Một trong những yêu cầu chính đối với bất kỳ cơ sở dữ liệu nào là đạt được khả năng mở rộng. Nó chỉ có thể đạt được nếu sự tranh chấp (khóa) được giảm thiểu càng nhiều càng tốt, nếu không loại bỏ tất cả cùng nhau. Vì đọc / ghi / cập nhật / xóa là một số hoạt động chính thường xuyên xảy ra trong cơ sở dữ liệu nên điều rất quan trọng là các hoạt động này phải diễn ra đồng thời mà không bị chặn. Để đạt được điều này, hầu hết các cơ sở dữ liệu chính sử dụng mô hình đồng thời được gọi là Điều khiển đồng thời nhiều phiên bản, làm giảm sự tranh chấp đến mức tối thiểu.
MVCC là gì
Kiểm soát đồng thời nhiều phiên bản (ở đây trở đi là MVCC) là một thuật toán để cung cấp khả năng kiểm soát đồng thời tốt bằng cách duy trì nhiều phiên bản của cùng một đối tượng để thao tác ĐỌC và VIẾT không xung đột. Ở đây WRITE có nghĩa là CẬP NHẬT và XÓA, vì bản ghi mới được CHÈN sẽ được bảo vệ theo mức cô lập. Mỗi thao tác WRITE tạo ra một phiên bản mới của đối tượng và mỗi thao tác đọc đồng thời đọc một phiên bản khác nhau của đối tượng tùy thuộc vào mức độ cô lập. Vì cả hai thao tác đọc và ghi đều hoạt động trên các phiên bản khác nhau của cùng một đối tượng nên không cần thao tác nào trong số này để khóa hoàn toàn và do đó cả hai có thể hoạt động đồng thời. Trường hợp duy nhất mà tranh chấp vẫn có thể tồn tại là khi hai giao dịch đồng thời cố gắng VIẾT cùng một bản ghi.
Hầu hết các cơ sở dữ liệu chính hiện nay đều hỗ trợ MVCC. Mục đích của thuật toán này là duy trì nhiều phiên bản của cùng một đối tượng nên việc triển khai MVCC chỉ khác nhau giữa cơ sở dữ liệu này với cơ sở dữ liệu khác về cách nhiều phiên bản được tạo và duy trì. Theo đó, hoạt động cơ sở dữ liệu tương ứng và lưu trữ các thay đổi dữ liệu.
Phương pháp tiếp cận được công nhận nhiều nhất để triển khai MVCC là phương pháp được sử dụng bởi PostgreSQL và Firebird / Interbase và một phương pháp khác được sử dụng bởi InnoDB và Oracle. Trong các phần tiếp theo, chúng ta sẽ thảo luận chi tiết về cách nó đã được triển khai trong PostgreSQL và InnoDB.
MVCC Trong PostgreSQL
Để hỗ trợ nhiều phiên bản, PostgreSQL duy trì các trường bổ sung cho từng đối tượng (Tuple trong thuật ngữ PostgreSQL) như được đề cập bên dưới:
- xmin - ID giao dịch của giao dịch đã chèn hoặc cập nhật bộ tuple. Trong trường hợp CẬP NHẬT, phiên bản mới hơn của bộ tuple sẽ được chỉ định với ID giao dịch này.
- xmax - ID giao dịch của giao dịch đã xóa hoặc cập nhật bộ giá trị. Trong trường hợp CẬP NHẬT, phiên bản tuple hiện đang tồn tại sẽ được chỉ định ID giao dịch này. Trên một bộ giá trị mới được tạo, giá trị mặc định của trường này là null.
PostgreSQL lưu trữ tất cả dữ liệu trong một bộ nhớ chính gọi là HEAP (trang có kích thước mặc định là 8KB). Tất cả tuple mới nhận xmin như một giao dịch đã tạo ra nó và tuple phiên bản cũ hơn (đã được cập nhật hoặc bị xóa) được gán với xmax. Luôn có một liên kết từ tuple phiên bản cũ hơn đến phiên bản mới. Tuple phiên bản cũ hơn có thể được sử dụng để tạo lại tuple trong trường hợp khôi phục và để đọc phiên bản cũ hơn của tuple bằng cách đọc câu lệnh READ tùy thuộc vào mức độ cô lập.
