Python và SQL là hai trong số những ngôn ngữ quan trọng nhất đối với Nhà phân tích dữ liệu.
Trong bài viết này, tôi sẽ hướng dẫn bạn mọi thứ bạn cần biết để kết nối Python và SQL.
Bạn sẽ học cách kéo dữ liệu từ cơ sở dữ liệu quan hệ vào thẳng đường ống học máy của mình, lưu trữ dữ liệu từ ứng dụng Python trong cơ sở dữ liệu của riêng bạn hoặc bất kỳ trường hợp sử dụng nào khác mà bạn có thể đưa ra.
Chúng ta sẽ cùng nhau đề cập đến:
- Tại sao nên học cách sử dụng Python và SQL cùng nhau?
- Cách thiết lập môi trường Python và Máy chủ MySQL của bạn
- Kết nối với Máy chủ MySQL bằng Python
- Tạo Cơ sở dữ liệu mới
- Tạo Bảng và Mối quan hệ giữa Bảng
- Sắp xếp các bảng với dữ liệu
- Đọc dữ liệu
- Cập nhật Hồ sơ
- Xóa hồ sơ
- Tạo bản ghi từ danh sách Python
- Tạo các chức năng có thể tái sử dụng để thực hiện tất cả những điều này cho chúng tôi trong tương lai
Đó là rất nhiều thứ rất hữu ích và rất thú vị. Hãy bắt đầu!
Một lưu ý nhanh trước khi chúng ta bắt đầu:có một Sổ tay Jupyter chứa tất cả mã được sử dụng trong hướng dẫn này có sẵn trong kho lưu trữ GitHub này. Chúng tôi rất khuyến khích sử dụng mã hóa!
Cơ sở dữ liệu và mã SQL được sử dụng ở đây là tất cả từ loạt bài Giới thiệu về SQL trước đây của tôi được đăng trên Towards Data Science (hãy liên hệ với tôi nếu bạn gặp bất kỳ vấn đề nào khi xem bài viết và tôi có thể gửi cho bạn liên kết để xem chúng miễn phí).
Nếu bạn không quen thuộc với SQL và các khái niệm đằng sau cơ sở dữ liệu quan hệ, tôi sẽ hướng dẫn bạn về loạt bài đó (tất nhiên là có rất nhiều thứ tuyệt vời có sẵn ở đây trên freeCodeCamp!)
Tại sao sử dụng Python với SQL?
Đối với các nhà phân tích dữ liệu và nhà khoa học dữ liệu, Python có rất nhiều lợi thế. Một loạt các thư viện mã nguồn mở khổng lồ làm cho nó trở thành một công cụ cực kỳ hữu ích cho bất kỳ Nhà phân tích dữ liệu nào.
Chúng tôi có gấu trúc, NumPy và Vaex để phân tích dữ liệu, Matplotlib, seaborn và Bokeh để trực quan hóa và TensorFlow, scikit-learning và PyTorch cho các ứng dụng học máy (cùng với nhiều ứng dụng khác).
Với đường cong học tập (tương đối) dễ dàng và tính linh hoạt, không có gì lạ khi Python là một trong những ngôn ngữ lập trình phát triển nhanh nhất hiện có.
Vì vậy, nếu chúng ta đang sử dụng Python để phân tích dữ liệu, thì cần phải hỏi - tất cả dữ liệu này đến từ đâu?
Mặc dù có rất nhiều nguồn cho bộ dữ liệu, nhưng trong nhiều trường hợp - đặc biệt là trong các doanh nghiệp doanh nghiệp - dữ liệu sẽ được lưu trữ trong cơ sở dữ liệu quan hệ. Cơ sở dữ liệu quan hệ là một cách cực kỳ hiệu quả, mạnh mẽ và được sử dụng rộng rãi để tạo, đọc, cập nhật và xóa các loại dữ liệu.
Các hệ quản trị cơ sở dữ liệu quan hệ (RDBMS) được sử dụng rộng rãi nhất - Oracle, MySQL, Microsoft SQL Server, PostgreSQL, IBM DB2 - đều sử dụng Ngôn ngữ truy vấn có cấu trúc (SQL) để truy cập và thực hiện các thay đổi đối với dữ liệu.
Lưu ý rằng mỗi RDBMS sử dụng một hương vị SQL hơi khác nhau, vì vậy mã SQL được viết cho một mã thường sẽ không hoạt động trong một RDBMS khác nếu không có sửa đổi (thường là khá nhỏ). Nhưng các khái niệm, cấu trúc và hoạt động phần lớn giống hệt nhau.
Điều này có nghĩa là đối với một Nhà phân tích dữ liệu đang làm việc, hiểu biết sâu sắc về SQL là vô cùng quan trọng. Biết cách sử dụng Python và SQL cùng nhau sẽ mang lại cho bạn nhiều lợi thế hơn khi làm việc với dữ liệu của mình.
Phần còn lại của bài viết này sẽ được dành để cho bạn thấy chính xác cách chúng tôi có thể làm điều đó.
Bắt đầu
Yêu cầu &Cài đặt
Để viết mã cùng với hướng dẫn này, bạn sẽ cần thiết lập môi trường Python của riêng mình.
Tôi sử dụng Anaconda, nhưng có rất nhiều cách để làm điều này. Chỉ cần google "cách cài đặt Python" nếu bạn cần trợ giúp thêm. Bạn cũng có thể sử dụng Binder để viết mã cùng với Máy tính xách tay Jupyter được liên kết.
Chúng tôi sẽ sử dụng MySQL Community Server vì nó miễn phí và được sử dụng rộng rãi trong ngành. Nếu bạn đang sử dụng Windows, hướng dẫn này sẽ giúp bạn thiết lập. Dưới đây là hướng dẫn cho người dùng Mac và Linux (mặc dù nó có thể khác nhau tùy theo bản phân phối Linux).
Sau khi bạn đã thiết lập những thứ đó, chúng ta sẽ cần làm cho chúng giao tiếp với nhau.
Để làm được điều đó, chúng ta cần cài đặt thư viện MySQL Connector Python. Để thực hiện việc này, hãy làm theo hướng dẫn hoặc chỉ sử dụng pip:
pip install mysql-connector-pythonChúng tôi cũng sẽ sử dụng gấu trúc, vì vậy hãy đảm bảo rằng bạn cũng đã cài đặt nó.
pip install pandasNhập Thư viện
Như với mọi dự án bằng Python, điều đầu tiên chúng tôi muốn làm là nhập các thư viện của chúng tôi.
Cách tốt nhất là nhập tất cả các thư viện mà chúng tôi sẽ sử dụng khi bắt đầu dự án, vì vậy những người đọc hoặc xem lại mã của chúng tôi biết đại khái những gì sắp xảy ra nên không có gì ngạc nhiên.
