Sự cố trễ sao chép trong PostgreSQL không phải là vấn đề phổ biến đối với hầu hết các thiết lập. Mặc dù, nó có thể xảy ra và khi nó xảy ra, nó có thể ảnh hưởng đến thiết lập sản xuất của bạn. PostgreSQL được thiết kế để xử lý nhiều luồng, chẳng hạn như truy vấn song song hoặc triển khai các luồng công nhân để xử lý các tác vụ cụ thể dựa trên các giá trị được gán trong cấu hình. PostgreSQL được thiết kế để xử lý tải nặng và căng thẳng, nhưng đôi khi (do cấu hình không tốt) máy chủ của bạn vẫn có thể đi xuống phía nam.
Xác định độ trễ sao chép trong PostgreSQL không phải là một nhiệm vụ phức tạp để thực hiện, nhưng có một số cách tiếp cận khác nhau để xem xét vấn đề. Trong blog này, chúng ta sẽ xem xét những điều cần xem xét khi bản sao PostgreSQL của bạn bị trễ.
Các kiểu Sao chép trong PostgreSQL
Trước khi đi sâu vào chủ đề, trước tiên chúng ta hãy xem quá trình sao chép trong PostgreSQL phát triển như thế nào vì có nhiều phương pháp và giải pháp đa dạng khi xử lý sao chép.
Chế độ chờ ấm áp cho PostgreSQL đã được triển khai trong phiên bản 8.2 (trở lại năm 2006) và dựa trên phương pháp vận chuyển nhật ký. Điều này có nghĩa là các bản ghi WAL được chuyển trực tiếp từ máy chủ cơ sở dữ liệu này sang máy chủ cơ sở dữ liệu khác để được áp dụng hoặc đơn giản là một cách tiếp cận tương tự đối với PITR hoặc rất giống những gì bạn đang làm với rsync.
Cách tiếp cận này, thậm chí là cũ, vẫn được sử dụng cho đến ngày nay và một số tổ chức thực sự thích cách tiếp cận cũ hơn này. Cách tiếp cận này thực hiện vận chuyển nhật ký dựa trên tệp bằng cách chuyển các bản ghi WAL một tệp (phân đoạn WAL) tại một thời điểm. Mặc dù nó có một mặt trái; Một lỗi lớn trên các máy chủ chính, các giao dịch chưa được vận chuyển sẽ bị mất. Có một cửa sổ cho việc mất dữ liệu (bạn có thể điều chỉnh điều này bằng cách sử dụng tham số archive_timeout, có thể được đặt ở mức thấp trong vài giây, nhưng cài đặt thấp như vậy sẽ làm tăng đáng kể băng thông cần thiết để vận chuyển tệp).
Trong phiên bản PostgreSQL 9.0, Streaming Replication đã được giới thiệu. Tính năng này cho phép chúng tôi cập nhật nhiều hơn khi so sánh với việc vận chuyển nhật ký dựa trên tệp. Cách tiếp cận của nó là bằng cách chuyển các bản ghi WAL (một tệp WAL bao gồm các bản ghi WAL) ngay lập tức (chỉ đơn thuần là vận chuyển nhật ký dựa trên bản ghi), giữa một máy chủ chính và một hoặc một số máy chủ dự phòng. Giao thức này không cần đợi tệp WAL được điền, không giống như vận chuyển nhật ký dựa trên tệp. Trong thực tế, một quá trình được gọi là bộ thu WAL, chạy trên máy chủ dự phòng, sẽ kết nối với máy chủ chính bằng kết nối TCP / IP. Trong máy chủ chính, tồn tại một quá trình khác có tên là người gửi WAL. Nó có vai trò phụ trách việc gửi các đăng ký WAL đến (các) máy chủ dự phòng khi chúng xảy ra.
