Hiệu suất cực kỳ quan trọng trong nhiều sản phẩm tiêu dùng như thương mại điện tử, hệ thống thanh toán, trò chơi, ứng dụng giao thông, v.v. Mặc dù cơ sở dữ liệu được tối ưu hóa nội bộ thông qua nhiều cơ chế để đáp ứng các yêu cầu về hiệu suất của chúng trong thế giới hiện đại, nhưng điều này cũng phụ thuộc rất nhiều vào nhà phát triển ứng dụng - xét cho cùng, chỉ có nhà phát triển mới biết ứng dụng phải thực hiện những truy vấn nào.
Các nhà phát triển xử lý cơ sở dữ liệu quan hệ đã sử dụng hoặc ít nhất là nghe nói về lập chỉ mục và đó là một khái niệm rất phổ biến trong thế giới cơ sở dữ liệu. Tuy nhiên, phần quan trọng nhất là hiểu những gì cần lập chỉ mục và cách lập chỉ mục sẽ tăng thời gian phản hồi truy vấn. Để làm điều đó, bạn cần hiểu cách bạn sẽ truy vấn các bảng cơ sở dữ liệu của mình. Chỉ có thể tạo chỉ mục thích hợp khi bạn biết chính xác mẫu truy vấn và truy cập dữ liệu của mình trông như thế nào.
Theo thuật ngữ đơn giản, một chỉ mục ánh xạ các khóa tìm kiếm tới dữ liệu tương ứng trên đĩa bằng cách sử dụng các cấu trúc dữ liệu trong bộ nhớ và trên đĩa khác nhau. Chỉ mục được sử dụng để nhanh chóng tìm kiếm bằng cách giảm số lượng bản ghi cần tìm kiếm.
Chủ yếu chỉ mục được tạo trên các cột được chỉ định trong WHERE mệnh đề của truy vấn khi cơ sở dữ liệu truy xuất &lọc dữ liệu từ các bảng dựa trên các cột đó. Nếu bạn không tạo chỉ mục, cơ sở dữ liệu sẽ quét tất cả các hàng, lọc ra các hàng phù hợp và trả về kết quả. Với hàng triệu bản ghi, thao tác quét này có thể mất nhiều giây và thời gian phản hồi cao này làm cho các API và ứng dụng chậm hơn và không sử dụng được. Hãy xem một ví dụ -
Chúng tôi sẽ sử dụng MySQL với công cụ cơ sở dữ liệu InnoDB mặc định, mặc dù các khái niệm được giải thích trong bài viết này ít nhiều giống với các máy chủ cơ sở dữ liệu khác cũng như Oracle, MSSQL, v.v.
Tạo bảng có tên index_demo với giản đồ sau:
CREATE TABLE index_demo (
name VARCHAR(20) NOT NULL,
age INT,
pan_no VARCHAR(20),
phone_no VARCHAR(20)
);Làm cách nào để xác minh rằng chúng tôi đang sử dụng công cụ InnoDB?
Chạy lệnh dưới đây:
SHOW TABLE STATUS WHERE name = 'index_demo' \G;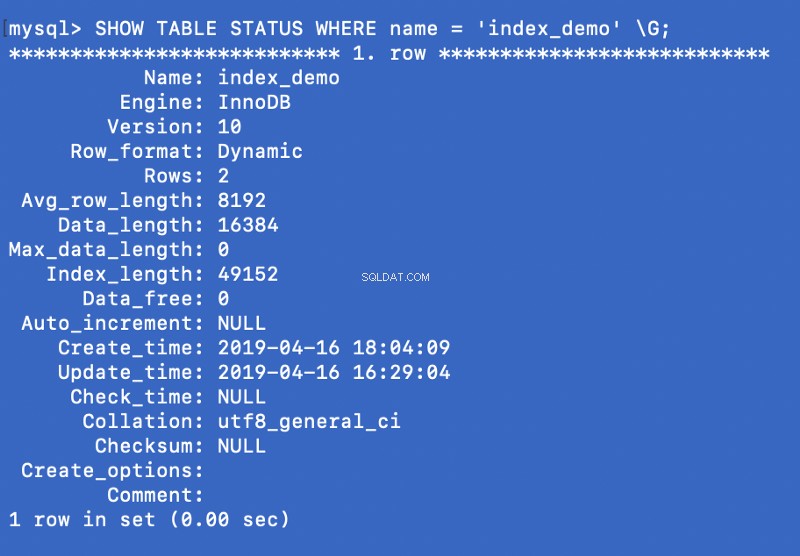
Engine trong ảnh chụp màn hình ở trên đại diện cho công cụ được sử dụng để tạo bảng. Đây InnoDB được sử dụng.
Bây giờ Chèn một số dữ liệu ngẫu nhiên vào bảng, bảng của tôi với 5 hàng trông như sau:
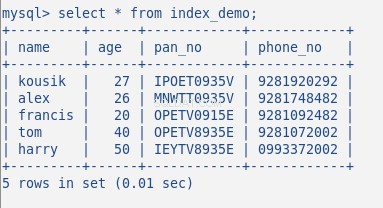
Tôi đã không tạo bất kỳ chỉ mục nào cho đến bây giờ trên bảng này. Hãy xác minh điều này bằng lệnh:SHOW INDEX . Nó trả về 0 kết quả.

