Khi bạn đang làm việc trên một dự án bao gồm nhiều microservices, nó có thể cũng sẽ bao gồm nhiều cơ sở dữ liệu.
Ví dụ:bạn có thể có cơ sở dữ liệu MySQL và cơ sở dữ liệu PostgreSQL, cả hai đều chạy trên các máy chủ riêng biệt.
Thông thường, để kết hợp dữ liệu từ hai cơ sở dữ liệu, bạn sẽ phải giới thiệu một microservice mới sẽ kết hợp dữ liệu với nhau. Nhưng điều này sẽ làm tăng độ phức tạp của hệ thống.
Trong hướng dẫn này, chúng tôi sẽ sử dụng Materialize để kết hợp MySQL và Postgres trong một chế độ xem vật thể hóa trực tiếp. Sau đó, chúng tôi sẽ có thể truy vấn trực tiếp và lấy lại kết quả từ cả hai cơ sở dữ liệu trong thời gian thực bằng cách sử dụng SQL chuẩn.
Materialize là một cơ sở dữ liệu phát trực tuyến có sẵn nguồn được viết bằng Rust để duy trì kết quả của một truy vấn SQL (một dạng xem được vật thể hóa) trong bộ nhớ khi dữ liệu thay đổi.
Hướng dẫn bao gồm một dự án demo mà bạn có thể bắt đầu sử dụng docker-compose .
Dự án demo mà chúng tôi sẽ sử dụng sẽ theo dõi các đơn đặt hàng trên trang web giả của chúng tôi. Nó sẽ tạo ra các sự kiện mà sau này có thể được sử dụng để gửi thông báo khi một giỏ hàng đã bị bỏ trong một thời gian dài.
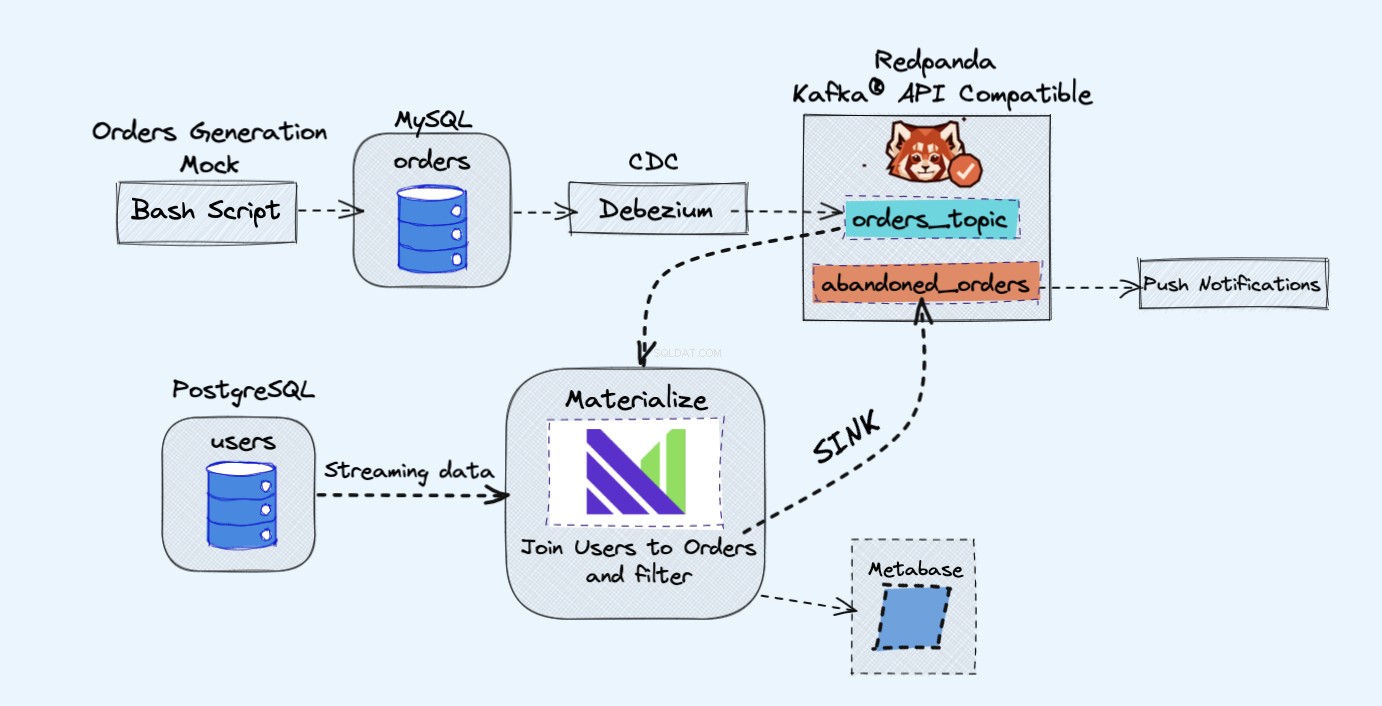
Kiến trúc của dự án demo như sau:
Điều kiện tiên quyết
Tất cả các dịch vụ mà chúng tôi sẽ sử dụng trong bản demo sẽ chạy bên trong vùng chứa Docker, theo cách đó bạn sẽ không phải cài đặt bất kỳ dịch vụ bổ sung nào trên máy tính xách tay hoặc máy chủ của mình thay vì Docker và Docker Compose.
