Trong lịch sử, nhiệm vụ khó nhất khi làm việc với PostgreSQL là xử lý các bản nâng cấp. Cách nâng cấp trực quan nhất mà bạn có thể nghĩ đến là tạo một bản sao trong một phiên bản mới và thực hiện chuyển đổi dự phòng ứng dụng sang nó. Với PostgreSQL, điều này đơn giản là không thể thực hiện theo cách gốc. Để hoàn thành nâng cấp, bạn cần nghĩ đến các cách nâng cấp khác, chẳng hạn như sử dụng pg_upgrade, hủy và khôi phục hoặc sử dụng một số công cụ của bên thứ ba như Slony hoặc Bucardo, tất cả chúng đều có những lưu ý riêng.
Tại sao lại như vậy? Do cách PostgreSQL triển khai nhân rộng.
Sao chép trực tuyến tích hợp trong PostgreSQL được gọi là vật lý:nó sẽ sao chép các thay đổi ở cấp độ từng byte, tạo ra một bản sao giống hệt của cơ sở dữ liệu trong một máy chủ khác. Phương pháp này có rất nhiều hạn chế khi nghĩ đến việc nâng cấp, vì bạn không thể tạo bản sao trong một phiên bản máy chủ khác hoặc thậm chí trong một kiến trúc khác.
Vì vậy, đây là nơi PostgreSQL 10 trở thành một người thay đổi cuộc chơi. Với các phiên bản 10 và 11 mới này, PostgreSQL triển khai sao chép logic tích hợp, trái ngược với sao chép vật lý, bạn có thể sao chép giữa các phiên bản chính khác nhau của PostgreSQL. Tất nhiên, điều này sẽ mở ra một cánh cửa mới cho các chiến lược nâng cấp.
Trong blog này, hãy xem cách chúng ta có thể nâng cấp PostgreSQL 10 lên PostgreSQL 11 với thời gian chết bằng không bằng cách sử dụng bản sao lôgic. Trước hết, hãy xem qua phần giới thiệu về sao chép hợp lý.
Sao chép lôgic là gì?
Sao chép lôgic là một phương pháp sao chép các đối tượng dữ liệu và các thay đổi của chúng, dựa trên nhận dạng bản sao của chúng (thường là một khóa chính). Nó dựa trên chế độ xuất bản và đăng ký, trong đó một hoặc nhiều người đăng ký đăng ký một hoặc nhiều ấn phẩm trên một nút nhà xuất bản.
Ấn phẩm là một tập hợp các thay đổi được tạo ra từ một bảng hoặc một nhóm bảng (còn được gọi là tập hợp nhân bản). Nút nơi một ấn phẩm được xác định được gọi là nhà xuất bản. Đăng ký là mặt sau của sao chép hợp lý. Nút nơi đăng ký được xác định được gọi là người đăng ký và nó xác định kết nối với cơ sở dữ liệu khác và tập hợp các ấn phẩm (một hoặc nhiều) mà nó muốn đăng ký. Người đăng ký lấy dữ liệu từ các ấn phẩm mà họ đăng ký.
Bản sao lôgic được xây dựng với kiến trúc tương tự như bản sao luồng vật lý. Nó được thực hiện bởi các quy trình "walsender" và "apply". Quá trình walsender bắt đầu giải mã logic của WAL và tải plugin giải mã logic tiêu chuẩn. Plugin chuyển các thay đổi được đọc từ WAL sang giao thức sao chép hợp lý và lọc dữ liệu theo đặc điểm kỹ thuật xuất bản. Sau đó, dữ liệu được chuyển liên tục bằng cách sử dụng giao thức sao chép trực tuyến tới trình xử lý ứng dụng, ánh xạ dữ liệu tới các bảng cục bộ và áp dụng các thay đổi riêng lẻ khi chúng được nhận, theo thứ tự giao dịch chính xác.