Đối với hướng dẫn này, chúng tôi sẽ chỉ sử dụng hai thư viện - MySQL Connector và pandas.
import mysql.connector
from mysql.connector import Error
import pandas as pdChúng tôi nhập riêng chức năng Lỗi để chúng tôi có thể dễ dàng truy cập vào nó cho các chức năng của mình.
Kết nối với Máy chủ MySQL
Đến thời điểm này, chúng ta nên thiết lập MySQL Community Server trên hệ thống của mình. Bây giờ chúng ta cần viết một số mã bằng Python cho phép chúng ta thiết lập kết nối với máy chủ đó.
def create_server_connection(host_name, user_name, user_password):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionCách tốt nhất là tạo một hàm có thể sử dụng lại cho mã như thế này, để chúng ta có thể sử dụng nó nhiều lần với nỗ lực tối thiểu. Sau khi điều này được viết ra, bạn cũng có thể sử dụng lại nó trong tất cả các dự án của mình trong tương lai, vì vậy trong tương lai-bạn sẽ rất biết ơn!
Hãy xem qua từng dòng một để chúng ta hiểu điều gì đang xảy ra ở đây:
Dòng đầu tiên là chúng ta đặt tên cho hàm (create_server_connection) và đặt tên cho các đối số mà hàm đó sẽ nhận (host_name, user_name và user_password).
Dòng tiếp theo đóng mọi kết nối hiện có để máy chủ không bị nhầm lẫn với nhiều kết nối đang mở.
Tiếp theo, chúng tôi sử dụng khối try-trừ trong Python để xử lý bất kỳ lỗi tiềm ẩn nào. Phần đầu tiên cố gắng tạo kết nối đến máy chủ bằng phương thức mysql.connector.connect () bằng cách sử dụng các chi tiết do người dùng chỉ định trong các đối số. Nếu điều này hoạt động, hàm sẽ in một thông báo thành công nhỏ.
Phần ngoại trừ của khối in ra lỗi mà Máy chủ MySQL trả về, trong trường hợp không may là có lỗi.
Cuối cùng, nếu kết nối thành công, hàm trả về một đối tượng kết nối.
Chúng tôi sử dụng điều này trong thực tế bằng cách gán đầu ra của hàm cho một biến, sau đó trở thành đối tượng kết nối của chúng tôi. Sau đó, chúng tôi có thể áp dụng các phương pháp khác (chẳng hạn như con trỏ) cho nó và tạo các đối tượng hữu ích khác.
connection = create_server_connection("localhost", "root", pw)Điều này sẽ tạo ra một thông báo thành công:

Tạo cơ sở dữ liệu mới
Bây giờ chúng ta đã thiết lập kết nối, bước tiếp theo của chúng ta là tạo một cơ sở dữ liệu mới trên máy chủ của chúng ta.
Trong hướng dẫn này, chúng tôi sẽ thực hiện điều này chỉ một lần, nhưng một lần nữa chúng tôi sẽ viết nó dưới dạng một hàm có thể sử dụng lại để chúng ta có một hàm hữu ích tuyệt vời mà chúng ta có thể sử dụng lại cho các dự án trong tương lai.
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("Database created successfully")
except Error as err:
print(f"Error: '{err}'")Hàm này nhận hai đối số, kết nối (đối tượng kết nối của chúng ta) và truy vấn (truy vấn SQL mà chúng ta sẽ viết trong bước tiếp theo). Nó thực hiện truy vấn trong máy chủ thông qua kết nối.
Chúng tôi sử dụng phương thức con trỏ trên đối tượng kết nối của mình để tạo đối tượng con trỏ (MySQL Connector sử dụng mô hình lập trình hướng đối tượng, vì vậy có rất nhiều đối tượng kế thừa thuộc tính từ các đối tượng mẹ).
Đối tượng con trỏ này có các phương thức như thi hành, thi hành (mà chúng ta sẽ sử dụng trong hướng dẫn này) cùng với một số phương thức hữu ích khác.
Nếu hữu ích, chúng ta có thể nghĩ đối tượng con trỏ cung cấp cho chúng ta quyền truy cập vào con trỏ nhấp nháy trong cửa sổ đầu cuối Máy chủ MySQL.
Tiếp theo, chúng tôi xác định một truy vấn để tạo cơ sở dữ liệu và gọi hàm:

Tất cả các truy vấn SQL được sử dụng trong hướng dẫn này được giải thích trong loạt bài Hướng dẫn Giới thiệu về SQL của tôi và mã đầy đủ có thể được tìm thấy trong Sổ tay Jupyter được liên kết trong kho lưu trữ GitHub này, vì vậy tôi sẽ không cung cấp giải thích về những gì mã SQL trong này hướng dẫn.
Tuy nhiên, đây có lẽ là truy vấn SQL đơn giản nhất có thể. Nếu bạn có thể đọc tiếng Anh, bạn có thể tìm ra nó làm gì!
Chạy hàm create_database với các đối số như trên dẫn đến một cơ sở dữ liệu có tên 'school' đang được tạo trong máy chủ của chúng tôi.
Tại sao cơ sở dữ liệu của chúng tôi được gọi là 'trường học'? Có lẽ bây giờ sẽ là thời điểm tốt để xem xét chi tiết hơn về chính xác những gì chúng tôi sẽ triển khai trong hướng dẫn này.
