Bạn có thể đã nghe nói về thuật ngữ “chuyển đổi dự phòng” trong ngữ cảnh sao chép MySQL. Có thể bạn tự hỏi nó là gì khi bạn đang bắt đầu cuộc phiêu lưu của mình với cơ sở dữ liệu. Có thể bạn biết nó là gì nhưng bạn không chắc về những vấn đề tiềm ẩn liên quan đến nó và cách chúng có thể được giải quyết?
Trong bài đăng trên blog này, chúng tôi sẽ cố gắng giới thiệu cho bạn cách xử lý chuyển đổi dự phòng trong MySQL &MariaDB.
Chúng ta sẽ thảo luận về chuyển đổi dự phòng là gì, tại sao nó không thể tránh khỏi, sự khác biệt giữa chuyển đổi dự phòng và chuyển đổi là gì. Chúng ta sẽ thảo luận về quá trình chuyển đổi dự phòng ở dạng chung nhất. Chúng tôi cũng sẽ đề cập một chút về các vấn đề khác nhau mà bạn sẽ phải giải quyết liên quan đến quá trình chuyển đổi dự phòng.
“Chuyển đổi dự phòng” có nghĩa là gì?
Bản sao MySQL là một tập hợp các nút, mỗi nút có thể phục vụ một vai trò tại một thời điểm. Nó có thể trở thành một bản chính hoặc một bản sao. Chỉ có một nút chính tại một thời điểm nhất định. Nút này nhận lưu lượng ghi và nó sao chép ghi vào các bản sao của nó.
Như bạn có thể tưởng tượng, là một điểm nhập dữ liệu duy nhất vào cụm sao chép, nút chính là khá quan trọng. Điều gì sẽ xảy ra nếu nó không thành công và không khả dụng?
Đây là một điều kiện khá nghiêm trọng cho một cụm sao chép. Nó không thể chấp nhận bất kỳ ghi nào tại một thời điểm nhất định. Như bạn có thể mong đợi, một trong những bản sao sẽ phải đảm nhận nhiệm vụ của bản chính và bắt đầu chấp nhận ghi. Phần còn lại của cấu trúc liên kết sao chép cũng có thể phải thay đổi - các bản sao còn lại sẽ thay đổi nút chính của chúng từ nút cũ bị lỗi sang nút mới được chọn. Quá trình “thúc đẩy” một bản sao trở thành bản chính sau khi bản chính cũ bị lỗi được gọi là “chuyển đổi dự phòng”.
Mặt khác, "chuyển đổi" xảy ra khi người dùng kích hoạt quảng cáo bản sao. Một bản chính mới được thăng cấp từ một bản sao do người dùng chỉ ra và bản sao cũ, thông thường, trở thành một bản sao cho bản chính mới.
Sự khác biệt quan trọng nhất giữa “chuyển đổi dự phòng” và “chuyển đổi” là trạng thái của bản chính cũ. Khi thực hiện chuyển đổi dự phòng, theo một cách nào đó, bản gốc cũ không thể truy cập được. Nó có thể đã bị rơi, nó có thể đã bị phân vùng mạng. Nó không thể được sử dụng tại một thời điểm nhất định và trạng thái của nó, thường là, không xác định.
Mặt khác, khi một chuyển đổi được thực hiện, chủ cũ vẫn còn sống và khỏe mạnh. Điều này gây ra hậu quả nghiêm trọng. Nếu không thể truy cập được một bản gốc, điều đó có thể có nghĩa là một số dữ liệu vẫn chưa được gửi đến các nô lệ (trừ khi sử dụng sao chép bán đồng bộ). Một số dữ liệu có thể đã bị hỏng hoặc được gửi một phần.
Có những cơ chế được áp dụng để tránh lan truyền những lỗi như vậy trên nô lệ nhưng vấn đề là một số dữ liệu có thể bị mất trong quá trình xử lý. Mặt khác, trong khi thực hiện chuyển đổi, bản chính cũ sẽ khả dụng và dữ liệu được duy trì nhất quán.
Quá trình chuyển đổi dự phòng
Hãy dành thời gian thảo luận về cách chính xác của quá trình chuyển đổi dự phòng.
Sự cố chính được phát hiện
Đối với người mới bắt đầu, một bản gốc phải gặp sự cố trước khi quá trình chuyển đổi dự phòng được thực hiện. Khi nó không có sẵn, chuyển đổi dự phòng sẽ được kích hoạt. Cho đến nay, điều đó có vẻ đơn giản nhưng sự thật là chúng ta đang ở trên mặt đất trơn trượt.
