Trong phần thứ 3 này của Giải pháp đám mây PostgreSQL được quản lý theo điểm chuẩn , Tôi đã tận dụng lợi thế của việc cung cấp cấp miễn phí GCP của Google. Đó là một trải nghiệm đáng giá và với tư cách là một sysadmin dành phần lớn thời gian của mình trên bảng điều khiển, tôi không thể bỏ lỡ cơ hội dùng thử cloud shell, một trong những tính năng của bảng điều khiển giúp Google khác biệt với nhà cung cấp đám mây mà tôi quen thuộc hơn , Dịch vụ Web của Amazon.
Để nhanh chóng tóm tắt lại, trong Phần 1, tôi đã xem xét các công cụ điểm chuẩn hiện có và giải thích lý do tại sao tôi chọn Quy trình điểm chuẩn AWS cho Aurora. Tôi cũng đã đánh giá điểm chuẩn của Amazon Aurora cho PostgreSQL phiên bản 10.6. Trong Phần 2, tôi đã xem xét AWS RDS cho PostgreSQL phiên bản 11.1.
Trong vòng này, các bài kiểm tra dựa trên Quy trình điểm chuẩn AWS cho Aurora sẽ được chạy trên Google Cloud SQL dành cho PostgreSQL 9.6 vì phiên bản 11.1 vẫn đang trong giai đoạn thử nghiệm.
Phiên bản đám mây
Điều kiện tiên quyết
Như đã đề cập trong hai bài viết trước, tôi đã chọn để cài đặt PostgreSQL ở mặc định GUC trên đám mây của chúng, trừ khi chúng ngăn các thử nghiệm chạy (xem thêm bên dưới). Nhớ lại các bài viết trước rằng giả định rằng nhà cung cấp dịch vụ đám mây nên cấu hình phiên bản cơ sở dữ liệu để cung cấp hiệu suất hợp lý.
Bản vá thời gian AWS pgbench cho PostgreSQL 9.6.5 được áp dụng rõ ràng cho phiên bản Google Cloud của PostgreSQL 9.6.10.
Bằng cách sử dụng thông tin mà Google đưa ra trong blog của họ, Google Cloud cho AWS Professionals, tôi đã đối chiếu các thông số kỹ thuật cho khách hàng và các phiên bản mục tiêu liên quan đến các thành phần Tính toán, Lưu trữ và Mạng. Ví dụ:Google Cloud tương đương với Mạng nâng cao AWS đạt được bằng cách định kích thước nút tính toán dựa trên công thức:
max( [vCPUs x 2Gbps/vCPU], 16Gbps)Khi nói đến việc thiết lập phiên bản cơ sở dữ liệu đích, tương tự như AWS, Google Cloud không cho phép bản sao, tuy nhiên, bộ nhớ được mã hóa ở chế độ nghỉ và không có tùy chọn để tắt nó.
Cuối cùng, để đạt được hiệu suất mạng tốt nhất, máy khách và các phiên bản đích phải được đặt trong cùng một vùng khả dụng.
Khách hàng
Các thông số kỹ thuật của bản sao ứng dụng khách phù hợp với bản sao AWS gần nhất, là:
- vCPU:32 (16 Cores x 2 Threads / Core)
- RAM:208 GiB (tối đa cho phiên bản 32 vCPU)
- Bộ nhớ:Đĩa liên tục của Compute Engine
- Mạng:16 Gbps (tối đa [32 vCPU x 2 Gbps / vCPU] và 16 Gbps)
Chi tiết phiên bản sau khi khởi tạo:
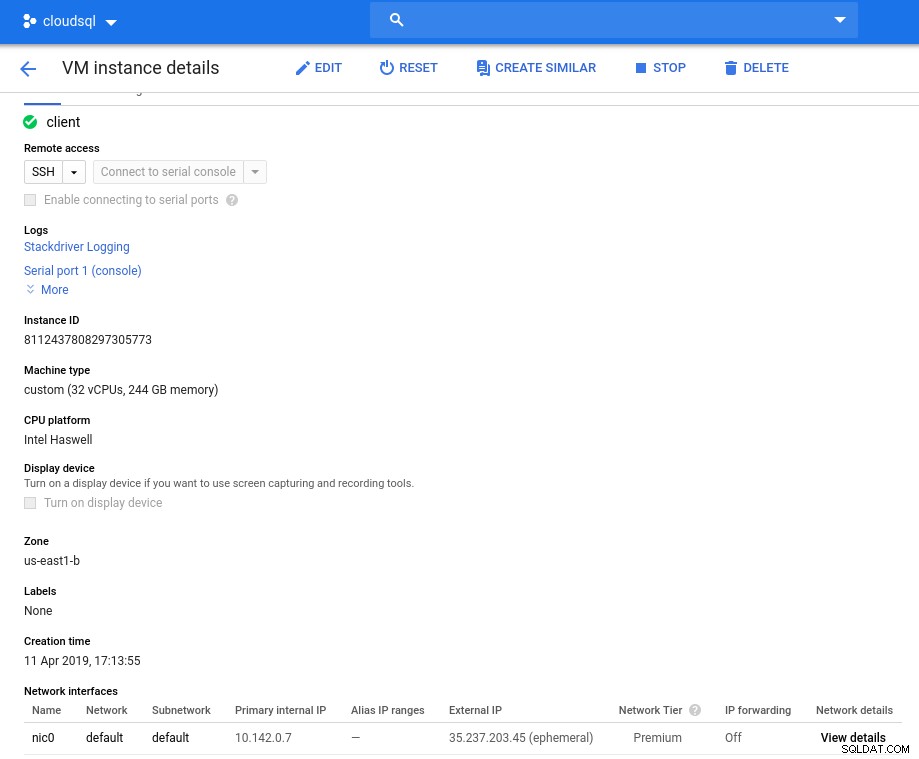 Phiên bản ứng dụng khách:Máy tính và mạng
Phiên bản ứng dụng khách:Máy tính và mạng Lưu ý:Theo mặc định, các phiên bản được giới hạn ở 24 vCPU. Bộ phận Hỗ trợ Kỹ thuật của Google phải chấp thuận việc tăng hạn ngạch lên 32 vCPU cho mỗi trường hợp.