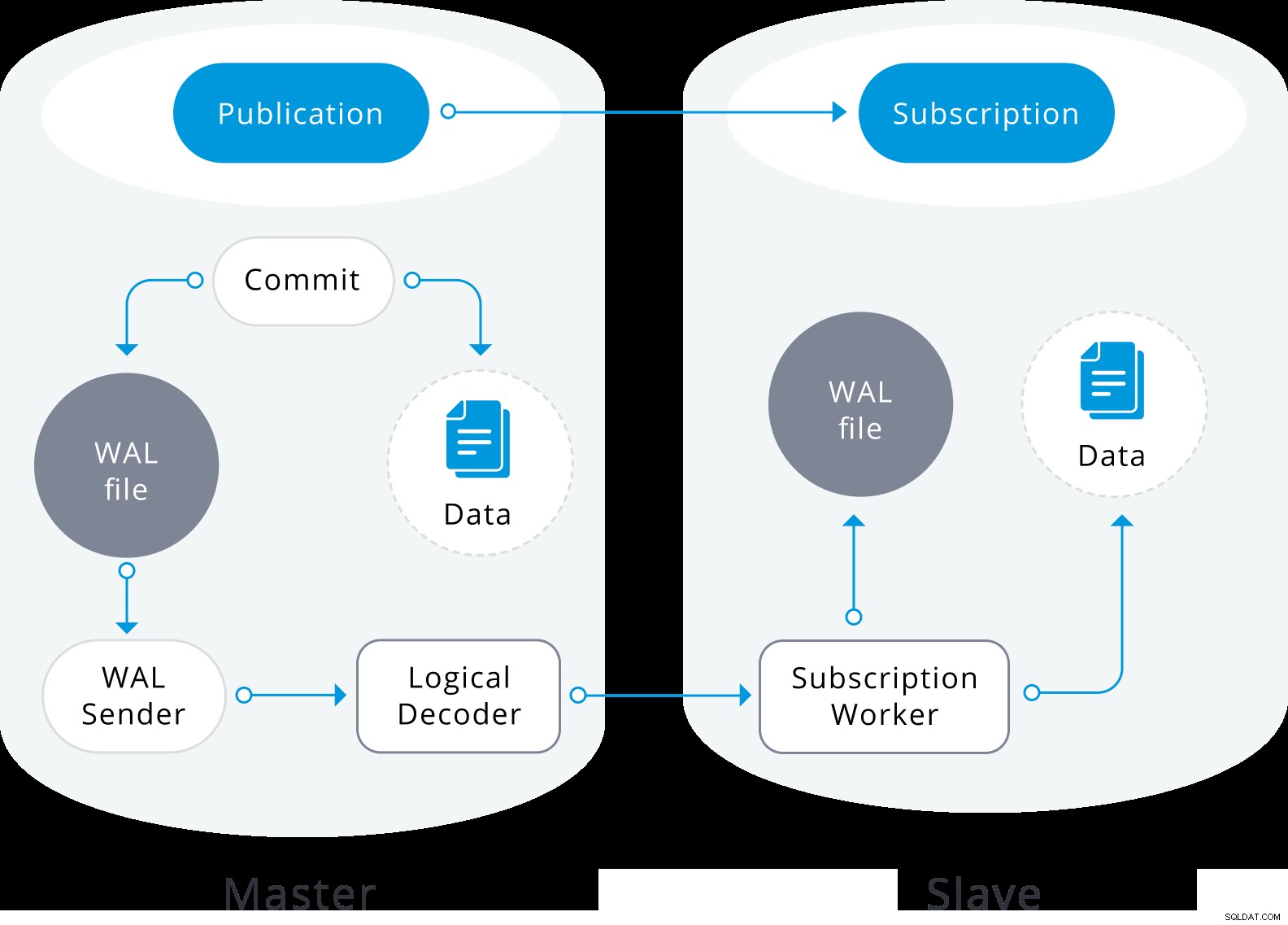 Sơ đồ sao chép lôgic
Sơ đồ sao chép lôgic Việc sao chép lôgic bắt đầu bằng cách chụp nhanh dữ liệu trên cơ sở dữ liệu của nhà xuất bản và sao chép dữ liệu đó cho người đăng ký. Dữ liệu ban đầu trong các bảng đã đăng ký hiện có được chụp nhanh và sao chép trong một phiên bản song song của một loại quy trình áp dụng đặc biệt. Quá trình này sẽ tạo khe sao chép tạm thời của riêng nó và sao chép dữ liệu hiện có. Khi dữ liệu hiện có được sao chép, worker sẽ vào chế độ đồng bộ hóa, điều này đảm bảo rằng bảng được đưa đến trạng thái đồng bộ với quy trình áp dụng chính bằng cách phát trực tuyến bất kỳ thay đổi nào đã xảy ra trong quá trình sao chép dữ liệu ban đầu bằng cách sử dụng sao chép logic tiêu chuẩn. Khi quá trình đồng bộ hóa được thực hiện xong, việc kiểm soát quá trình sao chép bảng được đưa trở lại quy trình áp dụng chính, nơi quá trình sao chép vẫn tiếp tục như bình thường. Các thay đổi về nhà xuất bản được gửi đến người đăng ký khi chúng xảy ra trong thời gian thực.
