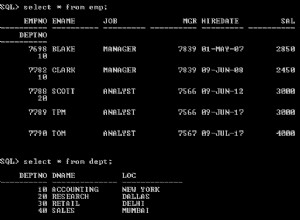
Đã xảy ra lỗi nghiêm trọng khi truy vấn của bạn mất 2 giờ để thực thi khi tôi có thể thực hiện điều tương tự trong vòng chưa đầy 60 giây trên phần cứng tương tự.
Một số điều sau đây có thể hữu ích ...
Điều chỉnh MySQL cho công cụ của bạn
Kiểm tra cấu hình máy chủ của bạn và tối ưu hóa cho phù hợp. Một số tài nguyên sau đây sẽ hữu ích.
- http ://www.mysqlperformanceblog.com/2006/09/29/what-to-tune-in-mysql-server- after-installation/
- https://www.mysqlperformanceblog.com/
- https://www.highperfmysql.com/
- https://forge.mysql.com/wiki/ServerVariables
- https://dev.mysql. com / doc / refman / 5.0 / en / server-system-variable.html
- http:/ /www.xaprb.com/blog/2006/07/04/how-to-exploit-mysql-index-optimizations/
- https://jpipes.com/presentations/perf_tuning_best_practices.pdf
- https://jpipes.com/presentations/index_coding_optimization.pdf
- https://www.jasny.net/?p=36
Bây giờ để ít rõ ràng hơn ...
Cân nhắc sử dụng quy trình đã lưu trữ để xử lý phía máy chủ dữ liệu
Tại sao không xử lý tất cả dữ liệu bên trong MySQL để bạn không phải gửi một lượng lớn dữ liệu đến lớp ứng dụng của mình? Ví dụ sau sử dụng con trỏ để lặp lại và xử lý 50 triệu hàng phía máy chủ trong vòng chưa đầy 2 phút. Tôi không phải là người thích dùng con trỏ, đặc biệt là trong MySQL, nơi chúng rất hạn chế, nhưng tôi đoán bạn đang lặp lại tập kết quả và thực hiện một số dạng phân tích số, vì vậy việc sử dụng con trỏ là hợp lý trong trường hợp này.
Bảng kết quả myisam được đơn giản hóa - các khóa dựa trên của bạn.
drop table if exists results_1mregr_c_ew_f;
create table results_1mregr_c_ew_f
(
id int unsigned not null auto_increment primary key,
rc tinyint unsigned not null,
df int unsigned not null default 0,
val double(10,4) not null default 0,
ts timestamp not null default now(),
key (rc, df)
)
engine=myisam;
Tôi đã tạo 100 triệu hàng dữ liệu với các trường khóa có cùng số lượng như trong ví dụ của bạn:
show indexes from results_1mregr_c_ew_f;
Table Non_unique Key_name Seq_in_index Column_name Collation Cardinality Index_type
===== ========== ======== ============ =========== ========= =========== ==========
results_1mregr_c_ew_f 0 PRIMARY 1 id A 100000000 BTREE
results_1mregr_c_ew_f 1 rc 1 rc A 2 BTREE
results_1mregr_c_ew_f 1 rc 2 df A 223 BTREE
Quy trình được lưu trữ
Tôi đã tạo một thủ tục được lưu trữ đơn giản để tìm nạp dữ liệu cần thiết và xử lý nó (sử dụng cùng điều kiện where như ví dụ của bạn)
drop procedure if exists process_results_1mregr_c_ew_f;
delimiter #
create procedure process_results_1mregr_c_ew_f
(
in p_rc tinyint unsigned,
in p_df int unsigned
)
begin
declare v_count int unsigned default 0;
declare v_done tinyint default 0;
declare v_id int unsigned;
declare v_result_cur cursor for select id from results_1mregr_c_ew_f where rc = p_rc and df > p_df;
declare continue handler for not found set v_done = 1;
open v_result_cur;
repeat
fetch v_result_cur into v_id;
set v_count = v_count + 1;
-- do work...
until v_done end repeat;
close v_result_cur;
select v_count as counter;
end #
delimiter ;
Các thời gian chạy sau đã được quan sát thấy:
call process_results_1mregr_c_ew_f(0,60);
runtime 1 = 03:24.999 Query OK (3 mins 25 secs)
runtime 2 = 03:32.196 Query OK (3 mins 32 secs)
call process_results_1mregr_c_ew_f(1,60);
runtime 1 = 04:59.861 Query OK (4 mins 59 secs)
runtime 2 = 04:41.814 Query OK (4 mins 41 secs)
counter
========
23000002 (23 million rows processed in each case)
Hmmmm, hiệu suất hơi thất vọng nên hãy lên ý tưởng tiếp theo.