Trước hết, kiểm tra sức khỏe tổng thể như thế nào? Nó được kiểm tra từ một vị trí hay các bài kiểm tra được phân phối? Phần mềm quản lý chuyển đổi dự phòng chỉ cố gắng kết nối với phần mềm chính hay nó thực hiện các xác minh nâng cao hơn trước khi thông báo lỗi chính?
Hãy hình dung cấu trúc liên kết sau:
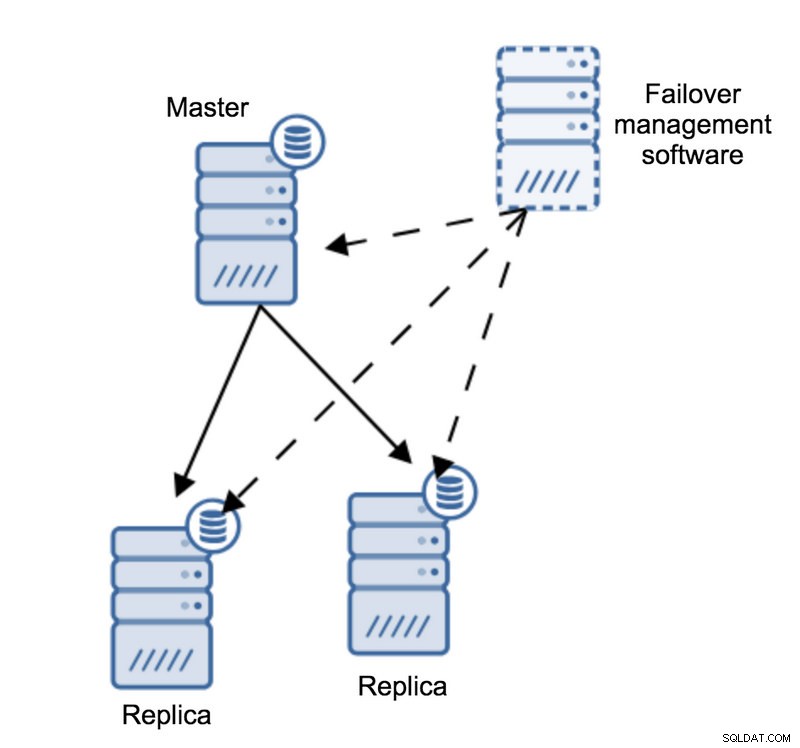
Chúng tôi có một bản chính và hai bản sao. Chúng tôi cũng có một phần mềm quản lý chuyển đổi dự phòng nằm trên một số máy chủ bên ngoài. Điều gì sẽ xảy ra nếu kết nối mạng giữa máy chủ có phần mềm chuyển đổi dự phòng và máy chủ không thành công?
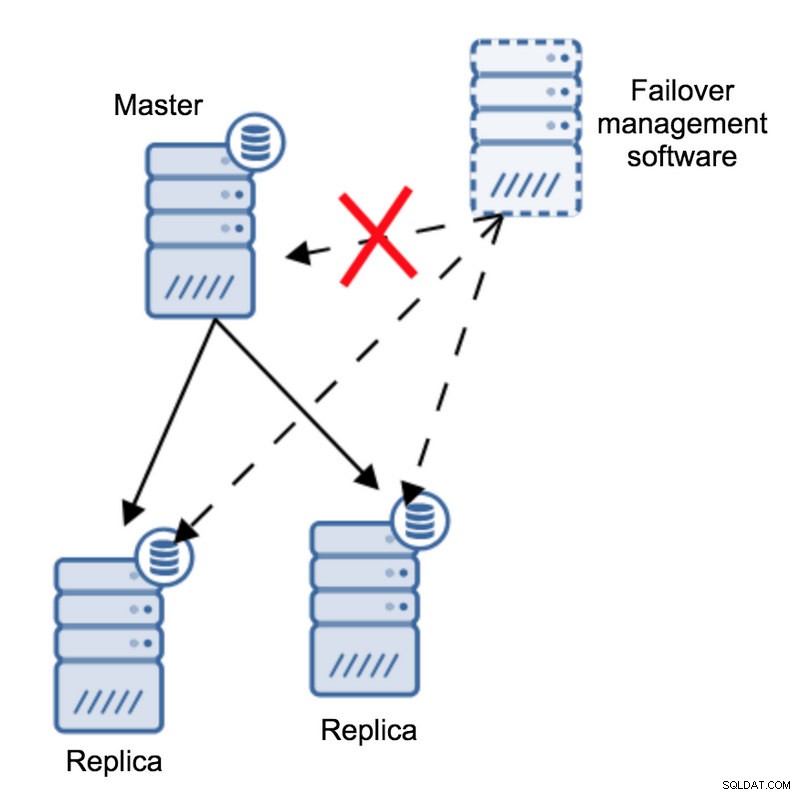
Theo phần mềm quản lý chuyển đổi dự phòng, bản chính đã bị lỗi - không có kết nối với nó. Tuy nhiên, bản thân bản sao vẫn hoạt động tốt. Điều sẽ xảy ra ở đây là phần mềm quản lý chuyển đổi dự phòng sẽ cố gắng kết nối với các bản sao và xem quan điểm của họ là gì.