Cơ sở dữ liệu của chúng tôi
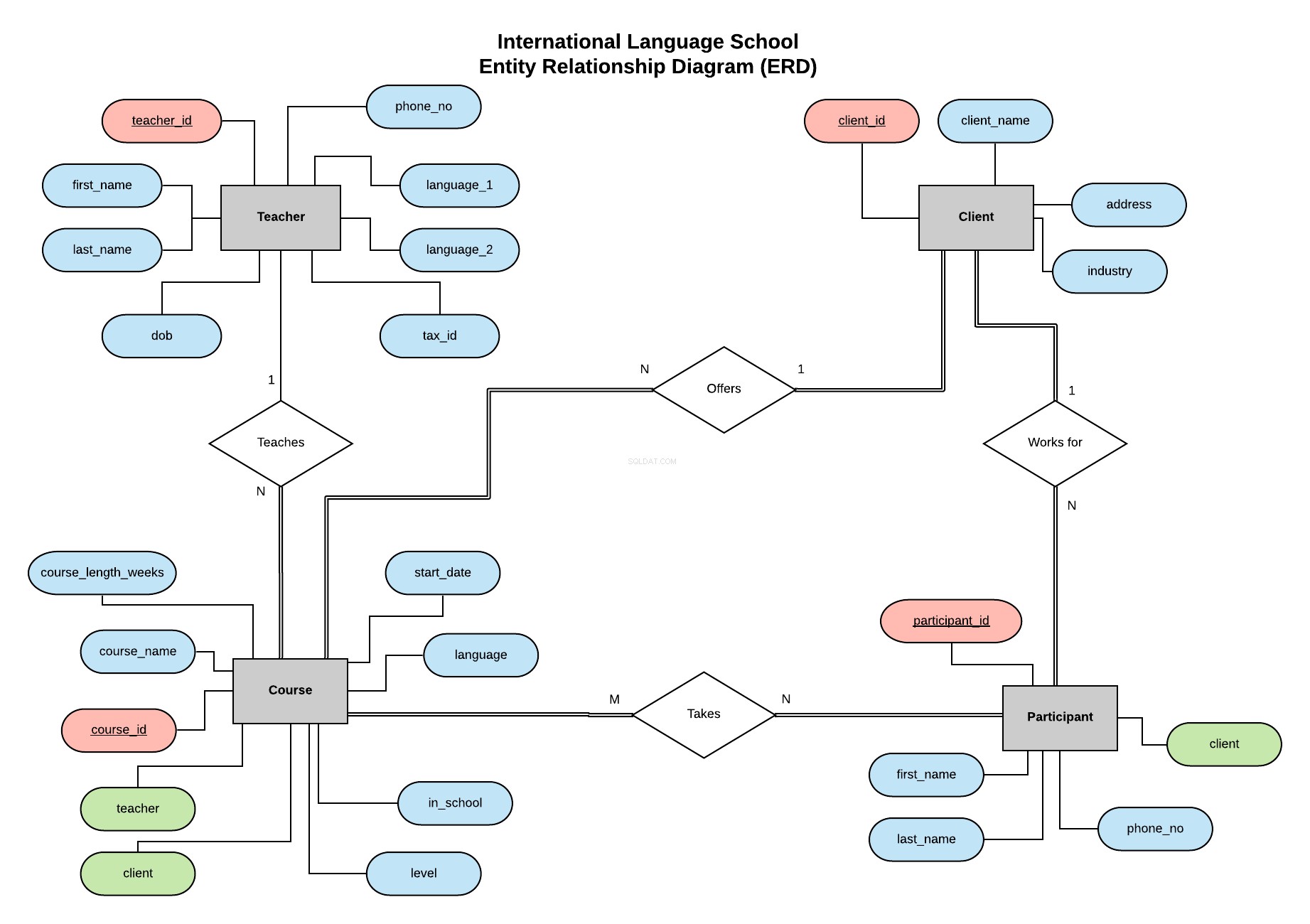
Theo ví dụ trong loạt bài trước của tôi, chúng tôi sẽ triển khai cơ sở dữ liệu cho Trường Ngôn ngữ Quốc tế - một trường đào tạo ngôn ngữ hư cấu cung cấp các bài học ngôn ngữ chuyên nghiệp cho khách hàng doanh nghiệp.
Sơ đồ mối quan hệ thực thể (ERD) này đưa ra các thực thể của chúng tôi (Giáo viên, Khách hàng, Khóa học và Người tham gia) và xác định mối quan hệ giữa chúng.
Tất cả thông tin về ERD là gì và những điều cần cân nhắc khi tạo và thiết kế cơ sở dữ liệu có thể được tìm thấy trong bài viết này.
Mã SQL thô, các yêu cầu cơ sở dữ liệu và dữ liệu để đi vào cơ sở dữ liệu đều có trong kho lưu trữ GitHub này, nhưng bạn sẽ thấy tất cả khi chúng ta xem qua hướng dẫn này.
Kết nối với Cơ sở dữ liệu
Bây giờ chúng ta đã tạo cơ sở dữ liệu trong MySQL Server, chúng ta có thể sửa đổi hàm create_server_connection để kết nối trực tiếp với cơ sở dữ liệu này.
Lưu ý rằng có thể - thực tế là phổ biến - có nhiều cơ sở dữ liệu trên một Máy chủ MySQL, vì vậy chúng tôi muốn kết nối luôn và tự động với cơ sở dữ liệu mà chúng tôi quan tâm.
Chúng ta có thể làm như vậy:
def create_db_connection(host_name, user_name, user_password, db_name):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password,
database=db_name
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionĐây là cùng một hàm chính xác, nhưng bây giờ chúng ta lấy thêm một đối số - tên cơ sở dữ liệu - và chuyển đối số đó làm đối số cho phương thức connect ().
Tạo hàm thực thi truy vấn
Hàm cuối cùng mà chúng ta sẽ tạo (hiện tại) là một hàm cực kỳ quan trọng - một hàm thực thi truy vấn. Điều này sẽ nhận các truy vấn SQL của chúng tôi, được lưu trữ trong Python dưới dạng chuỗi và chuyển chúng đến phương thức cursor.execute () để thực thi chúng trên máy chủ.
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Hàm này hoàn toàn giống với hàm create_database của chúng ta trước đó, ngoại trừ việc nó sử dụng phương thức connect.commit () để đảm bảo rằng các lệnh chi tiết trong truy vấn SQL của chúng ta được triển khai.
Đây sẽ là hàm workhorse của chúng tôi, chúng tôi sẽ sử dụng (cùng với create_db_connection) để tạo bảng, thiết lập mối quan hệ giữa các bảng đó, điền dữ liệu vào bảng, cập nhật và xóa bản ghi trong cơ sở dữ liệu của chúng tôi.
Nếu bạn là một chuyên gia SQL, chức năng này sẽ cho phép bạn thực thi bất kỳ và tất cả các lệnh và truy vấn phức tạp mà bạn có thể gặp phải, trực tiếp từ một tập lệnh Python. Đây có thể là một công cụ rất mạnh để quản lý dữ liệu của bạn.
Tạo bảng
Bây giờ chúng ta đã sẵn sàng để bắt đầu chạy các lệnh SQL vào Máy chủ của mình và bắt đầu xây dựng cơ sở dữ liệu của chúng ta. Điều đầu tiên chúng ta muốn làm là tạo các bảng cần thiết.
Hãy bắt đầu với bảng Giáo viên của chúng ta:
create_teacher_table = """
CREATE TABLE teacher (
teacher_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
language_1 VARCHAR(3) NOT NULL,
language_2 VARCHAR(3),
dob DATE,
tax_id INT UNIQUE,
phone_no VARCHAR(20)
);
"""
connection = create_db_connection("localhost", "root", pw, db) # Connect to the Database
execute_query(connection, create_teacher_table) # Execute our defined queryTrước hết, chúng ta gán lệnh SQL của mình (được giải thích chi tiết ở đây) cho một biến có tên thích hợp.