Tại thời điểm này, nếu chúng ta chạy một SELECT đơn giản truy vấn, vì không có chỉ mục do người dùng xác định, truy vấn sẽ quét toàn bộ bảng để tìm ra kết quả:
EXPLAIN SELECT * FROM index_demo WHERE name = 'alex';
EXPLAIN cho biết công cụ truy vấn dự định thực hiện truy vấn như thế nào. Trong ảnh chụp màn hình ở trên, bạn có thể thấy rằng rows cột trả về 5 &possible_keys trả về null . possible_keys đại diện cho tất cả các chỉ số có sẵn ở đó có thể được sử dụng trong truy vấn này. Khóa key cột biểu thị chỉ mục nào thực sự sẽ được sử dụng trong số tất cả các chỉ mục có thể có trong truy vấn này.
Khóa chính:
Truy vấn trên là rất kém hiệu quả. Hãy tối ưu hóa truy vấn này. Chúng tôi sẽ tạo phone_no cột a PRIMARY KEY giả sử rằng không có hai người dùng nào có thể tồn tại trong hệ thống của chúng tôi với cùng một số điện thoại. Hãy cân nhắc những điều sau khi tạo khóa chính:
- Khóa chính phải là một phần của nhiều truy vấn quan trọng trong ứng dụng của bạn.
- Khóa chính là một ràng buộc xác định duy nhất mỗi hàng trong bảng. Nếu nhiều cột là một phần của khóa chính, thì tổ hợp đó phải là duy nhất cho mỗi hàng.
- Khóa chính không được rỗng. Không bao giờ đặt các trường không có khả năng trở thành khóa chính của bạn. Theo tiêu chuẩn ANSI SQL, các khóa chính phải được so sánh với nhau và bạn chắc chắn có thể biết liệu giá trị cột khóa chính cho một hàng cụ thể lớn hơn, nhỏ hơn hay bằng cùng một hàng từ hàng khác. Kể từ khi
NULLnghĩa là một giá trị không xác định trong các tiêu chuẩn SQL, bạn không thể so sánh một cách xác địnhNULLvới bất kỳ giá trị nào khác, vì vậy về mặt logicNULLkhông được phép. - Loại khóa chính lý tưởng phải là một số như
INThoặcBIGINTbởi vì so sánh số nguyên nhanh hơn, vì vậy việc duyệt qua chỉ mục sẽ rất nhanh.
Thường thì chúng tôi xác định một id trường dưới dạng AUTO INCREMENT trong bảng và sử dụng khóa đó làm khóa chính, nhưng việc lựa chọn khóa chính phụ thuộc vào nhà phát triển.
Điều gì sẽ xảy ra nếu bạn không tự tạo bất kỳ khóa chính nào?
Bạn không bắt buộc phải tự tạo khóa chính. Nếu bạn chưa xác định bất kỳ khóa chính nào, InnoDB sẽ mặc nhiên tạo một khóa chính cho bạn vì InnoDB theo thiết kế phải có khóa chính trong mọi bảng. Vì vậy, khi bạn tạo khóa chính sau này cho bảng đó, InnoDB sẽ xóa khóa chính được xác định tự động trước đó.
Vì chúng tôi không có bất kỳ khóa chính nào được xác định cho đến thời điểm hiện tại, hãy xem những gì InnoDB theo mặc định đã tạo cho chúng tôi:
SHOW EXTENDED INDEX FROM index_demo;
EXTENDED hiển thị tất cả các chỉ số mà người dùng không thể sử dụng được nhưng được quản lý hoàn toàn bởi MySQL.
Ở đây, chúng ta thấy rằng MySQL đã xác định một chỉ mục tổng hợp (chúng ta sẽ thảo luận về các chỉ số tổng hợp sau) trên DB_ROW_ID , DB_TRX_ID , DB_ROLL_PTR &tất cả các cột được xác định trong bảng. Trong trường hợp không có khóa chính do người dùng xác định, chỉ mục này được sử dụng để tìm các bản ghi duy nhất.
Sự khác biệt giữa khóa và chỉ mục là gì?
Mặc dù các điều khoản key &index được sử dụng thay thế cho nhau, key nghĩa là một ràng buộc áp đặt lên hành vi của cột. Trong trường hợp này, ràng buộc là khóa chính là trường không thể null xác định duy nhất mỗi hàng. Mặt khác, index là một cấu trúc dữ liệu đặc biệt tạo điều kiện thuận lợi cho việc tìm kiếm dữ liệu trên toàn bảng.
Bây giờ hãy tạo chỉ mục chính trên phone_no &kiểm tra chỉ mục đã tạo:
ALTER TABLE index_demo ADD PRIMARY KEY (phone_no);
SHOW INDEXES FROM index_demo;
Lưu ý rằng CREATE INDEX không thể được sử dụng để tạo chỉ mục chính, nhưng ALTER TABLE được sử dụng.

Trong ảnh chụp màn hình ở trên, chúng ta thấy rằng một chỉ mục chính được tạo trên cột phone_no . Các cột của các hình ảnh sau được mô tả như sau:
Table :Bảng mà chỉ mục được tạo.
Non_unique :Nếu giá trị là 1, chỉ mục không phải là duy nhất, nếu giá trị là 0, chỉ mục là duy nhất.
Key_name :Tên của chỉ mục được tạo. Tên của chỉ mục chính luôn là PRIMARY trong MySQL, bất kể bạn đã cung cấp bất kỳ tên chỉ mục nào hay chưa khi tạo chỉ mục.
Seq_in_index :Số thứ tự của cột trong chỉ mục. Nếu nhiều cột là một phần của chỉ mục, số thứ tự sẽ được chỉ định dựa trên cách các cột được sắp xếp trong thời gian tạo chỉ mục. Số thứ tự bắt đầu từ 1.
Collation :cách sắp xếp cột trong chỉ mục. A có nghĩa là tăng dần, D nghĩa là giảm dần, NULL có nghĩa là không được sắp xếp.