Bạn có thể tìm thêm về sao chép hợp lý trong các blog sau:
- Tổng quan về sao chép lôgic trong PostgreSQL
- Sao chép luồng PostgreSQL so với Sao chép lôgic
Cách nâng cấp PostgreSQL 10 lên PostgreSQL 11 bằng cách sử dụng bản sao lôgic
Vì vậy, bây giờ chúng tôi đã biết tính năng mới này là gì, chúng tôi có thể suy nghĩ về cách chúng tôi có thể sử dụng nó để giải quyết vấn đề nâng cấp.
Chúng tôi sẽ định cấu hình sao chép hợp lý giữa hai phiên bản chính khác nhau của PostgreSQL (10 và 11), và tất nhiên, sau khi bạn làm việc này, chỉ cần thực hiện chuyển đổi dự phòng ứng dụng vào cơ sở dữ liệu với phiên bản mới hơn.
Chúng tôi sẽ thực hiện các bước sau để đưa tính năng sao chép hợp lý hoạt động:
- Định cấu hình nút nhà xuất bản
- Định cấu hình nút người đăng ký
- Tạo người dùng đăng ký
- Tạo một ấn phẩm
- Tạo cấu trúc bảng trong người đăng ký
- Tạo đăng ký
- Kiểm tra trạng thái sao chép
Vậy hãy bắt đầu.
Về phía nhà xuất bản, chúng tôi sẽ định cấu hình các thông số sau trong tệp postgresql.conf:
- listening_addresses:(Các) địa chỉ IP nào để nghe. Chúng tôi sẽ sử dụng '*' cho tất cả.
- wal_level:Xác định lượng thông tin được ghi vào WAL. Chúng tôi sẽ đặt nó thành logic.
- max_replication_slots:Chỉ định số lượng khe sao chép tối đa mà máy chủ có thể hỗ trợ. Nó phải được đặt thành ít nhất số lượng đăng ký dự kiến kết nối, cộng với một số dự trữ để đồng bộ hóa bảng.
- max_wal_senders:Chỉ định số lượng kết nối đồng thời tối đa từ máy chủ dự phòng hoặc máy khách sao lưu cơ sở phát trực tuyến. Nó phải được đặt thành ít nhất bằng max_replication_slots cộng với số lượng bản sao vật lý được kết nối cùng một lúc.
Hãy nhớ rằng một số tham số này yêu cầu khởi động lại dịch vụ PostgreSQL để áp dụng.
Tệp pg_hba.conf cũng cần được điều chỉnh để cho phép sao chép. Chúng tôi cần cho phép người dùng sao chép kết nối với cơ sở dữ liệu.
Vì vậy, dựa trên điều này, hãy định cấu hình nhà xuất bản của chúng tôi (trong trường hợp này là máy chủ PostgreSQL 10 của chúng tôi) như sau:
- postgresql.conf:
listen_addresses = '*' wal_level = logical max_wal_senders = 8 max_replication_slots = 4 - pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD host all rep 192.168.100.144/32 md5
Chúng tôi phải thay đổi người dùng (trong bản đại diện ví dụ của chúng tôi), người dùng sẽ được sử dụng để sao chép và địa chỉ IP 192.168.100.144/32 cho IP tương ứng với PostgreSQL 11.
