Tính sẵn sàng cao là yêu cầu đối với nhiều hệ thống, bất kể bạn đang sử dụng công nghệ nào. Điều này đặc biệt quan trọng đối với cơ sở dữ liệu, vì chúng lưu trữ dữ liệu mà các ứng dụng dựa vào. Tùy thuộc vào yêu cầu, có những cách khác nhau để triển khai môi trường Tính sẵn sàng cao cho PostgreSQL, nhưng luôn cần sử dụng một công cụ bổ sung vì các tính năng gốc của PostgreSQL là không đủ.
Trong blog này, chúng ta sẽ xem cách triển khai Percona Distribution cho PostgreSQL để có Tính sẵn sàng cao và loại công cụ nào cần thiết để thực hiện.
Phân phối Percona cho PostgreSQL
Đây là một tập hợp các công cụ hỗ trợ bạn quản lý hệ thống cơ sở dữ liệu PostgreSQL của mình. Nó cài đặt PostgreSQL và bổ sung cho nó bằng một loạt các phần mở rộng cho phép giải quyết các tác vụ thực tế thiết yếu một cách hiệu quả, bao gồm:
- pg_repack :Nó xây dựng lại các đối tượng cơ sở dữ liệu PostgreSQL.
- pgaudit :Nó cung cấp ghi nhật ký kiểm tra phiên hoặc đối tượng chi tiết thông qua cơ sở ghi nhật ký PostgreSQL tiêu chuẩn.
- pgBackRest :Đây là giải pháp sao lưu và khôi phục cho PostgreSQL.
- Patroni :Đây là một giải pháp sẵn có cao cho PostgreSQL.
- pg_stat_monitor :Nó thu thập và tổng hợp số liệu thống kê cho PostgreSQL và cung cấp thông tin biểu đồ.
- Một bộ sưu tập các phần mở rộng bổ sung của PostgreSQL đóng góp.
Tính khả dụng cao trên PostgreSQL
Có nhiều kiến trúc khác nhau để PostgreSQL có tính khả dụng cao, nhưng phổ biến nhất là có cấu trúc liên kết Master-Slave (Primary-Standby). Nó dựa trên một cơ sở dữ liệu chính với một hoặc nhiều nút chờ. Các cơ sở dữ liệu dự phòng này sẽ vẫn được đồng bộ hóa (hoặc gần như đồng bộ) với cơ sở dữ liệu chính, tùy thuộc vào việc bản sao là đồng bộ hay không đồng bộ. Nếu máy chủ chính bị lỗi, chế độ chờ sẽ chứa gần như tất cả dữ liệu của máy chủ chính và có thể nhanh chóng được chuyển thành máy chủ cơ sở dữ liệu chính mới.
Tuy nhiên, thiết lập master-slave là không đủ để đảm bảo tính khả dụng cao một cách hiệu quả, vì bạn cũng cần phải xử lý các lỗi. Sau khi phát hiện lỗi, bạn có thể chọn một nút chờ và chuyển đổi dự phòng sang nút đó với độ trễ càng nhỏ càng tốt. Bản thân PostgreSQL không bao gồm cơ chế chuyển đổi dự phòng tự động, do đó, điều đó sẽ yêu cầu một số tập lệnh tùy chỉnh hoặc công cụ của bên thứ ba để tự động hóa này.
Sau khi chuyển đổi dự phòng xảy ra, (các) ứng dụng cần được thông báo tương ứng để chúng có thể bắt đầu sử dụng nút chính mới. Ngoài ra, bạn cần đánh giá trạng thái kiến trúc của chúng tôi sau khi chuyển đổi dự phòng, vì bạn có thể chạy trong tình huống mà bạn chỉ có nút chính mới đang chạy (tức là bạn có một nút chính và chỉ một nút chờ trước khi sự cố). Trong trường hợp đó, bạn sẽ cần phải thêm một nút chờ mới bằng cách nào đó để tạo lại thiết lập master-slave mà bạn đã có ban đầu cho Tính khả dụng cao.
Để nó hoạt động, bạn sẽ cần có các công cụ / dịch vụ khác nhau để giúp bạn thực hiện nhiệm vụ này.
