệu đang trực tuyến, được phục hồi đến thời điểm chúng tôi quyết định và chấp nhận các kết nối đọc / ghi như một nút chính. Đảm bảo tất cả các thông số cấu hình đều chính xác và sẵn sàng để sản xuất.
Cơ sở dữ liệu đang trực tuyến, nhưng quá trình khôi phục vẫn chưa được thực hiện! Giờ đây, bản sao lưu PITR này đang trực tuyến dưới dạng bản chính, nên thiết lập chế độ chờ và PITR mới sẽ được thiết lập, cho đến lúc đó bản sao mới này có thể trực tuyến và phục vụ các ứng dụng, nhưng sẽ không an toàn trước một thảm họa khác cho đến khi tất cả được thiết lập lại.
Các tình huống khôi phục thời điểm khác
Mang lại một bản sao lưu PITR cho toàn bộ cơ sở dữ liệu là một trường hợp cực kỳ nghiêm trọng, nhưng vẫn có những trường hợp khác khi chỉ một tập hợp con dữ liệu bị thiếu, bị hỏng hoặc bị lỗi. Trong những trường hợp này, chúng tôi có thể sáng tạo với các tùy chọn khôi phục của mình. Không cần đưa bản chính vào ngoại tuyến và thay thế nó bằng bản sao lưu, chúng tôi có thể đưa bản sao lưu PITR trực tuyến đến thời điểm chính xác mà chúng tôi muốn trên một máy chủ lưu trữ khác (hoặc một cổng khác nếu dung lượng không phải là vấn đề) và xuất dữ liệu đã khôi phục từ bản sao lưu trực tiếp vào cơ sở dữ liệu chính. Điều này có thể được sử dụng để khôi phục một số ít hàng, một số bảng hoặc bất kỳ cấu hình dữ liệu nào cần thiết.
Với tính năng sao chép trực tuyến và khôi phục điểm trong thời gian, PostgreSQL mang đến cho chúng tôi sự linh hoạt tuyệt vời trong việc đảm bảo rằng chúng tôi có thể khôi phục bất kỳ dữ liệu nào chúng tôi cần, miễn là chúng tôi có các máy chủ dự phòng sẵn sàng hoạt động như một máy chủ hoặc các bản sao lưu sẵn sàng khôi phục. Tùy chọn Khôi phục thảm họa tốt có thể được mở rộng hơn nữa với các tùy chọn sao lưu khác, nhiều nút bản sao hơn, nhiều trang web sao lưu trên các trung tâm dữ liệu và lục địa khác nhau, pg_dumps định kỳ trên một bản sao khác, v.v.
Những tùy chọn này có thể cộng lại, nhưng câu hỏi thực sự là "dữ liệu có giá trị như thế nào và bạn sẵn sàng chi bao nhiêu để lấy lại?". Trong nhiều trường hợp, việc mất dữ liệu là dấu hiệu chấm dứt hoạt động kinh doanh, vì vậy cần có các tùy chọn Khôi phục sau thảm họa tốt để ngăn chặn điều tồi tệ nhất xảy ra.