Trong trường hợp này, chúng tôi sử dụng ký hiệu dấu ngoặc kép của Python cho các chuỗi nhiều dòng để lưu trữ truy vấn SQL của chúng tôi, sau đó chúng tôi đưa nó vào hàm execute_query để triển khai.
Lưu ý rằng định dạng nhiều dòng này hoàn toàn vì lợi ích của con người đọc mã của chúng tôi. Cả SQL và Python đều không 'quan tâm' nếu lệnh SQL được trải rộng như thế này. Vì vậy, miễn là cú pháp chính xác, cả hai ngôn ngữ sẽ chấp nhận nó.
Tuy nhiên, vì lợi ích của con người, những người sẽ đọc mã của bạn, (ngay cả khi đó sẽ chỉ là của bạn trong tương lai!), Việc làm này rất hữu ích để làm cho mã dễ đọc và dễ hiểu hơn.
Điều này cũng đúng đối với việc viết hoa các toán tử trong SQL. Đây là quy ước được sử dụng rộng rãi được khuyến khích thực hiện, nhưng phần mềm thực tế chạy mã không phân biệt chữ hoa chữ thường và sẽ coi 'CREATE TABLE teacher' và 'create table teacher' là các lệnh giống hệt nhau.

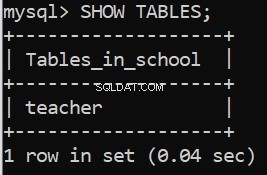
Chạy mã này cho chúng tôi thông báo thành công của chúng tôi. Chúng tôi cũng có thể xác minh điều này trong Máy khách dòng lệnh máy chủ MySQL:
Tuyệt quá! Bây giờ chúng ta hãy tạo các bảng còn lại.
create_client_table = """
CREATE TABLE client (
client_id INT PRIMARY KEY,
client_name VARCHAR(40) NOT NULL,
address VARCHAR(60) NOT NULL,
industry VARCHAR(20)
);
"""
create_participant_table = """
CREATE TABLE participant (
participant_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
phone_no VARCHAR(20),
client INT
);
"""
create_course_table = """
CREATE TABLE course (
course_id INT PRIMARY KEY,
course_name VARCHAR(40) NOT NULL,
language VARCHAR(3) NOT NULL,
level VARCHAR(2),
course_length_weeks INT,
start_date DATE,
in_school BOOLEAN,
teacher INT,
client INT
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, create_client_table)
execute_query(connection, create_participant_table)
execute_query(connection, create_course_table)Điều này tạo ra bốn bảng cần thiết cho bốn thực thể của chúng tôi.
Bây giờ chúng ta muốn xác định mối quan hệ giữa chúng và tạo thêm một bảng để xử lý mối quan hệ nhiều-nhiều giữa người tham gia và các bảng khóa học (xem tại đây để biết thêm chi tiết).
Chúng tôi làm điều này theo cùng một cách:
alter_participant = """
ALTER TABLE participant
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
alter_course = """
ALTER TABLE course
ADD FOREIGN KEY(teacher)
REFERENCES teacher(teacher_id)
ON DELETE SET NULL;
"""
alter_course_again = """
ALTER TABLE course
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
create_takescourse_table = """
CREATE TABLE takes_course (
participant_id INT,
course_id INT,
PRIMARY KEY(participant_id, course_id),
FOREIGN KEY(participant_id) REFERENCES participant(participant_id) ON DELETE CASCADE,
FOREIGN KEY(course_id) REFERENCES course(course_id) ON DELETE CASCADE
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, alter_participant)
execute_query(connection, alter_course)
execute_query(connection, alter_course_again)
execute_query(connection, create_takescourse_table)Giờ đây, các bảng của chúng ta đã được tạo, cùng với các ràng buộc thích hợp, quan hệ khóa chính và khóa ngoại.
Điền các bảng
Bước tiếp theo là thêm một số bản ghi vào các bảng. Một lần nữa, chúng tôi sử dụng execute_query để cung cấp các lệnh SQL hiện có của chúng tôi vào Máy chủ. Hãy bắt đầu lại với bảng Giáo viên.
pop_teacher = """
INSERT INTO teacher VALUES
(1, 'James', 'Smith', 'ENG', NULL, '1985-04-20', 12345, '+491774553676'),
(2, 'Stefanie', 'Martin', 'FRA', NULL, '1970-02-17', 23456, '+491234567890'),
(3, 'Steve', 'Wang', 'MAN', 'ENG', '1990-11-12', 34567, '+447840921333'),
(4, 'Friederike', 'Müller-Rossi', 'DEU', 'ITA', '1987-07-07', 45678, '+492345678901'),
(5, 'Isobel', 'Ivanova', 'RUS', 'ENG', '1963-05-30', 56789, '+491772635467'),
(6, 'Niamh', 'Murphy', 'ENG', 'IRI', '1995-09-08', 67890, '+491231231232');
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_teacher)Điều này có hiệu quả không? Chúng tôi có thể kiểm tra lại trong Máy khách dòng lệnh MySQL của mình:
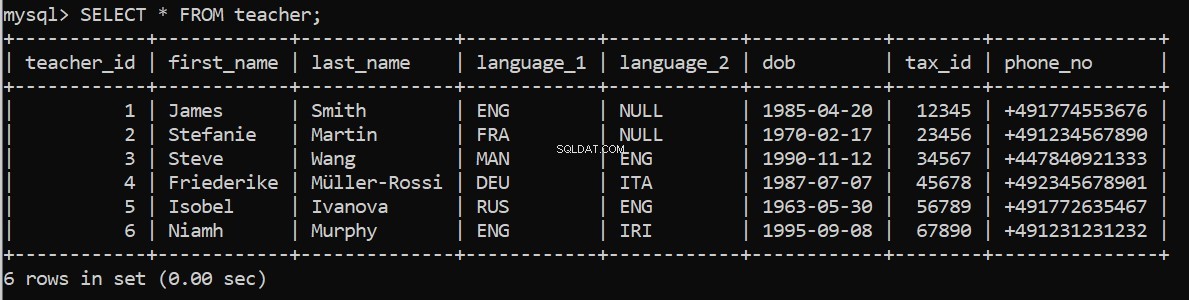
Bây giờ để điền các bảng còn lại.