Họ phàn nàn về một bản sao bị hỏng hay họ đang vui vẻ sao chép lại?
Mọi thứ có thể trở nên phức tạp hơn. Điều gì sẽ xảy ra nếu chúng tôi thêm một proxy (hoặc một tập hợp các proxy)? Nó sẽ được sử dụng để định tuyến lưu lượng - ghi vào master và đọc cho các bản sao. Điều gì sẽ xảy ra nếu một proxy không thể truy cập chính? Điều gì sẽ xảy ra nếu không có proxy nào có thể truy cập trang chủ?
Điều này có nghĩa là ứng dụng không thể hoạt động trong những điều kiện đó. Có nên kích hoạt chuyển đổi dự phòng không (thực ra, nó giống như một bộ chuyển đổi vì thiết bị chính vẫn còn sống về mặt kỹ thuật) được kích hoạt?
Về mặt kỹ thuật, bản chính vẫn còn sống nhưng nó không thể được sử dụng bởi ứng dụng. Ở đây, logic kinh doanh phải được đưa ra và phải đưa ra quyết định.
Ngăn Chủ cũ Chạy
Bất kể bằng cách nào và tại sao, nếu có quyết định thăng cấp một trong các bản sao trở thành bản sao mới, bản chính cũ phải bị dừng lại và lý tưởng nhất là không thể bắt đầu lại.
Làm thế nào điều này có thể đạt được phụ thuộc vào các chi tiết của môi trường cụ thể; do đó, phần này của quy trình chuyển đổi dự phòng thường được củng cố bằng các tập lệnh bên ngoài được tích hợp vào quy trình chuyển đổi dự phòng thông qua các móc khác nhau.
Các tập lệnh đó có thể được thiết kế để sử dụng các công cụ có sẵn trong môi trường cụ thể để ngăn chặn chương trình chính cũ. Nó có thể là một lệnh gọi CLI hoặc API sẽ dừng một máy ảo; nó có thể là mã shell chạy các lệnh thông qua một số loại thiết bị “quản lý đèn tắt”; nó có thể là một tập lệnh gửi các bẫy SNMP đến Đơn vị phân phối điện để vô hiệu hóa các ổ cắm điện mà thiết bị chính cũ đang sử dụng (nếu không có nguồn điện, chúng tôi có thể chắc chắn rằng nó sẽ không khởi động lại).
Nếu phần mềm quản lý chuyển đổi dự phòng là một phần của sản phẩm phức tạp hơn, phần mềm này cũng xử lý việc khôi phục các nút (giống như trường hợp của ClusterControl), phần mềm chính cũ có thể được đánh dấu là bị loại trừ khỏi quy trình khôi phục.
Bạn có thể thắc mắc tại sao việc ngăn không cho chủ cũ thêm một lần nữa lại quan trọng như vậy?
Vấn đề chính là trong thiết lập nhân bản, chỉ có một nút có thể được sử dụng để ghi. Thông thường, bạn đảm bảo rằng bằng cách bật biến read_only (và super_read_only, nếu có) trên tất cả các bản sao và chỉ tắt nó trên bản chính.
Khi một trang cái mới được thăng cấp, nó sẽ bị vô hiệu hóa read_only. Vấn đề là, nếu cái cũ không khả dụng, chúng ta không thể chuyển nó trở lại read_only =1. Nếu MySQL hoặc máy chủ bị sự cố, đây không phải là vấn đề nhiều vì các phương pháp hay là phải định cấu hình my.cnf với cài đặt đó, khi MySQL khởi động, nó luôn bắt đầu ở chế độ chỉ đọc.