Cardinality :Số lượng giá trị ước tính duy nhất trong chỉ mục. Số lượng nhiều hơn có nghĩa là cơ hội cao hơn rằng trình tối ưu hóa truy vấn sẽ chọn chỉ mục cho các truy vấn.
Sub_part :Tiền tố chỉ mục. Nó là NULL nếu toàn bộ cột được lập chỉ mục. Nếu không, nó hiển thị số byte được lập chỉ mục trong trường hợp cột được lập chỉ mục một phần. Chúng tôi sẽ xác định chỉ mục một phần sau.
Packed :Cho biết khóa được đóng gói như thế nào; NULL nếu không.
Null :YES nếu cột có thể chứa NULL và để trống nếu không.
Index_type :Cho biết cấu trúc dữ liệu lập chỉ mục nào được sử dụng cho chỉ mục này. Một số ứng cử viên có thể là - BTREE , HASH , RTREE hoặc FULLTEXT .
Comment :Thông tin về chỉ mục không được mô tả trong cột riêng của nó.
Index_comment :Nhận xét cho chỉ mục được chỉ định khi bạn tạo chỉ mục với COMMENT thuộc tính.
Bây giờ, hãy xem chỉ mục này có làm giảm số hàng sẽ được tìm kiếm cho một phone_no nhất định hay không trong WHERE mệnh đề của một truy vấn.
EXPLAIN SELECT * FROM index_demo WHERE phone_no = '9281072002';
Trong ảnh chụp nhanh này, lưu ý rằng các hàng key cột đã trả về 1 chỉ, possible_keys &key cả hai đều trả về PRIMARY . Vì vậy, về cơ bản nó có nghĩa là sử dụng chỉ mục chính có tên là PRIMARY (tên được tự động gán khi bạn tạo khóa chính), trình tối ưu hóa truy vấn chỉ trực tiếp đến bản ghi và tìm nạp nó. Nó rất hiệu quả. Đây chính xác là mục đích của chỉ mục - để giảm thiểu phạm vi tìm kiếm với chi phí là thêm dung lượng.
Chỉ mục theo cụm:
Một clustered index được sắp xếp với dữ liệu trong cùng một không gian bảng hoặc cùng một tệp đĩa. Bạn có thể coi rằng một chỉ mục được phân nhóm là một B-Tree chỉ mục có các nút lá là khối dữ liệu thực tế trên đĩa, vì chỉ mục và dữ liệu nằm cùng nhau. Loại chỉ mục này tổ chức vật lý dữ liệu trên đĩa theo thứ tự logic của khóa chỉ mục.
Tổ chức dữ liệu vật lý có nghĩa là gì?
Về mặt vật lý, dữ liệu được tổ chức trên đĩa qua hàng nghìn hoặc hàng triệu đĩa / khối dữ liệu. Đối với chỉ mục được phân nhóm, không bắt buộc tất cả các khối đĩa phải được lưu trữ liên tục. Các khối dữ liệu vật lý luôn được HĐH di chuyển khắp nơi tại đây bất cứ khi nào cần thiết. Hệ thống cơ sở dữ liệu không có bất kỳ quyền kiểm soát tuyệt đối nào đối với cách quản lý không gian dữ liệu vật lý, nhưng bên trong khối dữ liệu, các bản ghi có thể được lưu trữ hoặc quản lý theo thứ tự logic của khóa chỉ mục. Sơ đồ đơn giản sau giải thích điều đó:
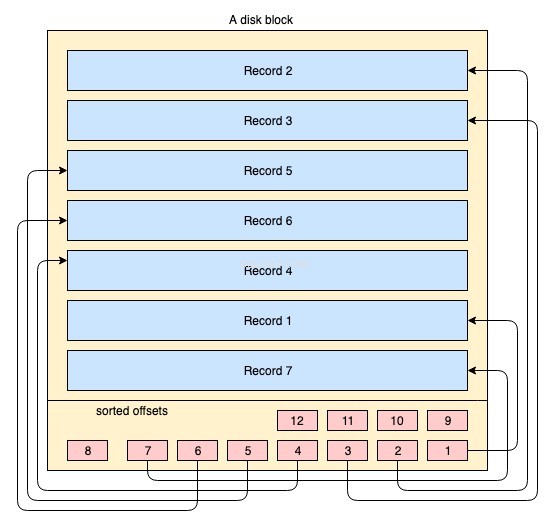
- Hình chữ nhật lớn có màu vàng thể hiện khối đĩa / khối dữ liệu
- các hình chữ nhật có màu xanh lam đại diện cho dữ liệu được lưu trữ dưới dạng các hàng bên trong khối đó
- vùng chân trang đại diện cho chỉ mục của khối nơi các hình chữ nhật nhỏ màu đỏ nằm theo thứ tự được sắp xếp của một khóa cụ thể. Những khối nhỏ này không là gì ngoài loại con trỏ trỏ đến các phần bù của bản ghi.
Các bản ghi được lưu trữ trên khối đĩa theo bất kỳ thứ tự tùy ý nào. Bất cứ khi nào các bản ghi mới được thêm vào, chúng sẽ được thêm vào không gian có sẵn tiếp theo. Bất cứ khi nào một bản ghi hiện có được cập nhật, hệ điều hành sẽ quyết định liệu bản ghi đó vẫn có thể phù hợp với vị trí cũ hay phải cấp phát một vị trí mới cho bản ghi đó.
Vì vậy, vị trí của các bản ghi hoàn toàn được xử lý bởi OS &không tồn tại mối quan hệ xác định nào giữa thứ tự của hai bản ghi bất kỳ. Để tìm nạp các bản ghi theo thứ tự lôgic của khóa, các trang đĩa chứa phần chỉ mục ở chân trang, chỉ mục chứa danh sách các con trỏ bù theo thứ tự của khóa. Mỗi khi bản ghi được thay đổi hoặc tạo, chỉ mục sẽ được điều chỉnh.
