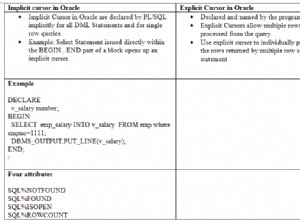
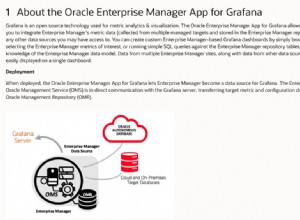
Tôi có thể sẽ sử dụng phạm vi ngày cột.
Điều đó mang lại cho bạn sự linh hoạt để có các khối có kích thước khác nhau và cho phép bạn xác định ràng buộc loại trừ để ngăn các phạm vi chồng chéo.
Việc tìm hàng cho một tuần nhất định vẫn khá đơn giản bằng cách sử dụng toán tử "chứa" @> , ví dụ. where the_column @> to_date('2019-24', 'iyyy-iw') tìm (các) hàng chứa số tuần 24 trong năm 2019.
Biểu thức to_date('2019-24', 'iyyy-iw') trả về ngày đầu tiên (thứ Hai) của tuần được chỉ định.
Việc tìm kiếm tất cả các hàng giữa hai tuần cũng có thể được thực hiện, tuy nhiên việc xây dựng phạm vi ngày tương ứng trông hơi xấu. Bạn có thể xây dựng một phạm vi bao gồm với ngày đầu tiên và ngày cuối cùng:daterange(to_date('2019-24', 'iyyy-iw'), to_date('2019-24', 'iyyy-iw') + 6, '[]')
Hoặc bạn có thể tạo một phạm vi với một phạm vi trên độc quyền với ngày đầu tiên của tuần tiếp theo:daterange(to_date('2019-24', 'iyyy-iw'), to_date('2019-25', 'iyyy-iw'), '[)')
Mặc dù các phạm vi có thể được lập chỉ mục khá hiệu quả và, các chỉ mục GIST cần thiết để duy trì đắt hơn một chút so với chỉ mục B-Tree trên hai cột số nguyên.
Một nhược điểm khác của việc sử dụng phạm vi (nếu bạn không thực sự cần sự linh hoạt) là chúng chiếm nhiều không gian hơn hai cột số nguyên (14 byte thay vì 8, hoặc thậm chí 4 với hai ký tự). Vì vậy, nếu kích thước của bảng là bất kỳ mối quan tâm nào, thì giải pháp hiện tại của bạn với các cột năm / tuần sẽ hiệu quả hơn.
Nếu thông tin đầu vào của bạn là ngày bắt đầu và ngày kết thúc bắt đầu bằng (thay vì "số tuần"), thì tôi chắc chắn sẽ sử dụng daterange cột. Nếu ngày bắt đầu và ngày kết thúc kéo dài hơn một tuần, thì bạn chỉ lưu trữ một hàng, thay vì nhiều hàng.