Cân bằng tải
Bộ cân bằng tải là công cụ có thể được sử dụng để quản lý lưu lượng truy cập từ ứng dụng của bạn nhằm tận dụng tối đa kiến trúc cơ sở dữ liệu của bạn.
Nó không chỉ hữu ích cho việc cân bằng tải cơ sở dữ liệu của chúng tôi, nó còn giúp các ứng dụng được chuyển hướng đến các nút có sẵn / khỏe mạnh và thậm chí chỉ định các cổng với các vai trò khác nhau.
HAProxy là bộ cân bằng tải phân phối lưu lượng truy cập từ một điểm gốc đến một hoặc nhiều điểm đến và có thể xác định các quy tắc và / hoặc giao thức cụ thể cho tác vụ này. Nếu bất kỳ điểm đến nào ngừng phản hồi, nó được đánh dấu là ngoại tuyến và lưu lượng truy cập được gửi đến phần còn lại của các điểm đến khả dụng.
Keepalived là một dịch vụ cho phép bạn định cấu hình IP ảo trong một nhóm máy chủ hoạt động / thụ động. IP ảo này được gán cho một máy chủ đang hoạt động. Nếu máy chủ này bị lỗi, IP sẽ tự động được di chuyển sang máy chủ thụ động "Phụ", cho phép nó tiếp tục hoạt động với cùng một IP một cách minh bạch cho các hệ thống.
Để thực hiện tất cả những điều này, bạn có thể thực hiện theo cách thủ công, điều này có nghĩa là các tác vụ tốn thêm thời gian và công việc hoặc bạn có thể thực hiện chỉ từ một hệ thống bằng ClusterControl.
Hãy xem cách nhập Phân phối Percona hiện có của bạn cho PostgreSQL vào ClusterControl, sau đó cách định cấu hình môi trường Tính khả dụng cao bằng HAProxy và Keepalived xung quanh thiết lập này từ một giao diện thân thiện và dễ sử dụng.
Cấu trúc liên kết PostgreSQL để có tính khả dụng cao
Cấu trúc liên kết sẵn có cao cơ bản cho PostgreSQL có thể là:
- 3 máy chủ PostgreSQL 12 (một nút chính và hai nút dự phòng).
- 2 Bộ cân bằng tải HAProxy.
- Được định cấu hình duy trì giữa các máy chủ cân bằng tải.
- 1 máy chủ ClusterControl
Vì vậy, bạn sẽ có cấu trúc liên kết sau:
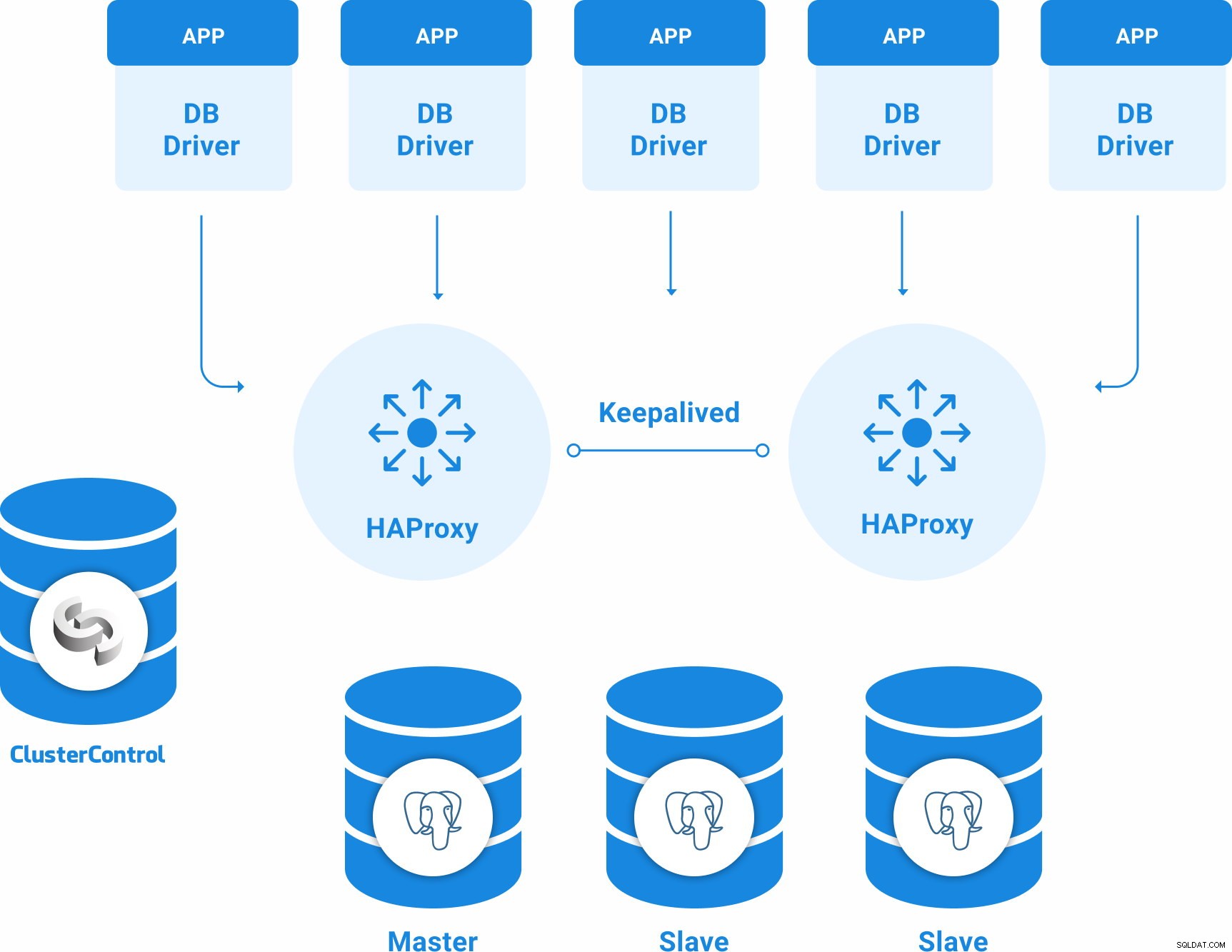
Cách cài đặt Percona Distribution cho PostgreSQL