Bằng cách này, bạn thực sự không cần quan tâm đến việc thực sự sắp xếp hồ sơ vật lý theo một thứ tự nhất định, thay vào đó, một phần chỉ mục nhỏ được duy trì theo thứ tự đó và việc tìm nạp hoặc duy trì hồ sơ trở nên rất dễ dàng.
Lợi thế của Clustered Index:
Việc sắp xếp thứ tự hoặc cùng vị trí của dữ liệu liên quan này thực sự làm cho một chỉ mục được phân cụm nhanh hơn. Khi dữ liệu được tìm nạp từ đĩa, khối hoàn chỉnh chứa dữ liệu sẽ được hệ thống đọc vì hệ thống IO trên đĩa của chúng tôi ghi và đọc dữ liệu trong các khối. Vì vậy, trong trường hợp truy vấn phạm vi, rất có thể dữ liệu sắp xếp được lưu vào bộ nhớ đệm. Giả sử bạn kích hoạt truy vấn sau:
SELECT * FROM index_demo WHERE phone_no > '9010000000' AND phone_no < '9020000000'
Một khối dữ liệu được tìm nạp trong bộ nhớ khi truy vấn được thực thi. Giả sử khối dữ liệu chứa phone_no trong phạm vi từ 9010000000 thành 9030000000 . Vì vậy, bất kỳ phạm vi nào bạn yêu cầu trong truy vấn chỉ là một tập hợp con của dữ liệu có trong khối. Nếu bây giờ bạn kích hoạt truy vấn tiếp theo để nhận tất cả các số điện thoại trong dải, hãy nói từ 9015000000 thành 9019000000 , bạn không cần tìm nạp thêm bất kỳ khối nào từ đĩa. Dữ liệu đầy đủ có thể được tìm thấy trong khối dữ liệu hiện tại, do đó clustered_index giảm số lượng IO của đĩa bằng cách sắp xếp dữ liệu liên quan càng nhiều càng tốt trong cùng một khối dữ liệu. IO đĩa giảm này làm cải thiện hiệu suất.
Vì vậy, nếu bạn hiểu rõ về khóa chính và các truy vấn của bạn dựa trên khóa chính, thì hiệu suất sẽ cực nhanh.
Ràng buộc của Clustered Index:
Vì chỉ mục được phân nhóm ảnh hưởng đến tổ chức vật lý của dữ liệu, nên chỉ có thể có một chỉ mục được phân nhóm trên mỗi bảng.
Mối quan hệ giữa Khóa chính &Chỉ mục nhóm:
Bạn không thể tạo chỉ mục nhóm theo cách thủ công bằng cách sử dụng InnoDB trong MySQL. MySQL chọn nó cho bạn. Nhưng nó chọn như thế nào? Các đoạn trích sau là từ tài liệu MySQL:
Khi bạn xác định mộtPRIMARY KEYtrên bàn của bạn,InnoDBsử dụng nó làm chỉ mục được phân cụm. Xác định khóa chính cho mỗi bảng mà bạn tạo. Nếu không có cột hoặc cột duy nhất hợp lý và không rỗng hoặc tập hợp các cột, hãy thêm một cột tăng tự động mới, có các giá trị được điền tự động.
Nếu bạn không xác địnhPRIMARY KEYcho bảng của bạn, MySQL định vịUNIQUEđầu tiên chỉ mục trong đó tất cả các cột chính làNOT NULLvàInnoDBsử dụng nó làm chỉ mục được phân cụm.
Nếu bảng không cóPRIMARY KEYhoặc phù hợpUNIQUEchỉ mục,InnoDBnội bộ tạo chỉ mục nhóm ẩn có tênGEN_CLUST_INDEXtrên một cột tổng hợp có chứa các giá trị ID hàng. Các hàng được sắp xếp theo IDInnoDBgán cho các hàng trong một bảng như vậy. ID hàng là một trường 6 byte tăng đơn điệu khi các hàng mới được chèn vào. Do đó, các hàng được sắp xếp theo ID hàng về mặt vật lý theo thứ tự chèn.
Nói tóm lại, công cụ MySQL InnoDB thực sự quản lý chỉ mục chính dưới dạng chỉ mục được phân cụm để cải thiện hiệu suất, vì vậy khóa chính và bản ghi thực tế trên đĩa được nhóm lại với nhau.
Cấu trúc của Chỉ mục khóa chính (nhóm):
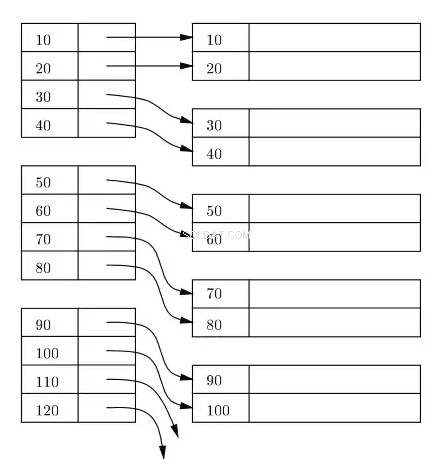
Một chỉ mục thường được duy trì dưới dạng B + Tree trên đĩa &trong bộ nhớ, và bất kỳ chỉ mục nào cũng được lưu trữ trong các khối trên đĩa. Các khối này được gọi là khối chỉ mục. Các mục nhập trong khối chỉ mục luôn được sắp xếp trên khóa chỉ mục / tìm kiếm. Khối chỉ mục lá của chỉ mục chứa bộ định vị hàng. Đối với chỉ mục chính, bộ định vị hàng đề cập đến địa chỉ ảo của vị trí vật lý tương ứng của các khối dữ liệu trên đĩa nơi các hàng nằm được sắp xếp theo khóa chỉ mục.