Về phía người đăng ký, nó cũng yêu cầu max_replication_slots phải được đặt. Trong trường hợp này, nó phải được đặt thành ít nhất số lượng đăng ký sẽ được thêm vào người đăng ký.
Các tham số khác cũng cần được đặt ở đây là:
- max_logical_replication_workers:Chỉ định số lượng nhân viên sao chép lôgic tối đa. Điều này bao gồm cả công nhân áp dụng và công nhân đồng bộ hóa bảng. Các công nhân sao chép lôgic được lấy từ nhóm được xác định bởi max_worker_processes. Nó phải được đặt thành ít nhất số lượng đăng ký, một lần nữa cộng với một số dự trữ để đồng bộ hóa bảng.
- max_worker_processes:Đặt số lượng quy trình nền tối đa mà hệ thống có thể hỗ trợ. Nó có thể cần được điều chỉnh để phù hợp với nhân viên nhân bản, ít nhất là max_logical_replication_workers + 1. Tham số này yêu cầu khởi động lại PostgreSQL.
Vì vậy, chúng tôi phải định cấu hình người đăng ký của mình (trong trường hợp này là máy chủ PostgreSQL 11 của chúng tôi) như sau:
- postgresql.conf:
listen_addresses = '*' max_replication_slots = 4 max_logical_replication_workers = 4 max_worker_processes = 8
Vì PostgreSQL 11 này sẽ sớm là bản chính mới của chúng tôi, chúng tôi nên xem xét thêm các tham số wal_level và archive_mode trong bước này, để tránh khởi động lại dịch vụ mới sau này.
wal_level = logical
archive_mode = onCác tham số này sẽ hữu ích nếu chúng ta muốn thêm một nô lệ sao chép mới hoặc để sử dụng các bản sao lưu PITR.
Trong nhà xuất bản, chúng tôi phải tạo người dùng mà người đăng ký của chúng tôi sẽ kết nối:
world=# CREATE ROLE rep WITH LOGIN PASSWORD '*****' REPLICATION;
CREATE ROLEVai trò được sử dụng cho kết nối sao chép phải có thuộc tính REPLICATION. Quyền truy cập cho vai trò phải được định cấu hình trong pg_hba.conf và nó phải có thuộc tính LOGIN.
Để có thể sao chép dữ liệu ban đầu, vai trò được sử dụng cho kết nối sao chép phải có đặc quyền CHỌN trên bảng đã xuất bản.
world=# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep;
GRANTChúng tôi sẽ tạo ấn phẩm pub1 trong nút nhà xuất bản, cho tất cả các bảng:
world=# CREATE PUBLICATION pub1 FOR ALL TABLES;
CREATE PUBLICATIONNgười dùng sẽ tạo ấn phẩm phải có đặc quyền TẠO trong cơ sở dữ liệu, nhưng để tạo ấn phẩm tự động xuất bản tất cả các bảng, người dùng phải là siêu người dùng.
Để xác nhận ấn phẩm được tạo, chúng tôi sẽ sử dụng danh mục pg_publication. Danh mục này chứa thông tin về tất cả các ấn phẩm được tạo trong cơ sở dữ liệu.
world=# SELECT * FROM pg_publication;
-[ RECORD 1 ]+------
pubname | pub1
pubowner | 16384
puballtables | t
pubinsert | t
pubupdate | t
pubdelete | tMô tả cột:
- pubname:Tên của ấn phẩm.
- pubowner:Chủ sở hữu của ấn phẩm.
- puballtables:Nếu đúng, ấn phẩm này tự động bao gồm tất cả các bảng trong cơ sở dữ liệu, bao gồm bất kỳ bảng nào sẽ được tạo trong tương lai.
- pubinsert:Nếu đúng, các thao tác INSERT sẽ được sao chép cho các bảng trong ấn phẩm.
- pubupdate:Nếu đúng, các thao tác UPDATE sẽ được sao chép cho các bảng trong ấn phẩm.