Hãy bắt đầu bằng cách cài đặt Percona Distribution cho PostgreSQL. Đối với ví dụ này, chúng tôi sẽ sử dụng CentOS 7 và PostgreSQL 12.
Nếu bạn đã cài đặt cụm của mình, hãy chuyển đến phần tiếp theo để nhập cơ sở dữ liệu hiện có của bạn vào ClusterControl.
Cài đặt epel-release và percona-release
$ yum install epel-release
$ yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpmBật kho lưu trữ PostgreSQL 12
$ percona-release setup ppg-12
* Disabling all Percona Repositories
* Enabling the Percona Distribution for PostgreSQL 12 repository
<*> All done!Cài đặt gói máy chủ
$ yum install percona-postgresql12-serverLưu ý rằng gói này sẽ không cài đặt tất cả các thành phần Percona Distribution. Để cài đặt các thành phần này, hãy sử dụng các gói tùy chọn thích hợp như được hiển thị bên dưới:
$ yum install percona-pg_repack12
$ yum install percona-pgaudit
$ yum install percona-pgbackrest
$ yum install percona-patroni
$ yum install percona-pg-stat-monitor12
$ yum install percona-postgresql12-contribKhởi tạo Cơ sở dữ liệu
$ /usr/pgsql-12/bin/postgresql-12-setup initdb
Initializing database ... OKĐảm bảo rằng bạn có cấu hình chính xác để có thể định cấu hình bản sao PostgreSQL, tương tự như:
$ vi /var/lib/pgsql/12/data/postgresql.conf
listen_addresses = '*'
wal_level=logical
max_wal_senders = 16
wal_keep_segments = 32
hot_standby = onSau đó, khởi động dịch vụ cơ sở dữ liệu
$ systemctl start postgresql-12Bây giờ, nếu bạn muốn thêm các nút chờ, hãy lặp lại các bước 1, 2 và 3 trong tất cả các nút mà bạn muốn thêm vào cụm. Đối với những nút đó, bạn không cần phải định cấu hình bất kỳ thứ gì khác vì ClusterControl sẽ tạo cấu hình tương ứng.
Nhập Percona Distribution cho PostgreSQL trong ClusterControl
Với ClusterControl, bạn có thể triển khai hoặc nhập các công cụ cơ sở dữ liệu mã nguồn mở khác nhau từ cùng một hệ thống và chỉ có quyền truy cập SSH và người dùng đặc quyền mới được sử dụng.