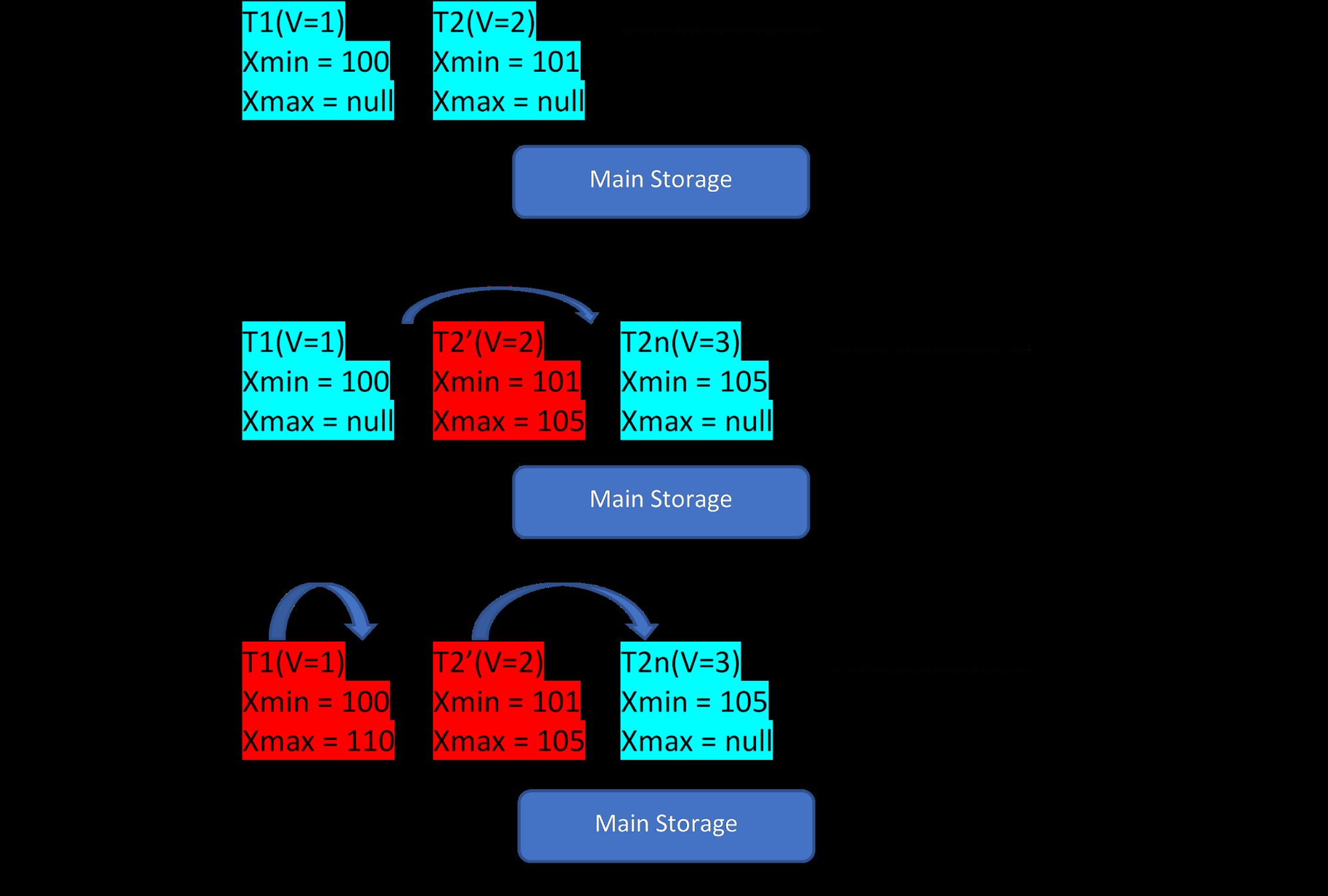
Hãy xem xét có hai bộ giá trị, T1 (với giá trị 1) và T2 (với giá trị 2) cho một bảng, việc tạo các hàng mới có thể được minh họa trong 3 bước dưới đây:
 MVCC:Lưu trữ nhiều phiên bản trong PostgreSQL
MVCC:Lưu trữ nhiều phiên bản trong PostgreSQL Như đã thấy trong hình, ban đầu có hai bộ giá trị trong cơ sở dữ liệu với các giá trị 1 và 2.
Sau đó, trong mỗi bước thứ hai, hàng T2 có giá trị 2 được cập nhật với giá trị 3. Tại thời điểm này, một phiên bản mới được tạo với giá trị mới và nó chỉ được lưu trữ bên cạnh bộ giá trị hiện có trong cùng một khu vực lưu trữ . Trước đó, phiên bản cũ hơn được gán với xmax và trỏ đến tuple phiên bản mới nhất.
Tương tự, trong bước thứ ba, khi hàng T1 có giá trị 1 bị xóa, thì hàng hiện tại sẽ bị xóa hầu như (tức là nó vừa gán xmax với giao dịch hiện tại) ở cùng một vị trí. Không có phiên bản mới nào được tạo cho việc này.
Tiếp theo, hãy xem cách mỗi thao tác tạo ra nhiều phiên bản và cách duy trì mức cô lập giao dịch mà không cần khóa với một số ví dụ thực tế. Trong tất cả các ví dụ dưới đây theo mặc định, tính năng cách ly “READ COMMITTED” được sử dụng.
CHÈN
Mỗi khi một bản ghi được chèn vào, nó sẽ tạo ra một bộ dữ liệu mới, bộ này sẽ được thêm vào một trong các trang thuộc bảng tương ứng.
