Hiệu suất cơ sở dữ liệu là một mối quan tâm rất quan trọng khi duy trì cụm cơ sở dữ liệu của bạn, đặc biệt là khi nó phát triển theo thời gian. Điều này đặc biệt đúng nếu ứng dụng của bạn bắt đầu với lưu lượng truy cập thấp, sau đó tăng dần đến khối lượng công việc đọc-ghi trung bình hoặc nặng.
Điều cần nhớ là không có cấu hình hoàn hảo nào mà bạn có thể dựa vào trong thời gian dài, vì một số khối lượng công việc nhất định có thể thay đổi theo thời gian.
Với ClusterControl, việc tạo hoặc triển khai một cụm cơ sở dữ liệu PostgreSQL mới sẽ thực hiện phân tích cơ bản như kiểm tra tài nguyên phần cứng của bạn, sau đó áp dụng tự động điều chỉnh và đặt giá trị cho các tham số có thể điều chỉnh được đã chọn. Khi PostgreSQL phát triển, rất nhiều công cụ cũng đã được phát triển để hỗ trợ các cấu hình khác nhau, đặc biệt là để cân bằng tải.
Trong blog này, chúng ta sẽ xem xét tầm quan trọng của HAProxy và cách nó có thể giúp thúc đẩy hiệu suất. Đó là một công cụ cũ nhưng là một proxy mạnh mẽ và / hoặc bộ cân bằng tải hỗ trợ không chỉ các máy chủ cơ sở dữ liệu mà còn hỗ trợ các giao thức dành riêng cho ứng dụng mạng. HAProxy có thể hoạt động tương ứng qua lớp bốn và lớp bảy, tùy thuộc vào kiểu thiết lập dựa trên cấu hình.
Điều chỉnh Hiệu suất PostgreSQL
Một trong những yếu tố chính để thúc đẩy hiệu suất cho PostgreSQL bắt đầu với việc điều chỉnh tham số cơ bản từ initdb đến các giá trị tham số thời gian chạy. Điều này phải có khả năng xử lý khối lượng công việc mong muốn phù hợp với các yêu cầu nhất định của bạn. Trước khi chúng tôi có thể thực hiện trên đường cho tính năng HAProxy cho PostgreSQL, máy chủ cơ sở dữ liệu của bạn phải ổn định và được điều chỉnh theo các biến mong muốn của nó. Hãy xem danh sách các khu vực của PostgreSQL về những thứ có thể ảnh hưởng đến hiệu suất hoạt động cho máy chủ cơ sở dữ liệu của bạn.
Điều chỉnh Quản lý Bộ nhớ Khả thi
PostgreSQL hiệu quả và có thể chạy hiệu quả với bộ nhớ ít nhất là 256Mb. Bộ nhớ không đắt, nhưng hầu hết các bộ dữ liệu đều nhỏ hơn 4Gib. Nếu bạn có ít nhất 4Gib thì tập dữ liệu đang hoạt động của bạn có thể vẫn còn trong tệp và / hoặc bộ đệm chia sẻ_bộ đệm.
Điều chỉnh PostgreSQL của bạn để quản lý bộ nhớ là một trong những điều chính và cơ bản nhất mà bạn cần thiết lập. Đặt nó một cách thích hợp có thể ảnh hưởng đến việc thúc đẩy hiệu suất của máy chủ cơ sở dữ liệu của bạn. Mặc dù nó phụ thuộc vào loại bàn bạn đang chơi. Truy vấn sai và định nghĩa bảng kém cũng có thể dẫn đến hiệu suất kém. Với các chỉ mục thích hợp được xác định cho các bảng của bạn và với các truy vấn tham chiếu đến các chỉ mục, cơ hội có thể đạt từ 80% - 100% các truy vấn có thể được truy xuất từ bộ nhớ của bạn. Điều này đặc biệt nếu bộ đệm chỉ mục có giá trị phù hợp để tải chỉ mục của bạn được xác định trên các bảng của bạn. Hãy xem xét các thông số thường được đặt để cải thiện hiệu suất.