Thiết lập Sao chép không đồng bộ trong sao chép trực tuyến có thể phát sinh các vấn đề như mất dữ liệu hoặc độ trễ nô lệ, vì vậy phiên bản 9.1 giới thiệu tính năng sao chép đồng bộ. Trong sao chép đồng bộ, mỗi cam kết của một giao dịch ghi sẽ đợi cho đến khi nhận được xác nhận rằng cam kết đã được ghi vào nhật ký ghi trước trên đĩa của cả máy chủ chính và máy chủ dự phòng. Phương pháp này giảm thiểu khả năng mất dữ liệu, vì để điều đó xảy ra, chúng ta sẽ cần cả bản gốc và chế độ chờ không bị lỗi cùng một lúc.
Nhược điểm rõ ràng của cấu hình này là thời gian phản hồi cho mỗi giao dịch ghi tăng lên, vì chúng ta cần đợi cho đến khi tất cả các bên đã phản hồi. Không giống như MySQL, không có hỗ trợ như trong môi trường bán đồng bộ của MySQL, nó sẽ dự phòng trở về không đồng bộ nếu thời gian chờ đã xảy ra. Vì vậy, trong Với PostgreSQL, thời gian cho một cam kết (tối thiểu) là chuyến đi khứ hồi giữa chế độ chính và chế độ chờ. Giao dịch chỉ đọc sẽ không bị ảnh hưởng bởi điều đó.
Khi nó phát triển, PostgreSQL liên tục cải tiến và bản sao của nó rất đa dạng. Ví dụ:bạn có thể sử dụng sao chép không đồng bộ luồng vật lý hoặc sử dụng sao chép luồng hợp lý. Cả hai đều được giám sát khác nhau mặc dù sử dụng cùng một cách tiếp cận khi gửi dữ liệu qua sao chép, tức là vẫn đang sao chép trực tuyến. Để biết thêm chi tiết, hãy kiểm tra hướng dẫn sử dụng để biết các loại giải pháp khác nhau trong PostgreSQL khi xử lý sao chép.
Nguyên nhân của Trễ sao chép PostgreSQL
Như đã định nghĩa trong blog trước của chúng tôi, độ trễ sao chép là chi phí của độ trễ đối với (các) giao dịch hoặc (các) hoạt động được tính bằng chênh lệch thời gian thực hiện giữa chính / chủ so với chế độ chờ / phụ nút.
Vì PostgreSQL đang sử dụng sao chép trực tuyến, nó được thiết kế để nhanh chóng vì các thay đổi được ghi lại dưới dạng một tập hợp các bản ghi nhật ký (từng byte) khi bị chặn bởi bộ thu WAL, sau đó ghi các bản ghi nhật ký này vào tệp WAL. Sau đó, quá trình khởi động bằng PostgreSQL phát lại dữ liệu từ phân đoạn WAL đó và quá trình sao chép trực tuyến bắt đầu. Trong PostgreSQL, độ trễ sao chép có thể xảy ra do các yếu tố sau:
- Sự cố mạng
- Không thể tìm thấy phân đoạn WAL từ phân đoạn chính. Thông thường, điều này là do hành vi điểm kiểm tra trong đó các phân đoạn WAL được quay hoặc tái chế
- Các nút bận ((các) nút chính và dự phòng). Có thể do các quy trình bên ngoài gây ra hoặc một số truy vấn không hợp lệ gây ra việc sử dụng nhiều tài nguyên
- Các vấn đề về phần cứng hoặc phần cứng không tốt gây ra độ trễ
- Cấu hình kém trong PostgreSQL chẳng hạn như số lượng nhỏ max_wal_senders được đặt trong khi xử lý hàng tấn yêu cầu giao dịch (hoặc khối lượng lớn thay đổi).
Cần tìm gì với độ trễ sao chép PostgreSQL
Quá trình sao chép PostgreSQL chưa đa dạng nhưng việc theo dõi tình trạng sao chép là tinh tế nhưng không phức tạp. Trong cách tiếp cận này, chúng tôi sẽ giới thiệu dựa trên thiết lập chế độ chờ chính với tính năng sao chép phát trực tuyến không đồng bộ. Việc sao chép hợp lý không thể mang lại lợi ích cho hầu hết các trường hợp chúng ta đang thảo luận ở đây nhưng chế độ xem pg_stat_subscription có thể giúp bạn thu thập thông tin. Tuy nhiên, chúng tôi sẽ không tập trung vào điều đó trong blog này.