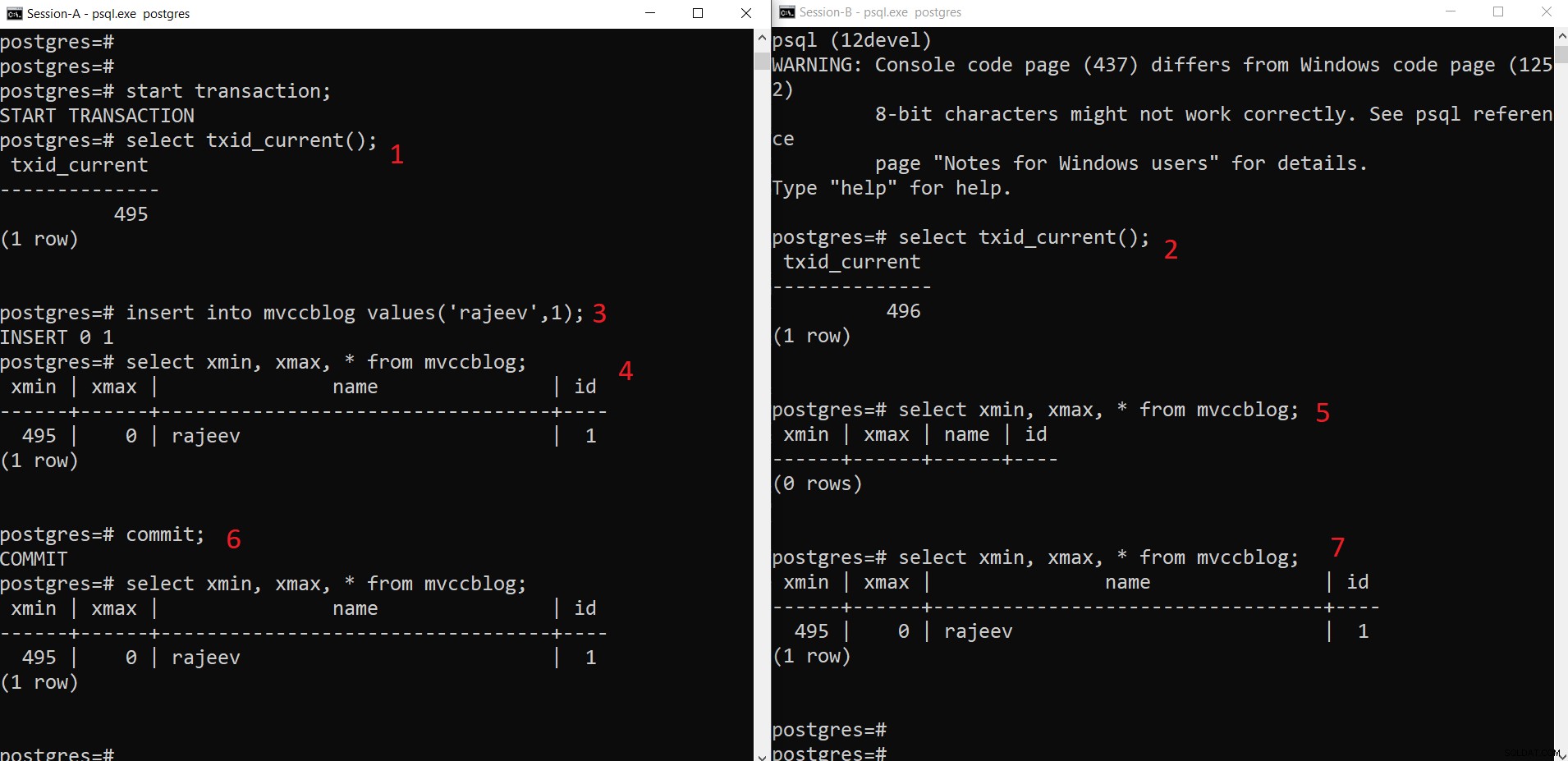 Thao tác CHÈN đồng thời PostgreSQL
Thao tác CHÈN đồng thời PostgreSQL Như chúng ta có thể thấy ở đây theo từng bước:
- Phiên-A bắt đầu một giao dịch và nhận được ID giao dịch 495.
- Phiên-B bắt đầu một giao dịch và nhận được ID giao dịch 496.
- Phiên-A chèn một bộ giá trị mới (được lưu trữ trong HEAP)
- Giờ đây, bộ giá trị mới với xmin được đặt thành ID giao dịch hiện tại 495 sẽ được thêm vào.
- Nhưng điều tương tự sẽ không hiển thị từ Session-B vì xmin (tức là 495) vẫn không được cam kết.
- Khi đã cam kết.
- Dữ liệu được hiển thị cho cả hai phiên.
CẬP NHẬT
PostgreSQL UPDATE không phải là bản cập nhật “IN-PLACE”, tức là nó không sửa đổi đối tượng hiện có với giá trị mới được yêu cầu. Thay vào đó, nó tạo ra một phiên bản mới của đối tượng. Vì vậy, CẬP NHẬT bao gồm rộng rãi các bước bên dưới:
- Nó đánh dấu đối tượng hiện tại là đã bị xóa.
