Trong thế giới công nghệ thông tin, tự động hóa không phải là điều mới mẻ đối với hầu hết chúng ta. Trên thực tế, hầu hết các tổ chức đang sử dụng nó cho các mục đích khác nhau tùy thuộc vào loại công việc và mục tiêu của họ. Ví dụ:các nhà phân tích dữ liệu sử dụng tự động hóa để tạo báo cáo, quản trị viên hệ thống sử dụng tự động hóa cho các tác vụ lặp đi lặp lại của họ như dọn dẹp dung lượng đĩa và các nhà phát triển sử dụng tự động hóa để tự động hóa quy trình phát triển của họ.
Ngày nay, có rất nhiều công cụ tự động hóa dành cho CNTT và có thể được lựa chọn nhờ vào kỷ nguyên DevOps. Công cụ nào là tốt nhất? Câu trả lời là "điều đó phụ thuộc" có thể dự đoán được, vì nó phụ thuộc vào những gì chúng ta đang cố gắng đạt được cũng như thiết lập môi trường của chúng ta. Một số công cụ tự động hóa là Terraform, Bolt, Chef, SaltStack và một công cụ rất hợp thời trang là Ansible. Ansible là một công cụ CNTT không tác nhân mã nguồn mở có thể tự động hóa việc triển khai ứng dụng, quản lý cấu hình và điều phối CNTT. Ansible được thành lập vào năm 2012 và được viết bằng ngôn ngữ phổ biến nhất, Python. Nó sử dụng một playbook để triển khai tất cả quá trình tự động hóa, trong đó tất cả các cấu hình đều được viết bằng ngôn ngữ mà con người có thể đọc được, YAML.
Trong bài đăng hôm nay, chúng ta sẽ tìm hiểu cách sử dụng Ansible để triển khai cơ sở dữ liệu Postgresql.
Điều gì khiến Ansible Đặc biệt?
Lý do tại sao ansible được sử dụng chủ yếu là do các tính năng của nó. Các tính năng đó là:
-
Mọi thứ đều có thể được tự động hóa bằng cách sử dụng ngôn ngữ đơn giản mà con người có thể đọc được YAML
-
Không có tác nhân nào sẽ được cài đặt trên máy từ xa (kiến trúc không có tác nhân)
-
Cấu hình sẽ được đẩy từ máy cục bộ của bạn đến máy chủ từ máy cục bộ của bạn (mô hình đẩy)
-
Được phát triển bằng Python (một trong những ngôn ngữ phổ biến được sử dụng hiện nay) và rất nhiều thư viện có thể được chọn từ
-
Bộ sưu tập các mô-đun Ansible được lựa chọn cẩn thận bởi Nhóm Kỹ thuật Red Had
Con đường Ansible hoạt động
Trước khi Ansible có thể chạy bất kỳ tác vụ hoạt động nào đối với các máy chủ từ xa, chúng ta cần cài đặt nó vào một máy chủ sẽ trở thành nút điều khiển. Trong nút điều khiển này, chúng tôi sẽ sắp xếp bất kỳ tác vụ nào mà chúng tôi muốn thực hiện vào các máy chủ từ xa còn được gọi là các nút được quản lý.
Nút điều khiển phải có bản kiểm kê của các nút được quản lý và phần mềm Ansible để quản lý nó. Dữ liệu bắt buộc được Ansible sử dụng như tên máy chủ hoặc địa chỉ IP của nút được quản lý sẽ được đặt bên trong khoảng không quảng cáo này. Nếu không có hàng tồn kho thích hợp, Ansible không thể thực hiện tự động hóa một cách chính xác. Xem tại đây để tìm hiểu thêm về khoảng không quảng cáo.
Ansible là không có tác nhân và sử dụng SSH để đẩy các thay đổi, có nghĩa là chúng tôi không phải cài đặt Ansible trong tất cả các nút, nhưng tất cả các nút được quản lý phải cài đặt python và mọi thư viện python cần thiết. Cả nút bộ điều khiển và các nút được quản lý phải được đặt là không có mật khẩu. Điều đáng nói là kết nối giữa tất cả các nút bộ điều khiển và các nút được quản lý đều tốt và được kiểm tra đúng cách.