Sự cố hiển thị khi đó không phải là sự cố mà là sự cố mạng. Trang chủ cũ vẫn đang chạy với read_only bị vô hiệu hóa, nó chỉ là không khả dụng. Khi các mạng hội tụ, bạn sẽ có hai nút có thể ghi. Đây có thể là một vấn đề. Một số proxy sử dụng cài đặt read_only như một chỉ báo cho dù một nút là nút chính hay bản sao. Hai máy chủ xuất hiện tại thời điểm nhất định có thể dẫn đến một vấn đề lớn vì dữ liệu được ghi vào cả hai máy chủ, nhưng các bản sao chỉ nhận được một nửa lưu lượng ghi (phần tiếp cận với bản chính mới).
Đôi khi đó là về cài đặt mã cứng trong một số tập lệnh được định cấu hình để chỉ kết nối với một máy chủ nhất định. Thông thường chúng sẽ không thành công và ai đó sẽ nhận thấy rằng cái chính đã thay đổi.
Khi có chủ cũ, họ sẽ vui vẻ kết nối với nó và sự khác biệt về dữ liệu sẽ phát sinh. Như bạn có thể thấy, đảm bảo rằng bản chính cũ sẽ không khởi động là một mục có mức độ ưu tiên cao.
Quyết định ứng cử viên chính
Chủ cũ đã mất và nó sẽ không trở lại từ nấm mồ của nó, bây giờ đã đến lúc quyết định chúng ta nên sử dụng máy chủ nào làm chủ mới. Thông thường có nhiều hơn một bản sao để chọn, vì vậy cần phải đưa ra quyết định. Có nhiều lý do tại sao một bản sao có thể được chọn thay cho bản sao khác, do đó phải thực hiện kiểm tra.
Danh sách trắng và danh sách đen
Đối với người mới bắt đầu, một nhóm quản lý cơ sở dữ liệu có thể có lý do để chọn một bản sao thay vì một bản sao khác khi quyết định về một ứng cử viên chính. Có thể nó đang sử dụng phần cứng yếu hơn hoặc có một số công việc cụ thể được giao cho nó (bản sao đó chạy sao lưu, truy vấn phân tích, nhà phát triển có quyền truy cập vào nó và chạy các truy vấn tùy chỉnh, được làm thủ công). Có thể đó là một bản sao thử nghiệm trong đó một phiên bản mới đang trải qua các bài kiểm tra chấp nhận trước khi tiếp tục nâng cấp. Hầu hết phần mềm quản lý chuyển đổi dự phòng đều hỗ trợ danh sách trắng và danh sách đen, có thể được sử dụng để xác định chính xác bản sao nào nên hoặc không thể sử dụng làm ứng viên chính.
Sao chép bán đồng bộ
Thiết lập sao chép có thể là sự kết hợp của các bản sao không đồng bộ và bán đồng bộ. Có một sự khác biệt rất lớn giữa chúng - bản sao bán đồng bộ được đảm bảo chứa tất cả các sự kiện từ bản chính. Một bản sao không đồng bộ có thể không nhận được tất cả dữ liệu do đó nếu không thực hiện được nó có thể dẫn đến mất dữ liệu. Chúng tôi muốn thấy các bản sao bán đồng bộ được thúc đẩy.
Độ trễ sao chép
Mặc dù một bản sao bán đồng bộ sẽ chứa tất cả các sự kiện, những sự kiện đó vẫn có thể chỉ nằm trong các bản ghi chuyển tiếp. Với lưu lượng truy cập lớn, tất cả các bản sao, bất kể là bán đồng bộ hay không đồng bộ, đều có thể bị trễ.
Vấn đề với độ trễ của bản sao là khi bạn quảng bá bản sao, bạn nên đặt lại cài đặt sao chép để nó không cố gắng kết nối với bản chính cũ. Thao tác này cũng sẽ xóa tất cả nhật ký chuyển tiếp, ngay cả khi chúng chưa được áp dụng - dẫn đến mất dữ liệu.
Ngay cả khi bạn không đặt lại cài đặt sao chép, bạn vẫn không thể mở một cái chính mới cho các kết nối nếu nó chưa áp dụng tất cả các sự kiện từ nhật ký chuyển tiếp của nó. Nếu không, bạn sẽ gặp rủi ro rằng các truy vấn mới sẽ ảnh hưởng đến các giao dịch từ nhật ký chuyển tiếp, gây ra tất cả các loại vấn đề (ví dụ:một ứng dụng có thể xóa một số hàng được truy cập bởi các giao dịch từ nhật ký chuyển tiếp).