Mặc dù các yêu cầu như vậy thường được xử lý trong vòng 2 ngày làm việc, nhưng tôi phải ủng hộ Dịch vụ hỗ trợ của Google vì đã hoàn thành yêu cầu của tôi chỉ sau 2 giờ.
Đối với những người tò mò, công thức tốc độ mạng dựa trên tài liệu về công cụ máy tính được tham chiếu trong blog GCP này.
Cụm DB
Dưới đây là các thông số kỹ thuật của phiên bản cơ sở dữ liệu:
- vCPU:8
- RAM:52 GiB (tối đa)
- Bộ nhớ:144 MB / s, 9.000 IOPS
- Mạng:2.000 MB / s
Lưu ý rằng bộ nhớ khả dụng tối đa cho phiên bản 8 vCPU là 52 GiB. Có thể cấp thêm bộ nhớ bằng cách chọn một phiên bản lớn hơn (nhiều vCPU hơn):
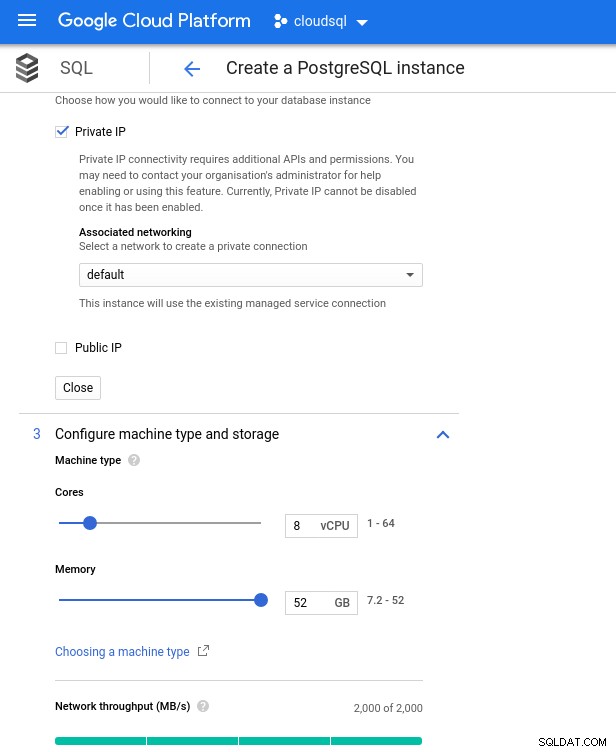 Định cỡ bộ nhớ và CPU cơ sở dữ liệu
Định cỡ bộ nhớ và CPU cơ sở dữ liệu Mặc dù Google SQL có thể tự động mở rộng bộ nhớ cơ bản, đây là một tính năng thực sự thú vị, tôi đã chọn tắt tùy chọn này để phù hợp với bộ tính năng AWS và tránh tác động I / O tiềm ẩn trong quá trình thay đổi kích thước. (“Tiềm năng”, bởi vì nó sẽ không có tác động tiêu cực nào cả, tuy nhiên, theo kinh nghiệm của tôi, việc thay đổi kích thước bất kỳ loại bộ nhớ cơ bản nào sẽ làm tăng I / O, ngay cả khi trong vài giây).