Sử dụng Chế độ xem pg_stat_replication
Cách tiếp cận phổ biến nhất là chạy một truy vấn tham chiếu đến chế độ xem này trong nút chính. Hãy nhớ rằng, bạn chỉ có thể thu thập thông tin từ nút chính bằng cách sử dụng chế độ xem này. Dạng xem này chứa định nghĩa bảng sau dựa trên PostgreSQL 11 như được hiển thị bên dưới:
postgres=# \d pg_stat_replication
View "pg_catalog.pg_stat_replication"
Column | Type | Collation | Nullable | Default
------------------+--------------------------+-----------+----------+---------
pid | integer | | |
usesysid | oid | | |
usename | name | | |
application_name | text | | |
client_addr | inet | | |
client_hostname | text | | |
client_port | integer | | |
backend_start | timestamp with time zone | | |
backend_xmin | xid | | |
state | text | | |
sent_lsn | pg_lsn | | |
write_lsn | pg_lsn | | |
flush_lsn | pg_lsn | | |
replay_lsn | pg_lsn | | |
write_lag | interval | | |
flush_lag | interval | | |
replay_lag | interval | | |
sync_priority | integer | | |
sync_state | text | | | Trường hợp các trường được xác định là (bao gồm phiên bản PG <10),
- pid :Id tiến trình của tiến trình walsender
- useysid :OID của người dùng được sử dụng để sao chép Truyền trực tuyến.
- tên người dùng :Tên người dùng được sử dụng để sao chép Truyền trực tuyến
- application_name :Tên ứng dụng được kết nối với chính
- client_addr :Địa chỉ sao chép ở chế độ chờ / phát trực tuyến
- client_hostname :Tên máy chủ của chế độ chờ.
- client_port :Số cổng TCP ở chế độ chờ giao tiếp với người gửi WAL
- backend_start :Thời gian bắt đầu khi SR kết nối với Master.
- backend_xmin :đường chân trời xmin ở chế độ chờ được hot_standby_feedback báo cáo.
- trạng thái :Trạng thái người gửi WAL hiện tại, tức là đang phát trực tuyến
- sent_lsn / sent_location :Vị trí giao dịch cuối cùng được gửi về chế độ chờ.
- write_lsn / write_location :Giao dịch cuối cùng được ghi trên đĩa ở chế độ chờ
- flush_lsn / flush_location :Giao dịch cuối cùng sẽ được xóa trên đĩa ở chế độ chờ.
- replay_lsn / replay_location :Giao dịch cuối cùng sẽ được xóa trên đĩa ở chế độ chờ.
- write_lag :Thời gian đã trôi qua trong thời gian WAL đã cam kết từ chính đến chế độ chờ (nhưng chưa được cam kết trong chế độ chờ)
- flush_lag :Thời gian đã trôi qua trong thời gian WAL đã cam kết từ chính đến chế độ chờ (WAL đã được xóa nhưng chưa được áp dụng)
- replay_lag :Thời gian đã trôi qua trong các WAL đã cam kết từ chính đến dự phòng (cam kết hoàn toàn trong nút chờ)
- sync_priasty :Mức độ ưu tiên của máy chủ dự phòng được chọn làm chế độ chờ đồng bộ
- sync_state :Đồng bộ hóa Trạng thái chờ (không đồng bộ hay đồng bộ).