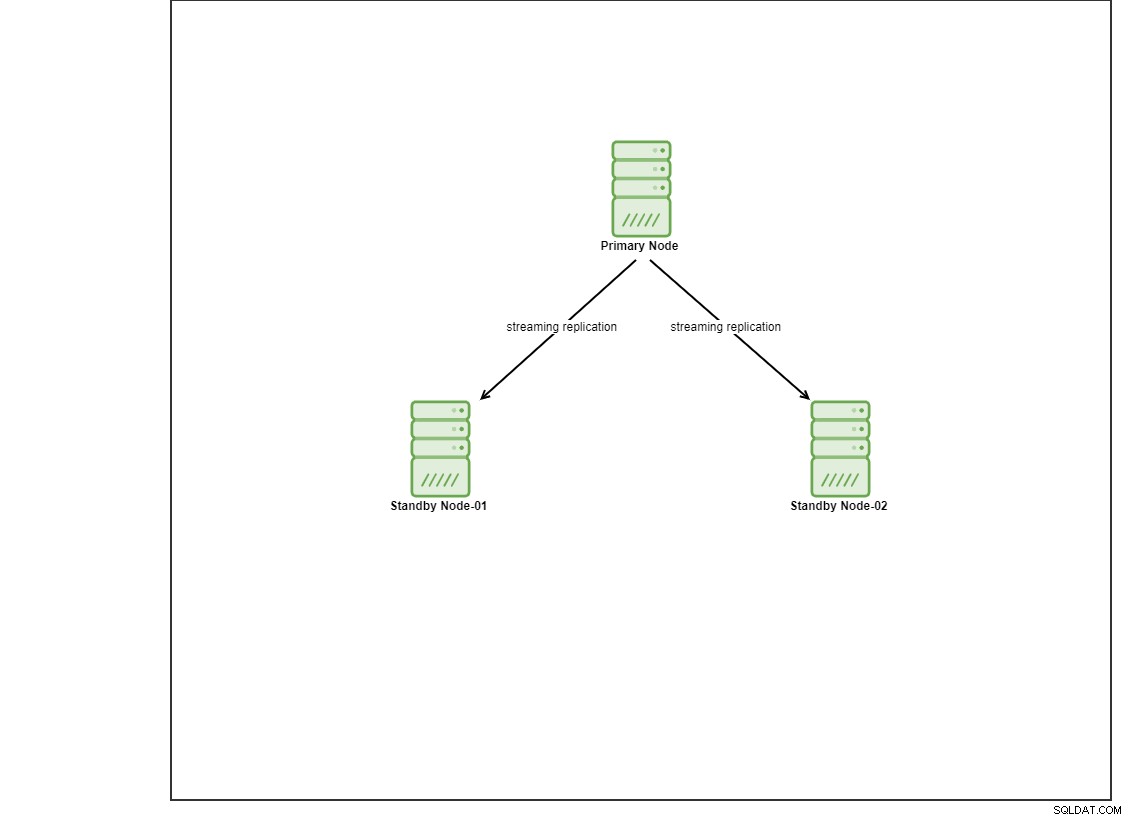
Đối với bản demo này, tôi đã cung cấp 4 máy ảo Centos 8 bằng cách sử dụng vagrant. Một sẽ hoạt động như một nút điều khiển và 2 máy ảo khác sẽ hoạt động như các nút cơ sở dữ liệu được triển khai. Chúng tôi không đi vào chi tiết về cách cài đặt Ansible trong bài đăng trên blog này nhưng trong trường hợp bạn muốn xem hướng dẫn, vui lòng truy cập liên kết này. Lưu ý rằng chúng tôi đang sử dụng 3 nút để thiết lập cấu trúc liên kết sao chép trực tuyến, với một nút chính và 2 nút dự phòng. Ngày nay, nhiều cơ sở dữ liệu sản xuất đang ở trong tình trạng thiết lập tính sẵn sàng cao và thiết lập 3 nút là một cách phổ biến.