Xem xét tất cả những điều này, lựa chọn an toàn duy nhất là đợi nhật ký chuyển tiếp được áp dụng. Tuy nhiên, có thể mất một lúc nếu bản sao bị tụt hậu nặng. Phải đưa ra quyết định xem bản sao nào sẽ tạo ra bản chính tốt hơn - không đồng bộ, nhưng có độ trễ nhỏ hoặc bán đồng bộ, nhưng với độ trễ sẽ cần một lượng thời gian đáng kể để áp dụng.
Giao dịch không bình thường
Mặc dù bản sao không nên được ghi vào, vẫn có thể xảy ra trường hợp ai đó (hoặc một cái gì đó) đã viết cho nó.
Trước đây, nó có thể chỉ là một cách giao dịch duy nhất, nhưng nó vẫn có thể ảnh hưởng nghiêm trọng đến khả năng thực hiện chuyển đổi dự phòng. Vấn đề này hoàn toàn liên quan đến ID giao dịch toàn cầu (GTID), một tính năng chỉ định một ID riêng biệt cho mọi giao dịch được thực hiện trên một nút MySQL nhất định.
Ngày nay, đây là một thiết lập khá phổ biến vì nó mang lại mức độ linh hoạt cao và cho phép hiệu suất tốt hơn (với các bản sao đa luồng).
Vấn đề nằm ở chỗ, trong khi tái tạo thành bản chính mới, bản sao GTID yêu cầu tất cả các sự kiện từ bản chính đó (chưa được thực thi trên bản sao) phải được sao chép sang bản sao.
Chúng ta hãy xem xét tình huống sau:tại một thời điểm nào đó trong quá khứ, một bản sao đã xảy ra một bản sao. Đã lâu rồi và sự kiện này đã bị xóa khỏi nhật ký nhị phân của bản sao. Tại một thời điểm nào đó, một bản chính đã bị lỗi và bản sao được chỉ định làm bản chính mới. Tất cả các bản sao còn lại sẽ bị loại khỏi bản chính mới. Họ sẽ hỏi về các giao dịch được thực hiện trên tổng thể mới. Nó sẽ phản hồi với một danh sách các GTID đến từ bản chính cũ và một GTID duy nhất liên quan đến bản ghi cũ đó. GTID từ bản chính cũ không phải là vấn đề vì tất cả các bản sao còn lại chứa ít nhất phần lớn trong số chúng (nếu không phải là tất cả) và tất cả các sự kiện bị thiếu phải đủ gần đây để có sẵn trong nhật ký nhị phân của bản chính mới.
Trường hợp xấu nhất, một số sự kiện bị thiếu sẽ được đọc từ các bản ghi nhị phân và chuyển sang các bản sao. Vấn đề là với bản ghi cũ đó - nó chỉ xảy ra trên một máy chủ mới, trong khi nó vẫn là một bản sao, do đó nó không tồn tại trên các máy chủ còn lại. Đây là một sự kiện cũ do đó không có cách nào để lấy nó từ các bản ghi nhị phân. Do đó, không bản sao nào có thể làm nô lệ cho bản chính mới. Giải pháp duy nhất ở đây là thực hiện một thao tác thủ công và đưa một sự kiện trống với GTID có vấn đề đó lên tất cả các bản sao. Điều đó cũng có nghĩa là, tùy thuộc vào những gì đã xảy ra, các bản sao có thể không đồng bộ với bản chính mới.
Như bạn có thể thấy, điều khá quan trọng là phải theo dõi các giao dịch sai sót và xác định xem liệu có an toàn để thúc đẩy một bản sao nhất định trở thành một bản sao mới hay không. Nếu nó chứa các giao dịch sai sót, nó có thể không phải là lựa chọn tốt nhất.
Xử lý chuyển đổi dự phòng cho ứng dụng
Điều quan trọng cần ghi nhớ là chuyển mạch tổng thể, có bắt buộc hay không, có ảnh hưởng đến toàn bộ cấu trúc liên kết. Các ghi phải được chuyển hướng đến một nút mới. Điều này có thể được thực hiện theo nhiều cách và điều quan trọng là đảm bảo rằng thay đổi này càng minh bạch với ứng dụng càng tốt. Trong phần này, chúng ta sẽ xem xét một số ví dụ về cách chuyển đổi dự phòng có thể được minh bạch hóa đối với ứng dụng.