Một truy vấn mẫu sẽ trông như sau trong PostgreSQL 9.6,
paultest=# select * from pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 7174
usesysid | 16385
usename | cmon_replication
application_name | pgsql_1_node_1
client_addr | 192.168.30.30
client_hostname |
client_port | 10580
backend_start | 2020-02-20 18:45:52.892062+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | async
-[ RECORD 2 ]----+------------------------------
pid | 7175
usesysid | 16385
usename | cmon_replication
application_name | pgsql_80_node_2
client_addr | 192.168.30.20
client_hostname |
client_port | 60686
backend_start | 2020-02-20 18:45:52.899446+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | asyncĐiều này về cơ bản cho bạn biết khối vị trí nào trong các phân đoạn WAL đã được viết, xóa hoặc áp dụng. Nó cung cấp cho bạn cái nhìn chi tiết về trạng thái sao chép.
Truy vấn sử dụng trong nút chờ
Trong nút chờ, có các chức năng được hỗ trợ mà bạn có thể giảm thiểu điều này thành một truy vấn và cung cấp cho bạn tổng quan về tình trạng sao chép dự phòng của bạn. Để thực hiện việc này, bạn có thể chạy truy vấn sau bên dưới (truy vấn dựa trên phiên bản PG> 10),
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00Trong các phiên bản cũ hơn, bạn có thể sử dụng truy vấn sau:
postgres=# select pg_is_in_recovery(),pg_last_xlog_receive_location(), pg_last_xlog_replay_location(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_last_xlog_receive_location | 1/9FD6490
pg_last_xlog_replay_location | 1/9FD6490
pg_last_xact_replay_timestamp | 2020-02-21 08:32:40.485958-06Truy vấn cho biết điều gì? Các chức năng được định nghĩa tương ứng tại đây,
- pg_is_in_recovery ():(boolean) Đúng nếu quá trình khôi phục vẫn đang diễn ra.
- pg_last_wal_receive_lsn () / pg_last_xlog_receive_location ():(pg_lsn) Vị trí nhật ký ghi trước được nhận và đồng bộ hóa với đĩa bằng cách sao chép trực tuyến.
- pg_last_wal_replay_lsn () / pg_last_xlog_replay_location ():(pg_lsn) Vị trí nhật ký ghi trước lần cuối được phát lại trong quá trình khôi phục. Nếu quá trình khôi phục vẫn đang được tiến hành, điều này sẽ tăng lên một cách đơn điệu.
- pg_last_xact_replay_timestamp ():(Dấu thời gian với múi giờ) Nhận dấu thời gian của giao dịch cuối cùng được phát lại trong quá trình khôi phục.
Sử dụng một số phép toán cơ bản, bạn có thể kết hợp các hàm này. Hàm được sử dụng phổ biến nhất được sử dụng bởi DBA là,
SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
hoặc trong các phiên bản PG <10,
SELECT CASE WHEN pg_last_xlog_receive_location() = pg_last_xlog_replay_location()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;Mặc dù truy vấn này đã được sử dụng trong thực tế và được sử dụng bởi DBA. Tuy nhiên, nó không cung cấp cho bạn một cái nhìn chính xác về độ trễ. Tại sao? Hãy thảo luận vấn đề này trong phần tiếp theo.
Xác định Trễ do Sự vắng mặt của Phân đoạn WAL gây ra
Các nút dự phòng của PostgreSQL, đang ở chế độ khôi phục, không báo cáo cho bạn trạng thái chính xác về những gì đang xảy ra trong quá trình sao chép của bạn. Không trừ khi bạn xem nhật ký PG, bạn có thể thu thập thông tin về những gì đang xảy ra. Không có truy vấn nào bạn có thể chạy để xác định điều này. Trong hầu hết các trường hợp, các tổ chức và thậm chí các tổ chức nhỏ sử dụng phần mềm của bên thứ 3 để cho phép họ được cảnh báo khi có báo động.