- Sau đó, nó thêm một phiên bản mới của đối tượng.
- Chuyển hướng phiên bản cũ hơn của đối tượng sang phiên bản mới.
Vì vậy, mặc dù một số bản ghi vẫn giữ nguyên, HEAP chiếm không gian như thể một bản ghi khác được chèn vào.
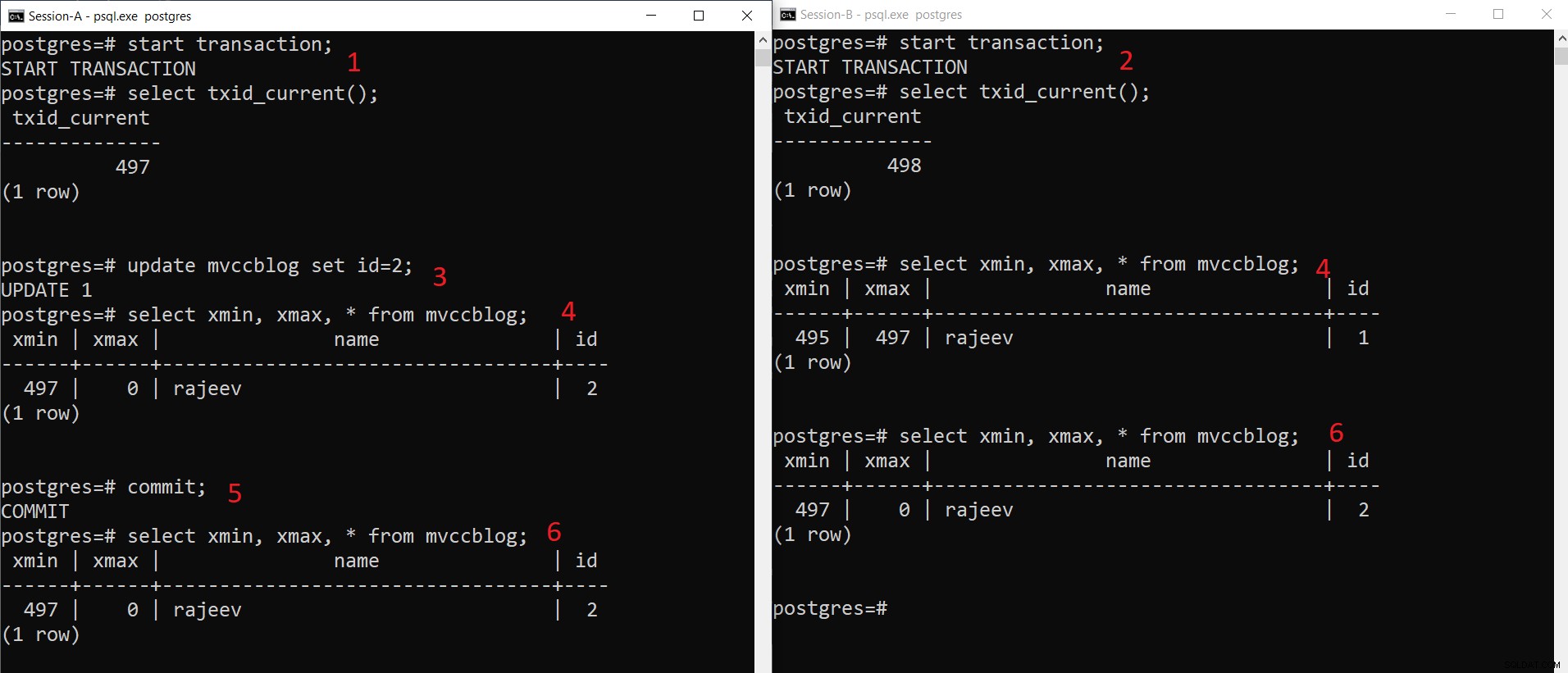 Thao tác CHÈN đồng thời PostgreSQL
Thao tác CHÈN đồng thời PostgreSQL Như chúng ta có thể thấy ở đây theo từng bước:
- Phiên-A bắt đầu một giao dịch và nhận được ID giao dịch 497.
- Phiên-B bắt đầu một giao dịch và nhận được ID giao dịch 498.
- Phiên-A cập nhật bản ghi hiện có.
- Ở đây Phiên-A nhìn thấy một phiên bản của bộ tuple (bộ tuple được cập nhật) trong khi Phiên-B nhìn thấy phiên bản khác (bộ tuple cũ hơn nhưng xmax được đặt thành 497). Cả hai phiên bản tuple đều được lưu trữ trong bộ nhớ HEAP (thậm chí trên cùng một trang tùy thuộc vào tình trạng còn trống)
- Sau khi Phiên-A thực hiện giao dịch, tuple cũ hơn sẽ hết hạn vì xmax của tuple cũ hơn được cam kết.
- Giờ đây, cả hai phiên đều thấy cùng một phiên bản của bản ghi.
