Blog này là phần thứ hai của việc Triển khai Thiết lập Đa Trung tâm Dữ liệu cho PostgreSQL. Trong bài viết này, chúng tôi sẽ hướng dẫn cách triển khai PostgreSQL trong loại môi trường này và cách chuyển đổi dự phòng trong trường hợp lỗi chính bằng cách sử dụng tính năng tự động khôi phục ClusterControl.
Tại thời điểm này, chúng tôi sẽ cho rằng bạn có kết nối giữa các trung tâm dữ liệu (như chúng ta đã thấy trong phần đầu của blog này) và bạn có các máy chủ cần thiết cho tác vụ này (như chúng tôi cũng đã đề cập trong phần trước).
Triển khai Cụm PostgreSQL
Chúng tôi sẽ sử dụng ClusterControl cho tác vụ này, vì vậy chúng tôi sẽ giả sử bạn đã cài đặt nó (nó có thể được cài đặt trên cùng một máy chủ Load Balancer, nhưng nếu bạn có thể sử dụng một máy chủ khác thì tốt hơn).
Đi tới máy chủ ClusterControl của bạn và chọn tùy chọn 'Triển khai'. Nếu bạn đã có phiên bản PostgreSQL đang chạy, thì bạn cần chọn 'Nhập máy chủ / cơ sở dữ liệu hiện có'.
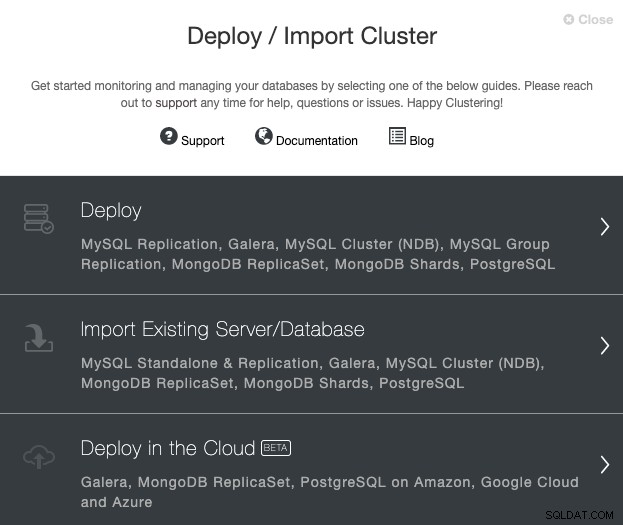
Khi chọn PostgreSQL, bạn phải chỉ định Người dùng, Khóa hoặc Mật khẩu và cổng để kết nối bằng SSH với các máy chủ PostgreSQL của chúng tôi. Bạn cũng cần tên cho cụm mới của mình và nếu bạn muốn ClusterControl cài đặt phần mềm và cấu hình tương ứng cho bạn.
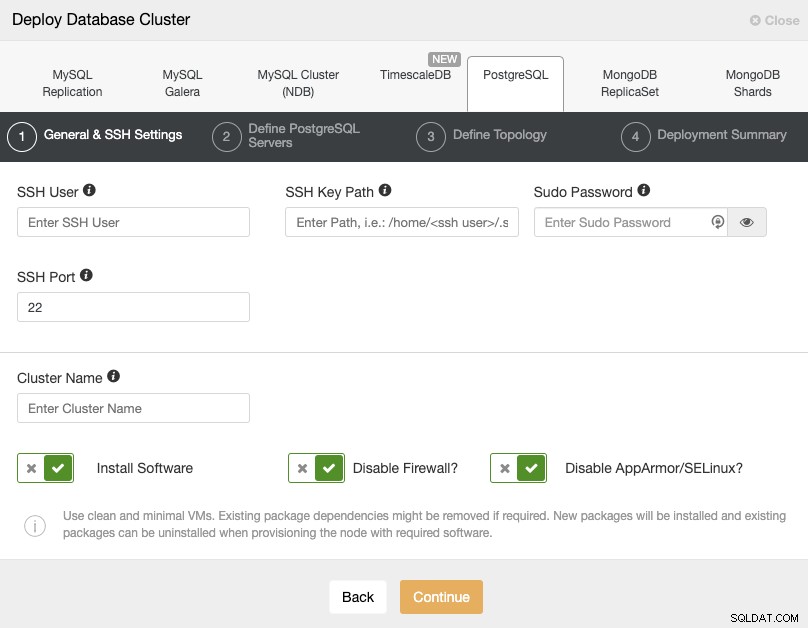
Vui lòng kiểm tra các yêu cầu của người dùng ClusterControl cho tác vụ này tại đây, nhưng nếu bạn đã làm theo blog trước, bạn nên sử dụng người dùng 'từ xa' ở đây và cổng SSH chính xác (như chúng tôi đã đề cập, bạn nên sử dụng một cổng khác nếu bạn đang sử dụng địa chỉ IP công cộng để truy cập nó thay vì VPN).