- shared_buffers - PostgreSQL kích thước không gian bộ nhớ chính của nó với shared_buffers. Bộ nhớ đệm hoạt động của tất cả các bộ nóng (và các mục nhập chỉ mục) trong PostgreSQL. Tham số này đặt dung lượng bộ nhớ mà máy chủ cơ sở dữ liệu sử dụng cho bộ đệm bộ nhớ được chia sẻ. Đó là một bộ đệm (bộ đệm) được cấp phát trước. Đối với các hệ thống dựa trên Linux, lý tưởng nhất là đặt tham số hạt nhân kernel.shmmax có thể được đặt liên tục thông qua tệp cấu hình hạt nhân /etc/sysctl.conf.
- temp_buffers - Đặt số lượng bộ đệm tạm thời tối đa được sử dụng cho mỗi phiên. Đây là các bộ đệm phiên cục bộ chỉ được sử dụng để truy cập các bảng tạm thời. Một phiên sẽ chỉ định các bộ đệm tạm thời nếu cần đến giới hạn do bộ đệm tạm thời đưa ra.
- work_mem - Bộ nhớ làm việc có sẵn cho các hoạt động công việc (các loại) trước khi PostgreSQL sẽ hoán đổi. Không đặt toàn cục (postgresql.conf). Sử dụng cho mỗi giao dịch vì điều này có thể không tốt cho mỗi truy vấn, mỗi kết nối hoặc mỗi loại. Bạn nên sử dụng GIẢI THÍCH PHÂN TÍCH để xem bạn có bị tràn hay không.
- Maint_work_mem - Chỉ định dung lượng bộ nhớ sẽ được sử dụng cho các hoạt động bảo trì (VACUUM, CREATE INDEX và ALTER TABLE… THÊM TỪ KHÓA NGOẠI LỆ…)
Điều chỉnh để quản lý đĩa khả thi
Một số tham số thời gian chạy cần đặt ở đây. Hãy liệt kê những thứ này là gì:
- temp_file_limit - Chỉ định dung lượng ổ đĩa tối đa mà một phiên có thể sử dụng cho các tệp tạm thời, chẳng hạn như sắp xếp và băm các tệp tạm thời hoặc tệp lưu trữ cho một con trỏ được giữ. Giao dịch cố gắng vượt quá giới hạn này sẽ bị hủy.
- fsync - Nếu fsync được bật, PostgreSQL sẽ cố gắng đảm bảo rằng các bản cập nhật được ghi vật lý vào đĩa. Điều này đảm bảo rằng cụm cơ sở dữ liệu có thể được phục hồi về trạng thái nhất quán sau sự cố hệ điều hành hoặc phần cứng. Mặc dù vô hiệu hóa fsync thường cải thiện hiệu suất, nhưng nó có thể gây mất dữ liệu trong trường hợp mất điện hoặc sự cố hệ thống. Do đó, chỉ nên hủy kích hoạt fsync nếu bạn có thể dễ dàng tạo lại toàn bộ cơ sở dữ liệu của mình từ dữ liệu bên ngoài
- sync_commit - Được sử dụng để thực thi cam kết đó sẽ đợi WAL được ghi trên đĩa trước khi trả về trạng thái thành công cho máy khách. Biến này có sự cân bằng giữa hiệu suất và độ tin cậy. Nếu bạn cần thêm hiệu suất, hãy đặt cài đặt này thành tắt, có nghĩa là khi máy chủ gặp sự cố, có xu hướng mất dữ liệu. Ngược lại, nếu độ tin cậy là quan trọng, hãy đặt điều này thành bật. Điều này có nghĩa là sẽ có khoảng cách thời gian giữa trạng thái thành công và quá trình ghi được đảm bảo vào đĩa, do đó có thể ảnh hưởng đến hiệu suất.