Trong sơ đồ sau, các hình chữ nhật bên trái đại diện cho các khối chỉ mục mức lá và các hình chữ nhật bên phải đại diện cho các khối dữ liệu. Về mặt logic, các khối dữ liệu trông được căn chỉnh theo thứ tự được sắp xếp, nhưng như đã được mô tả trước đó, các vị trí thực tế có thể nằm rải rác ở đây và ở đó.
Có thể tạo chỉ mục chính trên khóa không phải khóa chính không?
Trong MySQL, một chỉ mục chính được tạo tự động và chúng ta đã mô tả ở trên cách MySQL chọn chỉ mục chính. Nhưng trong thế giới cơ sở dữ liệu, thực sự không cần thiết phải tạo chỉ mục trên cột khóa chính - chỉ mục chính cũng có thể được tạo trên bất kỳ cột không phải khóa chính nào. Nhưng khi được tạo trên khóa chính, tất cả các mục nhập khóa là duy nhất trong chỉ mục, trong khi trong trường hợp khác, chỉ mục chính cũng có thể có một khóa trùng lặp.
Có thể xóa khóa chính không?
Có thể xóa khóa chính. Khi bạn xóa khóa chính, chỉ mục được nhóm có liên quan cũng như thuộc tính duy nhất của cột đó sẽ bị mất.
ALTER TABLE `index_demo` DROP PRIMARY KEY;
- If the primary key does not exist, you get the following error:
"ERROR 1091 (42000): Can't DROP 'PRIMARY'; check that column/key exists"Ưu điểm của Chỉ mục Chính:
- Các truy vấn phạm vi dựa trên chỉ mục chính rất hiệu quả. Có thể có khả năng khối đĩa mà cơ sở dữ liệu đã đọc từ đĩa chứa tất cả dữ liệu thuộc về truy vấn, vì chỉ mục chính được phân nhóm &các bản ghi được sắp xếp theo thứ tự vật lý. Vì vậy, vị trí của dữ liệu có thể được cung cấp bởi chỉ mục chính.
- Bất kỳ truy vấn nào tận dụng khóa chính đều rất nhanh.
Nhược điểm của Chỉ mục Chính:
- Vì chỉ mục chính chứa tham chiếu trực tiếp đến địa chỉ khối dữ liệu thông qua không gian địa chỉ ảo &các khối đĩa được tổ chức vật lý theo thứ tự của khóa chỉ mục, mỗi khi Hệ điều hành thực hiện chia nhỏ trang đĩa nào đó do
DMLcác thao tác nhưINSERT/UPDATE/DELETE, chỉ mục chính cũng cần được cập nhật. Vì vậy,DMLhoạt động gây áp lực lên hiệu suất của chỉ mục chính.
Chỉ mục phụ:
Bất kỳ chỉ mục nào khác với chỉ mục được phân nhóm được gọi là chỉ mục thứ cấp. Các chỉ số phụ không ảnh hưởng đến các vị trí lưu trữ vật lý không giống như các chỉ số chính.
Khi nào bạn cần Chỉ mục phụ?
Bạn có thể có một số trường hợp sử dụng trong ứng dụng của mình trong đó bạn không truy vấn cơ sở dữ liệu bằng khóa chính. Trong ví dụ của chúng tôi phone_no là khóa chính nhưng chúng tôi có thể cần truy vấn cơ sở dữ liệu bằng pan_no hoặc name . Trong những trường hợp như vậy, bạn cần các chỉ mục phụ trên các cột này nếu tần suất của các truy vấn như vậy rất cao.
Cách tạo chỉ mục phụ trong MySQL?
Lệnh sau tạo chỉ mục phụ trong name trong index_demo bảng.
CREATE INDEX secondary_idx_1 ON index_demo (name);
Cấu trúc của Chỉ mục phụ:
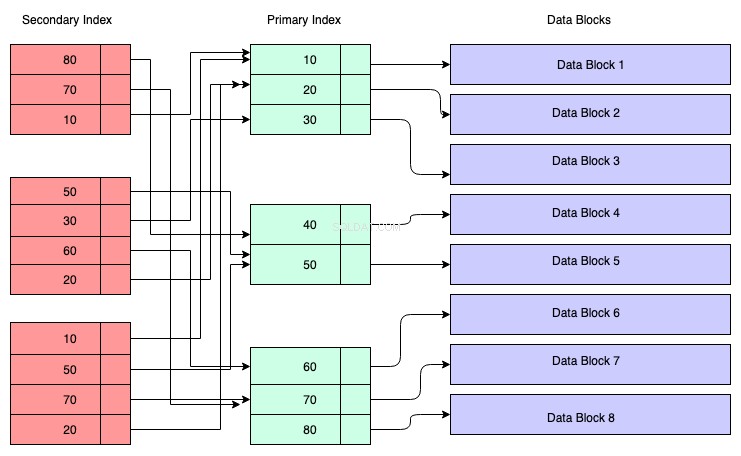
Trong sơ đồ bên dưới, các hình chữ nhật màu đỏ đại diện cho các khối chỉ mục phụ. Chỉ mục phụ cũng được duy trì trong B + Tree và nó được sắp xếp theo khóa mà chỉ mục được tạo. Các nút lá chứa một bản sao của khóa của dữ liệu tương ứng trong chỉ mục chính.