Đi tới phần "Nhập" và điền đầy đủ thông tin bắt buộc của máy chủ PostgreSQL của bạn.
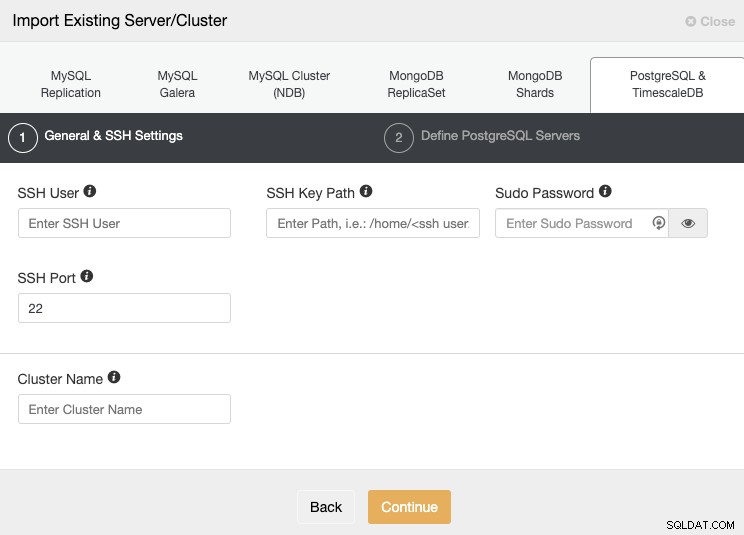
Bạn phải chỉ định Người dùng, Khóa hoặc Mật khẩu và cổng để kết nối bằng SSH đến máy chủ của bạn. Bạn cũng cần một tên cho cụm mới của mình, nếu không, ClusterControl sẽ chỉ định một tên chung cho bạn.
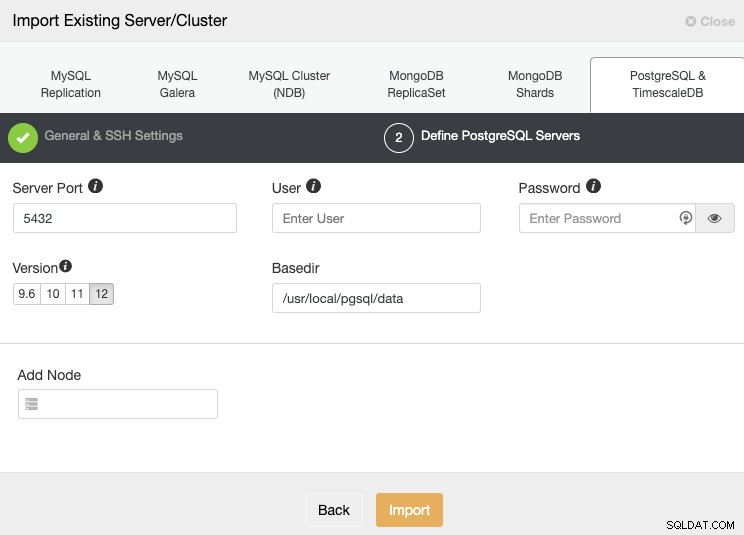
Sau khi thiết lập thông tin truy cập SSH, bạn phải xác định thông tin đăng nhập cơ sở dữ liệu, phiên bản, basedir và Địa chỉ IP hoặc Tên máy chủ cho mỗi nút cơ sở dữ liệu.
Nếu bạn chưa định cấu hình bản sao, bạn chỉ cần thêm địa chỉ IP hoặc Tên máy chủ cho nút chính vì chúng tôi sẽ hướng dẫn bạn cách thêm phần còn lại của các nút sau.