Trong trường hợp bạn chưa cài đặt Docker và Docker Compose, bạn có thể làm theo hướng dẫn chính thức về cách thực hiện việc đó tại đây:
- Cài đặt Docker
- Cài đặt Docker Compose
Tổng quan
Như trong sơ đồ trên, chúng ta sẽ có các thành phần sau:
- Một dịch vụ giả để liên tục tạo ra các đơn đặt hàng.
- Các đơn đặt hàng sẽ được lưu trữ trong cơ sở dữ liệu MySQL .
- Khi cơ sở dữ liệu ghi xảy ra, Debezium chuyển các thay đổi ra khỏi MySQL tới Redpanda chủ đề.
- Chúng tôi cũng sẽ có Postgres cơ sở dữ liệu nơi chúng tôi có thể thu hút người dùng của mình.
- Sau đó, chúng tôi sẽ nhập chủ đề Redpanda này vào Materialize trực tiếp cùng với những người dùng từ cơ sở dữ liệu Postgres.
- Trong Materialize, chúng tôi sẽ kết hợp các đơn đặt hàng và người dùng của chúng tôi với nhau, thực hiện một số lọc và tạo một chế độ xem cụ thể hóa hiển thị thông tin giỏ hàng bị bỏ rơi.
- Sau đó, chúng tôi sẽ tạo một bồn rửa để gửi dữ liệu giỏ hàng bị bỏ rơi sang một chủ đề Redpanda mới.
- Cuối cùng, chúng tôi sẽ sử dụng Metabase để trực quan hóa dữ liệu.
- Sau này, bạn có thể sử dụng thông tin từ chủ đề mới đó để gửi thông báo cho người dùng của mình và nhắc họ rằng họ có một giỏ hàng bị bỏ rơi.
Một lưu ý nhỏ ở đây, bạn sẽ hoàn toàn ổn khi sử dụng Kafka thay vì Redpanda. Tôi chỉ thích sự đơn giản mà Redpanda mang lại cho bảng, vì bạn có thể chạy một phiên bản Redpanda duy nhất thay vì tất cả các thành phần Kafka.
Cách chạy Demo
Trước tiên, hãy bắt đầu bằng cách sao chép kho lưu trữ:
git clone https://github.com/bobbyiliev/materialize-tutorials.git
Sau đó, bạn có thể truy cập vào thư mục:
cd materialize-tutorials/mz-join-mysql-and-postgresql
Hãy bắt đầu bằng cách chạy vùng chứa Redpanda trước:
docker-compose up -d redpanda
Xây dựng hình ảnh:
docker-compose build
Cuối cùng, bắt đầu tất cả các dịch vụ:
docker-compose up -d
Để khởi chạy Materialize CLI, bạn có thể chạy lệnh sau:
docker-compose run mzcli
Đây chỉ là một lối tắt đến vùng chứa Docker với postgres-client được cài đặt sẵn. Nếu bạn đã có psql bạn có thể chạy psql -U materialize -h localhost -p 6875 materialize thay vào đó.