Vì vậy, để hiểu, bạn có thể giả định rằng chỉ mục phụ có tham chiếu đến địa chỉ của khóa chính, mặc dù không phải vậy. Truy xuất dữ liệu thông qua chỉ mục phụ có nghĩa là bạn phải duyệt qua hai cây B + - một cây là chính cây B + chỉ mục phụ và cây kia là cây B + chỉ mục chính.
Ưu điểm của Chỉ mục phụ:
Về mặt logic, bạn có thể tạo bao nhiêu chỉ mục phụ tùy thích. Nhưng trên thực tế, có bao nhiêu chỉ số thực sự được yêu cầu thì cần một quá trình suy nghĩ nghiêm túc vì mỗi chỉ số có hình phạt riêng.
Nhược điểm của Chỉ mục phụ:
Với DML các thao tác như DELETE / INSERT , chỉ mục phụ cũng cần được cập nhật để có thể xóa / chèn bản sao của cột khóa chính. Trong những trường hợp như vậy, sự tồn tại của nhiều chỉ mục phụ có thể tạo ra vấn đề.
Ngoài ra, nếu khóa chính rất lớn như URL , vì các chỉ mục phụ chứa bản sao của giá trị cột khóa chính, nên nó có thể không hiệu quả về mặt lưu trữ. Nhiều khóa phụ hơn có nghĩa là số lượng bản sao trùng lặp của giá trị cột khóa chính nhiều hơn, do đó, nhiều bộ nhớ hơn trong trường hợp có khóa chính lớn. Ngoài ra, bản thân khóa chính cũng lưu trữ các khóa, do đó, hiệu quả tổng hợp đối với việc lưu trữ sẽ rất cao.
Cân nhắc trước khi bạn xóa Chỉ mục chính:
Trong MySQL, bạn có thể xóa chỉ mục chính bằng cách bỏ khóa chính. Chúng ta đã thấy rằng một chỉ mục phụ phụ thuộc vào một chỉ mục chính. Vì vậy, nếu bạn xóa một chỉ mục chính, tất cả các chỉ mục phụ phải được cập nhật để chứa một bản sao của khóa chỉ mục chính mới mà MySQL tự động điều chỉnh.
Quá trình này tốn kém khi tồn tại một số chỉ mục thứ cấp. Ngoài ra, các bảng khác có thể có tham chiếu khóa ngoại đến khóa chính, vì vậy bạn cần xóa các tham chiếu khóa ngoại đó trước khi xóa khóa chính.
Khi khóa chính bị xóa, MySQL sẽ tự động tạo một khóa chính khác trong nội bộ và đó là một hoạt động tốn kém.
Chỉ mục chính DUY NHẤT:
Giống như khóa chính, khóa duy nhất cũng có thể xác định các bản ghi duy nhất bằng một điểm khác biệt - cột khóa duy nhất có thể chứa null giá trị.
Không giống như các máy chủ cơ sở dữ liệu khác, trong MySQL, một cột khóa duy nhất có thể có nhiều null giá trị nhất có thể. Trong tiêu chuẩn SQL, null nghĩa là một giá trị không xác định. Vì vậy, nếu MySQL chỉ phải chứa một null trong một cột khóa duy nhất, nó phải giả định rằng tất cả các giá trị null đều giống nhau.
Nhưng về mặt logic thì điều này không đúng vì null có nghĩa là không xác định - và các giá trị không xác định không thể được so sánh với nhau, đó là bản chất của null . Vì MySQL không thể khẳng định nếu tất cả null có nghĩa là giống nhau, nó cho phép nhiều null giá trị trong cột.
Lệnh sau cho biết cách tạo một chỉ mục khóa duy nhất trong MySQL:
CREATE UNIQUE INDEX unique_idx_1 ON index_demo (pan_no);
Chỉ mục tổng hợp:
MySQL cho phép bạn xác định các chỉ số trên nhiều cột, tối đa 16 cột. Chỉ mục này được gọi là chỉ mục Nhiều cột / Tổng hợp / Kết hợp.
Giả sử chúng ta có một chỉ mục được xác định trên 4 cột - col1 , col2 , col3 , col4 . Với chỉ mục tổng hợp, chúng tôi có khả năng tìm kiếm trên col1 , (col1, col2) , (col1, col2, col3) , (col1, col2, col3, col4) . Vì vậy, chúng tôi có thể sử dụng bất kỳ tiền tố bên trái nào của các cột được lập chỉ mục, nhưng chúng tôi không thể bỏ qua một cột ở giữa và sử dụng như - (col1, col3) hoặc (col1, col2, col4) hoặc col3 hoặc col4 v.v ... Đây là những kết hợp không hợp lệ.
Các lệnh sau tạo 2 chỉ mục tổng hợp trong bảng của chúng ta:
CREATE INDEX composite_index_1 ON index_demo (phone_no, name, age);
CREATE INDEX composite_index_2 ON index_demo (pan_no, name, age);
Nếu bạn có các truy vấn chứa WHERE mệnh đề trên nhiều cột, ghi mệnh đề theo thứ tự các cột của chỉ số tổng hợp. Chỉ mục sẽ có lợi cho truy vấn đó. Trên thực tế, trong khi quyết định các cột cho chỉ mục tổng hợp, bạn có thể phân tích các trường hợp sử dụng khác nhau của hệ thống và cố gắng đưa ra thứ tự các cột sẽ có lợi cho hầu hết các trường hợp sử dụng của bạn.
Các chỉ số tổng hợp có thể giúp bạn trong JOIN &SELECT truy vấn. Ví dụ:trong SELECT * sau truy vấn, composite_index_2 được sử dụng.

Khi một số chỉ mục được xác định, trình tối ưu hóa truy vấn MySQL sẽ chọn chỉ mục đó để loại bỏ số lượng hàng lớn nhất hoặc quét càng ít hàng càng tốt để có hiệu quả tốt hơn.