Cài đặt PostgreSQL
Có một số cách để cài đặt PostgreSQL bằng cách sử dụng Ansible. Hôm nay, tôi sẽ sử dụng Ansible Roles để đạt được mục đích này. Tóm lại, Ansible Roles là một tập hợp các tác vụ để cấu hình một máy chủ để phục vụ một mục đích nhất định như cấu hình một dịch vụ. Vai trò Ansible được xác định bằng cách sử dụng các tệp YAML với cấu trúc thư mục được xác định trước có sẵn để tải xuống từ cổng Ansible Galaxy.
Mặt khác,Ansible Galaxy là một kho lưu trữ cho các Vai trò Ansible có sẵn để đưa trực tiếp vào Playbook của bạn nhằm hợp lý hóa các dự án tự động hóa của bạn.
Đối với bản demo này, tôi đã chọn các vai trò do dudefellah đảm nhiệm. Để chúng tôi sử dụng vai trò này, chúng tôi cần tải xuống và cài đặt nó vào nút điều khiển. Nhiệm vụ này khá đơn giản và có thể được thực hiện bằng cách chạy lệnh sau với điều kiện là Ansible đã được cài đặt trên nút điều khiển của bạn:
$ ansible-galaxy install dudefellah.postgresqlBạn sẽ thấy kết quả sau khi vai trò được cài đặt thành công trong nút điều khiển của bạn:
$ ansible-galaxy install dudefellah.postgresql
- downloading role 'postgresql', owned by dudefellah
- downloading role from https://github.com/dudefellah/ansible-role-postgresql/archive/0.1.0.tar.gz
- extracting dudefellah.postgresql to /home/ansible/.ansible/roles/dudefellah.postgresql
- dudefellah.postgresql (0.1.0) was installed successfully
Để chúng tôi cài đặt PostgreSQL bằng vai trò này, cần thực hiện một số bước. Đây là Ansible Playbook. Ansible Playbook là nơi chúng ta có thể viết mã Ansible hoặc tập hợp các tập lệnh mà chúng ta muốn chạy trên các nút được quản lý. Ansible Playbook sử dụng YAML và bao gồm một hoặc nhiều lượt chơi chạy theo một thứ tự cụ thể. Bạn có thể xác định các máy chủ cũng như một tập hợp các tác vụ mà bạn muốn chạy trên các máy chủ được chỉ định hoặc các nút được quản lý đó.
Tất cả các tác vụ sẽ được thực thi với tư cách người dùng không thể truy cập đã đăng nhập. Để chúng tôi thực thi các tác vụ với một người dùng khác bao gồm cả ‘root’, chúng tôi có thể sử dụng trở thành. Hãy xem pg-play.yml bên dưới:
$ cat pg-play.yml
- hosts: pgcluster
become: yes
vars_files:
- ./custom_var.yml
roles:
- role: dudefellah.postgresql
postgresql_version: 13Như bạn thấy, tôi đã định nghĩa các máy chủ là pgcluster và sử dụng trở thành để Ansible chạy các tác vụ với đặc quyền sudo. Người dùng lang thang đã thuộc nhóm sudoer. Tôi cũng đã xác định vai trò mà tôi đã cài đặt dudefellah.postgresql. pgcluster đã được xác định trong tệp máy chủ lưu trữ mà tôi đã tạo. Trong trường hợp bạn thắc mắc nó trông như thế nào, bạn có thể xem bên dưới:
$ cat pghost
[pgcluster]
10.10.10.11 ansible_user=ansible
10.10.10.12 ansible_user=ansible
10.10.10.13 ansible_user=ansibleNgoài ra, tôi đã tạo một tệp tùy chỉnh khác (custom_var.yml) trong đó tôi bao gồm tất cả cấu hình và cài đặt cho PostgreSQL mà tôi muốn triển khai. Chi tiết cho tệp tùy chỉnh như sau:
$ cat custom_var.yml
postgresql_conf:
listen_addresses: "*"
wal_level: replica
max_wal_senders: 10
max_replication_slots: 10
hot_standby: on
postgresql_users:
- name: replication
password: example@sqldat.com
privs: "ALL"
role_attr_flags: "SUPERUSER,REPLICATION"
postgresql_pg_hba_conf:
- { type: "local", database: "all", user: "all", method: "trust" }
- { type: "host", database: "all", user: "all", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "127.0.0.1/32", method: "md5" }Để chạy cài đặt, tất cả những gì chúng ta phải làm là thực hiện lệnh sau. Bạn sẽ không thể chạy lệnh ansible-playbook mà không tạo tệp playbook (trong trường hợp của tôi là pg-play.yml).