Cách tạo Nguồn Kafka Materialize
Bây giờ bạn đang ở trong Materialize CLI, hãy xác định orders trong mysql.shop cơ sở dữ liệu như nguồn Redpanda:
CREATE SOURCE orders
FROM KAFKA BROKER 'redpanda:9092' TOPIC 'mysql.shop.orders'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081'
ENVELOPE DEBEZIUM;
Nếu bạn kiểm tra các cột có sẵn từ orders nguồn bằng cách chạy câu lệnh sau:
SHOW COLUMNS FROM orders;
Bạn có thể thấy rằng, vì Materialize đang kéo dữ liệu giản đồ thông báo từ sổ đăng ký Redpanda, nó biết các loại cột để sử dụng cho mỗi thuộc tính:
name | nullable | type
--------------+----------+-----------
id | f | bigint
user_id | t | bigint
order_status | t | integer
price | t | numeric
created_at | f | text
updated_at | t | timestamp
Cách tạo chế độ xem cụ thể hóa
Tiếp theo, chúng tôi sẽ tạo Chế độ xem Vật liệu hóa đầu tiên của mình, để lấy tất cả dữ liệu từ orders Nguồn Redpanda:
CREATE MATERIALIZED VIEW orders_view AS
SELECT * FROM orders;
CREATE MATERIALIZED VIEW abandoned_orders AS
SELECT
user_id,
order_status,
SUM(price) as revenue,
COUNT(id) AS total
FROM orders_view
WHERE order_status=0
GROUP BY 1,2;
Bây giờ bạn có thể sử dụng SELECT * FROM abandoned_orders; để xem kết quả:
SELECT * FROM abandoned_orders;
Để biết thêm thông tin về cách tạo các chế độ xem cụ thể hóa, hãy xem phần Chế độ xem cụ thể hóa của tài liệu Nguyên liệu hóa.
Cách tạo nguồn Postgres
Có hai cách để tạo nguồn Postgres trong Materialize:
- Sử dụng Debezium giống như chúng tôi đã làm với nguồn MySQL.
- Sử dụng Nguồn Materialize của Postgres, cho phép bạn kết nối Materialize trực tiếp với Postgres để bạn không phải sử dụng Debezium.
Đối với bản trình diễn này, chúng tôi sẽ sử dụng Nguồn Postgres Materialize chỉ như một minh chứng về cách sử dụng nó, nhưng hãy sử dụng Debezium để thay thế.
Để tạo Nguồn vật chất hóa Postgres, hãy chạy câu lệnh sau:
CREATE MATERIALIZED SOURCE "mz_source" FROM POSTGRES
CONNECTION 'user=postgres port=5432 host=postgres dbname=postgres password=postgres'
PUBLICATION 'mz_source';
Tóm tắt nhanh câu lệnh trên:
-
MATERIALIZED:Hiện thực hóa dữ liệu của nguồn PostgreSQL. Tất cả dữ liệu được giữ lại trong bộ nhớ và giúp các nguồn có thể chọn trực tiếp. -
mz_source:Tên của nguồn PostgreSQL. -
CONNECTION:Các tham số kết nối PostgreSQL. -
PUBLICATION:Ấn phẩm PostgreSQL, chứa các bảng được truyền trực tuyến đến Materialize.
Khi chúng tôi đã tạo nguồn PostgreSQL, để có thể truy vấn các bảng PostgreSQL, chúng tôi cần tạo các dạng xem đại diện cho các bảng gốc của ấn phẩm ngược dòng.
Trong trường hợp của chúng tôi, chúng tôi chỉ có một bảng được gọi là users vì vậy câu lệnh mà chúng ta cần chạy là:
CREATE VIEWS FROM SOURCE mz_source (users);
Để xem các dạng xem có sẵn, hãy thực hiện câu lệnh sau:
SHOW FULL VIEWS;
Sau khi hoàn tất, bạn có thể truy vấn trực tiếp các chế độ xem mới:
SELECT * FROM users;
Tiếp theo, hãy tiếp tục và tạo thêm một vài chế độ xem.
Cách tạo bồn rửa Kafka
Chìm cho phép bạn gửi dữ liệu từ Materialize sang nguồn bên ngoài.
