Trong bài trước, chúng ta đã thảo luận về cách xác minh rằng MySQL Replication đang hoạt động tốt. Chúng tôi cũng đã xem xét một số vấn đề điển hình. Trong bài đăng này, chúng ta sẽ xem xét thêm một số vấn đề mà bạn có thể gặp khi xử lý bản sao MySQL.
Các mục nhập bị thiếu hoặc trùng lặp
Đây là điều không nên xảy ra, nhưng nó rất thường xuyên xảy ra - một tình huống trong đó một câu lệnh SQL được thực thi trên master thành công nhưng câu lệnh tương tự được thực thi trên một trong các nô lệ lại không thành công. Lý do chính là sự trôi dạt của nô lệ - một cái gì đó (thường là các giao dịch sai sót nhưng cũng có các vấn đề khác hoặc lỗi trong quá trình sao chép) khiến nô lệ khác với chủ của nó. Ví dụ:một hàng tồn tại trên cái chính không tồn tại trên hàng phụ và nó không thể bị xóa hoặc cập nhật. Tần suất vấn đề này xuất hiện chủ yếu phụ thuộc vào cài đặt sao chép của bạn. Tóm lại, có ba cách mà MySQL lưu trữ các sự kiện nhật ký nhị phân. Đầu tiên, “câu lệnh”, có nghĩa là SQL được viết bằng văn bản thuần túy, giống như nó đã được thực thi trên một cái chính. Cài đặt này có dung sai cao nhất đối với sự trôi dạt của nô lệ nhưng cũng là cài đặt không thể đảm bảo tính nhất quán của nô lệ - rất khó để khuyến nghị sử dụng nó trong sản xuất. Định dạng thứ hai, “hàng”, lưu trữ kết quả truy vấn thay vì câu lệnh truy vấn. Ví dụ:một sự kiện có thể trông giống như dưới đây:
### UPDATE `test`.`tab`
### WHERE
### @1=2
### @2=5
### SET
### @1=2
### @2=4Điều này có nghĩa là chúng tôi đang cập nhật một hàng trong bảng 'tab' trong lược đồ 'thử nghiệm' trong đó cột đầu tiên có giá trị là 2 và cột thứ hai có giá trị là 5. Chúng tôi đặt cột đầu tiên thành 2 (giá trị không thay đổi) và cột thứ hai cột đến 4. Như bạn có thể thấy, không có nhiều chỗ để giải thích - nó được xác định chính xác hàng nào được sử dụng và cách hàng đó được thay đổi. Do đó, định dạng này rất phù hợp để đảm bảo tính nhất quán của nô lệ, nhưng như bạn có thể tưởng tượng, nó rất dễ bị ảnh hưởng khi bị trôi dữ liệu. Tuy nhiên, đó là cách được khuyến nghị để chạy bản sao MySQL.
Cuối cùng, cái thứ ba, “hỗn hợp”, hoạt động theo cách mà những sự kiện an toàn để viết dưới dạng câu lệnh sử dụng định dạng “câu lệnh”. Những thứ có thể gây ra sự trôi dạt dữ liệu sẽ sử dụng định dạng "hàng".
Làm cách nào để bạn phát hiện ra chúng?
Như thường lệ, HIỂN THỊ TRẠNG THÁI CHẬM sẽ giúp chúng tôi xác định sự cố.
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000021, end_log_pos 970 Last_SQL_Errno: 1062
Last_SQL_Error: Could not execute Write_rows event on table test.tab; Duplicate entry '3' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log binlog.000021, end_log_pos 1229Như bạn có thể thấy, các lỗi rất rõ ràng và dễ hiểu (và về cơ bản chúng giống hệt nhau giữa MySQL và MariaDB.
Làm cách nào để bạn khắc phục sự cố?
