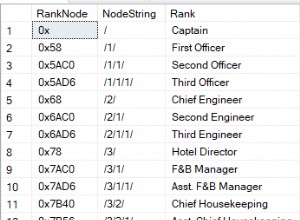
Có nhiều cách để đạt được điều này với các chức năng hiện có. Bạn có thể sử dụng các hàm cửa sổ first_value() và last_value()
, kết hợp với DISTINCT hoặc DISTINCT ON để lấy nó mà không cần kết hợp và truy vấn con:
SELECT DISTINCT ON (userid)
userid
, last_value(rank) OVER w
- first_value(rank) OVER w AS rank_delta
FROM rankings
WINDOW w AS (PARTITION BY userid ORDER BY ts
ROWS BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING);
Lưu ý các khung tùy chỉnh cho các chức năng cửa sổ !
Hoặc bạn có thể sử dụng các hàm tổng hợp cơ bản trong một truy vấn con và JOIN:
SELECT userid, r2.rank - r1.rank AS rank_delta
FROM (
SELECT userid
, min(ts) AS first_ts
, max(ts) AS last_ts
FROM rankings
GROUP BY 1
) sub
JOIN rankings r1 USING (userid)
JOIN rankings r2 USING (userid)
WHERE r1.ts = first_ts
AND r2.ts = last_ts;
Giả sử (userid, rank) hoặc các yêu cầu của bạn sẽ không rõ ràng.
Shichinin không samurai
Mỗi yêu cầu trong nhận xét, chỉ giống nhau cho bảy hàng cuối cùng cho mỗi userrid (hoặc tìm càng nhiều càng tốt, nếu có ít hơn):
Một lần nữa, một trong nhiều cách khả thi. Nhưng tôi tin rằng đây là một trong những cách ngắn nhất:
SELECT DISTINCT ON (userid)
userid
, first_value(rank) OVER w
- last_value(rank) OVER w AS rank_delta
FROM rankings
WINDOW w AS (PARTITION BY userid ORDER BY ts DESC
ROWS BETWEEN CURRENT ROW AND 7 FOLLOWING)
ORDER BY userid, ts DESC;
Lưu ý thứ tự sắp xếp đảo ngược. Hàng đầu tiên là mục nhập "mới nhất". Tôi kéo dài khung (tối đa) 7 hàng và chỉ chọn kết quả cho mục nhập mới nhất với DISTINCT ON .