$ ansible-playbook pg-play.yml -i pghostSau khi tôi thực hiện lệnh này, nó sẽ chạy một vài tác vụ được xác định bởi vai trò và sẽ hiển thị thông báo này nếu lệnh chạy thành công:
PLAY [pgcluster] *************************************************************************************
TASK [Gathering Facts] *******************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Load platform variables] ***********************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Set up role-specific facts based on some inputs and the OS distribution] ***
included: /home/ansible/.ansible/roles/dudefellah.postgresql/tasks/role_facts.yml for 10.10.10.11, 10.10.10.12Sau khi ansible hoàn thành các tác vụ, tôi đăng nhập vào nô lệ (n2), dừng dịch vụ PostgreSQL, xóa nội dung của thư mục dữ liệu (/ var / lib / pgsql / 13 / data /) và chạy lệnh sau để bắt đầu tác vụ sao lưu:
$ sudo -u postgres pg_basebackup -h 10.10.10.11 -D /var/lib/pgsql/13/data/ -U replication -P -v -R -X stream -C -S slaveslot1
10.10.10.11 is the IP address of the master. We can now verify the replication slot by logging into the master:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_replication_slots;
-[ RECORD 1 ]-------+-----------
slot_name | slaveslot1
plugin |
slot_type | physical
datoid |
database |
temporary | f
active | t
active_pid | 63854
xmin |
catalog_xmin |
restart_lsn | 0/3000148
confirmed_flush_lsn |
wal_status | reserved
safe_wal_size |Chúng tôi cũng có thể kiểm tra trạng thái của bản sao ở chế độ chờ bằng cách sử dụng lệnh sau sau khi chúng tôi bắt đầu lại dịch vụ PostgreSQL:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_stat_wal_receiver;
-[ RECORD 1 ]---------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
pid | 229552
status | streaming
receive_start_lsn | 0/3000000
receive_start_tli | 1
written_lsn | 0/3000148
flushed_lsn | 0/3000148
received_tli | 1
last_msg_send_time | 2021-05-09 14:10:00.29382+00
last_msg_receipt_time | 2021-05-09 14:09:59.954983+00
latest_end_lsn | 0/3000148
latest_end_time | 2021-05-09 13:53:28.209279+00
slot_name | slaveslot1
sender_host | 10.10.10.11
sender_port | 5432
conninfo | user=replication password=******** channel_binding=prefer dbname=replication host=10.10.10.11 port=5432 fallback_application_name=walreceiver sslmode=prefer sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=prefer krbsrvname=postgres target_session_attrs=anyNhư bạn thấy, có rất nhiều công việc cần phải được thực hiện để chúng tôi thiết lập bản sao cho PostgreSQL mặc dù chúng tôi đã tự động hóa một số tác vụ. Hãy xem cách này có thể được thực hiện với ClusterControl.