Đây, thật không may là phần phức tạp. Trước hết, bạn cần xác định một nguồn gốc của sự thật. Máy chủ nào chứa dữ liệu chính xác? Chủ nhân hay nô lệ? Thông thường, bạn sẽ cho rằng đó là chính nhưng đừng cho rằng đó là chủ đề theo mặc định - hãy điều tra! Có thể là sau khi chuyển đổi dự phòng, một số phần của ứng dụng vẫn được phát hành các bản ghi cho chủ cũ, hiện hoạt động như một nô lệ. Có thể là read_only chưa được đặt chính xác trên máy chủ đó hoặc có thể ứng dụng sử dụng superuser để kết nối với cơ sở dữ liệu (vâng, chúng tôi đã thấy điều này trong môi trường sản xuất). Trong trường hợp đó, nô lệ có thể là nguồn gốc của sự thật - ít nhất là ở một mức độ nào đó.
Tùy thuộc vào dữ liệu nào sẽ ở lại và dữ liệu nào sẽ chuyển đi, cách hành động tốt nhất sẽ là xác định những gì cần thiết để đồng bộ hóa trở lại. Trước hết, sự sao chép bị phá vỡ, vì vậy bạn cần phải tham gia vào điều này. Đăng nhập vào trang cái và kiểm tra nhật ký nhị phân ngay cả khi bản sao bị hỏng.
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106672
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106671Như bạn có thể thấy, chúng tôi bỏ lỡ một sự kiện:5d1e2227-07c6-11e7-8123-080027495a77:1106672. Hãy kiểm tra nó trong nhật ký nhị phân của trang cái:
mysqlbinlog -v --include-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1106672' /var/lib/mysql/binlog.000021
#170320 20:53:37 server id 1 end_log_pos 1066 CRC32 0xc582a367 GTID last_committed=3 sequence_number=4
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672'/*!*/;
# at 1066
#170320 20:53:37 server id 1 end_log_pos 1138 CRC32 0x6f33754d Query thread_id=5285 exec_time=0 error_code=0
SET TIMESTAMP=1490043217/*!*/;
SET @@session.pseudo_thread_id=5285/*!*/;
SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/;
SET @@session.sql_mode=1436549152/*!*/;
SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;
BEGIN
/*!*/;
# at 1138
#170320 20:53:37 server id 1 end_log_pos 1185 CRC32 0xa00b1f59 Table_map: `test`.`tab` mapped to number 571
# at 1185
#170320 20:53:37 server id 1 end_log_pos 1229 CRC32 0x5597e50a Write_rows: table id 571 flags: STMT_END_F
BINLOG '
UUHQWBMBAAAALwAAAKEEAAAAADsCAAAAAAEABHRlc3QAA3RhYgACAwMAAlkfC6A=
UUHQWB4BAAAALAAAAM0EAAAAADsCAAAAAAEAAgAC//wDAAAABwAAAArll1U=
'/*!*/;
### INSERT INTO `test`.`tab`
### SET
### @1=3
### @2=7
# at 1229
#170320 20:53:37 server id 1 end_log_pos 1260 CRC32 0xbbc3367c Xid = 5224257
COMMIT/*!*/;Chúng ta có thể thấy đó là một chèn đặt cột đầu tiên thành 3 và cột thứ hai thành 7. Hãy xác minh xem bảng của chúng ta trông như thế nào bây giờ:
mysql> SELECT * FROM test.tab;
+----+------+
| id | b |
+----+------+
| 1 | 2 |
| 2 | 4 |
| 3 | 10 |
+----+------+
3 rows in set (0.01 sec)Bây giờ chúng tôi có hai tùy chọn, tùy thuộc vào dữ liệu nào sẽ chiếm ưu thế. Nếu dữ liệu chính xác nằm trên cái chính, chúng ta có thể chỉ cần xóa hàng có id =3 trên phụ. Chỉ cần đảm bảo rằng bạn tắt tính năng ghi nhật ký nhị phân để tránh giới thiệu các giao dịch sai lầm. Mặt khác, nếu chúng ta quyết định rằng dữ liệu chính xác nằm trên máy chủ, chúng ta cần chạy lệnh REPLACE trên máy chủ để đặt hàng có id =3 để sửa nội dung của (3, 10) từ hiện tại (3, 7). Tuy nhiên, trên nô lệ, chúng ta sẽ phải bỏ qua GTID hiện tại (hoặc nói chính xác hơn, chúng ta sẽ phải tạo một sự kiện GTID trống) để có thể khởi động lại quá trình sao chép.