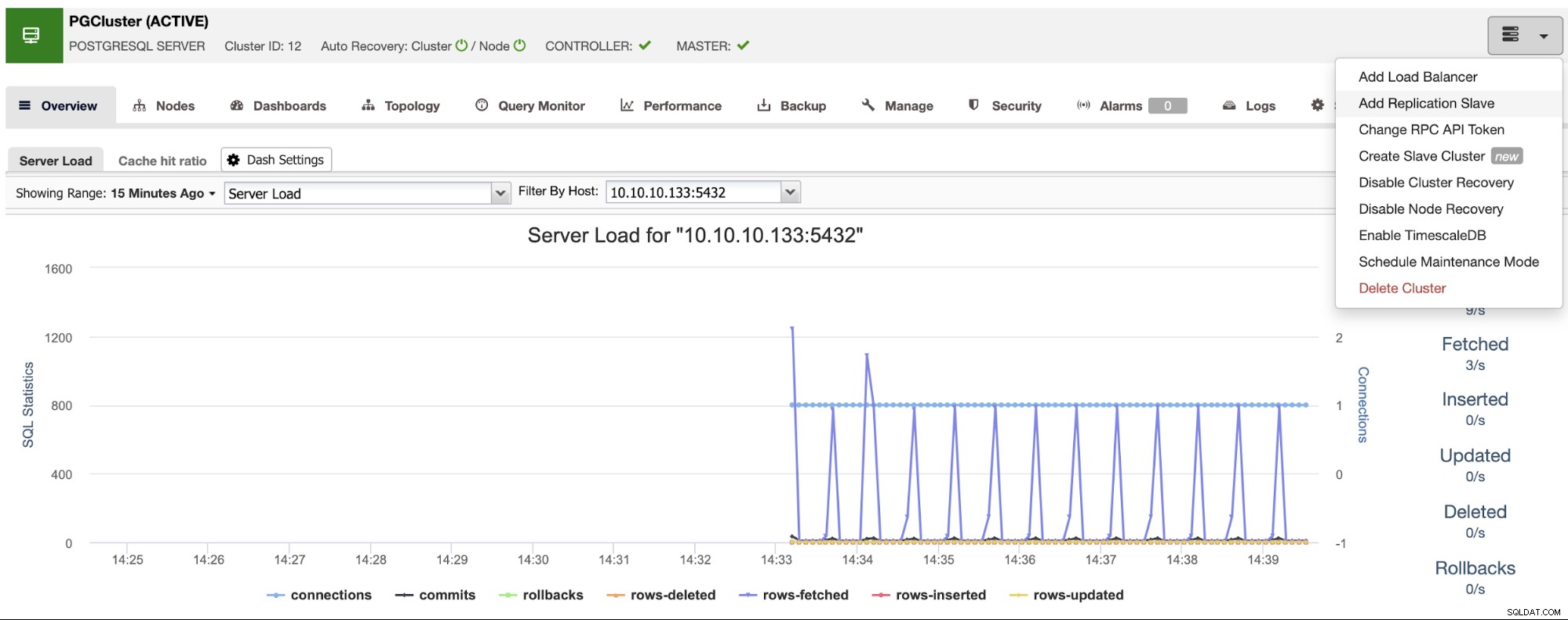
Đảm bảo bạn nhận được dấu tích màu xanh lục khi nhập tên máy chủ hoặc địa chỉ IP, cho biết ClusterControl có thể giao tiếp với nút. Sau đó, nhấp vào nút Nhập và đợi cho đến khi ClusterControl hoàn thành công việc của nó. Bạn có thể theo dõi quá trình trong Phần Hoạt động ClusterControl. Khi hoàn tất, bạn sẽ thấy cụm mới trên màn hình chính của ClusterControl. Để thêm một bản sao mới, hãy chuyển đến các hành động cụm và chọn tùy chọn “Thêm bản sao nhân bản”.
Nếu bạn làm theo các bước trước, bạn sẽ cài đặt Percona Distribution cho PostgreSQL trong tất cả các nút dự phòng, vì vậy bạn cần tắt “Cài đặt phần mềm PostgreSQL” trong phần này.
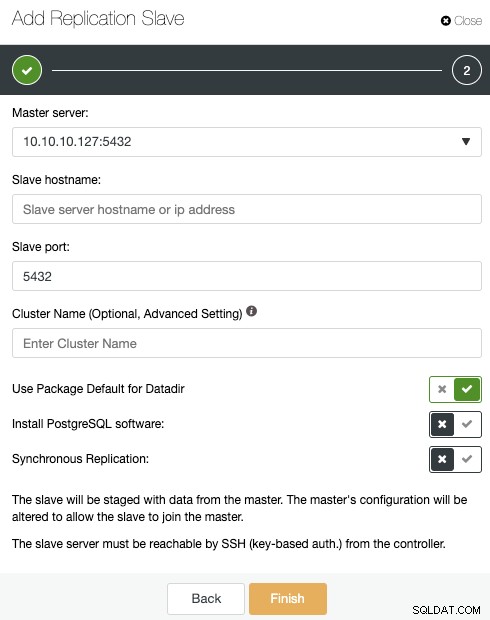
Theo cách này, ClusterControl sẽ sử dụng Percona Distribution đã cài đặt cho các gói PostgreSQL cài đặt các gói PostgreSQL chính thức.