Triển khai PostgreSQL bằng ClusterControl GUI
Bây giờ chúng ta đã biết cách triển khai PostgreSQL bằng cách sử dụng Ansible, hãy xem cách chúng ta có thể triển khai bằng cách sử dụng ClusterControl. ClusterControl là một phần mềm quản lý và tự động hóa cho các cụm cơ sở dữ liệu bao gồm MySQL, MariaDB, MongoDB cũng như TimescaleDB. Nó giúp triển khai, giám sát, quản lý và mở rộng cụm cơ sở dữ liệu của bạn. Có hai cách triển khai cơ sở dữ liệu, trong bài đăng trên blog này, chúng tôi sẽ chỉ cho bạn cách triển khai nó bằng giao diện người dùng đồ họa (GUI) giả sử rằng bạn đã cài đặt ClusterControl trên môi trường của mình.
Bước đầu tiên là đăng nhập vào ClusterControl của bạn và nhấp vào Triển khai:
Bạn sẽ thấy ảnh chụp màn hình bên dưới cho bước triển khai tiếp theo , chọn tab PostgreSQL để tiếp tục:
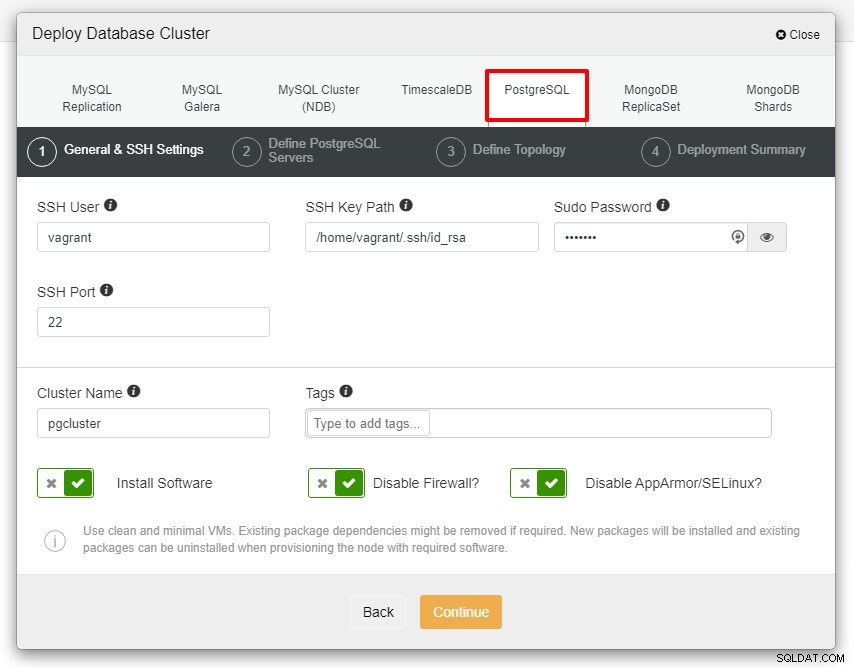
Trước khi chúng ta tiến xa hơn, tôi muốn nhắc bạn rằng kết nối giữa nút ClusterControl và các nút cơ sở dữ liệu phải không có mật khẩu. Trước khi triển khai, tất cả những gì chúng ta cần làm là tạo ssh-keygen từ nút ClusterControl và sau đó sao chép nó vào tất cả các nút. Điền thông tin đầu vào cho Người dùng SSH, Mật khẩu Sudo cũng như Tên cụm theo yêu cầu của bạn và nhấp vào Tiếp tục.