Một trong số đó là ClusterControl, cung cấp cho bạn khả năng quan sát, gửi cảnh báo khi báo động được nâng lên hoặc khôi phục nút của bạn trong trường hợp thảm họa hoặc thảm họa xảy ra. Hãy xem trường hợp này, cụm sao chép luồng không đồng bộ chính ở chế độ chờ của tôi đã bị lỗi. Làm thế nào bạn có thể biết nếu có điều gì đó không ổn? Hãy kết hợp những điều sau:
Bước 1:Xác định xem có Trễ không
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
-[ RECORD 1 ]
log_delay | 0Bước 2:Xác định phân đoạn WAL nhận được từ nút chính và so sánh với nút chờ
## Get the master's current LSN. Run the query below in the master
postgres=# SELECT pg_current_wal_lsn();
-[ RECORD 1 ]------+-----------
pg_current_wal_lsn | 0/925D7E70Đối với các phiên bản cũ hơn của PG <10, hãy sử dụng pg_current_xlog_location.
## Get the current WAL segments received (flushed or applied/replayed)
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00Trông có vẻ tệ.
Bước 3:Xác định mức độ tồi tệ của nó
Bây giờ, hãy trộn công thức từ bước # 1 với bước # 2 và nhận được sự khác biệt. Làm thế nào để làm điều này, PostgreSQL có một hàm được gọi là pg_wal_lsn_diff được định nghĩa là,
pg_wal_lsn_diff (lsn pg_lsn, lsn pg_lsn) / pg_xlog_location_diff (vị trí pg_lsn, vị trí pg_lsn):(số) Tính toán sự khác biệt giữa hai vị trí nhật ký ghi trước
Bây giờ, hãy sử dụng nó để xác định độ trễ. Bạn có thể chạy nó trong bất kỳ nút PG nào, vì nút này chúng tôi sẽ chỉ cung cấp các giá trị tĩnh:
postgres=# select pg_wal_lsn_diff('0/925D7E70','0/2705BDA0'); -[ RECORD 1 ]---+-----------
pg_wal_lsn_diff | 1800913104Hãy ước tính 1800913104 là bao nhiêu, dường như khoảng 1,6GiB có thể đã bị thiếu trong nút chờ,