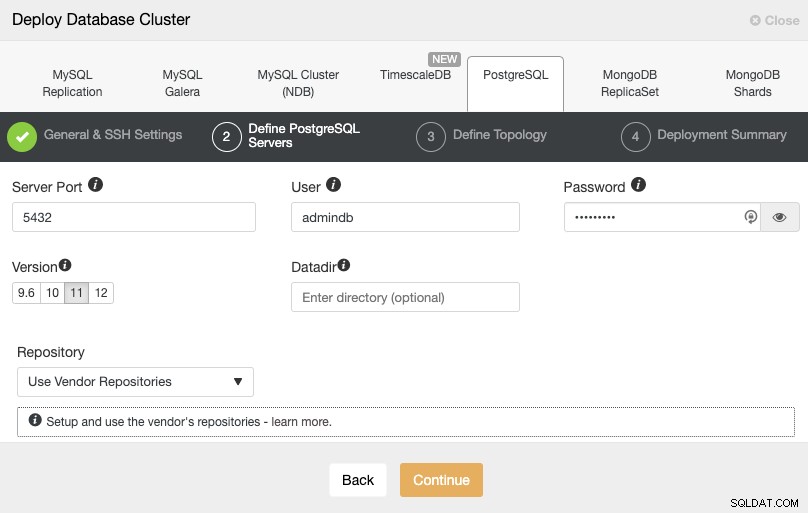
Sau khi thiết lập thông tin truy cập SSH, bạn phải xác định người dùng cơ sở dữ liệu, phiên bản và datadir (tùy chọn). Bạn cũng có thể chỉ định kho lưu trữ nào sẽ sử dụng. Trong bước tiếp theo, bạn cần thêm máy chủ của mình vào cụm mà bạn sẽ tạo.
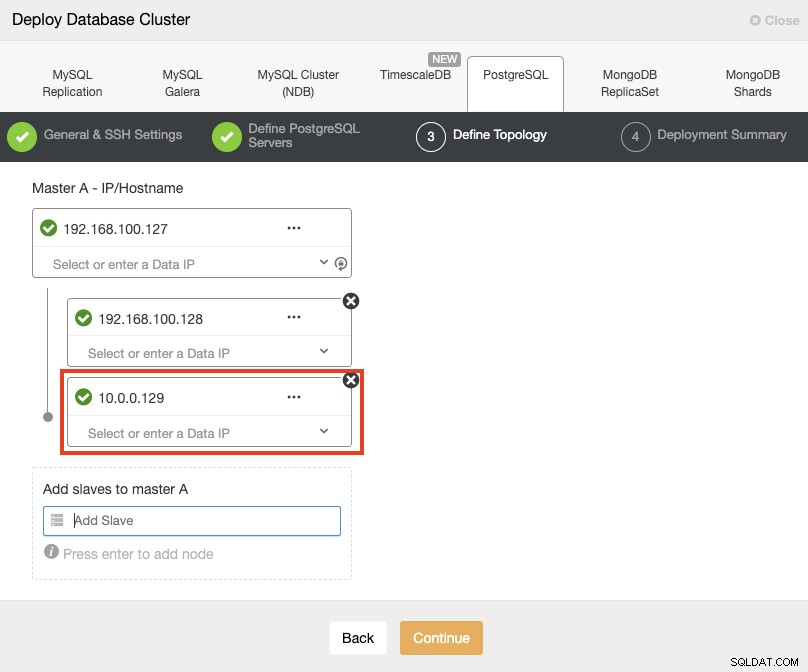
Khi thêm máy chủ, bạn có thể nhập IP hoặc tên máy chủ. Trong phần này, bạn sẽ sử dụng các địa chỉ IP công cộng của các máy chủ của mình và như bạn có thể thấy trong hộp màu đỏ, tôi đang sử dụng một mạng khác cho nút chờ thứ hai. ClusterControl không có bất kỳ giới hạn nào về mạng được sử dụng. Yêu cầu duy nhất về việc này là có quyền truy cập SSH vào nút.