XÓA
Xóa gần giống như thao tác CẬP NHẬT ngoại trừ nó không phải thêm phiên bản mới. Nó chỉ đánh dấu đối tượng hiện tại là ĐÃ XÓA như giải thích trong trường hợp CẬP NHẬT.
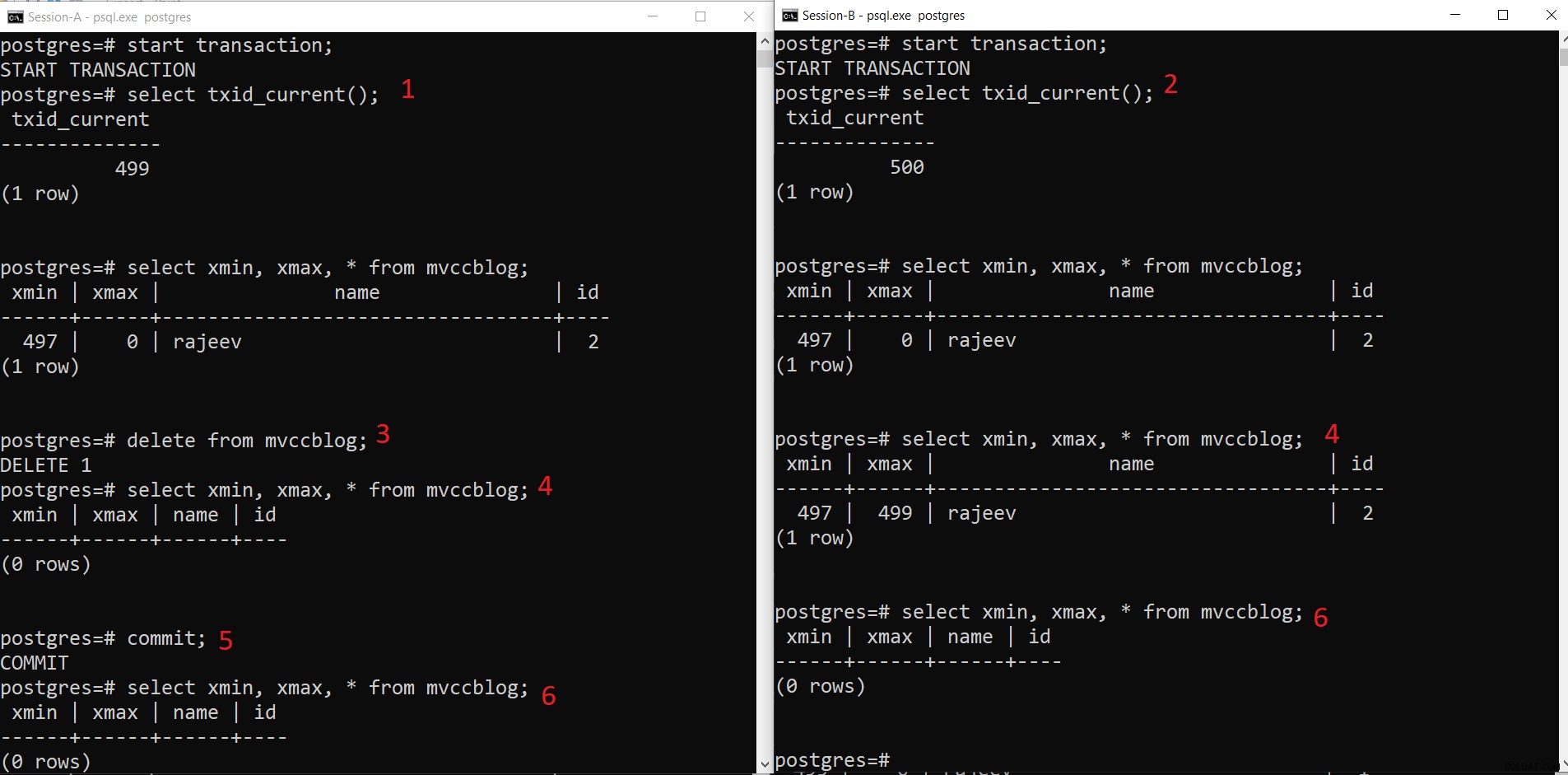 Thao tác XÓA đồng thời PostgreSQL
Thao tác XÓA đồng thời PostgreSQL - Phiên-A bắt đầu một giao dịch và nhận được ID giao dịch 499.
- Phiên-B bắt đầu một giao dịch và nhận được ID giao dịch 500.
- Phiên-A xóa bản ghi hiện có.
- Ở đây Phiên-A không thấy bất kỳ bộ giá trị nào bị xóa khỏi giao dịch hiện tại. Trong khi Session-B thấy phiên bản cũ hơn của bộ tuple (với xmax là 499; giao dịch đã xóa bản ghi này).
- Sau khi Phiên-A thực hiện giao dịch, tuple cũ hơn sẽ hết hạn vì xmax của tuple cũ hơn được cam kết.
- Giờ đây, cả hai phiên đều không thấy bộ dữ liệu đã xóa.