Tại sao chúng tôi sử dụng chỉ số tổng hợp ? Tại sao không xác định nhiều chỉ số phụ trên các cột mà chúng ta quan tâm?
MySQL chỉ sử dụng một chỉ mục cho mỗi bảng cho mỗi truy vấn ngoại trừ UNION. (Trong UNION, mỗi truy vấn logic được chạy riêng biệt và kết quả được hợp nhất.) Vì vậy, việc xác định nhiều chỉ số trên nhiều cột không đảm bảo các chỉ số đó sẽ được sử dụng ngay cả khi chúng là một phần của truy vấn.
MySQL duy trì một thứ gọi là thống kê chỉ mục giúp MySQL suy ra dữ liệu trông như thế nào trong hệ thống. Mặc dù vậy, thống kê chỉ mục là sự tổng hợp hóa, nhưng dựa trên dữ liệu meta này, MySQL quyết định chỉ mục nào phù hợp cho truy vấn hiện tại.
Chỉ mục tổng hợp hoạt động như thế nào?
Các cột được sử dụng trong chỉ mục tổng hợp được nối với nhau và các khóa được nối đó được lưu trữ theo thứ tự được sắp xếp bằng cách sử dụng B + Tree. Khi bạn thực hiện tìm kiếm, việc nối các khóa tìm kiếm của bạn được khớp với các khóa của chỉ mục tổng hợp. Sau đó, nếu có bất kỳ sự không khớp nào giữa thứ tự các khóa tìm kiếm của bạn và thứ tự của các cột chỉ mục tổng hợp, thì bạn không thể sử dụng chỉ mục đó.
Trong ví dụ của chúng tôi, đối với bản ghi sau, một khóa chỉ mục tổng hợp được tạo bằng cách nối pan_no , name , age - HJKXS9086Wkousik28 .
+--------+------+------------+------------+
name
age
pan_no
phone_no
+--------+------+------------+------------+
kousik
28
HJKXS9086W
9090909090Cách xác định xem bạn có cần chỉ mục tổng hợp hay không:
- Trước tiên hãy phân tích các truy vấn của bạn theo các trường hợp sử dụng của bạn. Nếu bạn thấy một số trường nhất định xuất hiện cùng nhau trong nhiều truy vấn, bạn có thể cân nhắc tạo chỉ mục tổng hợp.
- Nếu bạn đang tạo chỉ mục trong
col1&một chỉ mục tổng hợp trong (col1,col2), thì chỉ có chỉ số tổng hợp là ổn.col1riêng chỉ mục tổng hợp có thể được phân phát bởi chính chỉ mục tổng hợp vì nó là tiền tố bên trái của chỉ mục. - Xem xét bản số. Nếu các cột được sử dụng trong chỉ mục tổng hợp có số lượng cao với nhau, thì chúng là ứng cử viên tốt cho chỉ mục tổng hợp.
Chỉ mục bao gồm:
Chỉ mục bao trùm là một loại chỉ mục tổng hợp đặc biệt trong đó tất cả các cột được chỉ định trong truy vấn ở đâu đó tồn tại trong chỉ mục. Vì vậy, trình tối ưu hóa truy vấn không cần phải nhấn vào cơ sở dữ liệu để lấy dữ liệu - thay vào đó nó lấy kết quả từ chính chỉ mục. Ví dụ:chúng tôi đã xác định một chỉ mục tổng hợp trên (pan_no, name, age) , vì vậy bây giờ hãy xem xét truy vấn sau:
SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = 'kousik'
Các cột được đề cập trong SELECT &WHERE mệnh đề là một phần của chỉ mục tổng hợp. Vì vậy, trong trường hợp này, chúng ta thực sự có thể nhận được giá trị của age từ chính chỉ mục tổng hợp. Hãy xem EXPLAIN lệnh hiển thị cho truy vấn này:
EXPLAIN FORMAT=JSON SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = '111kousik1';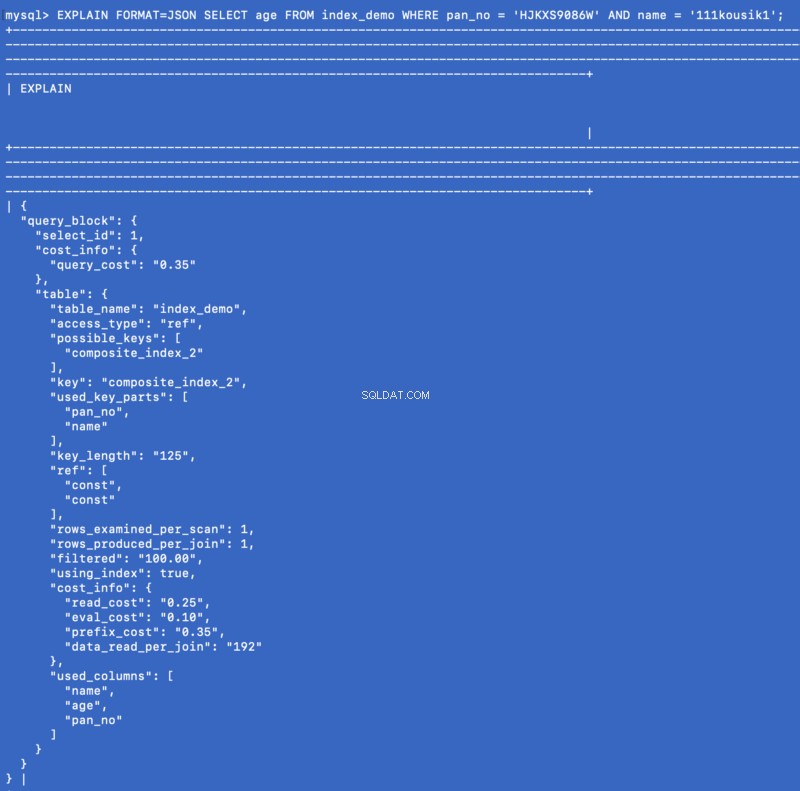
Trong câu trả lời trên, hãy lưu ý rằng có một khóa - using_index được đặt thành true biểu thị rằng chỉ mục bao trùm đã được sử dụng để trả lời truy vấn.