pop_client = """
INSERT INTO client VALUES
(101, 'Big Business Federation', '123 Falschungstraße, 10999 Berlin', 'NGO'),
(102, 'eCommerce GmbH', '27 Ersatz Allee, 10317 Berlin', 'Retail'),
(103, 'AutoMaker AG', '20 Künstlichstraße, 10023 Berlin', 'Auto'),
(104, 'Banko Bank', '12 Betrugstraße, 12345 Berlin', 'Banking'),
(105, 'WeMoveIt GmbH', '138 Arglistweg, 10065 Berlin', 'Logistics');
"""
pop_participant = """
INSERT INTO participant VALUES
(101, 'Marina', 'Berg','491635558182', 101),
(102, 'Andrea', 'Duerr', '49159555740', 101),
(103, 'Philipp', 'Probst', '49155555692', 102),
(104, 'René', 'Brandt', '4916355546', 102),
(105, 'Susanne', 'Shuster', '49155555779', 102),
(106, 'Christian', 'Schreiner', '49162555375', 101),
(107, 'Harry', 'Kim', '49177555633', 101),
(108, 'Jan', 'Nowak', '49151555824', 101),
(109, 'Pablo', 'Garcia', '49162555176', 101),
(110, 'Melanie', 'Dreschler', '49151555527', 103),
(111, 'Dieter', 'Durr', '49178555311', 103),
(112, 'Max', 'Mustermann', '49152555195', 104),
(113, 'Maxine', 'Mustermann', '49177555355', 104),
(114, 'Heiko', 'Fleischer', '49155555581', 105);
"""
pop_course = """
INSERT INTO course VALUES
(12, 'English for Logistics', 'ENG', 'A1', 10, '2020-02-01', TRUE, 1, 105),
(13, 'Beginner English', 'ENG', 'A2', 40, '2019-11-12', FALSE, 6, 101),
(14, 'Intermediate English', 'ENG', 'B2', 40, '2019-11-12', FALSE, 6, 101),
(15, 'Advanced English', 'ENG', 'C1', 40, '2019-11-12', FALSE, 6, 101),
(16, 'Mandarin für Autoindustrie', 'MAN', 'B1', 15, '2020-01-15', TRUE, 3, 103),
(17, 'Français intermédiaire', 'FRA', 'B1', 18, '2020-04-03', FALSE, 2, 101),
(18, 'Deutsch für Anfänger', 'DEU', 'A2', 8, '2020-02-14', TRUE, 4, 102),
(19, 'Intermediate English', 'ENG', 'B2', 10, '2020-03-29', FALSE, 1, 104),
(20, 'Fortgeschrittenes Russisch', 'RUS', 'C1', 4, '2020-04-08', FALSE, 5, 103);
"""
pop_takescourse = """
INSERT INTO takes_course VALUES
(101, 15),
(101, 17),
(102, 17),
(103, 18),
(104, 18),
(105, 18),
(106, 13),
(107, 13),
(108, 13),
(109, 14),
(109, 15),
(110, 16),
(110, 20),
(111, 16),
(114, 12),
(112, 19),
(113, 19);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_client)
execute_query(connection, pop_participant)
execute_query(connection, pop_course)
execute_query(connection, pop_takescourse)Kinh ngạc! Bây giờ chúng ta đã tạo một cơ sở dữ liệu hoàn chỉnh với các quan hệ, ràng buộc và bản ghi trong MySQL, không sử dụng gì ngoài các lệnh Python.
Chúng tôi đã trải qua từng bước này để giữ cho nó dễ hiểu. Nhưng đến thời điểm này, bạn có thể thấy rằng tất cả điều này có thể rất dễ dàng được viết thành một tập lệnh Python và được thực thi bằng một lệnh trong thiết bị đầu cuối. Công cụ mạnh mẽ.
Đọc dữ liệu
Bây giờ chúng ta có một cơ sở dữ liệu chức năng để làm việc. Là một Nhà phân tích dữ liệu, bạn có khả năng tiếp xúc với các cơ sở dữ liệu hiện có trong các tổ chức nơi bạn làm việc. Sẽ rất hữu ích nếu biết cách kéo dữ liệu ra khỏi các cơ sở dữ liệu đó để sau đó nó có thể được đưa vào đường dẫn dữ liệu python của bạn. Đây là những gì chúng tôi sẽ làm tiếp theo.
Đối với điều này, chúng ta sẽ cần một hàm nữa, lần này sử dụng cursor.fetchall () thay vì cursor.commit (). Với chức năng này, chúng tôi đang đọc dữ liệu từ cơ sở dữ liệu và sẽ không thực hiện bất kỳ thay đổi nào.
def read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as err:
print(f"Error: '{err}'")Một lần nữa, chúng ta sẽ triển khai điều này theo một cách rất giống với execute_query. Hãy dùng thử với một truy vấn đơn giản để xem nó hoạt động như thế nào.
q1 = """
SELECT *
FROM teacher;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q1)
for result in results:
print(result)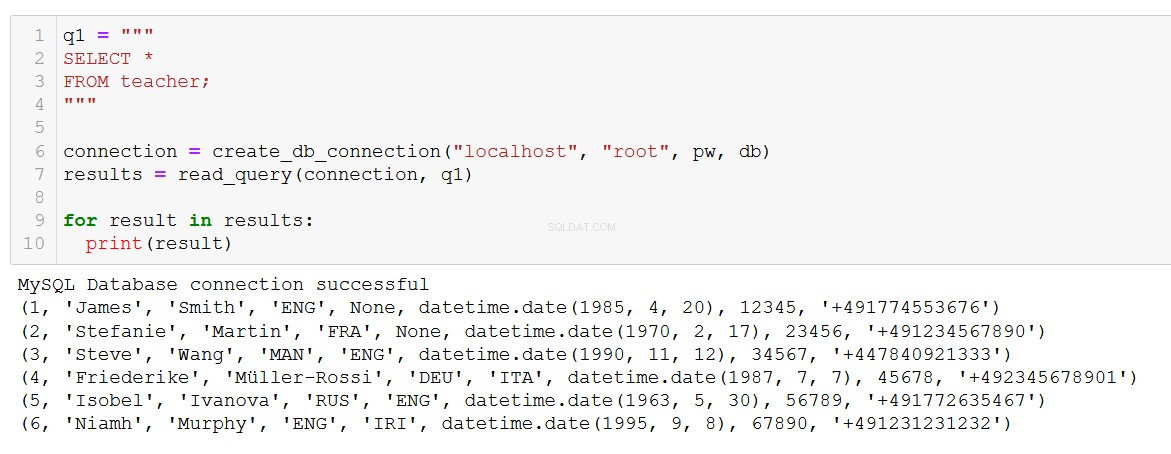
Chính xác những gì chúng tôi đang mong đợi. Hàm cũng hoạt động với các truy vấn phức tạp hơn, chẳng hạn như truy vấn này liên quan đến một JOIN trên các bảng khóa học và khách hàng.