Khi hoàn thành việc này, bạn sẽ thấy tất cả các nút trong cụm và trạng thái của tất cả chúng trong phần tổng quan.
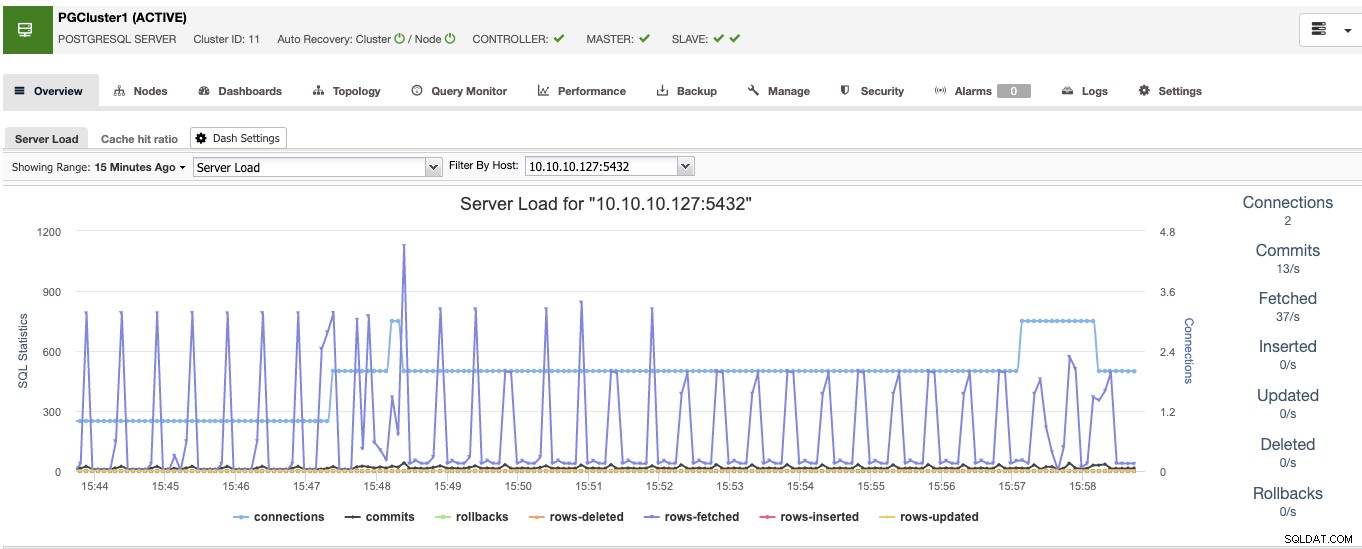
Bây giờ bạn đã sẵn sàng phía cơ sở dữ liệu, hãy xem cách hoàn thành Cao Môi trường khả dụng bằng cách thêm phần còn lại của các công cụ bằng ClusterControl.