Nhớ lại rằng phiên bản cơ sở dữ liệu AWS đã được sao lưu bằng bộ lưu trữ EBS được tối ưu hóa cung cấp tối đa:
- Băng thông 1.700 Mbps
- Thông lượng 212,5 MB / s
- 12.000 IOPS
Với Google Cloud, chúng tôi đạt được cấu hình tương tự bằng cách điều chỉnh số lượng vCPU (xem ở trên) và dung lượng lưu trữ:
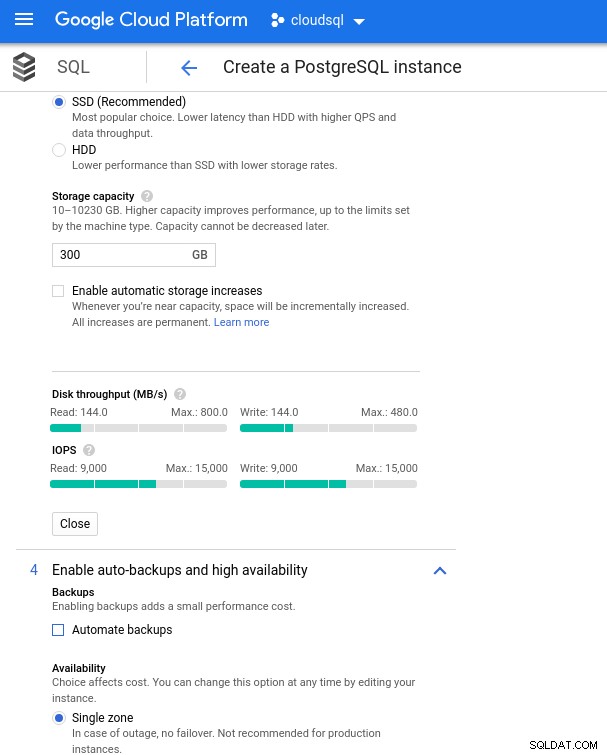 Cài đặt sao lưu và cấu hình lưu trữ Databse
Cài đặt sao lưu và cấu hình lưu trữ Databse Chạy Điểm chuẩn
Thiết lập
Tiếp theo, cài đặt các công cụ điểm chuẩn, pgbench và sysbench bằng cách làm theo các hướng dẫn trong hướng dẫn của Amazon được điều chỉnh cho phù hợp với PostgreSQL phiên bản 9.6.10.
Khởi tạo các biến môi trường PostgreSQL trong .bashrc và đặt đường dẫn đến các tệp nhị phân và thư viện PostgreSQL:
export PGHOST=10.101.208.7
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
export PGPORT=5432
export PATH=$PATH:/usr/local/pgsql/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/libDanh sách kiểm tra trước khi khởi hành:
[example@sqldat.com ~]# psql --version
psql (PostgreSQL) 9.6.10
[example@sqldat.com ~]# pgbench --version
pgbench (PostgreSQL) 9.6.10
[example@sqldat.com ~]# sysbench --version
sysbench 0.5
postgres=> select version();
version
---------------------------------------------------------------------------------------------------------
PostgreSQL 9.6.10 on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4, 64-bit
(1 row)Và chúng tôi đã sẵn sàng để cất cánh:
pgbench
Khởi tạo cơ sở dữ liệu pgbench.
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000… Và vài phút sau:
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 1000000000 tuples (0%) done (elapsed 0.09 s, remaining 872.42 s)
200000 of 1000000000 tuples (0%) done (elapsed 0.19 s, remaining 955.00 s)
300000 of 1000000000 tuples (0%) done (elapsed 0.33 s, remaining 1105.08 s)
400000 of 1000000000 tuples (0%) done (elapsed 0.53 s, remaining 1317.56 s)
500000 of 1000000000 tuples (0%) done (elapsed 0.63 s, remaining 1258.72 s)
...
500000000 of 1000000000 tuples (50%) done (elapsed 943.93 s, remaining 943.93 s)
500100000 of 1000000000 tuples (50%) done (elapsed 944.08 s, remaining 943.71 s)
500200000 of 1000000000 tuples (50%) done (elapsed 944.22 s, remaining 943.46 s)
500300000 of 1000000000 tuples (50%) done (elapsed 944.33 s, remaining 943.20 s)
500400000 of 1000000000 tuples (50%) done (elapsed 944.47 s, remaining 942.96 s)
500500000 of 1000000000 tuples (50%) done (elapsed 944.59 s, remaining 942.70 s)
500600000 of 1000000000 tuples (50%) done (elapsed 944.73 s, remaining 942.47 s)
...
999600000 of 1000000000 tuples (99%) done (elapsed 1878.28 s, remaining 0.75 s)
999700000 of 1000000000 tuples (99%) done (elapsed 1878.41 s, remaining 0.56 s)
999800000 of 1000000000 tuples (99%) done (elapsed 1878.58 s, remaining 0.38 s)
999900000 of 1000000000 tuples (99%) done (elapsed 1878.70 s, remaining 0.19 s)
1000000000 of 1000000000 tuples (100%) done (elapsed 1878.83 s, remaining 0.00 s)
vacuum...
set primary keys...
total time: 5978.44 s (insert 1878.90 s, commit 0.04 s, vacuum 2484.96 s, index 1614.54 s)
done.Như bây giờ chúng ta đã quen, kích thước cơ sở dữ liệu phải là 160GB. Hãy xác minh rằng:
postgres=> SELECT
postgres-> d.datname AS Name,
postgres-> pg_catalog.pg_get_userbyid(d.datdba) AS Owner,
postgres-> pg_catalog.pg_size_pretty(pg_catalog.pg_database_size(d.datname)) AS SIZE
postgres-> FROM pg_catalog.pg_database d
postgres-> WHERE d.datname = 'postgres';
name | owner | size
----------+-------------------+--------
postgres | cloudsqlsuperuser | 160 GB
(1 row)Với tất cả các bước chuẩn bị đã hoàn tất, hãy bắt đầu kiểm tra đọc / ghi:
[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: remaining connection slots are reserved for non-replication superuser connectionsGiáo sư! Mức tối đa là bao nhiêu?