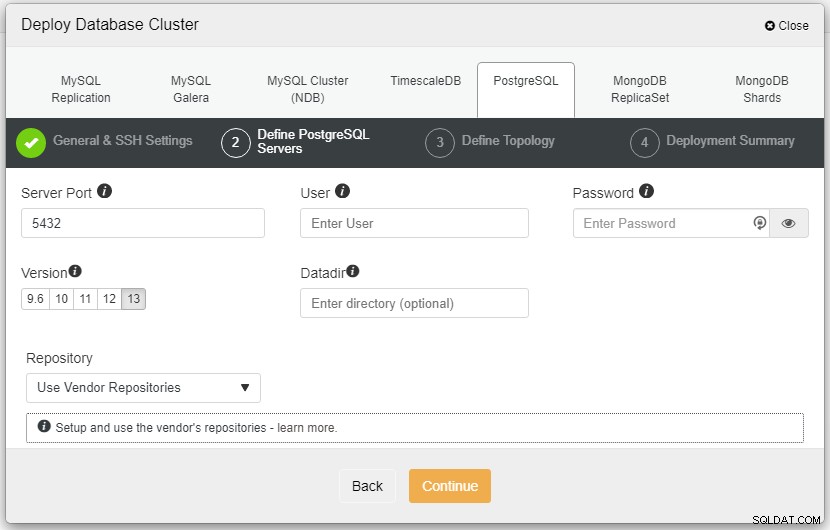
Trong ảnh chụp màn hình ở trên, bạn sẽ cần xác định Cổng máy chủ (trong trường hợp bạn muốn sử dụng người khác), người dùng mà bạn muốn cũng như mật khẩu và Phiên bản bạn muốn để cài đặt.
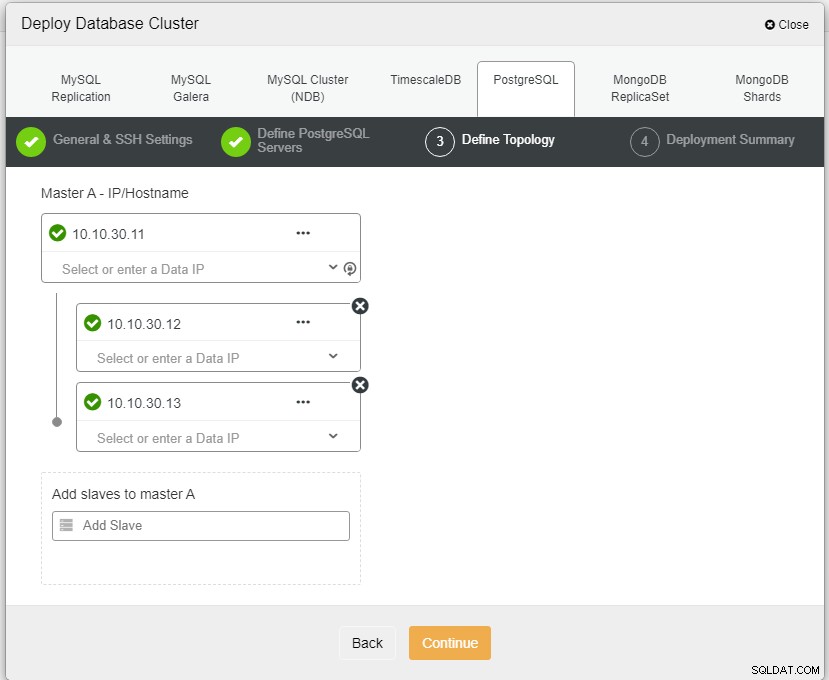
Ở đây chúng ta cần xác định các máy chủ sử dụng tên máy chủ hoặc địa chỉ IP, như trong trường hợp này là 1 máy chủ và 2 máy chủ. Bước cuối cùng là chọn chế độ sao chép cho cụm của chúng tôi.
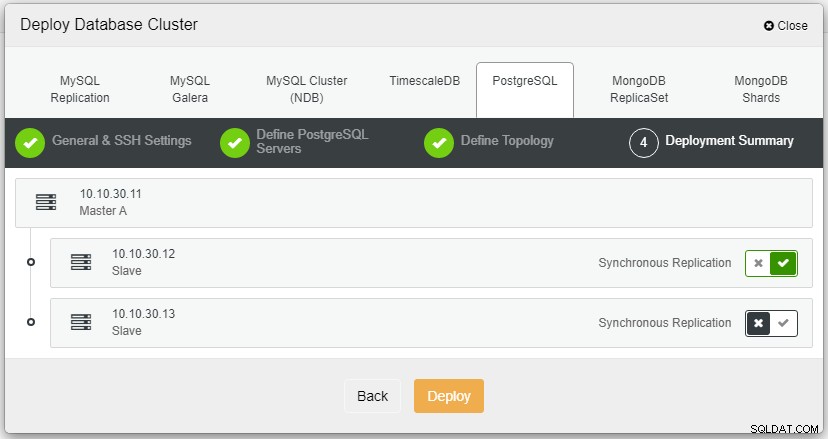
Sau khi bạn nhấp vào Triển khai, quá trình triển khai sẽ bắt đầu và chúng tôi có thể theo dõi tiến trình trong tab Hoạt động.