Xóa một hàng trên nô lệ rất đơn giản:
SET SESSION log_bin=0; DELETE FROM test.tab WHERE id=3; SET SESSION log_bin=1;Việc chèn GTID trống gần như đơn giản:
mysql> SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672';
Query OK, 0 rows affected (0.00 sec)mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)mysql> COMMIT;
Query OK, 0 rows affected (0.00 sec)mysql> SET @@SESSION.GTID_NEXT=automatic;
Query OK, 0 rows affected (0.00 sec)Một phương pháp khác để giải quyết vấn đề cụ thể này (miễn là chúng tôi chấp nhận chính là nguồn chân lý) là sử dụng các công cụ như pt-table-checksum và pt-table-sync để xác định nơi nào nô lệ không nhất quán với chủ của nó và cái gì SQL phải được thực thi trên cái chính để đưa nô lệ trở lại đồng bộ. Thật không may, phương pháp này khá nặng nề - rất nhiều tải được thêm vào master và một loạt các truy vấn được ghi vào luồng sao chép có thể ảnh hưởng đến độ trễ trên nô lệ và hiệu suất chung của thiết lập sao chép. Điều này đặc biệt đúng nếu có một số lượng đáng kể các hàng cần được đồng bộ hóa.
Cuối cùng, như mọi khi, bạn có thể xây dựng lại nô lệ của mình bằng cách sử dụng dữ liệu từ chính - bằng cách này, bạn có thể chắc chắn rằng nô lệ sẽ được làm mới với dữ liệu mới nhất, cập nhật. Thực ra, đây không hẳn là một ý tưởng tồi - khi chúng ta đang nói về số lượng lớn các hàng để đồng bộ hóa bằng cách sử dụng pt-table-checksum / pt-table-sync, điều này đi kèm với chi phí đáng kể trong hiệu suất sao chép, CPU tổng thể và I / O tải và giờ công cần thiết.
ClusterControl cho phép bạn xây dựng lại một nô lệ, sử dụng một bản sao mới của dữ liệu chính.
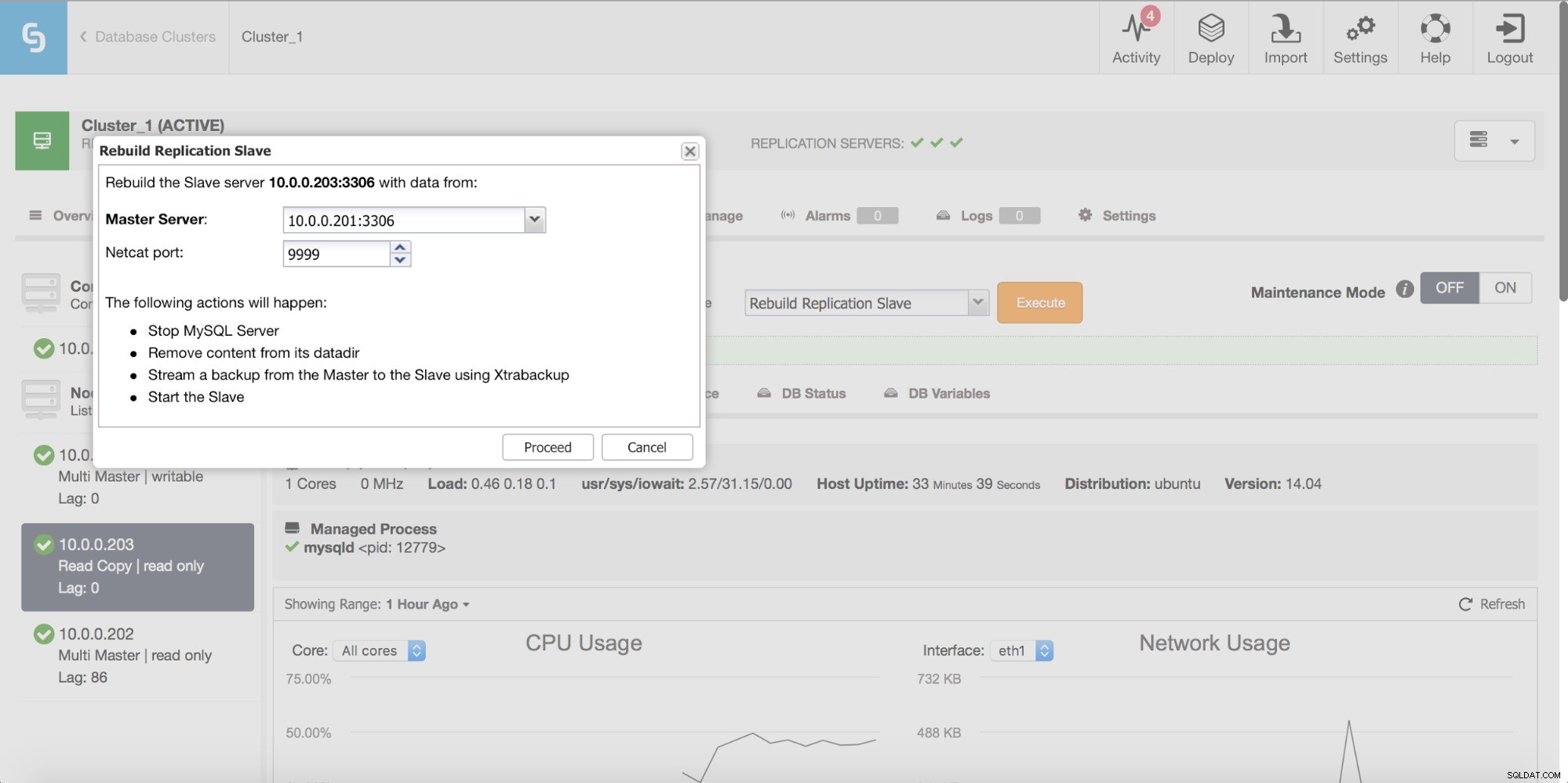
Kiểm tra tính nhất quán
Như chúng ta đã đề cập trong chương trước, tính nhất quán có thể trở thành một vấn đề nghiêm trọng và có thể gây ra nhiều đau đầu cho người dùng đang chạy các thiết lập sao chép MySQL. Hãy xem cách bạn có thể xác minh rằng các nô lệ MySQL của bạn có đồng bộ với trang cái và bạn có thể làm gì với nó.
Cách phát hiện nô lệ không nhất quán
Thật không may, cách thông thường mà người dùng biết rằng nô lệ là không nhất quán là gặp phải một trong những vấn đề mà chúng tôi đã đề cập trong chương trước. Để tránh việc giám sát chủ động tính nhất quán của nô lệ là cần thiết. Hãy kiểm tra xem nó có thể được thực hiện như thế nào.
Chúng tôi sẽ sử dụng một công cụ từ Bộ công cụ Percona:pt-table-checksum. Nó được thiết kế để quét cụm sao chép và xác định bất kỳ sự khác biệt nào.