postgres=> show max_connections ;
max_connections
-----------------
600
(1 row)Vì vậy, trong khi AWS đặt max_connections đủ lớn như tôi không gặp phải vấn đề đó, Google Cloud yêu cầu một chỉnh sửa nhỏ ... Quay lại bảng điều khiển đám mây, cập nhật thông số cơ sở dữ liệu, đợi vài phút rồi kiểm tra:
postgres=> show max_connections ;
max_connections
-----------------
1005
(1 row)Khởi động lại kiểm tra mọi thứ dường như hoạt động tốt:
starting vacuum...end.
progress: 60.0 s, 5461.7 tps, lat 172.821 ms stddev 251.666
progress: 120.0 s, 4444.5 tps, lat 225.162 ms stddev 365.695
progress: 180.0 s, 4338.5 tps, lat 230.484 ms stddev 373.998... nhưng có một cách bắt khác. Tôi đã rất ngạc nhiên khi cố gắng mở một phiên psql mới để đếm số lượng kết nối:
psql: FATAL: remaining connection slots are reserved for non-replication superuser connectionsCó thể là superuser_reserved_connections không ở chế độ mặc định?
postgres=> show superuser_reserved_connections ;
superuser_reserved_connections
--------------------------------
3
(1 row)Đó là mặc định, sau đó nó có thể là gì khác?
postgres=> select usename from pg_stat_activity ;
usename
---------------
cloudsqladmin
cloudsqlagent
postgres
(3 rows)Chơi lô tô! Tuy nhiên, một lỗi khác của max_connections sẽ xử lý nó, tuy nhiên, tôi yêu cầu khởi động lại quá trình kiểm tra pgbench. Và đó là câu chuyện của mọi người đằng sau lần chạy trùng lặp rõ ràng trong biểu đồ bên dưới.
Và cuối cùng, kết quả là:
Tiến trìnhprogress: 60.0 s, 4553.6 tps, lat 194.696 ms stddev 250.663
progress: 120.0 s, 3646.5 tps, lat 278.793 ms stddev 434.459
progress: 180.0 s, 3130.4 tps, lat 332.936 ms stddev 711.377
progress: 240.0 s, 3998.3 tps, lat 250.136 ms stddev 319.215
progress: 300.0 s, 3305.3 tps, lat 293.250 ms stddev 549.216
progress: 360.0 s, 3547.9 tps, lat 289.526 ms stddev 454.484
progress: 420.0 s, 3770.5 tps, lat 265.977 ms stddev 470.451
progress: 480.0 s, 3050.5 tps, lat 327.917 ms stddev 643.983
progress: 540.0 s, 3591.7 tps, lat 273.906 ms stddev 482.020
progress: 600.0 s, 3350.9 tps, lat 296.303 ms stddev 566.792
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: prepared
number of clients: 1000
number of threads: 1000
duration: 600 s
number of transactions actually processed: 2157735
latency average = 278.149 ms
latency stddev = 503.396 ms
tps = 3573.331659 (including connections establishing)
tps = 3591.759513 (excluding connections establishing)sysbench
Điền vào cơ sở dữ liệu:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250\
--oltp-table-size=450000 \
prepareĐầu ra:
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 450000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Inserting 450000 records into 'sbtest2'
...
Creating table 'sbtest249'...
Inserting 450000 records into 'sbtest249'
Creating secondary indexes on 'sbtest249'...
Creating table 'sbtest250'...
Inserting 450000 records into 'sbtest250'
Creating secondary indexes on 'sbtest250'...Và bây giờ hãy chạy thử nghiệm:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250 \
--oltp-table-size=450000 \
--max-requests=0 \
--forced-shutdown \
--report-interval=60 \
--oltp_simple_ranges=0 \
--oltp-distinct-ranges=0 \
--oltp-sum-ranges=0 \
--oltp-order-ranges=0 \
--oltp-point-selects=0 \
--rand-type=uniform \
--max-time=600 \
--num-threads=1000 \
runVà kết quả:
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 1000
Report intermediate results every 60 second(s)
Random number generator seed is 0 and will be ignored
Forcing shutdown in 630 seconds
Initializing worker threads...
Threads started!