- checkpoint_timeout, checkpoint_completion_target - PostgreSQL ghi các thay đổi vào WAL, đây là một hoạt động tốn kém. Nếu nó thường xuyên ghi các thay đổi vào WAL, nó có thể ảnh hưởng đến hiệu suất kém. Vì vậy, nó hoạt động như thế nào, quá trình điểm kiểm tra chuyển dữ liệu vào các tệp dữ liệu. Hoạt động này được thực hiện khi CHECKPOINT xảy ra và có thể gây ra một lượng lớn IO. Toàn bộ quá trình này liên quan đến các hoạt động đọc / ghi đĩa đắt tiền. Mặc dù bạn (người dùng quản trị) luôn có thể phát hành CHECKPOINT bất cứ khi nào có vẻ cần thiết hoặc tự động hóa nó bằng cách đặt các giá trị mong muốn cho các tham số này. Tham số checkpoint_timeout được sử dụng để đặt thời gian giữa các điểm kiểm tra WAL. Đặt quá thấp này làm giảm thời gian khôi phục sự cố, vì nhiều dữ liệu được ghi vào đĩa hơn, nhưng nó cũng ảnh hưởng đến hiệu suất vì mọi điểm kiểm tra đều tiêu tốn tài nguyên hệ thống có giá trị. Checkpoint_completion_target là phần thời gian giữa các điểm kiểm tra để hoàn thành điểm kiểm tra. Tần suất cao của các điểm kiểm tra có thể ảnh hưởng đến hiệu suất. Để kiểm tra suôn sẻ, checkpoint_timeout phải là một giá trị thấp. Nếu không, hệ điều hành sẽ tích tụ tất cả các trang bẩn cho đến khi đạt được tỷ lệ và sau đó xả sạch.
Điều chỉnh các Tham số Khác cho Hiệu suất
Có một số tham số nhất định giúp tăng cường và thúc đẩy hiệu suất trong PostgreSQL. Hãy liệt kê những điều này dưới đây:
- wal_buffers - PostgreSQL ghi bản ghi WAL (ghi nhật ký trước) của nó vào bộ đệm và sau đó các bộ đệm này được chuyển vào đĩa. Kích thước mặc định của bộ đệm, được xác định bởi wal_buffers, là 16MB, nhưng nếu bạn có nhiều kết nối đồng thời thì giá trị cao hơn có thể mang lại hiệu suất tốt hơn.
- effect_cache_size - Hiệu quả_cache_size cung cấp ước tính bộ nhớ có sẵn cho bộ nhớ đệm trên đĩa. Nó chỉ là một hướng dẫn, không phải là bộ nhớ được cấp phát chính xác hoặc kích thước bộ nhớ cache. Nó không cấp phát bộ nhớ thực nhưng cho trình tối ưu biết số lượng bộ nhớ đệm có sẵn trong hạt nhân. Nếu giá trị của giá trị này được đặt quá thấp, người lập kế hoạch truy vấn có thể quyết định không sử dụng một số chỉ mục, ngay cả khi chúng hữu ích. Do đó, đặt giá trị lớn luôn có lợi.
- default_stosystem_target - PostgreSQL thu thập số liệu thống kê từ mỗi bảng trong cơ sở dữ liệu của nó để quyết định cách các truy vấn sẽ được thực thi trên chúng. Theo mặc định, nó không thu thập quá nhiều thông tin và nếu bạn không có được kế hoạch thực thi tốt, bạn nên tăng giá trị này rồi chạy lại ANALYZE trong cơ sở dữ liệu (hoặc đợi AUTOVACUUM).
Hiệu quả Truy vấn PostgreSQL
PostgreSQL có một tính năng rất mạnh để tối ưu hóa các truy vấn. Với Trình tối ưu hóa Truy vấn Di truyền được tích hợp sẵn (được gọi là GEQO). Nó sử dụng một thuật toán di truyền là một phương pháp tối ưu hóa heuristic thông qua tìm kiếm ngẫu nhiên. Điều này được áp dụng khi thực hiện tối ưu hóa bằng cách sử dụng JOINs để tối ưu hóa hiệu suất rất tốt. Mỗi ứng cử viên trong kế hoạch tham gia được đại diện bởi một trình tự để tham gia các quan hệ cơ sở. Nó thực hiện ngẫu nhiên một mối quan hệ di truyền bằng cách đơn giản tạo ra một số trình tự liên kết có thể có nhưng là ngẫu nhiên.
Đối với mỗi chuỗi liên kết được xem xét, mã kế hoạch chuẩn được gọi để ước tính chi phí thực hiện truy vấn bằng cách sử dụng chuỗi liên kết đó. Vì vậy, đối với mỗi chuỗi JOIN, tất cả đều có các kế hoạch quét quan hệ được xác định ban đầu. Sau đó, kế hoạch truy vấn sẽ tính toán kế hoạch khả thi và hiệu quả nhất, tức là với chi phí ước tính thấp hơn và được coi là "phù hợp hơn" so với những kế hoạch có chi phí cao hơn.