- pubdelete:Nếu đúng, các hoạt động DELETE được sao chép cho các bảng trong ấn phẩm.
Vì lược đồ không được sao chép, chúng ta phải tạo một bản sao lưu trong PostgreSQL 10 và khôi phục nó trong PostgreSQL 11. Bản sao lưu sẽ chỉ được thực hiện cho lược đồ, vì thông tin sẽ được sao chép trong lần chuyển đầu tiên.
Trong PostgreSQL 10:
$ pg_dumpall -s > schema.sqlTrong PostgreSQL 11:
$ psql -d postgres -f schema.sqlKhi chúng tôi có lược đồ của mình trong PostgreSQL 11, chúng tôi tạo đăng ký, thay thế các giá trị của máy chủ lưu trữ, dbname, người dùng và mật khẩu bằng những giá trị tương ứng với môi trường của chúng tôi.
PostgreSQL 11:
world=# CREATE SUBSCRIPTION sub1 CONNECTION 'host=192.168.100.143 dbname=world user=rep password=*****' PUBLICATION pub1;
NOTICE: created replication slot "sub1" on publisher
CREATE SUBSCRIPTIONỞ trên sẽ bắt đầu quá trình sao chép, đồng bộ hóa nội dung mục lục ban đầu của các bảng trong ấn phẩm và sau đó bắt đầu sao chép các thay đổi gia tăng đối với các bảng đó.
Người dùng tạo đăng ký phải là người dùng cấp cao. Quá trình đăng ký đăng ký sẽ chạy trong cơ sở dữ liệu cục bộ với các đặc quyền của người dùng cấp cao.
Để xác minh đăng ký đã tạo, chúng tôi có thể sử dụng danh mục pg_stat_subscription. Dạng xem này sẽ chứa một hàng cho mỗi đăng ký đối với công nhân chính (với PID rỗng nếu công nhân không chạy) và các hàng bổ sung cho công nhân xử lý bản sao dữ liệu ban đầu của các bảng đã đăng ký.
world=# SELECT * FROM pg_stat_subscription;
-[ RECORD 1 ]---------+------------------------------
subid | 16428
subname | sub1
pid | 1111
relid |
received_lsn | 0/172AF90
last_msg_send_time | 2018-12-05 22:11:45.195963+00
last_msg_receipt_time | 2018-12-05 22:11:45.196065+00
latest_end_lsn | 0/172AF90
latest_end_time | 2018-12-05 22:11:45.195963+00Mô tả cột:
- subid:OID của đăng ký.
- subname:Tên của gói đăng ký.
- pid:ID quy trình của quy trình nhân viên đăng ký.
- relid:OID của mối quan hệ mà worker đang đồng bộ hóa; null cho công nhân áp dụng chính.
- get_lsn:Đã nhận được vị trí nhật ký ghi trước lần cuối, giá trị ban đầu của trường này là 0.
- last_msg_send_time:Gửi thời gian của tin nhắn cuối cùng nhận được từ người gửi WAL gốc.
- last_msg_receipt_time:Thời gian nhận của tin nhắn cuối cùng nhận được từ người gửi gốc WAL.
- last_end_lsn:Vị trí nhật ký ghi lại lần cuối được báo cáo cho người gửi WAL gốc.
- last_end_time:Thời gian của vị trí nhật ký ghi trước lần cuối được báo cáo cho người gửi WAL gốc.
Để xác minh trạng thái sao chép trong bản chính, chúng ta có thể sử dụng pg_stat_replication:
world=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 1178
usesysid | 16427
usename | rep
application_name | sub1
client_addr | 192.168.100.144
client_hostname |
client_port | 58270
backend_start | 2018-12-05 22:11:45.097539+00
backend_xmin |
state | streaming
sent_lsn | 0/172AF90
write_lsn | 0/172AF90
flush_lsn | 0/172AF90
replay_lsn | 0/172AF90
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | asyncMô tả cột:
- pid:ID quy trình của quy trình người gửi WAL.
- useysid:OID của người dùng đã đăng nhập vào quy trình người gửi WAL này.
- usename:Tên của người dùng đã đăng nhập vào quy trình người gửi WAL này.