[ 60s] threads: 1000, tps: 1320.25, reads: 0.00, writes: 5312.62, response time: 1484.54ms (95%), errors: 0.00, reconnects: 0.00
[ 120s] threads: 1000, tps: 1486.77, reads: 0.00, writes: 5944.30, response time: 1290.87ms (95%), errors: 0.00, reconnects: 0.00
[ 180s] threads: 1000, tps: 1143.62, reads: 0.00, writes: 4585.67, response time: 1649.50ms (95%), errors: 0.02, reconnects: 0.00
[ 240s] threads: 1000, tps: 1498.23, reads: 0.00, writes: 5993.06, response time: 1269.03ms (95%), errors: 0.00, reconnects: 0.00
[ 300s] threads: 1000, tps: 1520.53, reads: 0.00, writes: 6058.57, response time: 1439.90ms (95%), errors: 0.02, reconnects: 0.00
[ 360s] threads: 1000, tps: 1234.57, reads: 0.00, writes: 4958.08, response time: 1550.39ms (95%), errors: 0.02, reconnects: 0.00
[ 420s] threads: 1000, tps: 1722.25, reads: 0.00, writes: 6890.98, response time: 1132.25ms (95%), errors: 0.00, reconnects: 0.00
[ 480s] threads: 1000, tps: 2306.25, reads: 0.00, writes: 9233.84, response time: 842.11ms (95%), errors: 0.00, reconnects: 0.00
