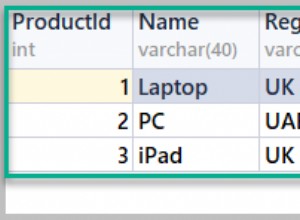
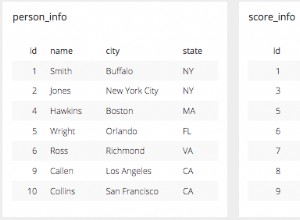
Vấn đề bạn đang thử nghiệm liên quan đến cách bạn đang sử dụng HINT_PASS_DISTINCT_THROUGH gợi ý.
Gợi ý này cho phép bạn chỉ ra Hibernate rằng DISTINCT từ khóa không được sử dụng trong SELECT tuyên bố đưa ra dựa trên cơ sở dữ liệu.
Bạn đang tận dụng thực tế này để cho phép các truy vấn của bạn được sắp xếp theo trường không có trong DISTINCT danh sách cột.
Nhưng đó không phải là cách gợi ý này nên được sử dụng.
Gợi ý này chỉ phải được sử dụng khi bạn chắc chắn rằng sẽ không có sự khác biệt giữa việc áp dụng hay không áp dụng DISTINCT từ khóa cho SQL SELECT vì SELECT câu lệnh đã sẵn sàng sẽ tìm nạp tất cả các giá trị riêng biệt per se . Ý tưởng là cải thiện hiệu suất của truy vấn tránh sử dụng DISTINCT không cần thiết tuyên bố.
Đây thường là điều sẽ xảy ra khi bạn sử dụng query.distinct trong các truy vấn tiêu chí của bạn và bạn đang join fetching các mối quan hệ con cái. Bài viết tuyệt vời này
của @VladMihalcea giải thích chi tiết cách hoạt động của gợi ý.
Mặt khác, khi bạn sử dụng phân trang, nó sẽ đặt OFFSET và LIMIT - hoặc thứ gì đó tương tự, tùy thuộc vào cơ sở dữ liệu bên dưới - trong SELECT của SQL được phát hành dựa trên cơ sở dữ liệu, giới hạn đến một số kết quả tối đa cho truy vấn của bạn.
Như đã nêu, nếu bạn sử dụng HINT_PASS_DISTINCT_THROUGH gợi ý, SELECT câu lệnh sẽ không chứa DISTINCT và do các liên kết của bạn, nó có thể tạo ra các bản ghi trùng lặp về thực thể chính của bạn. Bản ghi này sẽ được xử lý bởi Hibernate để phân biệt các bản sao vì bạn đang sử dụng query.distinct và trên thực tế nó sẽ loại bỏ các bản sao nếu cần. Tôi nghĩ đây là lý do tại sao bạn có thể nhận được ít bản ghi hơn yêu cầu trong Pageable của bạn .
Nếu bạn loại bỏ gợi ý, dưới dạng DISTINCT từ khóa được chuyển trong câu lệnh SQL được gửi đến cơ sở dữ liệu, theo như bạn chỉ chiếu thông tin của thực thể chính, nó sẽ tìm nạp tất cả các bản ghi được chỉ ra bởi LIMIT và đây là lý do tại sao nó sẽ luôn cung cấp cho bạn số lượng bản ghi được yêu cầu.
Bạn có thể thử và fetch join các thực thể con của bạn (thay vì chỉ join với họ). Nó sẽ loại bỏ vấn đề không thể sử dụng trường bạn cần sắp xếp trong các cột của DISTINCT từ khóa và ngoài ra, bạn sẽ có thể áp dụng gợi ý ngay bây giờ một cách hợp pháp.
Nhưng nếu bạn làm như vậy, bạn sẽ gặp phải một vấn đề khác:nếu bạn sử dụng tham gia tìm nạp và phân trang, để trả về các thực thể chính và bộ sưu tập của nó, Hibernate sẽ không áp dụng phân trang ở cấp cơ sở dữ liệu nữa - nó sẽ không bao gồm OFFSET hoặc LIMIT từ khóa trong câu lệnh SQL và nó sẽ cố gắng phân trang các kết quả trong bộ nhớ. Đây là HHH000104 Hibernate nổi tiếng cảnh báo:
HHH000104: firstResult/maxResults specified with collection fetch; applying in memory!
@VladMihalcea giải thích điều đó rất chi tiết trong phần cuối của điều này bài báo.
Anh ấy cũng đề xuất một giải pháp khả thi cho vấn đề của bạn, Chức năng cửa sổ .
Trong trường hợp sử dụng của bạn, thay vì sử dụng Specification s, ý tưởng là bạn thực hiện DAO của riêng bạn. DAO này chỉ cần có quyền truy cập vào EntityManager , đây không phải là vấn đề lớn vì bạn có thể đưa vào @PersistenceContext của mình :
@PersistenceContext
protected EntityManager em;
Sau khi bạn có EntityManager này , bạn có thể tạo các truy vấn gốc và sử dụng các hàm cửa sổ để xây dựng, dựa trên Pageable được cung cấp thông tin, câu lệnh SQL phù hợp sẽ được phát hành dựa trên cơ sở dữ liệu. Điều này sẽ mang lại cho bạn nhiều tự do hơn về những trường sử dụng để sắp xếp hoặc bất cứ điều gì bạn cần.
Như bài báo được trích dẫn cuối cùng đã chỉ ra, Chức năng Cửa sổ là một tính năng được hỗ trợ bởi tất cả các cơ sở dữ liệu của thị trưởng.
Trong trường hợp của PostgreSQL, bạn có thể dễ dàng bắt gặp chúng trong tài liệu chính thức .
Cuối cùng, một tùy chọn nữa, được đề xuất trên thực tế bởi @nickshoe và được giải thích rất chi tiết trong bài viết ông trích dẫn, là thực hiện quá trình sắp xếp và phân trang trong hai giai đoạn:trong giai đoạn đầu, bạn cần tạo một truy vấn sẽ tham chiếu đến các thực thể con của bạn và trong đó bạn sẽ áp dụng phân trang và sắp xếp. Truy vấn này sẽ cho phép bạn xác định id của các thực thể chính sẽ được sử dụng, trong giai đoạn thứ hai của quy trình, để lấy chính các thực thể chính đó.
Bạn có thể tận dụng DAO tùy chỉnh nói trên để thực hiện quá trình này.