q5 = """
SELECT course.course_id, course.course_name, course.language, client.client_name, client.address
FROM course
JOIN client
ON course.client = client.client_id
WHERE course.in_school = FALSE;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q5)
for result in results:
print(result)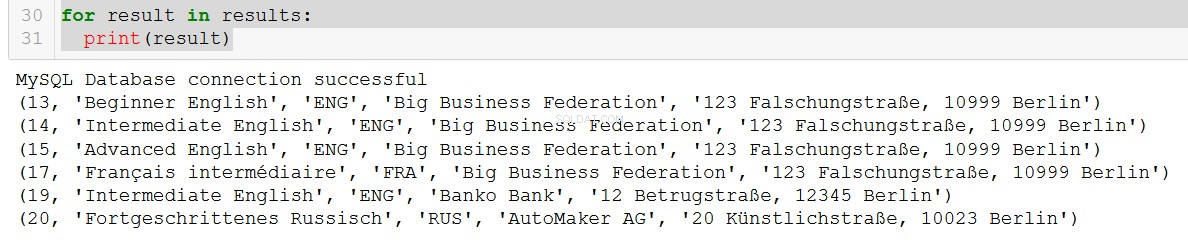
Rất đẹp.
Đối với đường ống dữ liệu và quy trình làm việc của chúng tôi bằng Python, chúng tôi có thể muốn nhận được những kết quả này ở các định dạng khác nhau để làm cho chúng hữu ích hơn hoặc sẵn sàng để chúng tôi thao tác.
Hãy xem qua một vài ví dụ để xem chúng ta có thể làm điều đó như thế nào.
Định dạng đầu ra thành danh sách
#Initialise empty list
from_db = []
# Loop over the results and append them into our list
# Returns a list of tuples
for result in results:
result = result
from_db.append(result)
Định dạng đầu ra thành một danh sách các danh sách
# Returns a list of lists
from_db = []
for result in results:
result = list(result)
from_db.append(result)
Định dạng đầu ra thành DataFrame gấu trúc
Đối với các Nhà phân tích dữ liệu sử dụng Python, gấu trúc là người bạn cũ xinh đẹp và đáng tin cậy của chúng tôi. Rất đơn giản để chuyển đổi đầu ra từ cơ sở dữ liệu của chúng tôi thành DataFrame và từ đó khả năng là vô tận!
# Returns a list of lists and then creates a pandas DataFrame
from_db = []
for result in results:
result = list(result)
from_db.append(result)
columns = ["course_id", "course_name", "language", "client_name", "address"]
df = pd.DataFrame(from_db, columns=columns)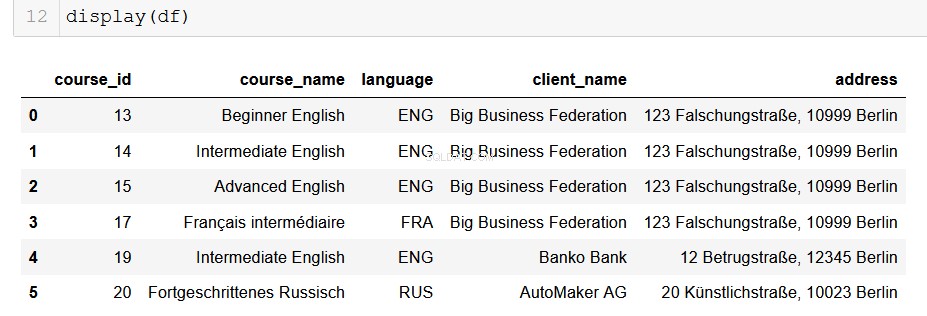
Hy vọng rằng bạn có thể nhìn thấy những khả năng đang mở ra trước mắt bạn ở đây. Chỉ với một vài dòng mã, chúng tôi có thể dễ dàng trích xuất tất cả dữ liệu mà chúng tôi có thể xử lý từ cơ sở dữ liệu quan hệ nơi nó tồn tại và đưa nó vào đường ống phân tích dữ liệu hiện đại của chúng tôi. Đây là công cụ thực sự hữu ích.
Cập nhật Bản ghi
Khi chúng tôi đang duy trì một cơ sở dữ liệu, đôi khi chúng tôi sẽ cần thực hiện các thay đổi đối với các bản ghi hiện có. Trong phần này, chúng ta sẽ xem xét cách thực hiện điều đó.
Giả sử ILS được thông báo rằng một trong những khách hàng hiện tại của nó, Big Business Federation, đang chuyển văn phòng đến 23 Fingiertweg, 14534 Berlin. Trong trường hợp này, quản trị viên cơ sở dữ liệu (đó là chúng tôi!) Sẽ cần thực hiện một số thay đổi.
Rất may, chúng ta có thể thực hiện việc này với hàm execute_query cùng với câu lệnh SQL UPDATE.
update = """
UPDATE client
SET address = '23 Fingiertweg, 14534 Berlin'
WHERE client_id = 101;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, update)Lưu ý rằng mệnh đề WHERE rất quan trọng ở đây. Nếu chúng tôi chạy truy vấn này mà không có mệnh đề WHERE, thì tất cả địa chỉ cho tất cả các bản ghi trong bảng Khách hàng của chúng tôi sẽ được cập nhật thành 23 Fingiertweg. Đó không phải là những gì chúng tôi đang muốn làm.
Cũng lưu ý rằng chúng tôi đã sử dụng "WHERE client_id =101" trong truy vấn CẬP NHẬT. Cũng có thể sử dụng "WHERE client_name ='Big Business Federation'" hoặc "WHERE address ='123 Falschungstraße, 10999 Berlin'" hoặc thậm chí "WHERE address LIKE '% Falschung%'".
Điều quan trọng là mệnh đề WHERE cho phép chúng tôi xác định duy nhất bản ghi (hoặc các bản ghi) mà chúng tôi muốn cập nhật.
Xóa các bản ghi
Cũng có thể sử dụng hàm execute_query của chúng tôi để xóa các bản ghi, bằng cách sử dụng DELETE.
Khi sử dụng SQL với cơ sở dữ liệu quan hệ, chúng ta cần cẩn thận khi sử dụng toán tử DELETE. Đây không phải là Windows, không có 'Bạn có chắc chắn muốn xóa cái này không?' cửa sổ bật lên cảnh báo và không có thùng rác tái chế. Sau khi chúng tôi xóa nội dung nào đó, nó thực sự biến mất.
Như đã nói, đôi khi chúng ta thực sự cần phải xóa mọi thứ. Vì vậy, hãy xem xét điều đó bằng cách xóa một khóa học khỏi bảng Khóa học của chúng tôi.
Trước hết, chúng ta hãy tự nhắc mình xem chúng ta có những khóa học nào.