[ 540s] threads: 1000, tps: 1432.85, reads: 0.00, writes: 5720.15, response time: 1709.83ms (95%), errors: 0.02, reconnects: 0.00
[ 600s] threads: 1000, tps: 1332.93, reads: 0.00, writes: 5347.10, response time: 1443.78ms (95%), errors: 0.02, reconnects: 0.00
OLTP test statistics:
queries performed:
read: 0
write: 3603595
other: 1801795
total: 5405390
transactions: 900895 (1500.68 per sec.)
read/write requests: 3603595 (6002.76 per sec.)
other operations: 1801795 (3001.38 per sec.)
ignored errors: 5 (0.01 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 600.3231s
total number of events: 900895
total time taken by event execution: 600164.2510s
response time:
min: 6.78ms
avg: 666.19ms
max: 4218.55ms
approx. 95 percentile: 1397.02ms
Threads fairness:
events (avg/stddev): 900.8950/14.19
execution time (avg/stddev): 600.1643/0.10Chỉ số điểm chuẩn
Plugin PostgreSQL cho Stackdriver đã không được dùng nữa kể từ ngày 28 tháng 2 năm 2019. Mặc dù Google khuyến nghị Blue Medora, nhưng với mục đích của bài viết này, tôi đã chọn loại bỏ việc tạo tài khoản và dựa vào các số liệu Stackdriver có sẵn.