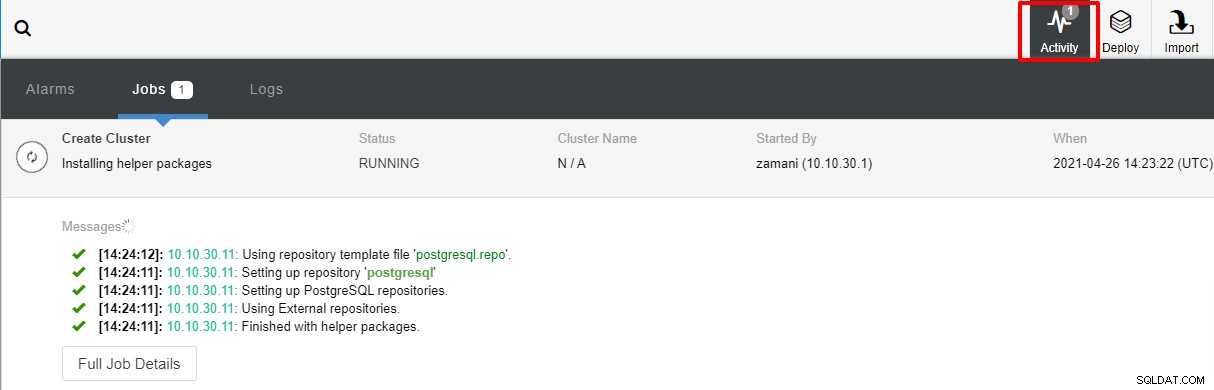
Quá trình triển khai thường sẽ mất vài phút, hiệu suất phụ thuộc chủ yếu vào mạng và thông số kỹ thuật của máy chủ.

Bây giờ chúng ta đã cài đặt PostgreSQL bằng ClusterControl.
Triển khai PostgreSQL bằng ClusterControl CLI
Cách khác để triển khai PostgreSQL là sử dụng CLI. miễn là chúng tôi đã định cấu hình kết nối không cần mật khẩu, chúng tôi chỉ có thể thực thi lệnh sau và để nó kết thúc.
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.50.11?master;10.10.50.12?slave;10.10.50.13?slave" --provider-version=13 --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --logBạn sẽ thấy thông báo bên dưới khi quá trình hoàn tất thành công và có thể đăng nhập vào web ClusterControl để xác minh:
...
Saving cluster configuration.
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token.Kết luận
Như bạn có thể thấy, có một số cách về cách triển khai PostgreSQL. Trong bài đăng trên blog này, chúng tôi đã học cách triển khai nó bằng cách sử dụng Ansible và cũng như sử dụng ClusterControl của chúng tôi. Cả hai cách đều dễ làm theo và có thể đạt được với một lộ trình học tập tối thiểu. Với ClusterControl, thiết lập sao chép luồng có thể được bổ sung với HAProxy, VIP và PGBouncer để thêm chuyển đổi dự phòng kết nối, IP ảo và tổng hợp kết nối vào thiết lập.
Lưu ý rằng triển khai chỉ là một khía cạnh của môi trường cơ sở dữ liệu sản xuất. Giữ cho nó luôn hoạt động, tự động chuyển dự phòng, khôi phục các nút bị hỏng và các khía cạnh khác như giám sát, cảnh báo, sao lưu là điều cần thiết.
Hy vọng rằng bài đăng trên blog này sẽ mang lại lợi ích cho một số bạn và đưa ra ý tưởng về cách tự động hóa việc triển khai PostgreSQL.