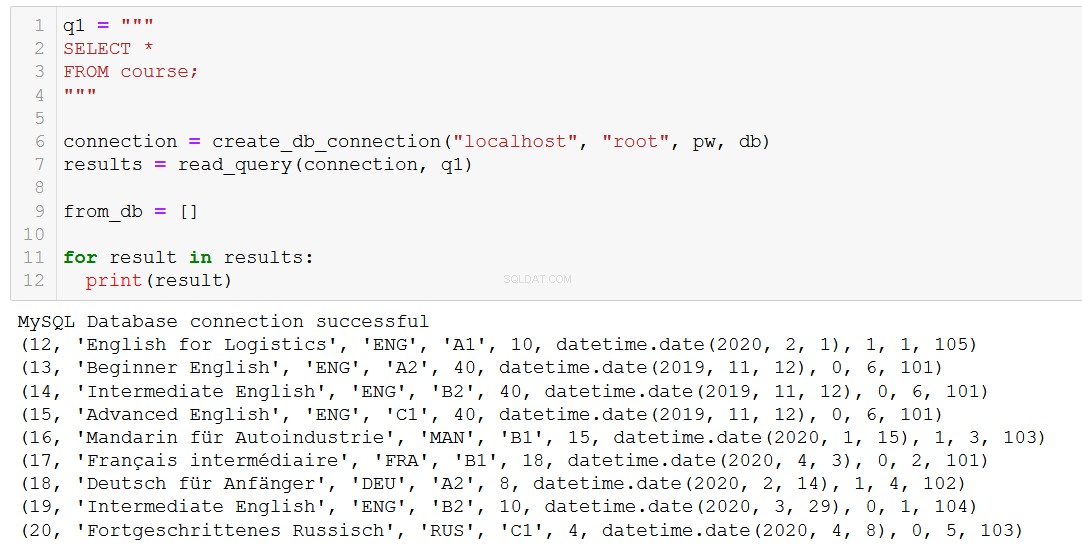
Giả sử khóa học 20, 'Fortgeschrittenes Russisch' (đó là 'Tiếng Nga nâng cao' đối với bạn và tôi), sắp kết thúc, vì vậy chúng tôi cần xóa nó khỏi cơ sở dữ liệu của mình.
Đến giai đoạn này, bạn sẽ hoàn toàn không ngạc nhiên với cách chúng tôi thực hiện việc này - lưu lệnh SQL dưới dạng một chuỗi, sau đó đưa nó vào hàm execute_query của workhorse.
delete_course = """
DELETE FROM course
WHERE course_id = 20;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, delete_course)Hãy kiểm tra để xác nhận rằng điều đó đã có tác dụng dự kiến:
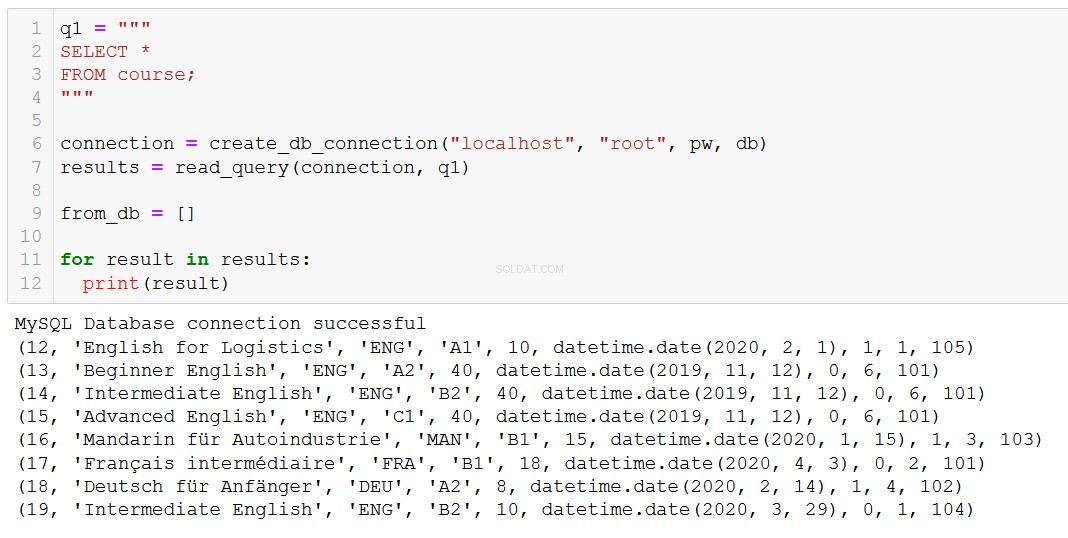
'Tiếng Nga nâng cao' đã biến mất, như chúng tôi mong đợi.
Điều này cũng hoạt động với việc xóa toàn bộ cột bằng DROP COLUMN và toàn bộ bảng bằng lệnh DROP TABLE, nhưng chúng tôi sẽ không đề cập đến các lệnh đó trong hướng dẫn này.
Tuy nhiên, hãy tiếp tục và thử nghiệm chúng - không quan trọng nếu bạn xóa một cột hoặc bảng khỏi cơ sở dữ liệu cho một trường học giả tưởng và bạn nên trở nên thoải mái với các lệnh này trước khi chuyển sang môi trường sản xuất.
Ồ CRUD
Đến thời điểm này, chúng tôi đã có thể hoàn thành bốn hoạt động chính để lưu trữ dữ liệu liên tục.
Chúng tôi đã học cách:
- Tạo - cơ sở dữ liệu, bảng và bản ghi hoàn toàn mới
- Đọc - trích xuất dữ liệu từ cơ sở dữ liệu và lưu trữ dữ liệu đó ở nhiều định dạng
- Cập nhật - thực hiện các thay đổi đối với các bản ghi hiện có trong cơ sở dữ liệu
- Xóa - xóa các bản ghi không còn cần thiết
Đây là những điều cực kỳ hữu ích có thể làm được.
Trước khi hoàn thành mọi thứ ở đây, chúng ta có một kỹ năng rất hữu ích nữa cần học.
Tạo bản ghi từ danh sách
Chúng tôi đã thấy khi điền vào các bảng của mình rằng chúng tôi có thể sử dụng lệnh SQL INSERT trong hàm execute_query của mình để chèn các bản ghi vào cơ sở dữ liệu của chúng tôi.
Cho rằng chúng tôi đang sử dụng Python để thao tác cơ sở dữ liệu SQL của mình, sẽ rất hữu ích nếu có thể lấy cấu trúc dữ liệu Python (chẳng hạn như danh sách) và chèn trực tiếp cấu trúc đó vào cơ sở dữ liệu của chúng tôi.