- application_name:Tên của ứng dụng được kết nối với người gửi WAL này.
- client_addr:Địa chỉ IP của ứng dụng được kết nối với người gửi WAL này. Nếu trường này trống, nó cho biết rằng máy khách được kết nối qua ổ cắm Unix trên máy chủ.
- client_hostname:Tên máy chủ của máy khách được kết nối, như được báo cáo bởi tra cứu DNS ngược của client_addr. Trường này sẽ chỉ có giá trị không trống đối với các kết nối IP và chỉ khi log_hostname được bật.
- client_port:Số cổng TCP mà khách hàng đang sử dụng để liên lạc với người gửi WAL này hoặc -1 nếu sử dụng ổ cắm Unix.
- backend_start:Thời điểm bắt đầu quá trình này.
- backend_xmin:Khoảng thời gian xmin ở chế độ chờ này được hot_standby_feedback báo cáo.
- trạng thái:Trạng thái người gửi WAL hiện tại. Các giá trị có thể có là:khởi động, bắt kịp, phát trực tuyến, sao lưu và dừng.
- sent_lsn:Vị trí nhật ký ghi trước lần cuối được gửi trên kết nối này.
- write_lsn:Vị trí nhật ký ghi trước lần cuối được máy chủ dự phòng này ghi vào đĩa.
- flush_lsn:Vị trí nhật ký ghi trước lần cuối được máy chủ chờ này chuyển vào đĩa.
- replay_lsn:Vị trí nhật ký ghi trước lần cuối được phát lại vào cơ sở dữ liệu trên máy chủ dự phòng này.
- write_lag:Thời gian trôi qua từ khi gửi cục bộ WAL gần đây đến khi nhận được thông báo rằng máy chủ dự phòng này đã viết nó (nhưng chưa xóa hoặc áp dụng nó).
- flush_lag:Thời gian trôi qua từ khi gửi cục bộ WAL gần đây đến khi nhận được thông báo rằng máy chủ dự phòng này đã viết và xóa nó (nhưng chưa áp dụng nó).
- replay_lag:Thời gian trôi qua từ khi gửi cục bộ WAL gần đây đến khi nhận được thông báo rằng máy chủ dự phòng này đã viết, xóa và áp dụng nó.
- sync_priasty:Mức độ ưu tiên của máy chủ dự phòng này để được chọn làm chế độ chờ đồng bộ trong bản sao đồng bộ dựa trên mức độ ưu tiên.
- sync_state:Trạng thái đồng bộ của máy chủ dự phòng này. Các giá trị có thể có là không đồng bộ, tiềm năng, đồng bộ hóa, túc số.
Để xác minh khi quá trình chuyển ban đầu kết thúc, chúng ta có thể xem nhật ký PostgreSQL trên người đăng ký:
2018-12-05 22:11:45.096 UTC [1111] LOG: logical replication apply worker for subscription "sub1" has started
2018-12-05 22:11:45.103 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has started
2018-12-05 22:11:45.114 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has started
2018-12-05 22:11:45.156 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has finished
2018-12-05 22:11:45.162 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has started
2018-12-05 22:11:45.168 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has finished
2018-12-05 22:11:45.206 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has finishedHoặc kiểm tra biến srsubstate trên danh mục pg_subscription_rel. Danh mục này chứa trạng thái cho mỗi mối quan hệ được sao chép trong mỗi đăng ký.
world=# SELECT * FROM pg_subscription_rel;
-[ RECORD 1 ]---------
srsubid | 16428
srrelid | 16387
srsubstate | r
srsublsn | 0/172AF20
-[ RECORD 2 ]---------
srsubid | 16428
srrelid | 16393
srsubstate | r
srsublsn | 0/172AF58
-[ RECORD 3 ]---------
srsubid | 16428
srrelid | 16400
srsubstate | r
srsublsn | 0/172AF90Mô tả cột:
- srsubid:Tham chiếu đến đăng ký.
- srrelid:Tham chiếu đến mối quan hệ.
- srsubstate:Mã trạng thái:i =khởi tạo, d =dữ liệu đang được sao chép, s =đồng bộ hóa, r =sẵn sàng (sao chép bình thường).