Đối với Demo này, chúng tôi sẽ sử dụng Redpanda.
Redpanda tương thích với API Kafka và Materialize có thể xử lý dữ liệu từ nó giống như xử lý dữ liệu từ nguồn Kafka.
Hãy tạo một chế độ xem cụ thể hóa, sẽ chứa tất cả các đơn đặt hàng chưa thanh toán số lượng lớn:
CREATE MATERIALIZED VIEW high_value_orders AS
SELECT
users.id,
users.email,
abandoned_orders.revenue,
abandoned_orders.total
FROM users
JOIN abandoned_orders ON abandoned_orders.user_id = users.id
GROUP BY 1,2,3,4
HAVING revenue > 2000;
Như bạn có thể thấy, ở đây chúng tôi thực sự đang tham gia users chế độ xem đang nhập dữ liệu trực tiếp từ nguồn Postgres của chúng tôi và abandond_orders chế độ xem đang nhập dữ liệu từ chủ đề Redpanda.
Hãy tạo một Sink nơi chúng tôi sẽ gửi dữ liệu của chế độ xem cụ thể hóa ở trên:
CREATE SINK high_value_orders_sink
FROM high_value_orders
INTO KAFKA BROKER 'redpanda:9092' TOPIC 'high-value-orders-sink'
FORMAT AVRO USING
CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
Bây giờ, nếu bạn kết nối với vùng chứa Redpanda và sử dụng chủ đề rpk topic consume , bạn sẽ có thể đọc các bản ghi từ chủ đề.
Tuy nhiên, hiện tại, chúng tôi sẽ không thể xem trước kết quả với rpk vì nó được định dạng AVRO. Redpanda rất có thể sẽ triển khai điều này trong tương lai, nhưng hiện tại, chúng tôi thực sự có thể truyền chủ đề trở lại Materialize để xác nhận định dạng.
Đầu tiên, lấy tên của chủ đề đã được tạo tự động:
SELECT topic FROM mz_kafka_sinks;
Đầu ra:
topic
-----------------------------------------------------------------
high-volume-orders-sink-u12-1637586945-13670686352905873426
Để biết thêm thông tin về cách tạo tên chủ đề, hãy xem tài liệu tại đây.
Sau đó, tạo Nguồn Vật liệu hóa mới từ chủ đề Redpanda này:
CREATE MATERIALIZED SOURCE high_volume_orders_test
FROM KAFKA BROKER 'redpanda:9092' TOPIC ' high-volume-orders-sink-u12-1637586945-13670686352905873426'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
Đảm bảo thay đổi tên chủ đề cho phù hợp!
Cuối cùng, hãy truy vấn chế độ xem cụ thể hóa mới này:
SELECT * FROM high_volume_orders_test LIMIT 2;
Bây giờ bạn đã có dữ liệu trong chủ đề, bạn có thể có các dịch vụ khác kết nối với nó và sử dụng nó, sau đó kích hoạt email hoặc cảnh báo chẳng hạn.
Cách kết nối siêu dữ liệu
Để truy cập phiên bản Metabase, hãy truy cập https://localhost:3030 nếu bạn đang chạy bản trình diễn cục bộ hoặc https://your_server_ip:3030 nếu bạn đang chạy bản demo trên máy chủ. Sau đó, hãy làm theo các bước để hoàn tất thiết lập Metabase.
Đảm bảo chọn Materialize làm nguồn dữ liệu.
Sau khi sẵn sàng, bạn sẽ có thể trực quan hóa dữ liệu của mình giống như khi bạn làm với cơ sở dữ liệu PostgreSQL tiêu chuẩn.
Cách dừng Bản trình diễn
Để dừng tất cả các dịch vụ, hãy chạy lệnh sau:
docker-compose down
Kết luận
Như bạn có thể thấy, đây là một ví dụ rất đơn giản về cách sử dụng Materialize. Bạn có thể sử dụng Materialize để nhập dữ liệu từ nhiều nguồn khác nhau và sau đó truyền trực tuyến dữ liệu đó đến nhiều điểm đến khác nhau.
Các tài nguyên hữu ích:
-
CREATE SOURCE: PostgreSQL -
CREATE SOURCE -
CREATE VIEWS -
SELECT