Chúng tôi đã xây dựng một kịch bản tùy chỉnh bằng cách sử dụng sysbench và chúng tôi đã đưa ra một chút không nhất quán trên một trong các nô lệ. Điều quan trọng (nếu bạn muốn kiểm tra nó như chúng tôi đã làm), bạn cần áp dụng một bản vá bên dưới để buộc pt-table-checksum nhận dạng giản đồ ‘sbtest’ là giản đồ không thuộc hệ thống:
--- pt-table-checksum 2016-12-15 14:31:07.000000000 +0000
+++ pt-table-checksum-fix 2017-03-21 20:32:53.282254794 +0000
@@ -7614,7 +7614,7 @@
my $filter = $self->{filters};
- if ( $db =~ m/information_schema|performance_schema|lost\+found|percona|percona_schema|test/ ) {
+ if ( $db =~ m/information_schema|performance_schema|lost\+found|percona|percona_schema|^test/ ) {
PTDEBUG && _d('Database', $db, 'is a system database, ignoring');
return 0;
}Đầu tiên, chúng ta sẽ thực thi pt-table-checksum theo cách sau:
master:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T20:33:30 0 0 1000000 15 0 27.103 sbtest.sbtest1
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2
03-21T20:34:26 0 0 1000000 15 0 28.503 sbtest.sbtest3
03-21T20:34:52 0 0 1000000 18 0 26.021 sbtest.sbtest4
03-21T20:35:34 0 0 1000000 17 0 42.730 sbtest.sbtest5
03-21T20:36:04 0 0 1000000 16 0 29.309 sbtest.sbtest6
03-21T20:36:42 0 0 1000000 15 0 38.071 sbtest.sbtest7
03-21T20:37:16 0 0 1000000 12 0 33.737 sbtest.sbtest8Một số lưu ý quan trọng về cách chúng tôi sử dụng công cụ. Trước hết, người dùng mà chúng tôi đặt phải tồn tại trên tất cả các nô lệ. Nếu muốn, bạn cũng có thể sử dụng ‘--slave-user’ để xác định người dùng khác, ít đặc quyền hơn để truy cập nô lệ. Một điều đáng giải thích khác - chúng tôi sử dụng sao chép dựa trên hàng không hoàn toàn tương thích với pt-table-checksum. Nếu bạn có sao chép dựa trên hàng, điều xảy ra là pt-table-checksum sẽ thay đổi định dạng nhật ký nhị phân ở cấp độ phiên thành ‘câu lệnh’ vì đây là định dạng duy nhất được hỗ trợ. Vấn đề là sự thay đổi như vậy sẽ chỉ hoạt động trên cấp độ đầu tiên của các nô lệ được kết nối trực tiếp với chủ. Nếu bạn có bậc thầy trung gian (vì vậy, nhiều hơn một cấp độ nô lệ), việc sử dụng pt-table-checksum có thể phá vỡ bản sao. Đây là lý do tại sao, theo mặc định, nếu công cụ phát hiện sao chép dựa trên hàng, nó sẽ thoát và in lỗi:
“Replica slave1 có binlog_format ROW có thể khiến pt-table-checksum phá vỡ sao chép. Vui lòng đọc "Bản sao bằng cách sử dụng sao chép dựa trên hàng" trong phần GIỚI HẠN của tài liệu của công cụ. Nếu bạn hiểu các rủi ro, hãy chỉ định --no-check-binlog-format để vô hiệu hóa việc kiểm tra này. ”
Chúng tôi chỉ sử dụng một cấp nô lệ nên có thể an toàn khi chỉ định “--no-check-binlog-format” và tiếp tục.
Cuối cùng, chúng tôi đặt độ trễ tối đa thành 5 giây. Nếu đạt đến ngưỡng này, pt-table-checksum sẽ tạm dừng trong một thời gian cần thiết để giảm độ trễ xuống dưới ngưỡng.
Như bạn có thể thấy từ đầu ra,
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2một sự không nhất quán đã được phát hiện trên bảng sbtest.sbtest2.
Theo mặc định, pt-table-checksum lưu trữ tổng kiểm tra trong bảng percona.checksums. Dữ liệu này có thể được sử dụng cho một công cụ khác từ Bộ công cụ Percona, pt-table-sync, để xác định những phần nào của bảng cần được kiểm tra chi tiết để tìm ra sự khác biệt chính xác về dữ liệu.