- srsublsn:Kết thúc LSN cho các trạng thái s và r.
Chúng tôi có thể chèn một số bản ghi thử nghiệm vào PostgreSQL 10 của mình và xác thực rằng chúng tôi có chúng trong PostgreSQL 11 của chúng tôi:
PostgreSQL 10:
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5001,'city1','USA','District1',10000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5002,'city2','ITA','District2',20000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5003,'city3','CHN','District3',30000);
INSERT 0 1PostgreSQL 11:
world=# SELECT * FROM city WHERE id>5000;
id | name | countrycode | district | population
------+-------+-------------+-----------+------------
5001 | city1 | USA | District1 | 10000
5002 | city2 | ITA | District2 | 20000
5003 | city3 | CHN | District3 | 30000
(3 rows)Tại thời điểm này, chúng tôi đã có mọi thứ sẵn sàng để trỏ ứng dụng của chúng tôi đến PostgreSQL 11.
Đối với điều này, trước hết, chúng tôi cần xác nhận rằng chúng tôi không có độ trễ sao chép.
Trên trang cái:
world=# SELECT application_name, pg_wal_lsn_diff(pg_current_wal_lsn(), replay_lsn) lag FROM pg_stat_replication;
-[ RECORD 1 ]----+-----
application_name | sub1
lag | 0Và bây giờ, chúng tôi chỉ cần thay đổi điểm cuối của mình từ ứng dụng hoặc bộ cân bằng tải (nếu có) sang máy chủ PostgreSQL 11 mới.
Nếu chúng ta có bộ cân bằng tải như HAProxy, chúng ta có thể định cấu hình nó bằng cách sử dụng PostgreSQL 10 đang hoạt động và PostgreSQL 11 làm bản sao lưu, theo cách này:
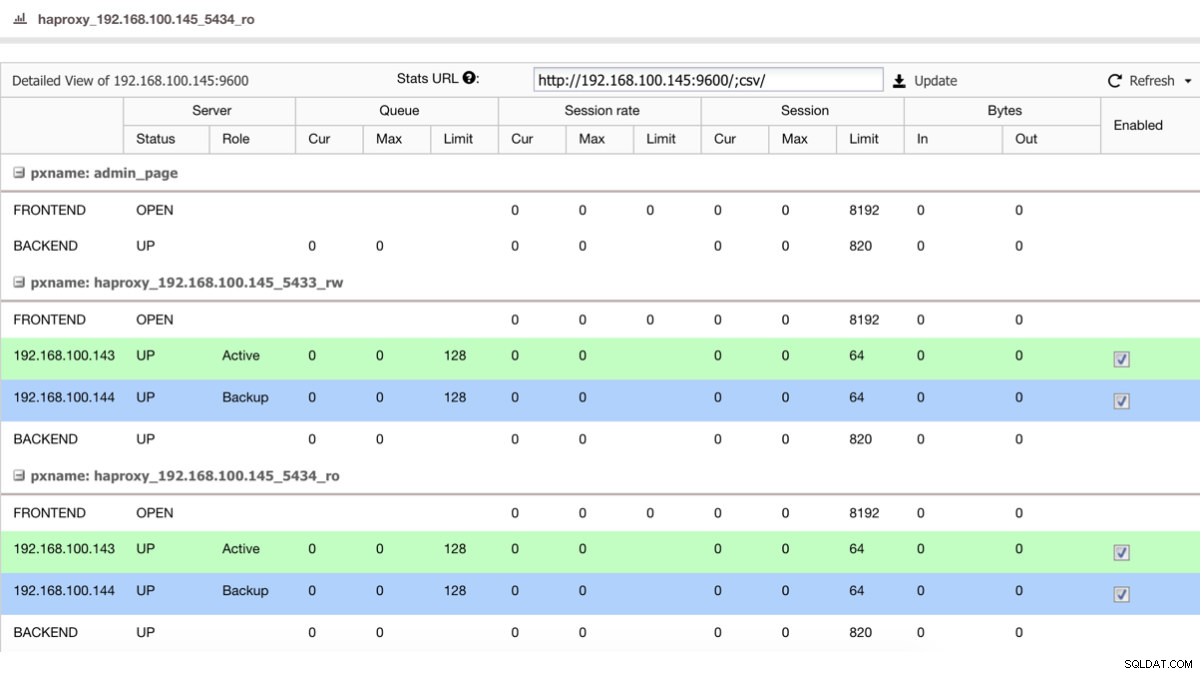 Chế độ xem trạng thái HAProxy
Chế độ xem trạng thái HAProxy Vì vậy, nếu bạn chỉ tắt máy chủ trong PostgreSQL 10, máy chủ sao lưu, trong trường hợp này là PostgreSQL 11, bắt đầu nhận lưu lượng truy cập một cách minh bạch cho người dùng / ứng dụng.