Vì vậy, theo ví dụ trước của chúng tôi, các địa chỉ IP này phải là:
Primary Node: 35.166.37.12
Standby 1 Node: 35.166.37.13
Standby 2 Node: 18.197.23.14 (red box)Trong bước cuối cùng, bạn có thể chọn xem bản sao của mình là Đồng bộ hay Không đồng bộ.
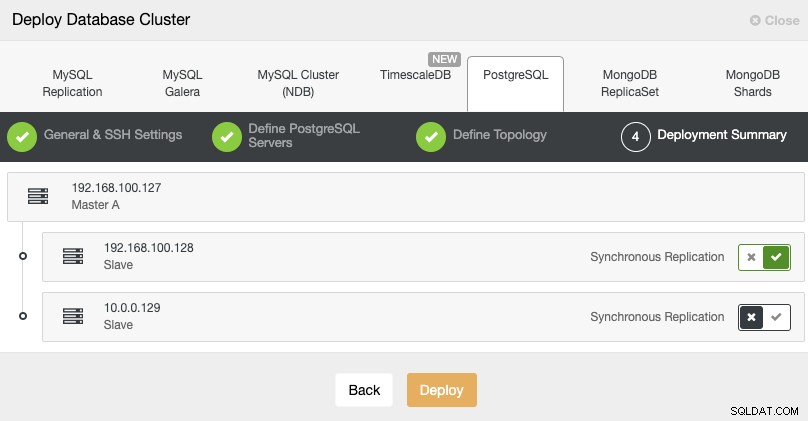
Trong trường hợp này, điều quan trọng là sử dụng sao chép không đồng bộ cho nút từ xa của bạn , nếu không, cụm của bạn có thể bị ảnh hưởng bởi độ trễ hoặc sự cố mạng.
Bạn có thể theo dõi trạng thái tạo cụm mới của mình từ trình theo dõi hoạt động ClusterControl.
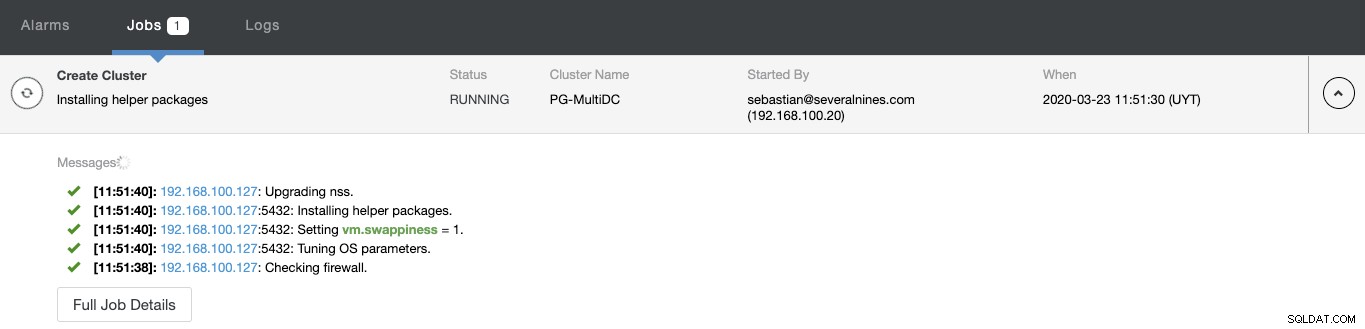
Khi nhiệm vụ hoàn thành, bạn có thể thấy cụm PostgreSQL mới của mình trong màn hình ClusterControl chính.