postgres=# select round(1800913104/pow(1024,3.0),2) missing_lsn_GiB;
-[ RECORD 1 ]---+-----
missing_lsn_gib | 1.68Cuối cùng, bạn có thể tiếp tục hoặc thậm chí trước khi truy vấn, hãy xem nhật ký như sử dụng tail -5f để theo dõi và kiểm tra những gì đang xảy ra. Làm điều này cho cả hai nút chính / dự phòng. Trong ví dụ này, chúng ta sẽ thấy rằng nó có vấn đề,
## Primary
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_033512.log
2020-02-21 16:44:33.574 UTC [25023] ERROR: requested WAL segment 000000030000000000000027 has already been removed
...
## Standby
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_014137.log
2020-02-21 16:45:23.599 UTC [26976] LOG: started streaming WAL from primary at 0/27000000 on timeline 3
2020-02-21 16:45:23.599 UTC [26976] FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000030000000000000027 has already been removed
...Khi gặp sự cố này, tốt hơn hết bạn nên xây dựng lại các nút dự phòng của mình. Trong ClusterControl, nó dễ dàng như một cú nhấp chuột. Chỉ cần chuyển đến phần Nodes / Topology và xây dựng lại nút giống như bên dưới:
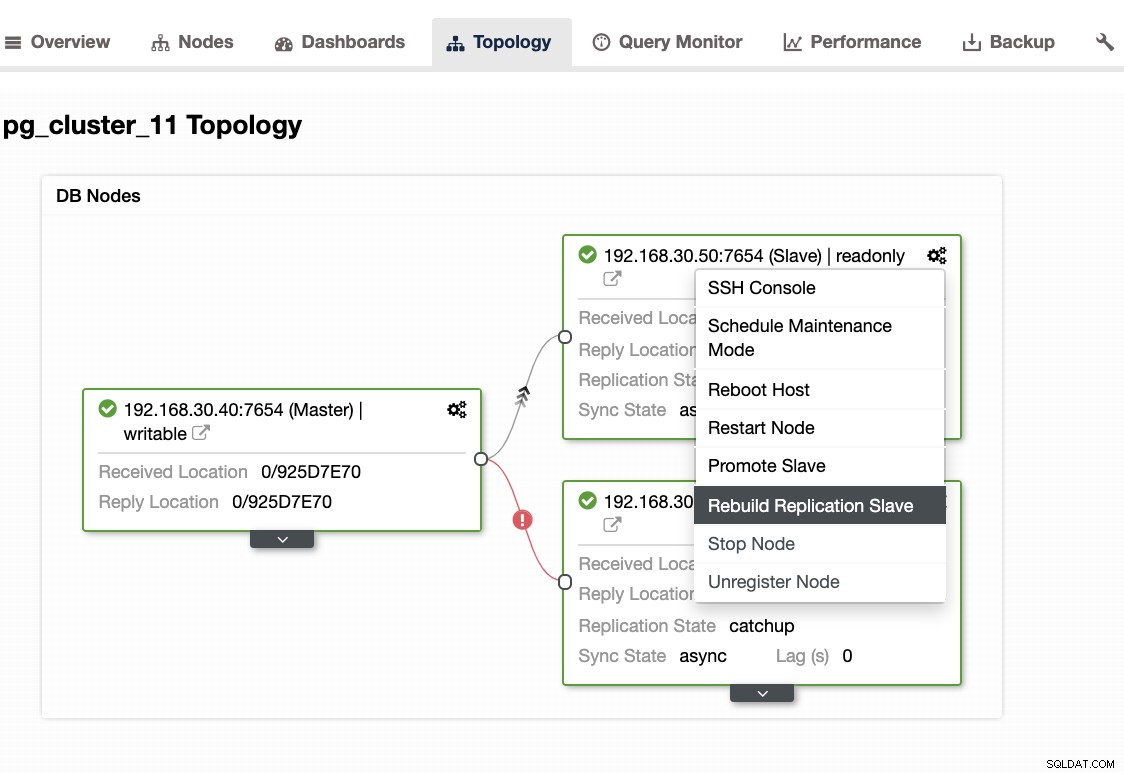
Những điều khác cần kiểm tra
Bạn có thể sử dụng cách tiếp cận tương tự trong blog trước của chúng tôi (trong MySQL), sử dụng các công cụ hệ thống như kết hợp ps, top, iostat, netstat. Ví dụ:bạn cũng có thể lấy phân đoạn WAL được khôi phục hiện tại từ nút chờ,
example@sqldat.com:/var/lib/postgresql/11/main# ps axufwww|egrep "postgre[s].*startup"
postgres 8065 0.0 8.3 715820 170872 ? Ss 01:41 0:03 \_ postgres: 11/main: startup recovering 000000030000000000000027ClusterControl có thể trợ giúp như thế nào?