DNS
Một trong những cách mà một ứng dụng có thể được trỏ đến một ứng dụng chính là sử dụng các mục nhập DNS. Với TTL thấp, có thể thay đổi địa chỉ IP mà mục nhập DNS như ‘master.dc1.example.com’ trỏ tới. Thay đổi như vậy có thể được thực hiện thông qua các tập lệnh bên ngoài được thực thi trong quá trình chuyển đổi dự phòng.
Khám phá dịch vụ
Các công cụ như Consul hoặc etc.d cũng có thể được sử dụng để hướng lưu lượng truy cập đến một vị trí chính xác. Những công cụ như vậy có thể chứa thông tin rằng IP của chính hiện tại được đặt thành một số giá trị. Một số người trong số họ cũng cung cấp khả năng sử dụng tra cứu tên máy chủ để trỏ đến một IP chính xác. Một lần nữa, các mục nhập trong các công cụ khám phá dịch vụ phải được duy trì và một trong những cách để làm điều đó là thực hiện những thay đổi đó trong quá trình chuyển đổi dự phòng, sử dụng các hook được thực thi trên các giai đoạn khác nhau của chuyển đổi dự phòng.
Proxy
Proxy cũng có thể được sử dụng như một nguồn xác thực về cấu trúc liên kết. Nói chung, bất kể họ phát hiện ra cấu trúc liên kết bằng cách nào (nó có thể là một quá trình tự động hoặc proxy phải được cấu hình lại khi cấu trúc liên kết thay đổi), chúng phải chứa trạng thái hiện tại của chuỗi sao chép vì nếu không chúng sẽ không thể truy vấn định tuyến một cách chính xác.
Cách tiếp cận sử dụng proxy như một nguồn sự thật có thể khá phổ biến cùng với cách tiếp cận để sắp xếp proxy trên các máy chủ ứng dụng. Có rất nhiều lợi thế khi kết hợp proxy và máy chủ web:giao tiếp nhanh và an toàn bằng Unix socket, giữ một lớp bộ nhớ đệm (vì một số proxy, như ProxySQL cũng có thể thực hiện bộ nhớ đệm) gần ứng dụng. Trong trường hợp như vậy, ứng dụng chỉ cần kết nối với proxy và cho rằng nó sẽ định tuyến các truy vấn một cách chính xác.
Chuyển đổi dự phòng trong ClusterControl
ClusterControl áp dụng các phương pháp hay nhất trong ngành để đảm bảo rằng quá trình chuyển đổi dự phòng được thực hiện chính xác. Nó cũng đảm bảo rằng quá trình sẽ an toàn - các cài đặt mặc định nhằm hủy bỏ quá trình chuyển đổi dự phòng nếu các vấn đề có thể được phát hiện. Người dùng có thể ghi đè những cài đặt đó nếu họ muốn ưu tiên chuyển đổi dự phòng hơn là an toàn dữ liệu.
Sau khi ClusterControl phát hiện lỗi chính, quá trình chuyển đổi dự phòng sẽ được bắt đầu và móc chuyển đổi dự phòng đầu tiên ngay lập tức được thực thi:

Tiếp theo, tính khả dụng chính được kiểm tra.

ClusterControl thực hiện các bài kiểm tra mở rộng để đảm bảo rằng bản chính thực sự không khả dụng. Hành vi này được bật theo mặc định và nó được quản lý bởi biến sau:
replication_check_external_bf_failover
Before attempting a failover, perform extended checks by checking the slave status to detect if the master is truly down, and also check if ProxySQL (if installed) can still see the master. If the master is detected to be functioning, then no failover will be performed. Default is 1 meaning the checks are enabled.Ở bước sau, ClusterControl đảm bảo rằng cái chính cũ bị lỗi và nếu không, ClusterControl đó sẽ không cố gắng khôi phục nó:

Bước tiếp theo là xác định máy chủ lưu trữ nào có thể được sử dụng làm ứng cử viên chính. ClusterControl có kiểm tra xem danh sách trắng hay danh sách đen được xác định hay không.
Bạn có thể làm điều đó bằng cách sử dụng các biến sau trong tệp cấu hình cmon:
replication_failover_blacklist
Comma separated list of hostname:port pairs. Blacklisted servers will not be considered as a candidate during failover. replication_failover_blacklist is ignored if replication_failover_whitelist is set.replication_failover_whitelist
Comma separated list of hostname:port pairs. Only whitelisted servers will be considered as a candidate during failover. If no server on the whitelist is available (up/connected) the failover will fail. replication_failover_blacklist is ignored if replication_failover_whitelist is set.Cũng có thể cấu hình ClusterControl để tìm kiếm sự khác biệt trong bộ lọc nhật ký nhị phân trên tất cả các bản sao. Nó có thể được thực hiện bằng cách sử dụng biến replication_check_binlog_filtration_bf_failover. Theo mặc định, những kiểm tra đó bị vô hiệu hóa. ClusterControl cũng xác minh rằng không có giao dịch sai sót nào được thực hiện, điều này có thể gây ra sự cố.