Cân nhắc sử dụng engine innodb (sốc kinh dị)
Tại sao innodb ?? bởi vì nó có các chỉ mục được phân cụm! Bạn sẽ thấy việc chèn chậm hơn bằng cách sử dụng innodb nhưng hy vọng nó sẽ đọc nhanh hơn vì vậy đó là một sự đánh đổi có thể đáng giá.
Việc truy cập một hàng thông qua chỉ mục được phân nhóm rất nhanh vì dữ liệu hàng nằm trên cùng một trang mà tìm kiếm chỉ mục dẫn đầu. Nếu một bảng lớn, kiến trúc chỉ mục nhóm thường lưu hoạt động I / O trên đĩa khi so sánh với các tổ chức lưu trữ lưu trữ dữ liệu hàng bằng cách sử dụng một trang khác với bản ghi chỉ mục. Ví dụ:MyISAM sử dụng một hàng tệp fordata và một hàng khác cho các bản ghi chỉ mục.
Thông tin thêm tại đây:
Bảng kết quả innodb được đơn giản hóa
drop table if exists results_innodb;
create table results_innodb
(
rc tinyint unsigned not null,
df int unsigned not null default 0,
id int unsigned not null, -- cant auto_inc this !!
val double(10,4) not null default 0,
ts timestamp not null default now(),
primary key (rc, df, id) -- note clustered (innodb only !) composite PK
)
engine=innodb;
Một vấn đề với innodb là không hỗ trợ các trường auto_increment tạo thành một phần của khóa tổng hợp, vì vậy bạn phải tự cung cấp giá trị khóa tăng dần bằng cách sử dụng trình tạo trình tự, trình kích hoạt hoặc một số phương pháp khác - có thể trong ứng dụng tự điền bảng kết quả ??
Một lần nữa, tôi đã tạo 100 triệu hàng dữ liệu với các trường khóa có cùng số lượng như trong ví dụ của bạn. Đừng lo lắng nếu những số liệu này không khớp với ví dụ myisam vì innodb ước tính các thẻ số để chúng sẽ không hoàn toàn giống nhau. (nhưng chúng là - cùng một tập dữ liệu được sử dụng)
show indexes from results_innodb;
Table Non_unique Key_name Seq_in_index Column_name Collation Cardinality Index_type
===== ========== ======== ============ =========== ========= =========== ==========
results_innodb 0 PRIMARY 1 rc A 18 BTREE
results_innodb 0 PRIMARY 2 df A 18 BTREE
results_innodb 0 PRIMARY 3 id A 100000294 BTREE
Quy trình được lưu trữ
Quy trình được lưu trữ giống hệt như ví dụ myisam ở trên nhưng thay vào đó chọn dữ liệu từ bảng innodb.
declare v_result_cur cursor for select id from results_innodb where rc = p_rc and df > p_df;
Kết quả như sau:
call process_results_innodb(0,60);
runtime 1 = 01:53.407 Query OK (1 mins 53 secs)
runtime 2 = 01:52.088 Query OK (1 mins 52 secs)
call process_results_innodb(1,60);
runtime 1 = 02:01.201 Query OK (2 mins 01 secs)
runtime 2 = 01:49.737 Query OK (1 mins 50 secs)
counter
========
23000002 (23 million rows processed in each case)
nhanh hơn khoảng 2-3 phút hơn việc triển khai công cụ myisam! (innodb FTW)
Chia rẽ và chinh phục
Xử lý kết quả trong thủ tục được lưu trữ phía máy chủ sử dụng con trỏ có thể không phải là giải pháp tối ưu, đặc biệt là MySQL không hỗ trợ những thứ như mảng và cấu trúc dữ liệu phức tạp sẵn có bằng các ngôn ngữ 3GL như C #, v.v. hoặc thậm chí trong các cơ sở dữ liệu khác như như Oracle PL / SQL.
Vì vậy, ý tưởng ở đây là trả về các lô dữ liệu cho một lớp ứng dụng (C # bất kỳ), sau đó có thể thêm kết quả vào cấu trúc dữ liệu dựa trên tập hợp và sau đó xử lý dữ liệu trong nội bộ.