ClusterControl cung cấp một cách hiệu quả để giám sát các nút cơ sở dữ liệu của bạn từ các nút chính đến các nút phụ. Khi chuyển đến tab Tổng quan, bạn đã có chế độ xem tình trạng sao chép của mình:
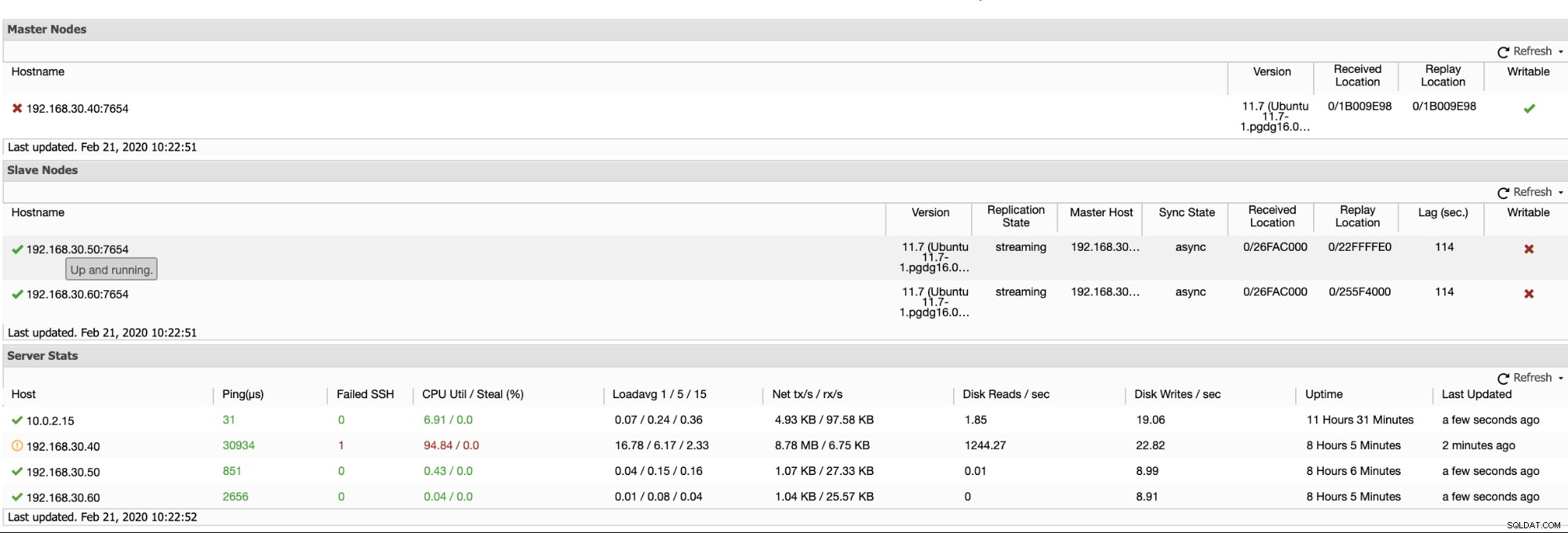
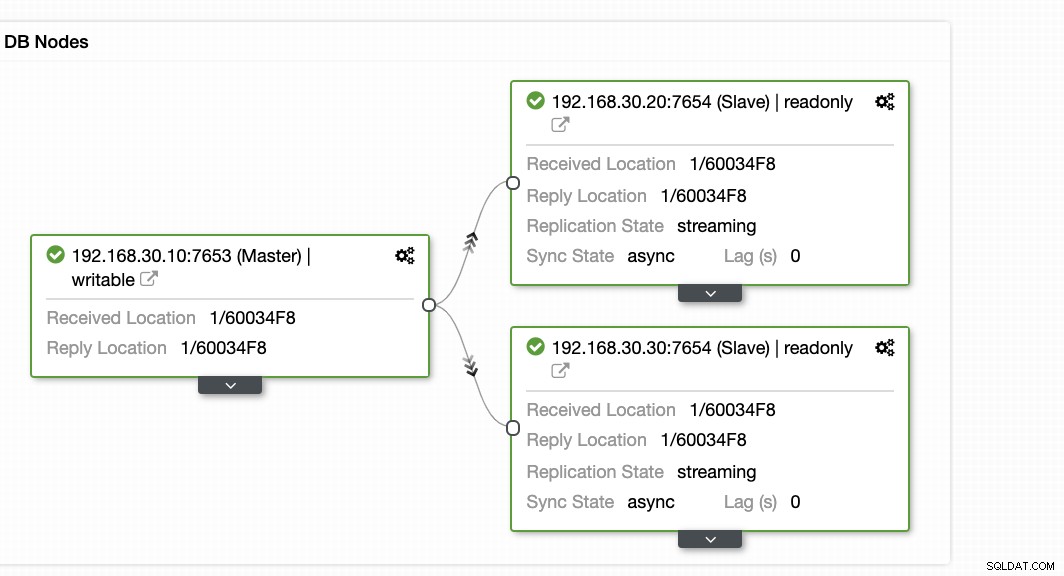
Về cơ bản, hai ảnh chụp màn hình ở trên hiển thị tình trạng sao chép và hiện tại như thế nào Các phân đoạn WAL. Điều đó hoàn toàn không phải. ClusterControl cũng hiển thị hoạt động hiện tại của những gì đang diễn ra với Cluster của bạn.