Như chúng ta có thể thấy, không có thao tác nào loại bỏ phiên bản hiện có của đối tượng một cách trực tiếp và bất cứ khi nào cần thiết, nó sẽ thêm một phiên bản bổ sung của đối tượng.
Bây giờ, hãy xem cách truy vấn SELECT được thực thi trên một tuple có nhiều phiên bản:SELECT cần đọc tất cả các phiên bản của tuple cho đến khi tìm thấy tuple thích hợp theo mức cô lập. Giả sử có tuple T1, được cập nhật và tạo phiên bản mới T1 'và đến lượt nó đã tạo ra T1' khi cập nhật:
- Thao tác SELECT sẽ chuyển qua lưu trữ đống cho bảng này và trước tiên hãy kiểm tra T1. Nếu giao dịch xmax T1 được cam kết, thì nó sẽ chuyển sang phiên bản tiếp theo của bộ tuple này.
- Giả sử bây giờ tuple xmax của T1 cũng được cam kết, sau đó một lần nữa nó chuyển sang phiên bản tiếp theo của tuple này.
- Cuối cùng, nó tìm thấy T1 ’’ và thấy rằng xmax không được cam kết (hoặc null) và T1 ’’ xmin hiển thị với giao dịch hiện tại theo mức cô lập. Cuối cùng, nó sẽ đọc T1 ’’ tuple.
Như chúng ta có thể thấy, nó cần phải duyệt qua cả 3 phiên bản của bộ tuple để tìm bộ giá trị có thể nhìn thấy thích hợp cho đến khi bộ tuple hết hạn bị xóa bởi bộ thu gom rác (VACUUM).
MVCC trong InnoDB
Để hỗ trợ nhiều phiên bản, InnoDB duy trì các trường bổ sung cho mỗi hàng như được đề cập bên dưới:
- DB_TRX_ID:ID giao dịch của giao dịch đã chèn hoặc cập nhật hàng.
- DB_ROLL_PTR:Nó còn được gọi là con trỏ cuộn và nó trỏ đến việc hoàn tác bản ghi nhật ký được ghi vào phân đoạn khôi phục (thông tin thêm về phần này tiếp theo).
Giống như PostgreSQL, InnoDB cũng tạo nhiều phiên bản của hàng như một phần của tất cả hoạt động nhưng việc lưu trữ của phiên bản cũ hơn là khác nhau.
Trong trường hợp InnoDB, phiên bản cũ của hàng đã thay đổi được giữ trong một vùng lưu trữ / vùng bảng riêng biệt (được gọi là phân đoạn hoàn tác). Vì vậy, không giống như PostgreSQL, InnoDB chỉ giữ phiên bản mới nhất của các hàng trong vùng lưu trữ chính và phiên bản cũ hơn được giữ trong phân đoạn hoàn tác. Các phiên bản hàng từ phân đoạn hoàn tác được sử dụng để hoàn tác thao tác trong trường hợp khôi phục và để đọc phiên bản cũ hơn của các hàng bằng câu lệnh READ tùy thuộc vào mức độ cô lập.