Triển khai Load Balancer
Để triển khai bộ cân bằng tải, hãy chọn tùy chọn “Thêm bộ cân bằng tải” trong các tác vụ cụm và điền thông tin được hỏi. 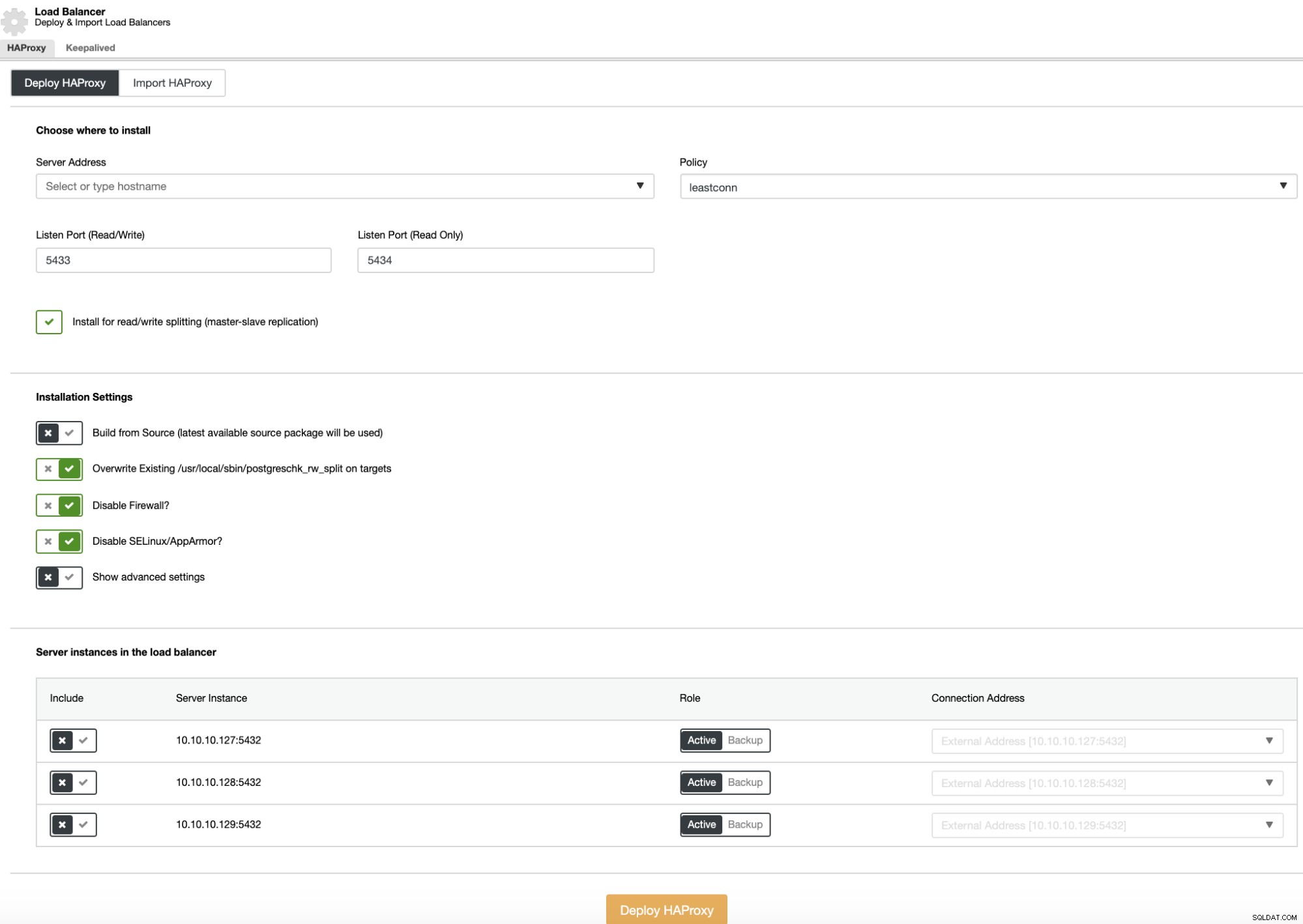
Bạn chỉ cần thêm Địa chỉ IP hoặc Tên máy chủ, cổng, chính sách và các nút bạn sẽ thêm vào cấu hình cân bằng tải.
Triển khai đủ điều kiện
Để thực hiện triển khai Keepalived, hãy chọn cụm, chuyển đến hành động của cụm, chọn “Thêm bộ cân bằng tải”, sau đó chuyển đến phần “Keepalived”.