Điều này có thể hữu ích khi chúng tôi muốn lưu trữ nhật ký hoạt động của người dùng trên một ứng dụng truyền thông xã hội mà chúng tôi đã viết bằng Python hoặc nhập liệu từ người dùng vào Wiki mà chúng tôi đã xây dựng chẳng hạn. Có rất nhiều cách sử dụng có thể cho việc này mà bạn có thể nghĩ ra.
Phương pháp này cũng an toàn hơn nếu cơ sở dữ liệu của chúng tôi mở cho người dùng tại bất kỳ thời điểm nào, vì nó giúp ngăn chặn các cuộc tấn công SQL Injection, có thể làm hỏng hoặc thậm chí phá hủy toàn bộ cơ sở dữ liệu của chúng tôi.
Để thực hiện việc này, chúng ta sẽ viết một hàm bằng phương thức execute (), thay vì phương thức execute () đơn giản hơn mà chúng ta đang sử dụng cho đến nay.
def execute_list_query(connection, sql, val):
cursor = connection.cursor()
try:
cursor.executemany(sql, val)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")Bây giờ chúng ta có một hàm, chúng ta cần xác định một lệnh SQL ('sql') và một danh sách chứa các giá trị mà chúng ta muốn nhập vào cơ sở dữ liệu ('val'). Các giá trị phải được lưu trữ dưới dạng danh sách các bộ giá trị, đây là một cách khá phổ biến để lưu trữ dữ liệu trong Python.
Để thêm hai giáo viên mới vào cơ sở dữ liệu, chúng ta có thể viết một số đoạn mã như sau:
sql = '''
INSERT INTO teacher (teacher_id, first_name, last_name, language_1, language_2, dob, tax_id, phone_no)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
'''
val = [
(7, 'Hank', 'Dodson', 'ENG', None, '1991-12-23', 11111, '+491772345678'),
(8, 'Sue', 'Perkins', 'MAN', 'ENG', '1976-02-02', 22222, '+491443456432')
]Lưu ý ở đây rằng trong mã 'sql', chúng tôi sử dụng '% s' làm trình giữ chỗ cho giá trị của chúng tôi. Sự giống nhau với trình giữ chỗ '% s' cho một chuỗi trong python chỉ là ngẫu nhiên (và nói thẳng ra là rất khó hiểu), chúng tôi muốn sử dụng '% s' cho tất cả các kiểu dữ liệu (chuỗi, int, ngày, v.v.) với MySQL Python Tư nối.
Bạn có thể thấy một số câu hỏi trên Stackoverflow nơi ai đó đã trở nên bối rối và cố gắng sử dụng trình giữ chỗ '% d' cho các số nguyên vì họ đã quen với việc này trong Python. Điều này sẽ không hoạt động ở đây - chúng tôi cần sử dụng '% s' cho mỗi cột mà chúng tôi muốn thêm giá trị vào.
Sau đó, hàm thực thi sẽ lấy từng bộ trong danh sách 'val' của chúng tôi và chèn giá trị có liên quan cho cột đó vào vị trí của trình giữ chỗ và thực thi lệnh SQL cho từng bộ có trong danh sách.
Điều này có thể được thực hiện cho nhiều hàng dữ liệu, miễn là chúng được định dạng chính xác. Trong ví dụ của chúng tôi, chúng tôi sẽ chỉ thêm hai giáo viên mới, với mục đích minh họa, nhưng về nguyên tắc, chúng tôi có thể thêm bao nhiêu tùy thích.
Hãy tiếp tục và thực hiện truy vấn này và thêm giáo viên vào cơ sở dữ liệu của chúng tôi.
connection = create_db_connection("localhost", "root", pw, db)
execute_list_query(connection, sql, val)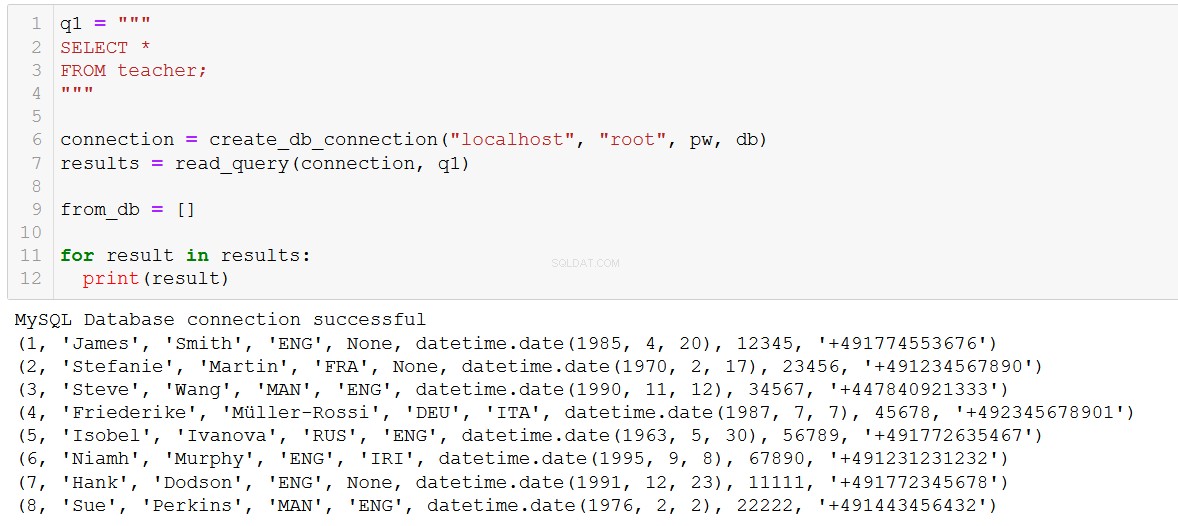
Chào mừng bạn đến với ILS, Hank và Sue!
This is yet another deeply useful function, allowing us to take data generated in our Python scripts and applications, and enter them directly into our database.
Conclusion
We have covered a lot of ground in this tutorial.
We have learned how to use Python and MySQL Connector to create an entirely new database in MySQL Server, create tables within that database, define the relationships between those tables, and populate them with data.
We have covered how to Create, Read, Update and Delete data in our database.
We have looked at how to extract data from existing databases and load them into pandas DataFrames, ready for analysis and further work taking advantage of all the possibilities offered by the PyData stack.
Going in the other direction, we have also learned how to take data generated by our Python scripts and applications, and write those into a database where they can be safely stored for later retrieval and manipulation.
I hope this tutorial has helped you to see how we can use Python and SQL together to be able to manipulate data even more effectively!
If you'd like to see more of my projects and work, please visit my website at craigdoesdata.de. If you have any feedback on this tutorial, please contact me directly - all feedback is warmly received!