Bạn cũng có thể yêu cầu ClusterControl tự động tạo lại các bản sao không thể sao chép từ bản chính mới bằng cách sử dụng cài đặt sau trong tệp cấu hình cmon:
* replication_auto_rebuild_slave:
If the SQL THREAD is stopped and error code is non-zero then the slave will be automatically rebuilt. 1 means enable, 0 means disable (default).
Sau đó, một tập lệnh thứ hai được thực thi:nó được định nghĩa trong cài đặt replication_pre_failover_script. Tiếp theo, một ứng viên trải qua quá trình chuẩn bị.


ClusterControl đợi các bản ghi làm lại được áp dụng (đảm bảo rằng việc mất dữ liệu là tối thiểu). Nó cũng kiểm tra xem có các giao dịch khác có sẵn trên các bản sao còn lại hay không, chưa được áp dụng cho ứng viên chính. Người dùng có thể kiểm soát cả hai hành vi bằng cách sử dụng các cài đặt sau trong tệp cấu hình cmon:
replication_skip_apply_missing_txs
Force failover/switchover by skipping applying transactions from other slaves. Default disabled. 1 means enabled.replication_failover_wait_to_apply_timeout
Candidate waits up to this many seconds to apply outstanding relay log (retrieved_gtids) before failing over. Default -1 seconds (wait forever). 0 means failover immediately.Như bạn có thể thấy, bạn có thể buộc chuyển đổi dự phòng mặc dù không phải tất cả các sự kiện nhật ký làm lại đều được áp dụng - nó cho phép người dùng quyết định điều gì có mức độ ưu tiên cao hơn - tính nhất quán của dữ liệu hoặc tốc độ chuyển đổi dự phòng.


Cuối cùng, cái chính được chọn và tập lệnh cuối cùng được thực thi (một tập lệnh có thể được định nghĩa là replication_post_failover_script.
Nếu bạn chưa dùng thử ClusterControl, tôi khuyến khích bạn tải xuống (miễn phí) và dùng thử.
Phát hiện chính trong ClusterControl
ClusterControl cung cấp cho bạn khả năng triển khai ngăn xếp Tính sẵn sàng cao đầy đủ bao gồm các lớp cơ sở dữ liệu và proxy. Khám phá chính luôn là một trong những vấn đề cần giải quyết.