Tôi không biết các chỉ số bao trùm được đánh giá cao như thế nào trong môi trường sản xuất, nhưng rõ ràng đây có vẻ là một cách tối ưu hóa tốt trong trường hợp truy vấn phù hợp với hóa đơn.
Chỉ mục một phần:
Chúng tôi đã biết rằng các Chỉ số tăng tốc các truy vấn của chúng tôi với chi phí là không gian. Bạn càng có nhiều chỉ số, yêu cầu lưu trữ càng nhiều. Chúng tôi đã tạo một chỉ mục có tên là secondary_idx_1 trên cột name . Cột name có thể chứa các giá trị lớn có độ dài bất kỳ. Cũng trong chỉ mục, siêu dữ liệu của trình định vị hàng hoặc con trỏ hàng có kích thước riêng. Vì vậy, về tổng thể, một chỉ mục có thể có tải trọng bộ nhớ và bộ nhớ cao.
Trong MySQL, bạn cũng có thể tạo chỉ mục trên một vài byte dữ liệu đầu tiên. Ví dụ:lệnh sau tạo một chỉ mục trên 4 byte đầu tiên của tên. Mặc dù phương pháp này làm giảm chi phí bộ nhớ xuống một lượng nhất định, chỉ mục không thể loại bỏ nhiều hàng, vì trong ví dụ này, 4 byte đầu tiên có thể phổ biến trên nhiều tên. Thường thì loại lập chỉ mục tiền tố này được hỗ trợ trên CHAR , VARCHAR , BINARY , VARBINARY loại cột.
CREATE INDEX secondary_index_1 ON index_demo (name(4));Điều gì xảy ra khi chúng tôi xác định một chỉ mục?
Hãy chạy SHOW EXTENDED lệnh một lần nữa:
SHOW EXTENDED INDEXES FROM index_demo;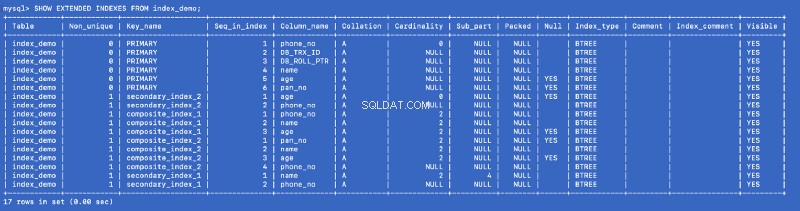
Chúng tôi đã xác định secondary_index_1 trên name , nhưng MySQL đã tạo một chỉ mục tổng hợp trên (name , phone_no ) ở đâu phone_no là cột khóa chính. Chúng tôi đã tạo secondary_index_2 trên age &MySQL đã tạo một chỉ mục tổng hợp trên (age , phone_no ). Chúng tôi đã tạo composite_index_2 trên (pan_no , name , age ) &MySQL đã tạo một chỉ mục tổng hợp trên (pan_no , name , age , phone_no ). Chỉ mục tổng hợp composite_index_1 đã có phone_no như một phần của nó.
Vì vậy, bất kỳ chỉ mục nào chúng tôi tạo, MySQL trong nền sẽ tạo ra một chỉ mục tổng hợp hỗ trợ mà lần lượt trỏ đến khóa chính. Điều này có nghĩa là khóa chính là công dân hạng nhất trong thế giới lập chỉ mục MySQL. It also proves that all the indexes are backed by a copy of the primary index —but I am not sure whether a single copy of the primary index is shared or different copies are used for different indexes.
There are many other indices as well like Spatial index and Full Text Search index offered by MySQL. I have not yet experimented with those indices, so I’m not discussing them in this post.
General Indexing guidelines:
- Since indices consume extra memory, carefully decide how many &what type of index will suffice your need.
- With
DMLoperations, indices are updated, so write operations are quite costly with indexes. The more indices you have, the greater the cost. Indexes are used to make read operations faster. So if you have a system that is write heavy but not read heavy, think hard about whether you need an index or not. - Cardinality is important — cardinality means the number of distinct values in a column. If you create an index in a column that has low cardinality, that’s not going to be beneficial since the index should reduce search space. Low cardinality does not significantly reduce search space.
Example:if you create an index on a boolean (int1or0only ) type column, the index will be very skewed since cardinality is less (cardinality is 2 here). But if this boolean field can be combined with other columns to produce high cardinality, go for that index when necessary. - Indices might need some maintenance as well if old data still remains in the index. They need to be deleted otherwise memory will be hogged, so try to have a monitoring plan for your indices.
In the end, it’s extremely important to understand the different aspects of database indexing. It will help while doing low level system designing. Many real-life optimizations of our applications depend on knowledge of such intricate details. A carefully chosen index will surely help you boost up your application’s performance.
Please do clap &share with your friends &on social media if you like this article. :)
References:
- https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
- https://www.quora.com/What-is-difference-between-primary-index-and-secondary-index-exactly-And-whats-advantage-of-one-over-another
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html
- https://www.oreilly.com/library/view/high-performance-mysql/0596003064/ch04.html
- https://www.unofficialmysqlguide.com/covering-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/multiple-column-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/show-index.html
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html