- Sử dụng CPU:
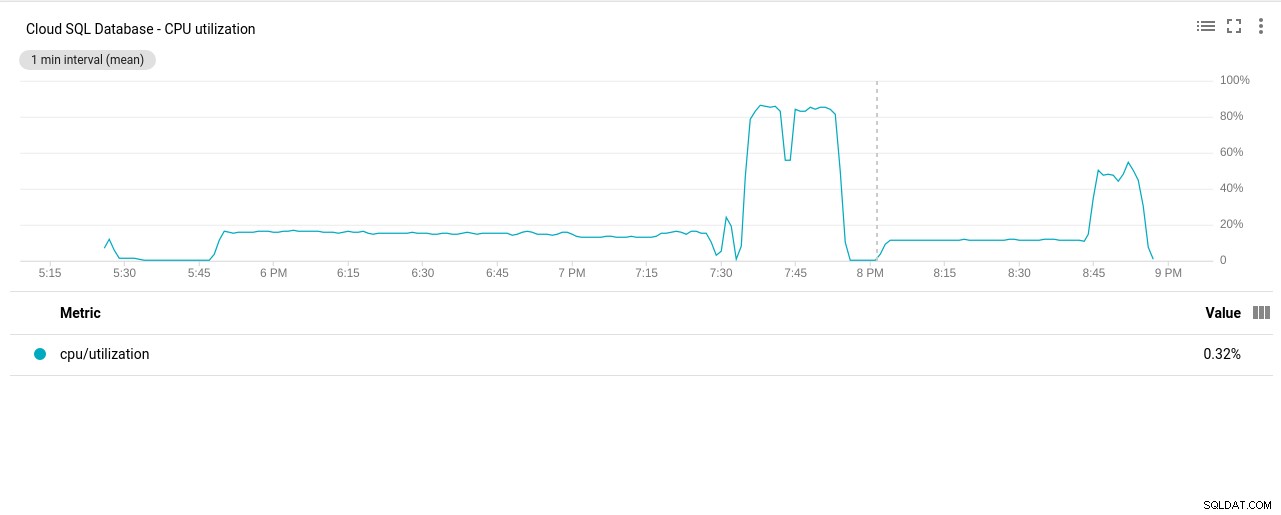 Tác giả ảnh Google Cloud SQL:Sử dụng CPU PostgreSQL
Tác giả ảnh Google Cloud SQL:Sử dụng CPU PostgreSQL - Thao tác Đọc / Ghi trên đĩa:
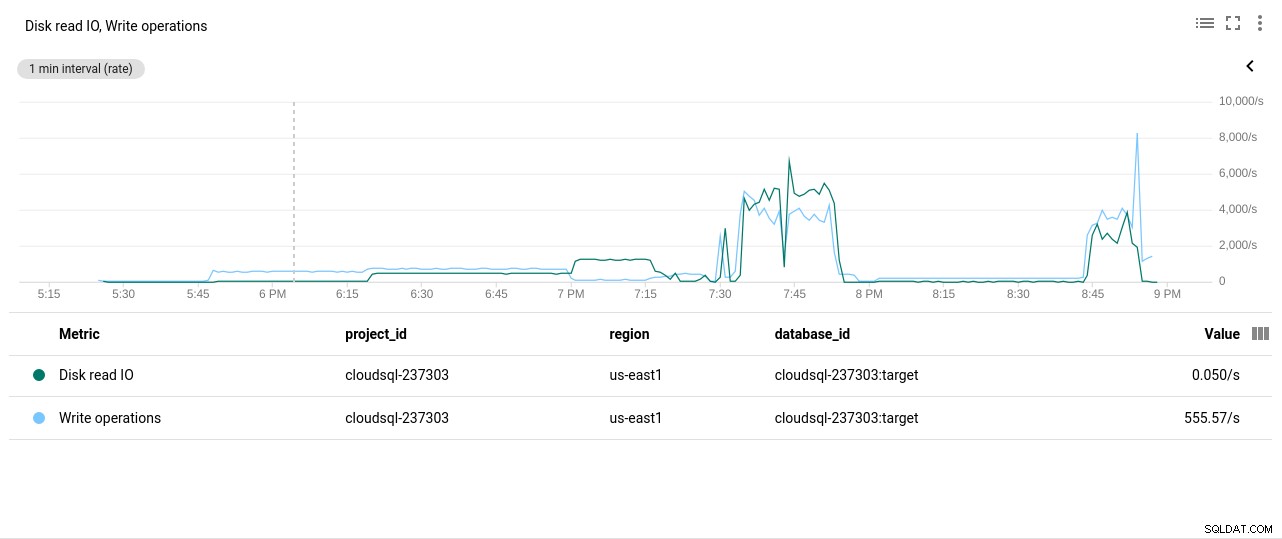 Tác giả ảnh Google Cloud SQL:Hoạt động đọc / ghi đĩa PostgreSQL
Tác giả ảnh Google Cloud SQL:Hoạt động đọc / ghi đĩa PostgreSQL - Số byte mạng đã gửi / nhận:
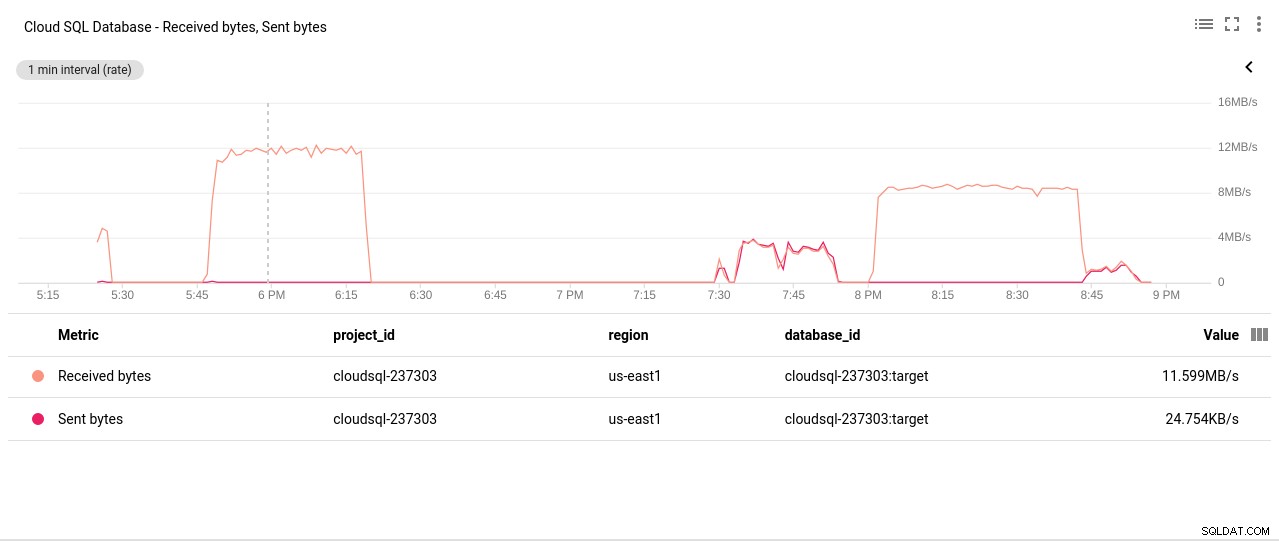 Tác giả ảnh Google Cloud SQL:PostgreSQL Network đã gửi / nhận byte
Tác giả ảnh Google Cloud SQL:PostgreSQL Network đã gửi / nhận byte - Số lượng Kết nối PostgreSQL:
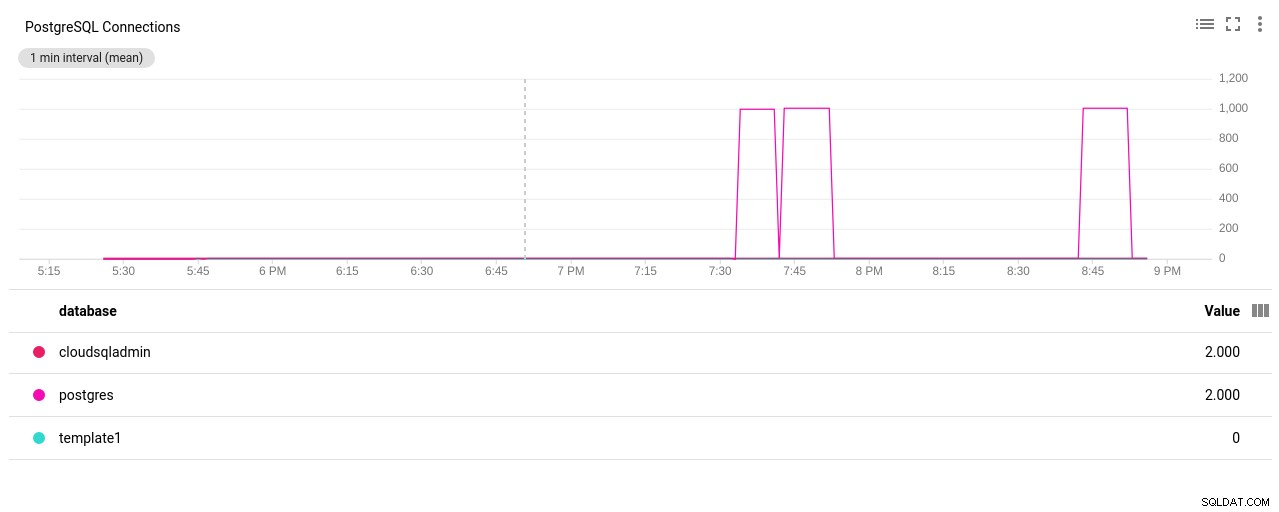 Tác giả ảnh Google Cloud SQL:Số lượng kết nối PostgreSQL
Tác giả ảnh Google Cloud SQL:Số lượng kết nối PostgreSQL
Kết quả điểm chuẩn
Khởi tạo pgbench
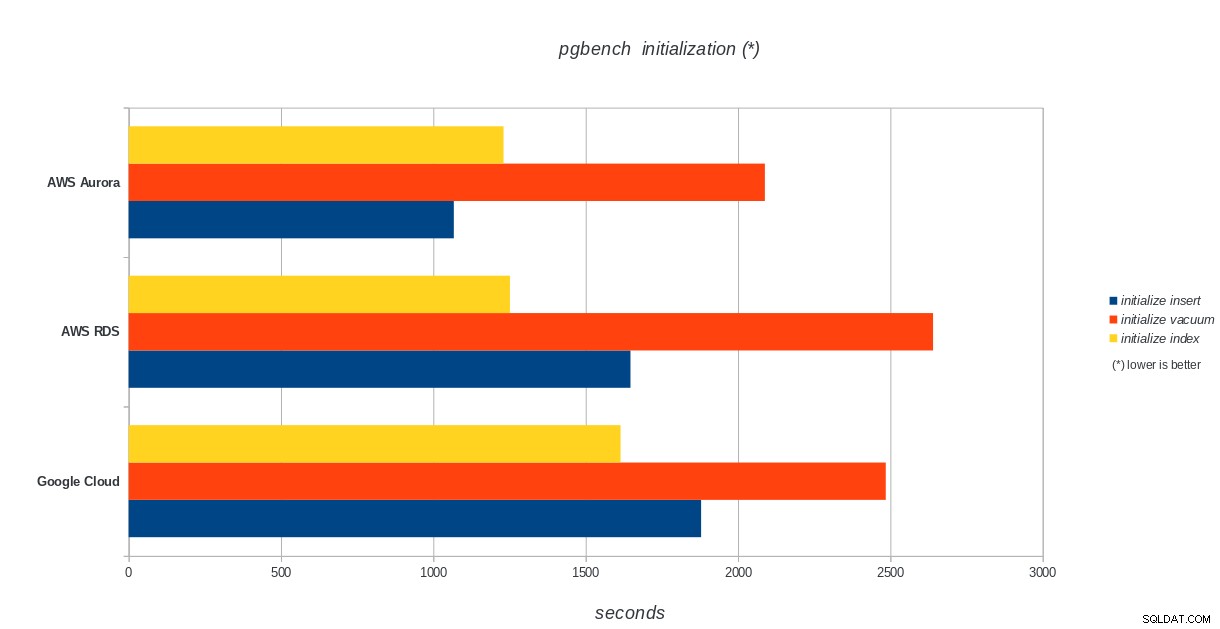 AWS Aurora, AWS RDS, Google Cloud SQL:Kết quả khởi tạo pgbench PostgreSQL
AWS Aurora, AWS RDS, Google Cloud SQL:Kết quả khởi tạo pgbench PostgreSQL pgbench run