Hãy xem xét có hai hàng, T1 (với giá trị 1) và T2 (với giá trị 2) cho một bảng, việc tạo các hàng mới có thể được minh họa trong 3 bước dưới đây:
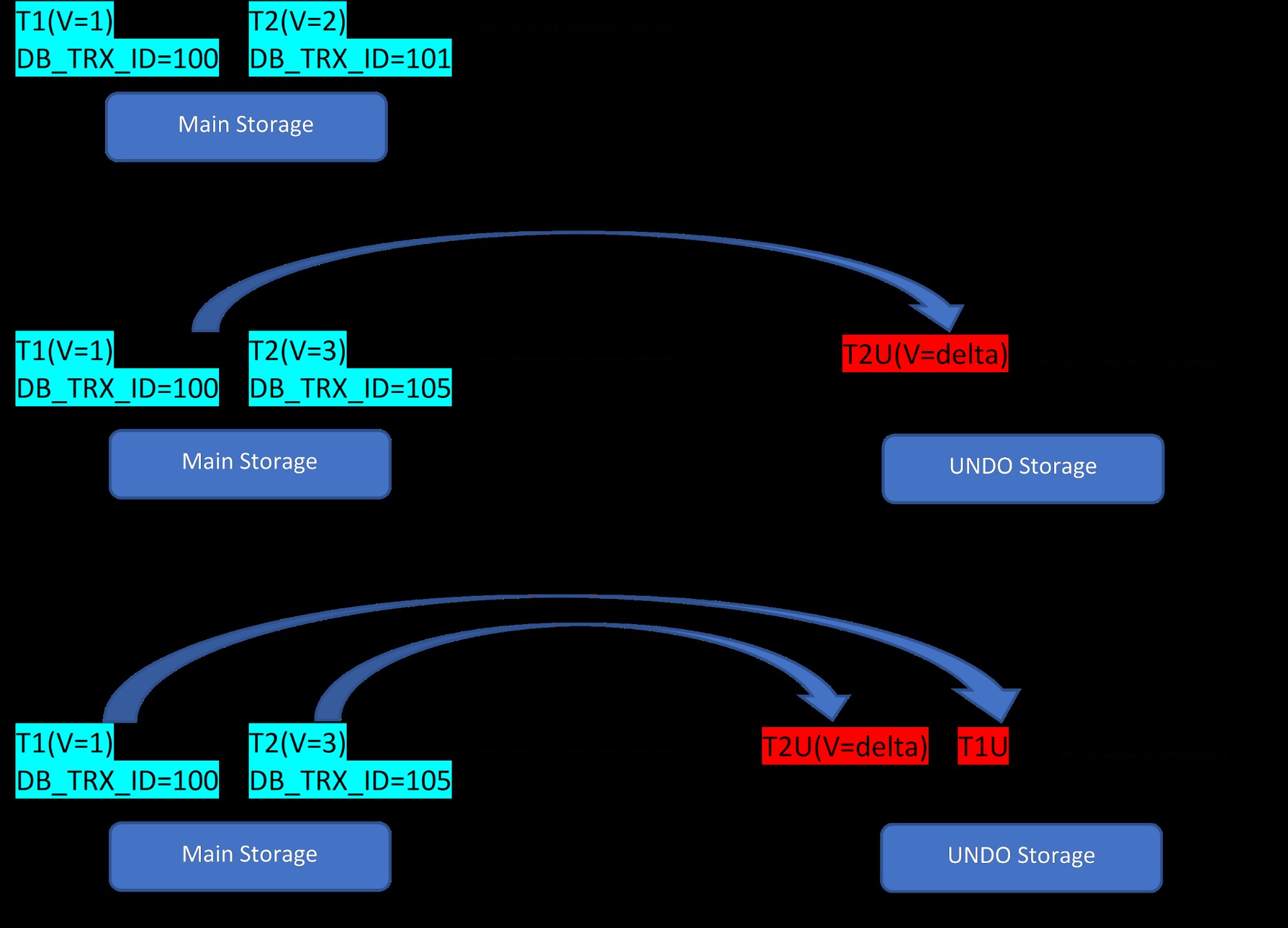 MVCC:Lưu trữ nhiều phiên bản trong InnoDB
MVCC:Lưu trữ nhiều phiên bản trong InnoDB Như đã thấy trong hình, ban đầu có hai hàng trong cơ sở dữ liệu với các giá trị 1 và 2.
Sau đó, trong mỗi giai đoạn thứ hai, hàng T2 có giá trị 2 được cập nhật với giá trị 3. Tại thời điểm này, một phiên bản mới được tạo với giá trị mới và nó thay thế phiên bản cũ hơn. Trước đó, phiên bản cũ hơn được lưu trữ trong phân đoạn hoàn tác (lưu ý rằng phiên bản phân đoạn UNDO chỉ có giá trị delta). Ngoài ra, hãy lưu ý rằng có một con trỏ từ phiên bản mới sang phiên bản cũ hơn trong phân đoạn khôi phục. Vì vậy, không giống như PostgreSQL, bản cập nhật InnoDB là “IN-PLACE”.
Tương tự, trong bước thứ ba, khi hàng T1 với giá trị 1 bị xóa, thì hàng hiện tại hầu như bị xóa (tức là nó chỉ đánh dấu một bit đặc biệt trong hàng) trong vùng lưu trữ chính và một phiên bản mới tương ứng với giá trị này sẽ được thêm vào phân đoạn Hoàn tác. Một lần nữa, có một con trỏ cuộn từ bộ nhớ chính đến phân đoạn hoàn tác.
Tất cả các hoạt động hoạt động theo cách tương tự như trong trường hợp của PostgreSQL khi nhìn từ bên ngoài. Chỉ là bộ nhớ trong của nhiều phiên bản khác nhau.
Tải xuống Báo cáo chính thức hôm nay Quản lý &Tự động hóa PostgreSQL với ClusterControlTìm hiểu về những điều bạn cần biết để triển khai, giám sát, quản lý và mở rộng PostgreSQLTải xuống Báo cáo chính thứcMVCC:PostgreSQL và InnoDB
Bây giờ, hãy phân tích sự khác biệt chính giữa PostgreSQL và InnoDB về việc triển khai MVCC của chúng là gì:
-
Kích thước của phiên bản cũ hơn
PostgreSQL chỉ cập nhật xmax trên phiên bản cũ hơn của bộ tuple, vì vậy kích thước của phiên bản cũ hơn vẫn giữ nguyên đối với bản ghi được chèn tương ứng. Điều này có nghĩa là nếu bạn có 3 phiên bản của bộ tuple cũ hơn thì tất cả chúng sẽ có cùng kích thước (ngoại trừ sự khác biệt về kích thước dữ liệu thực tế nếu có ở mỗi lần cập nhật).
Trong khi trong trường hợp của InnoDB, phiên bản đối tượng được lưu trữ trong phân đoạn Hoàn tác thường nhỏ hơn bản ghi được chèn tương ứng. Điều này là do chỉ các giá trị đã thay đổi (tức là chênh lệch) được ghi vào nhật ký UNDO.