Thêm Bộ cân bằng tải PostgreSQL (HAProxy)
Khi bạn đã tạo cụm của mình, bạn có thể thực hiện một số tác vụ trên đó, chẳng hạn như thêm bộ cân bằng tải (HAProxy) hoặc một bản sao mới.
Để làm theo ví dụ trước của chúng tôi, hãy thêm một bộ cân bằng tải, như chúng tôi đã đề cập, nó sẽ giúp bạn quản lý môi trường HA của mình. Đối với điều này, hãy truy cập ClusterControl -> Chọn PostgreSQL Cluster -> Cluster Actions -> Thêm Load Balancer.
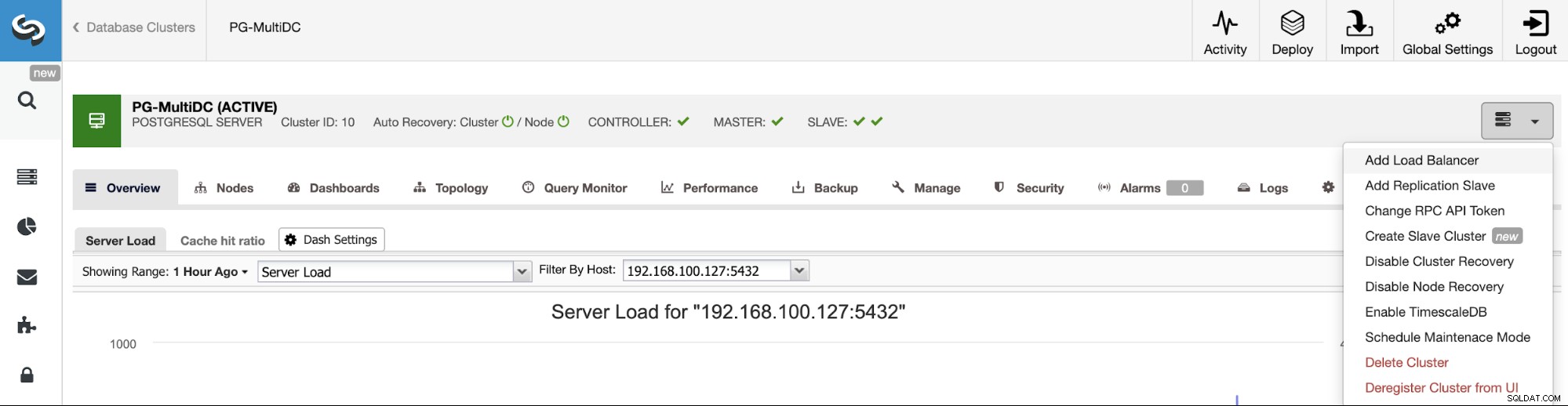
Tại đây, bạn phải thêm thông tin mà ClusterControl sẽ sử dụng để cài đặt và định cấu hình Bộ cân bằng tải HAProxy. Load Balancer này có thể được cài đặt trong cùng một máy chủ ClusterControl, nhưng nếu bạn có thể sử dụng một máy chủ khác, thậm chí còn tốt hơn.