Cho rằng nó có một tính năng mạnh mẽ được tích hợp trong PostgreSQL và các tham số được định cấu hình phù hợp theo yêu cầu mong muốn của bạn, nó không đánh bại tính khả thi khi nói đến hiệu suất nếu tải chỉ được chuyển đến một nút chính. Cân bằng tải với HAProxy giúp tăng hiệu suất ổ đĩa cho PostgreSQL.
Thúc đẩy hiệu suất cho PostgreSQL với tính năng phân tách đọc-ghi
Bạn có thể có hiệu suất tuyệt vời khi xử lý nút máy chủ PostgreSQL của mình nhưng bạn có thể không lường trước được loại khối lượng công việc mình có thể có, đặc biệt khi lưu lượng truy cập cao và nhu cầu vượt ra ngoài ranh giới. Việc cân bằng tải giữa chính và phụ giúp tăng hiệu suất trong ứng dụng của bạn và / hoặc các ứng dụng khách kết nối với cụm cơ sở dữ liệu PostgreSQL của bạn. Làm thế nào điều này có thể được thực hiện, không phải là một câu hỏi nữa vì đây là một thiết lập rất phổ biến cho tính khả dụng và dự phòng cao khi nói đến việc phân phối tải và tránh nút chính bị sa lầy do xử lý tải cao.
Thiết lập với HAProxy rất dễ dàng. Tuy nhiên, nó nhanh hơn và khả thi hơn với ClusterControl. Vì vậy, chúng tôi sẽ sử dụng ClusterControl để thiết lập điều này cho chúng tôi.
Thiết lập PostgreSQL với HAProxy
Để thực hiện việc này, chúng ta sẽ chỉ cần cài đặt và thiết lập HAProxy trên đầu các cụm PostgreSQL. HAProxy có một tính năng hỗ trợ PostgreSQL thông qua tùy chọn pgsql-check nhưng hỗ trợ của nó là một triển khai rất đơn giản để xác định xem một nút có được thiết lập hay không. Nó không có kiểm tra để xác định một nút chính và một nút khôi phục. Một tùy chọn là sử dụng xinetd mà chúng tôi sẽ dựa vào việc giao tiếp HAProxy để lắng nghe thông qua dịch vụ xinetd của chúng tôi để kiểm tra tình trạng của một nút cụ thể trong cụm PostgreSQL của chúng tôi.
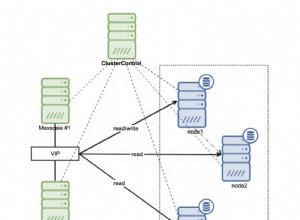
Trong ClusterControl, điều hướng đến Quản lý → Cân bằng tải như bên dưới,

Sau đó, chỉ cần theo dõi dựa trên giao diện người dùng trên ảnh chụp màn hình bên dưới. Bạn có thể nhấp vào Hiển thị cài đặt nâng cao để xem các tùy chọn nâng cao hơn. Tuy nhiên, việc tuân theo giao diện người dùng rất đơn giản. Xem bên dưới,

Tôi chỉ nhập HAProxy nút đơn không dự phòng nhưng với mục đích blog này, hãy làm cho nó đơn giản hơn.
Chế độ xem HAProxy mẫu của tôi được hiển thị bên dưới,

Như được hiển thị ở trên, 192.168.30.20 và 192.168.30.30 là chính và các nút thứ cấp / phục hồi tương ứng. Trong khi HAProxy được cài đặt trong nút phụ / khôi phục. Lý tưởng nhất là bạn có thể cài đặt HAProxy của mình trên nhiều nút để có nhiều dự phòng hơn và có tính khả dụng cao, cách tốt nhất là cô lập nó với các nút cơ sở dữ liệu. Nếu bạn eo hẹp về ngân sách hoặc tiết kiệm chi phí sử dụng, bạn có thể chọn cài đặt các nút HAProxy, nơi các nút cơ sở dữ liệu của bạn cũng được cài đặt.