Quy trình được lưu trữ
Thủ tục được lưu trữ có 3 tham số rc, df_low và df_high cho phép bạn chọn một dải dữ liệu như sau:
call list_results_innodb(0,1,1); -- df 1
call list_results_innodb(0,1,10); -- df between 1 and 10
call list_results_innodb(0,60,120); -- df between 60 and 120 etc...
rõ ràng là dải df càng cao thì bạn sẽ trích xuất được nhiều dữ liệu hơn.
drop procedure if exists list_results_innodb;
delimiter #
create procedure list_results_innodb
(
in p_rc tinyint unsigned,
in p_df_low int unsigned,
in p_df_high int unsigned
)
begin
select rc, df, id from results_innodb where rc = p_rc and df between p_df_low and p_df_high;
end #
delimiter ;
Tôi cũng đã gõ một phiên bản myisam giống hệt nhau ngoại trừ bảng được sử dụng.
call list_results_1mregr_c_ew_f(0,1,1);
call list_results_1mregr_c_ew_f(0,1,10);
call list_results_1mregr_c_ew_f(0,60,120);
Dựa trên ví dụ con trỏ ở trên, tôi hy vọng phiên bản innodb sẽ hoạt động tốt hơn phiên bản myisam.
Tôi đã phát triển ra một nhanh chóng và bẩn thỉu ứng dụng C # đa luồng sẽ gọi quy trình được lưu trữ và thêm kết quả vào bộ sưu tập để xử lý truy vấn bài đăng. Bạn không phải sử dụng các chuỗi, cùng một phương pháp truy vấn theo lô có thể được thực hiện tuần tự mà không làm giảm nhiều hiệu suất.
Mỗi luồng (QueryThread) chọn một dải dữ liệu df, lặp lại tập kết quả và thêm từng kết quả (hàng) vào tập hợp kết quả.
class Program
{
static void Main(string[] args)
{
const int MAX_THREADS = 12;
const int MAX_RC = 120;
List<AutoResetEvent> signals = new List<AutoResetEvent>();
ResultDictionary results = new ResultDictionary(); // thread safe collection
DateTime startTime = DateTime.Now;
int step = (int)Math.Ceiling((double)MAX_RC / MAX_THREADS) -1;
int start = 1, end = 0;
for (int i = 0; i < MAX_THREADS; i++){
end = (i == MAX_THREADS - 1) ? MAX_RC : end + step;
signals.Add(new AutoResetEvent(false));
QueryThread st = new QueryThread(i,signals[i],results,0,start,end);
start = end + 1;
}
WaitHandle.WaitAll(signals.ToArray());
TimeSpan runTime = DateTime.Now - startTime;
Console.WriteLine("{0} results fetched and looped in {1} secs\nPress any key", results.Count, runTime.ToString());
Console.ReadKey();
}
}
Thời gian chạy được quan sát như sau:
Thread 04 done - 31580517
Thread 06 done - 44313475
Thread 07 done - 45776055
Thread 03 done - 46292196
Thread 00 done - 47008566
Thread 10 done - 47910554
Thread 02 done - 48194632
Thread 09 done - 48201782
Thread 05 done - 48253744
Thread 08 done - 48332639
Thread 01 done - 48496235
Thread 11 done - 50000000
50000000 results fetched and looped in 00:00:55.5731786 secs
Press any key
Vì vậy, 50 triệu hàng đã được tìm nạp và thêm vào bộ sưu tập trong vòng chưa đầy 60 giây.
Tôi đã thử điều tương tự bằng cách sử dụng quy trình được lưu trữ myisam, mất 2 phút để hoàn thành.
50000000 results fetched and looped in 00:01:59.2144880 secs
Chuyển sang innodb
Trong hệ thống đơn giản của tôi, bảng myisam hoạt động không quá tệ vì vậy nó có thể không đáng để chuyển sang innodb. Nếu bạn quyết định sao chép dữ liệu kết quả của mình vào một bảng innodb thì hãy làm như sau:
start transaction;
insert into results_innodb
select <fields...> from results_1mregr_c_ew_f order by <innodb primary key>;
commit;
Việc sắp xếp kết quả bằng PK innodb trước khi chèn và gói toàn bộ nội dung trong một giao dịch sẽ đẩy nhanh tiến độ.
Tôi hy vọng một số điều này sẽ hữu ích.
Chúc các bạn thành công