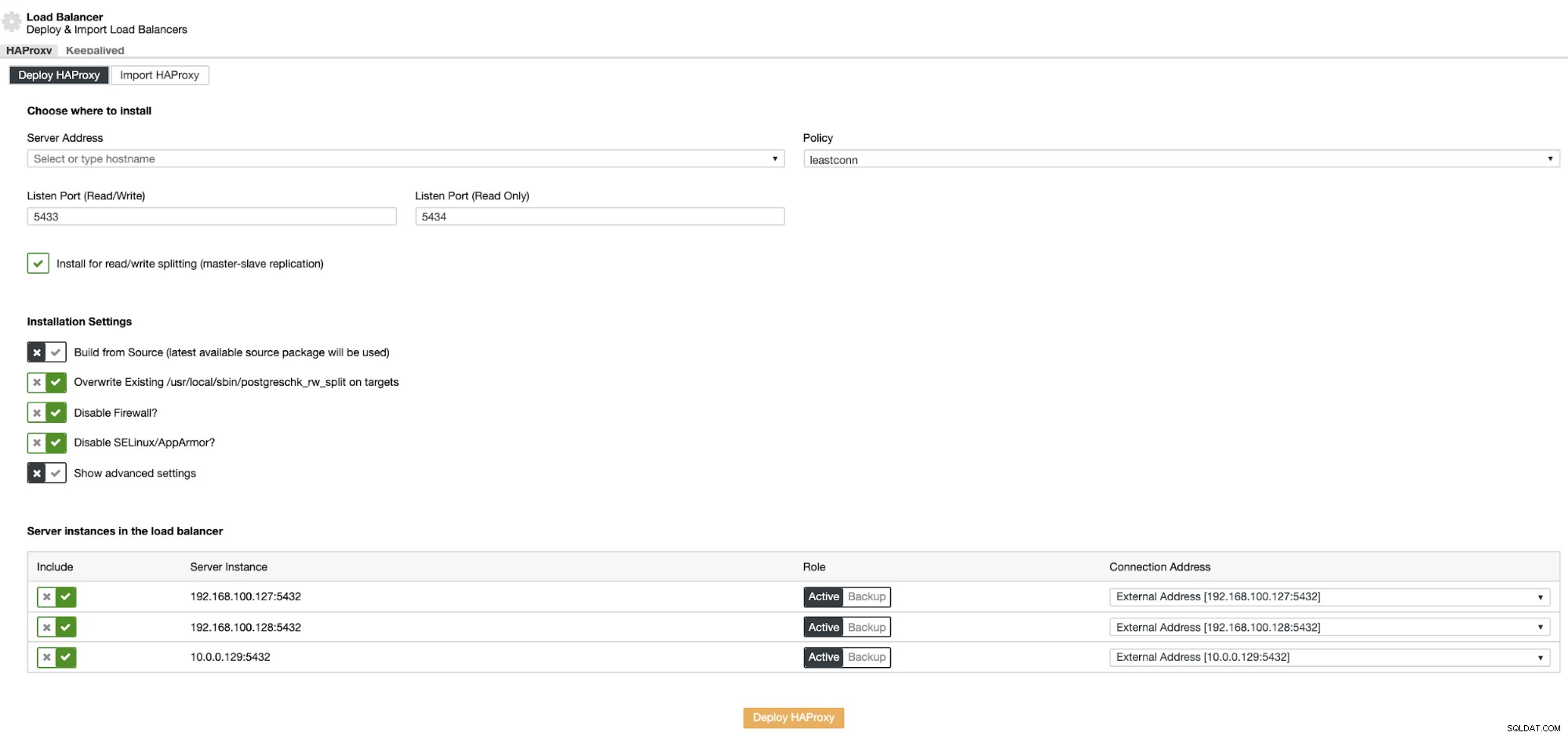
Thông tin bạn cần giới thiệu là:
Hành động:Triển khai hoặc Nhập.
Địa chỉ Máy chủ:Địa chỉ IP cho máy chủ HAProxy của bạn (Nó có thể là cùng một Địa chỉ IP ClusterControl).
Cổng Nghe (Đọc / Ghi):Cổng dành cho chế độ đọc / ghi.
Cổng Nghe (Chỉ đọc):Cổng dành cho chế độ chỉ đọc.
Chính sách:Có thể là:
- lessconn:Máy chủ có số lượng kết nối thấp nhất nhận được kết nối.
- roundrobin:Mỗi máy chủ được sử dụng lần lượt tùy theo trọng lượng của chúng.
- source:Địa chỉ IP nguồn được băm và chia cho tổng trọng lượng của các máy chủ đang chạy để chỉ định máy chủ nào sẽ nhận yêu cầu.
Cài đặt để phân tách đọc / ghi:Để sao chép master-slave.
Xây dựng từ Nguồn:Bạn có thể chọn Cài đặt từ trình quản lý gói hoặc xây dựng từ nguồn.
Và bạn cần chọn máy chủ nào bạn muốn thêm vào cấu hình HAProxy.
Ngoài ra, bạn có thể định cấu hình Cài đặt nâng cao như Người dùng quản trị, Tên phụ trợ, Hết thời gian chờ và hơn thế nữa.
Khi bạn hoàn tất cấu hình và xác nhận việc triển khai, bạn có thể theo dõi tiến trình trong phần Hoạt động trên Giao diện người dùng ClusterControl.