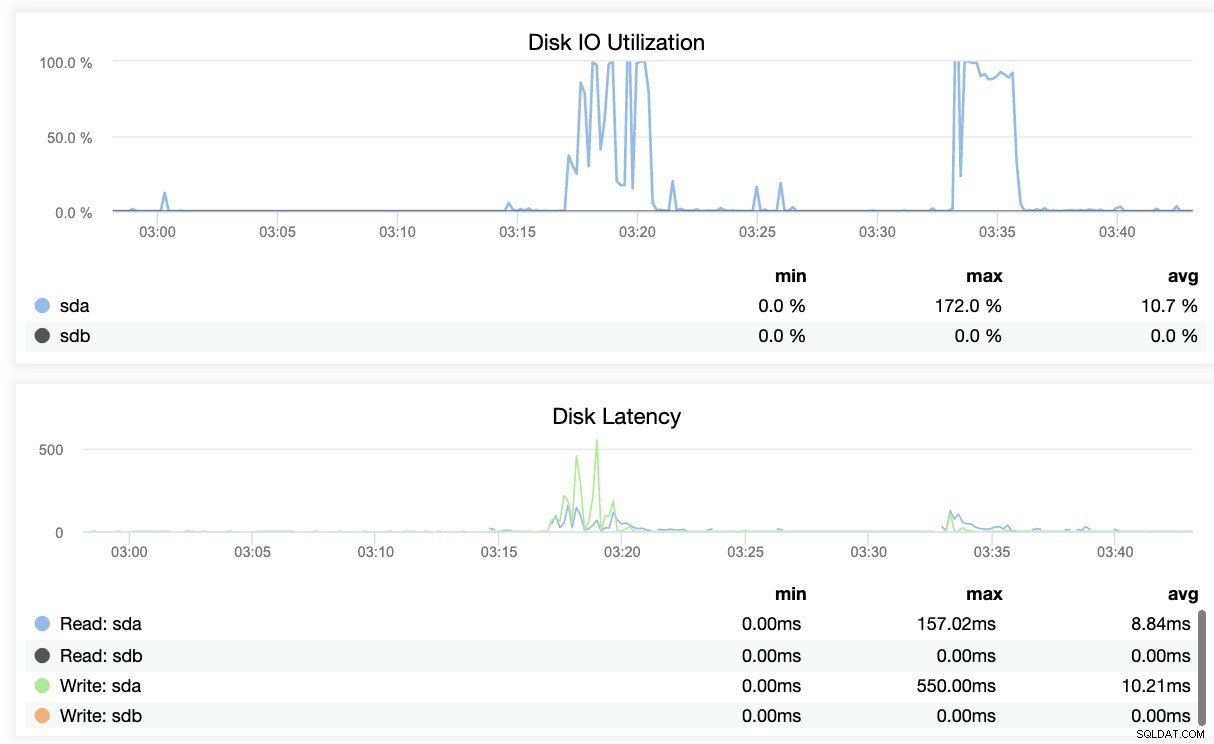
Kết luận
Theo dõi tình trạng sao chép trong PostgreSQL có thể kết thúc bằng một cách tiếp cận khác miễn là bạn có thể đáp ứng nhu cầu của mình. Sử dụng các công cụ của bên thứ ba với khả năng quan sát có thể thông báo cho bạn trong trường hợp thảm họa là lộ trình hoàn hảo của bạn, cho dù là nguồn mở hay doanh nghiệp. Điều quan trọng nhất là bạn có kế hoạch khắc phục thảm họa và tính liên tục kinh doanh của mình trước khi gặp sự cố như vậy.