Nó hoạt động như thế nào trong ClusterControl?
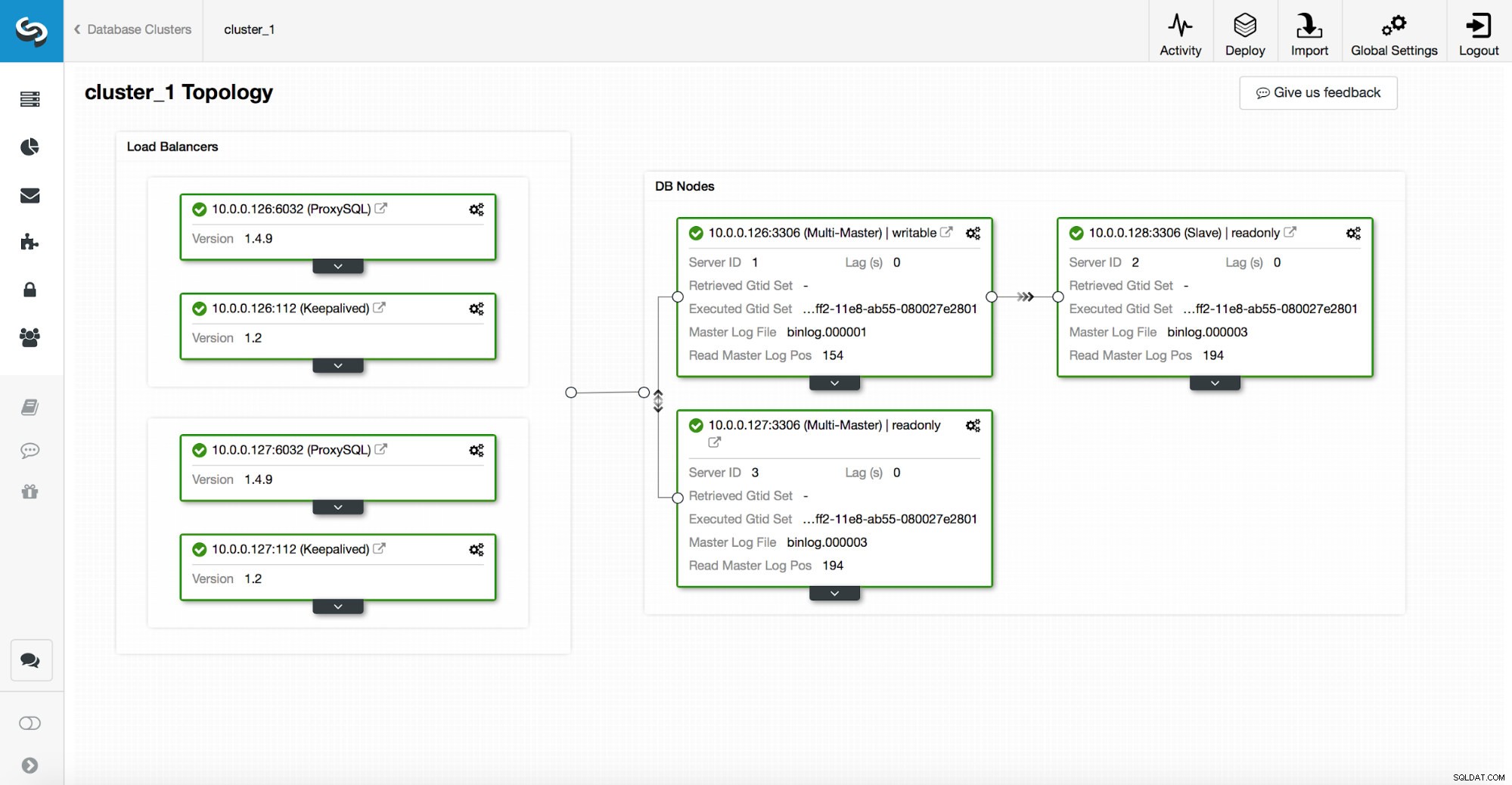
Một ngăn xếp tính khả dụng cao, được triển khai thông qua ClusterControl, bao gồm ba phần:
- lớp cơ sở dữ liệu
- lớp proxy có thể là HAProxy hoặc ProxySQL
- lớp keepalived, với việc sử dụng Virtual IP, đảm bảo tính khả dụng cao của lớp proxy
Các proxy dựa vào các biến read_only trên các nút.
Như bạn có thể thấy trong ảnh chụp màn hình ở trên, chỉ một nút trong cấu trúc liên kết được đánh dấu là “có thể ghi”. Đây là nút chính và đây là nút duy nhất nhận ghi.
Một proxy (trong ví dụ này là ProxySQL) sẽ giám sát biến này và nó sẽ tự động cấu hình lại.
Ở phía bên kia của phương trình đó, ClusterControl xử lý các thay đổi cấu trúc liên kết:chuyển đổi dự phòng và chuyển đổi. Nó sẽ thực hiện các thay đổi cần thiết trong giá trị read_only để phản ánh trạng thái của cấu trúc liên kết sau khi thay đổi. Nếu một cái chính mới được thăng cấp, nó sẽ trở thành nút duy nhất có thể ghi. Nếu một cái được chọn sau khi chuyển đổi dự phòng, nó sẽ bị vô hiệu hóa read_only.
Trên đầu lớp proxy, keepalived được triển khai. Nó triển khai VIP và nó giám sát trạng thái của các nút proxy cơ bản. VIP trỏ đến một nút proxy tại một thời điểm nhất định. Nếu nút này gặp sự cố, IP ảo sẽ được chuyển hướng đến một nút khác, đảm bảo rằng lưu lượng truy cập được hướng đến VIP sẽ đến được một nút proxy khỏe mạnh.
Tóm lại, một ứng dụng kết nối với cơ sở dữ liệu bằng địa chỉ IP ảo. IP này trỏ đến một trong các proxy. Proxy chuyển hướng lưu lượng truy cập tương ứng với cấu trúc topo. Thông tin về cấu trúc liên kết có nguồn gốc từ trạng thái read_only. Biến này được quản lý bởi ClusterControl và nó được đặt dựa trên các thay đổi cấu trúc liên kết mà người dùng yêu cầu hoặc ClusterControl được thực hiện tự động.