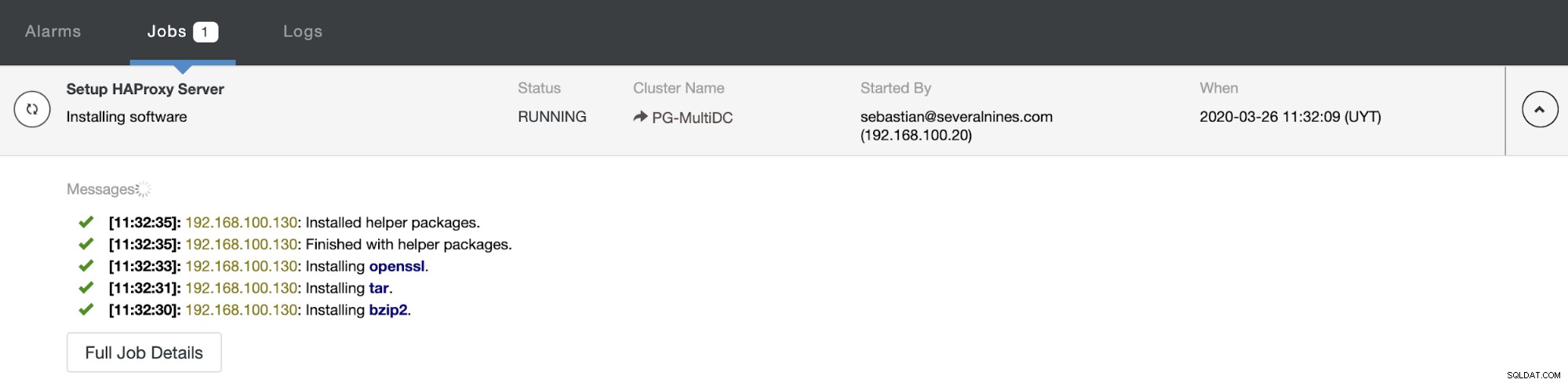
Và khi quá trình này kết thúc, bạn có thể truy cập ClusterControl -> Nodes -> Nút HAProxy và kiểm tra trạng thái hiện tại.
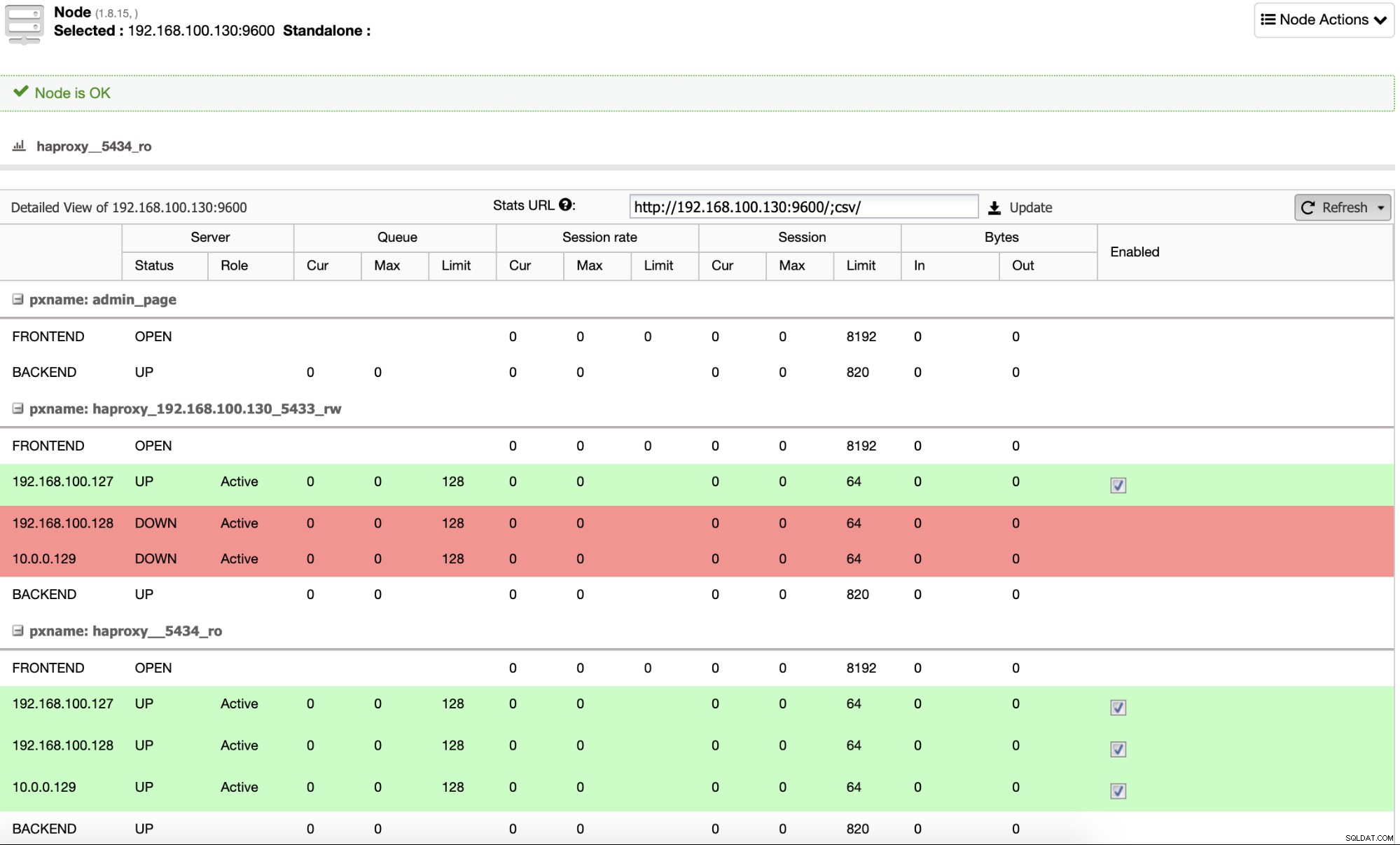
Theo mặc định, ClusterControl định cấu hình HAProxy với hai cổng khác nhau, một cổng dành cho Read- Viết, sẽ được sử dụng cho ứng dụng hoặc người dùng để ghi (và đọc) dữ liệu và một cái khác cho Chỉ đọc, sẽ được sử dụng để cân bằng lưu lượng đọc giữa tất cả các nút. Trong cổng Đọc-Ghi, chỉ có nút chính mới được kích hoạt và trong trường hợp lỗi chính, ClusterControl sẽ thúc đẩy nô lệ nâng cao nhất lên chế độ chính và sẽ cấu hình lại cổng này để vô hiệu hóa nút chính cũ và kích hoạt nút mới. Bằng cách