Khi kết thúc quá trình di chuyển, chúng tôi có thể xóa đăng ký trong bản chính mới của mình trong PostgreSQL 11:
world=# DROP SUBSCRIPTION sub1;
NOTICE: dropped replication slot "sub1" on publisher
DROP SUBSCRIPTIONVà xác minh rằng nó được xóa đúng cách:
world=# SELECT * FROM pg_subscription_rel;
(0 rows)
world=# SELECT * FROM pg_stat_subscription;
(0 rows)Hạn chế
Trước khi sử dụng bản sao hợp lý, hãy ghi nhớ những hạn chế sau:
- Lược đồ cơ sở dữ liệu và các lệnh DDL không được sao chép. Lược đồ ban đầu có thể được sao chép bằng cách sử dụng pg_dump --schema-only.
- Dữ liệu trình tự không được sao chép. Dữ liệu trong các cột nối tiếp hoặc cột nhận dạng được hỗ trợ bởi chuỗi sẽ được sao chép như một phần của bảng, nhưng bản thân chuỗi sẽ vẫn hiển thị giá trị bắt đầu trên người đăng ký.
- Việc sao chép các lệnh TRUNCATE được hỗ trợ, nhưng phải cẩn thận một số khi cắt bớt các nhóm bảng được kết nối bằng khóa ngoại. Khi sao chép một hành động cắt ngắn, người đăng ký sẽ cắt ngắn cùng một nhóm bảng đã được cắt ngắn trên nhà xuất bản, được chỉ định rõ ràng hoặc được thu thập ngầm thông qua CASCADE, trừ các bảng không phải là một phần của đăng ký. Điều này sẽ hoạt động chính xác nếu tất cả các bảng bị ảnh hưởng là một phần của cùng một gói đăng ký. Nhưng nếu một số bảng được cắt ngắn trên người đăng ký có liên kết khóa ngoại đến các bảng không thuộc cùng một (hoặc bất kỳ) đăng ký nào, thì việc áp dụng hành động cắt ngắn trên người đăng ký sẽ không thành công.
- Các đối tượng lớn không được sao chép. Không có cách giải quyết nào khác ngoài việc lưu trữ dữ liệu trong các bảng thông thường.
- Chỉ có thể sao chép từ bảng cơ sở sang bảng cơ sở. Có nghĩa là, các bảng trên ấn bản và bên đăng ký phải là bảng bình thường, không phải là dạng xem, dạng xem vật thể hóa, bảng gốc phân vùng hoặc bảng ngoại. Trong trường hợp phân vùng, bạn có thể sao chép phân cấp phân vùng một-một, nhưng hiện tại bạn không thể sao chép sang thiết lập phân vùng khác.
Kết luận
Giữ cho máy chủ PostgreSQL của bạn được cập nhật bằng cách thực hiện nâng cấp thường xuyên là một nhiệm vụ cần thiết nhưng khó khăn cho đến phiên bản PostgreSQL 10.
Trong blog này, chúng tôi đã giới thiệu ngắn gọn về sao chép hợp lý, một tính năng PostgreSQL được giới thiệu nguyên bản trong phiên bản 10 và chúng tôi đã chỉ cho bạn cách nó có thể giúp bạn hoàn thành thách thức này với chiến lược thời gian chết bằng không.