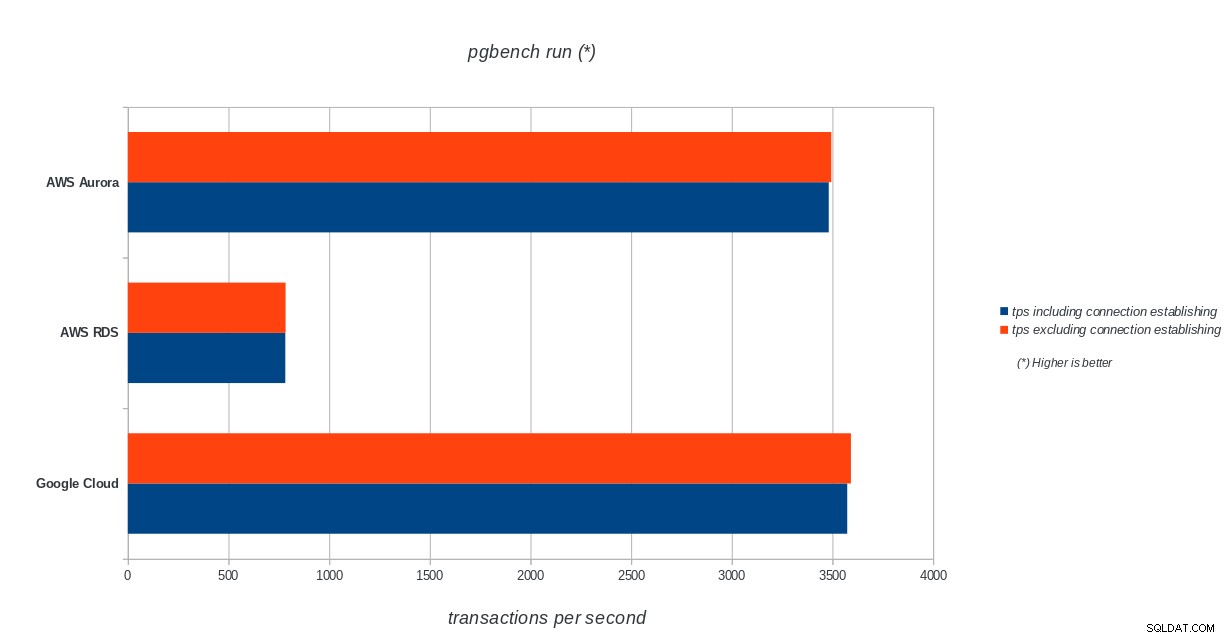 AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL pgbench kết quả chạy
AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL pgbench kết quả chạy sysbench
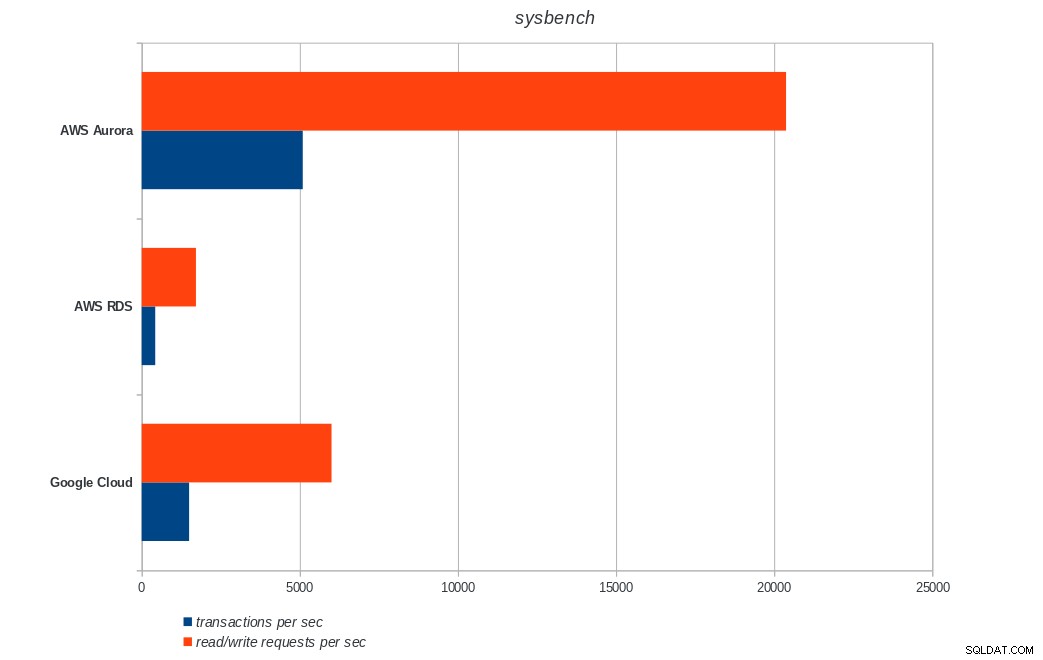 AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL sysbench kết quả
AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL sysbench kết quả Kết luận
Amazon Aurora đứng đầu trong các bài kiểm tra ghi nặng (sysbench), trong khi ngang bằng với Google Cloud SQL trong các bài kiểm tra đọc / ghi pgbench. Kiểm tra tải (khởi tạo pgbench) đặt Google Cloud SQL ở vị trí đầu tiên, tiếp theo là Amazon RDS. Dựa trên cái nhìn sơ lược về các mô hình định giá cho AWS Aurora và Google Cloud SQL, tôi mạo hiểm khi nói rằng Google Cloud là lựa chọn tốt hơn cho người dùng bình thường, trong khi AWS Aurora phù hợp hơn với môi trường hiệu suất cao. Sẽ có thêm phân tích sau khi hoàn thành tất cả các điểm chuẩn.
Phần tiếp theo và phần cuối cùng của loạt bài điểm chuẩn này sẽ có trên Microsoft Azure PostgreSQL.
Cảm ơn bạn đã đọc và vui lòng bình luận bên dưới nếu bạn có phản hồi.