này, ứng dụng của bạn vẫn có thể hoạt động trong trường hợp cơ sở dữ liệu chính bị lỗi, vì lưu lượng được Bộ cân bằng tải chuyển hướng đến đúng nút.
Bạn cũng có thể giám sát các máy chủ HAProxy của mình khi kiểm tra phần Trang tổng quan.
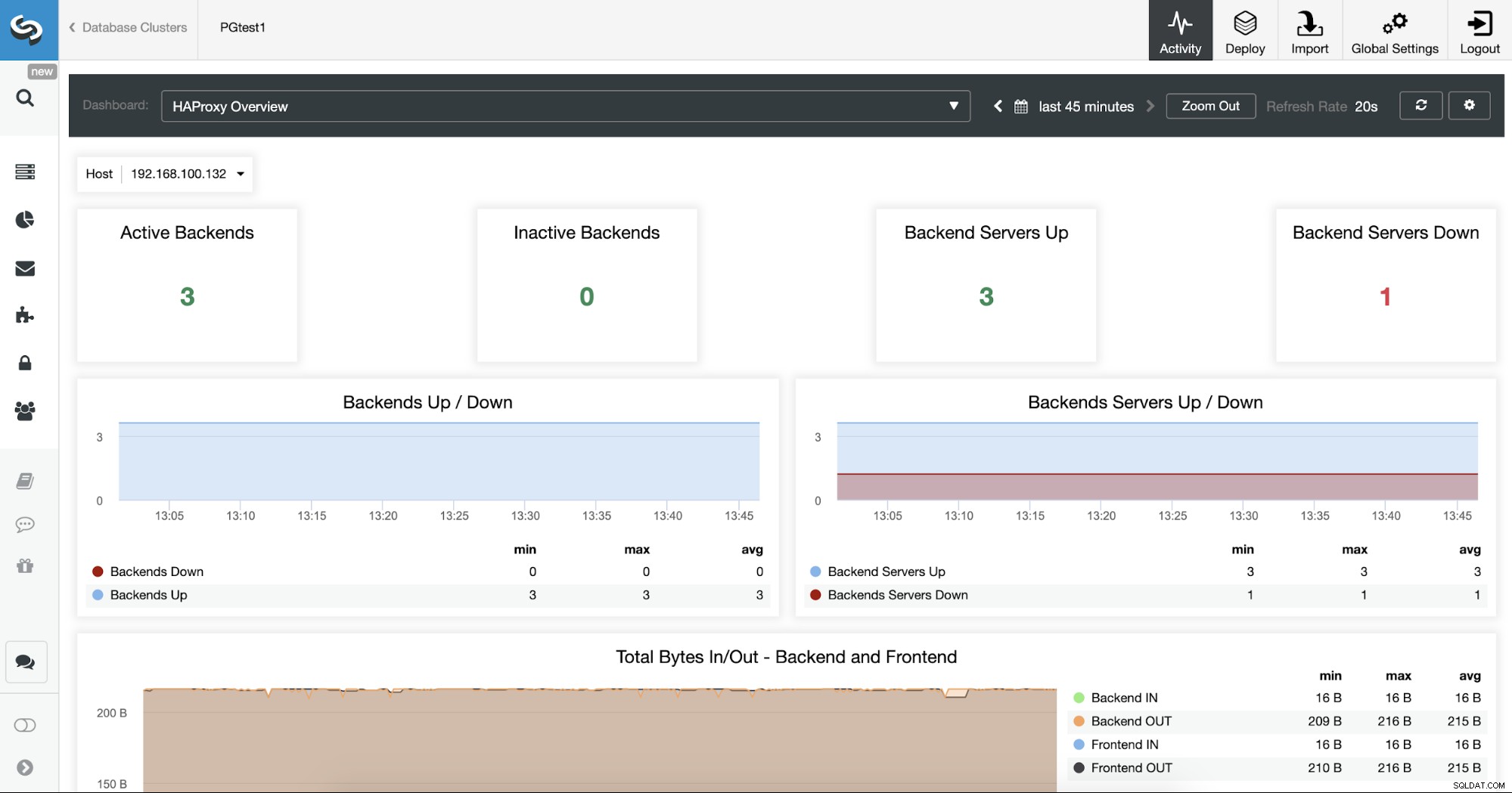
Bây giờ, bạn có thể cải thiện thiết kế HA của mình bằng cách thêm một nút HAProxy mới trong trung tâm dữ liệu từ xa và định cấu hình dịch vụ Keepalived giữa chúng. Keepalived sẽ cho phép bạn sử dụng địa chỉ IP ảo được gán cho nút Load Balancer đang hoạt động. Nếu nút này không thành công, IP ảo này sẽ được di chuyển sang nút HAProxy phụ, do đó, việc định cấu hình IP này trong ứng dụng của bạn sẽ cho phép bạn giữ mọi thứ hoạt động trong trường hợp có sự cố Load Balancer.
Tất cả cấu hình này có thể được thực hiện bằng ClusterControl.
Kết luận
Bằng cách theo dõi blog gồm hai phần này, bạn có thể triển khai thiết lập nhiều trung tâm dữ liệu cho PostgreSQL với tính khả dụng cao và kết nối SSH giữa trung tâm dữ liệu, để tránh sự phức tạp của cấu hình VPN.
Sử dụng sao chép không đồng bộ cho nút từ xa, bạn sẽ tránh được bất kỳ vấn đề nào liên quan đến độ trễ và hiệu suất mạng và sử dụng ClusterControl, bạn sẽ có chuyển đổi dự phòng tự động (hoặc thủ công) trong trường hợp bị lỗi (trong số một số tính năng khác). Đây có thể là cách đơn giản nhất để tiếp cận cấu trúc liên kết này và chúng tôi hy vọng điều này sẽ hữu ích cho bạn.