Cách khắc phục Nô lệ không nhất quán
Như đã đề cập ở trên, chúng tôi sẽ sử dụng pt-table-sync để làm điều đó. Trong trường hợp của chúng tôi, chúng tôi sẽ sử dụng dữ liệu được thu thập bởi pt-table-checksum mặc dù cũng có thể trỏ pt-table-sync đến hai máy chủ (chính và một máy chủ) và nó sẽ so sánh tất cả dữ liệu trên cả hai máy chủ. Do đó, đây chắc chắn là quá trình tốn nhiều thời gian và tài nguyên hơn, miễn là bạn đã có dữ liệu từ pt-table-checksum, thì tốt hơn là bạn nên sử dụng nó. Đây là cách chúng tôi thực thi nó để kiểm tra đầu ra:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=master --printREPLACE INTO `sbtest`.`sbtest2`(`id`, `k`, `c`, `pad`) VALUES ('1', '434041', '61753673565-14739672440-12887544709-74227036147-86382758284-62912436480-22536544941-50641666437-36404946534-73544093889', '23608763234-05826685838-82708573685-48410807053-00139962956') /*percona-toolkit src_db:sbtest src_tbl:sbtest2 src_dsn:h=10.0.0.101,p=...,u=sbtest dst_db:sbtest dst_tbl:sbtest2 dst_dsn:h=10.0.0.103,p=...,u=sbtest lock:1 transaction:1 changing_src:percona.checksums replicate:percona.checksums bidirectional:0 pid:25776 user:root host:vagrant-ubuntu-trusty-64*/;Như bạn có thể thấy, kết quả là một số SQL đã được tạo ra. Điều quan trọng cần lưu ý là biến --replicate. Điều xảy ra ở đây là chúng ta trỏ pt-table-sync đến bảng được tạo bởi pt-table-checksum. Chúng tôi cũng chỉ ra nó để làm chủ.
Để xác minh xem SQL có hợp lý không, chúng tôi đã sử dụng tùy chọn --print. Xin lưu ý rằng SQL được tạo chỉ hợp lệ tại thời điểm nó được tạo - bạn thực sự không thể lưu trữ nó ở đâu đó, hãy xem lại nó và sau đó thực thi. Tất cả những gì bạn có thể làm là xác minh xem SQL có hợp lý hay không và ngay sau đó, thực hiện lại công cụ với cờ --execute:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=10.0.0.101 --executeĐiều này sẽ làm cho nô lệ trở lại đồng bộ với chủ. Chúng tôi có thể xác minh điều đó bằng pt-table-checksum:
example@sqldat.com:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T21:36:04 0 0 1000000 13 0 23.749 sbtest.sbtest1
03-21T21:36:26 0 0 1000000 7 0 22.333 sbtest.sbtest2
03-21T21:36:51 0 0 1000000 10 0 24.780 sbtest.sbtest3
03-21T21:37:11 0 0 1000000 14 0 19.782 sbtest.sbtest4
03-21T21:37:42 0 0 1000000 15 0 30.954 sbtest.sbtest5
03-21T21:38:07 0 0 1000000 15 0 25.593 sbtest.sbtest6
03-21T21:38:27 0 0 1000000 16 0 19.339 sbtest.sbtest7
03-21T21:38:44 0 0 1000000 15 0 17.371 sbtest.sbtest8Như bạn có thể thấy, không còn khác biệt trong bảng sbtest.sbtest2.
Chúng tôi hy vọng bạn thấy bài đăng trên blog này có nhiều thông tin và hữu ích. Nhấp vào đây để tìm hiểu thêm về MySQL Replication. Nếu bạn có bất kỳ câu hỏi hoặc đề xuất nào, vui lòng liên hệ với chúng tôi thông qua các bình luận bên dưới.