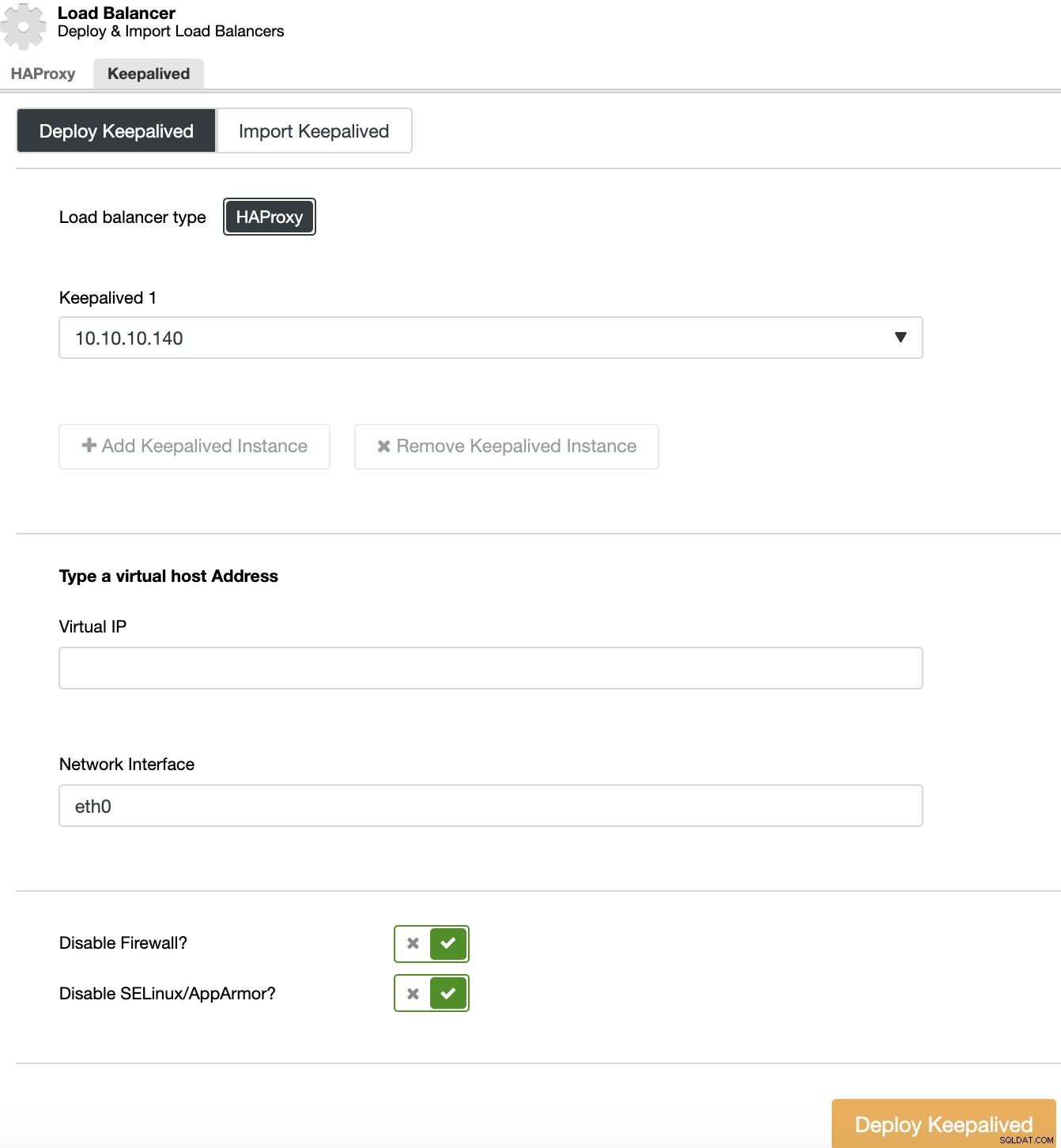
Đối với môi trường Tính sẵn sàng cao, bạn cần chọn máy chủ cân bằng tải và địa chỉ IP ảo mà bạn sẽ cần sử dụng để truy cập cụm của mình. Keepalived định cấu hình IP ảo này trong bộ cân bằng tải hoạt động và di chuyển nó từ bộ cân bằng tải này sang bộ cân bằng tải khác trong trường hợp bị lỗi, vì vậy thiết lập của bạn có thể tiếp tục hoạt động bình thường.
Kết luận
Vì bạn chưa thể triển khai Percona Distribution cho PostgreSQL trực tiếp từ ClusterControl, nên trong blog này, chúng tôi đã hướng dẫn bạn cách quản lý nó bằng ClusterControl và cách thêm các công cụ khác nhau như HAProxy và Keepalived để có môi trường Khả dụng cao tại chỗ một cách dễ dàng.