-
INSERT hoạt động
InnoDB cần ghi thêm một bản ghi trong phân đoạn UNDO ngay cả đối với INSERT trong khi PostgreSQL chỉ tạo phiên bản mới trong trường hợp CẬP NHẬT.
-
Khôi phục phiên bản cũ hơn trong trường hợp khôi phục
PostgreSQL không cần bất kỳ thứ gì cụ thể để khôi phục phiên bản cũ hơn trong trường hợp khôi phục. Hãy nhớ rằng phiên bản cũ hơn có xmax bằng với giao dịch đã cập nhật tuple này. Vì vậy, cho đến khi id giao dịch này được cam kết, nó được coi là bộ giá trị còn sống cho một ảnh chụp nhanh đồng thời. Khi giao dịch được hoàn nguyên, giao dịch tương ứng sẽ tự động được coi là còn sống đối với tất cả giao dịch vì nó sẽ là giao dịch bị hủy bỏ.
Trong khi trong trường hợp của InnoDB, rõ ràng yêu cầu phải xây dựng lại phiên bản cũ hơn của đối tượng sau khi quá trình quay trở lại xảy ra.
-
Lấy lại dung lượng bị chiếm bởi phiên bản cũ hơn
Trong trường hợp của PostgreSQL, không gian bị chiếm bởi phiên bản cũ hơn chỉ có thể được coi là đã chết khi không có ảnh chụp nhanh song song để đọc phiên bản này. Khi phiên bản cũ đã chết, thì hoạt động VACUUM có thể lấy lại không gian bị chúng chiếm dụng. VACUUM có thể được kích hoạt theo cách thủ công hoặc như một tác vụ nền tùy thuộc vào cấu hình.
Nhật ký InnoDB UNDO chủ yếu được chia thành INSERT UNDO và UPDATE UNDO. Cái đầu tiên bị loại bỏ ngay sau khi giao dịch tương ứng được thực hiện. Cái thứ hai cần bảo tồn cho đến khi nó song song với bất kỳ ảnh chụp nhanh nào khác. InnoDB không có hoạt động VACUUM rõ ràng nhưng trên một dòng tương tự, nó có PURGE không đồng bộ để loại bỏ nhật ký UNDO chạy như một tác vụ nền.
-
Tác động của chân không trễ
Như đã thảo luận ở điểm trước, có một tác động rất lớn của chân không trì hoãn trong trường hợp PostgreSQL. Nó làm cho bảng bắt đầu đầy hơi và khiến không gian lưu trữ tăng lên mặc dù các bản ghi liên tục bị xóa. Nó cũng có thể đạt đến điểm mà cần phải thực hiện ĐẦY ĐỦ VACUUM, một hoạt động rất tốn kém.
-
Quét tuần tự trong trường hợp bảng bị phình ra
Quét tuần tự PostgreSQL phải duyệt qua tất cả các phiên bản cũ hơn của một đối tượng mặc dù tất cả chúng đều đã chết (cho đến khi chúng được loại bỏ bằng chân không). Đây là vấn đề điển hình và được nói đến nhiều nhất trong PostgreSQL. Hãy nhớ PostgreSQL lưu trữ tất cả các phiên bản của một bộ trong cùng một bộ nhớ.
Trong khi trong trường hợp InnoDB, nó không cần đọc bản ghi Hoàn tác trừ khi được yêu cầu. Trong trường hợp tất cả các bản ghi hoàn tác đã chết, thì chỉ đủ để đọc qua tất cả phiên bản mới nhất của các đối tượng.
-
Chỉ mục
PostgreSQL lưu trữ chỉ mục trong một bộ lưu trữ riêng biệt giữ một liên kết đến dữ liệu thực tế trong HEAP. Vì vậy PostgreSQL cũng phải cập nhật phần INDEX mặc dù không có thay đổi trong INDEX. Mặc dù sau đó, vấn đề này đã được khắc phục bằng cách triển khai cập nhật HOT (Heap Only Tuple) nhưng nó vẫn có hạn chế là nếu không thể chứa một bộ heap mới trong cùng một trang, thì nó sẽ trở về CẬP NHẬT bình thường.
InnoDB không gặp vấn đề này vì họ sử dụng chỉ mục được phân cụm.
Kết luận
PostgreSQL MVCC có một số hạn chế, đặc biệt là về dung lượng lưu trữ cồng kềnh nếu khối lượng công việc của bạn thường xuyên UPDATE / DELETE. Vì vậy, nếu bạn quyết định sử dụng PostgreSQL, bạn nên hết sức cẩn thận để cấu hình VACUUM một cách khôn ngoan.
Cộng đồng PostgreSQL cũng đã thừa nhận đây là một vấn đề lớn và họ đã bắt đầu làm việc trên phương pháp tiếp cận MVCC dựa trên UNDO (tên dự kiến là ZHEAP) và chúng ta có thể thấy điều tương tự trong một bản phát hành trong tương lai.