ClusterControl thiết lập điều này tự động và cũng bao gồm dịch vụ xinetd để kiểm tra PostgreSQL. Điều này có thể được xác minh bằng netstat như bên dưới,
example@sqldat.com:~# netstat -tlv4np|grep haproxy
tcp 0 0 0.0.0.0:5433 0.0.0.0:* LISTEN 28441/haproxy
tcp 0 0 0.0.0.0:5434 0.0.0.0:* LISTEN 28441/haproxy
tcp 0 0 0.0.0.0:9600 0.0.0.0:* LISTEN 28441/haproxyTrong khi cổng 5433 là đọc-ghi và 5444 là chỉ đọc.
Đối với PostgreSQL, hãy kiểm tra dịch vụ xinetd cụ thể là postgreshk như bên dưới,
example@sqldat.com:~# cat /etc/xinetd.d/postgreschk
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITED
}
Các dịch vụ xinetd cũng dựa vào / etc / services để bạn có thể tìm thấy cổng được chỉ định để lập bản đồ.
example@sqldat.com:~# grep postgreschk /etc/services
postgreschk 9201/tcpNếu bạn cần thay đổi cổng postgreschk của mình thành cổng để ánh xạ, bạn phải thay đổi tệp này ngoài tệp cấu hình dịch vụ và sau đó đừng quên khởi động lại daemon xinetd.
Dịch vụ postgreschk chứa tham chiếu đến một tệp bên ngoài, về cơ bản nó sẽ kiểm tra các nút nếu nó có thể ghi được, nghĩa là nó là tệp chính hoặc tệp chính. Nếu một nút đang được khôi phục, thì đó là một bản sao hoặc một nút khôi phục.
example@sqldat.com:~# cat /usr/local/sbin/postgreschk
#!/bin/bash
#
# This script checks if a PostgreSQL server is healthy running on localhost. It will
# return:
# "HTTP/1.x 200 OK\r" (if postgres is running smoothly)
# - OR -
# "HTTP/1.x 500 Internal Server Error\r" (else)
#
# The purpose of this script is make haproxy capable of monitoring PostgreSQL properly
#
export PGHOST='localhost'
export PGUSER='s9smysqlchk'
export PGPASSWORD='password'
export PGPORT='7653'
export PGDATABASE='postgres'
export PGCONNECT_TIMEOUT=10
FORCE_FAIL="/dev/shm/proxyoff"
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"
return_ok()
{
echo -e "HTTP/1.1 200 OK\r\n"
echo -e "Content-Type: text/html\r\n"
if [ "$1x" == "masterx" ]; then
echo -e "Content-Length: 56\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL master is running.</body></html>\r\n"
elif [ "$1x" == "slavex" ]; then
echo -e "Content-Length: 55\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL slave is running.</body></html>\r\n"
else
echo -e "Content-Length: 49\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is running.</body></html>\r\n"
fi
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 0
}
return_fail()
{
echo -e "HTTP/1.1 503 Service Unavailable\r\n"
echo -e "Content-Type: text/html\r\n"
echo -e "Content-Length: 48\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is *down*.</body></html>\r\n"
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 1
}
if [ -f "$FORCE_FAIL" ]; then
return_fail;
fi
# check if in recovery mode (that means it is a 'slave')
SLAVE=$(psql -qt -c "$SLAVE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $SLAVE | egrep -i "(t|true|on|1)" 2>/dev/null >/dev/null; then
return_ok "slave"
fi
# check if writable (then we consider it as a 'master')
READONLY=$(psql -qt -c "$WRITABLE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $READONLY | egrep -i "(f|false|off|0)" 2>/dev/null >/dev/null; then
return_ok "master"
fi
return_ok "none";Tổ hợp người dùng / mật khẩu phải là VAI TRÒ hợp lệ trong máy chủ PostgreSQL của bạn. Vì chúng tôi đang cài đặt thông qua ClusterControl, điều này được xử lý tự động.
Bây giờ chúng tôi đã cài đặt HAProxy hoàn chỉnh, thiết lập này cho phép chúng tôi có một phân tách đọc-ghi trong đó đọc-ghi chuyển đến nút chính hoặc nút có thể ghi, trong khi chỉ đọc cho cả chính và phụ / các nút phục hồi. Thiết lập này không có nghĩa là nó đã hoạt động tốt, nó vẫn được điều chỉnh như đã thảo luận trước đó với sự kết hợp của HAProxy để cân bằng tải giúp tăng thêm hiệu suất cho ứng dụng của bạn và các máy khách cơ sở dữ liệu tương ứng.