Xem xét trường hợp sử dụng chính hiện tại của cơ sở dữ liệu là truy xuất dữ liệu, điều rất quan trọng là hiệu suất của nó rất cao và chỉ có thể đạt được nếu dữ liệu được tìm nạp theo cách hiệu quả nhất có thể từ bộ nhớ. Đã có nhiều phát minh và triển khai thành công được thực hiện để đạt được điều tương tự. Một trong những cách tiếp cận nổi tiếng được hầu hết các cơ sở dữ liệu áp dụng là có một chỉ mục trên bảng.
Chỉ mục cơ sở dữ liệu là gì?
Chỉ số cơ sở dữ liệu, như tên cho thấy, duy trì một chỉ mục cho dữ liệu thực tế và do đó cải thiện hiệu suất để truy xuất dữ liệu từ bảng thực tế. Trong một thuật ngữ cơ sở dữ liệu hơn, chỉ mục cho phép tìm nạp trang chứa dữ liệu được lập chỉ mục trong một đường truyền rất tối thiểu vì dữ liệu được sắp xếp theo thứ tự cụ thể. Lợi ích của chỉ mục đi kèm với chi phí của không gian lưu trữ bổ sung để ghi dữ liệu bổ sung. Chỉ mục dành riêng cho bảng bên dưới và bao gồm một hoặc nhiều khóa (nghĩa là một hoặc nhiều cột của bảng được chỉ định). Chủ yếu có hai loại kiến trúc chỉ mục
- Chỉ mục theo cụm - Dữ liệu chỉ mục được lưu trữ cùng với phần dữ liệu khác và dữ liệu được sắp xếp dựa trên khóa chỉ mục. Tối đa chỉ có thể có một chỉ mục trong danh mục này cho một bảng cụ thể.
- Chỉ mục không phân cụm - Dữ liệu chỉ mục được lưu trữ riêng biệt và nó có một con trỏ tới bộ lưu trữ nơi phần khác của dữ liệu được lưu trữ. Đây còn được gọi là chỉ số phụ. Có thể có bao nhiêu chỉ mục của danh mục này tùy thích trên một bảng cụ thể.
Có nhiều cấu trúc dữ liệu khác nhau được sử dụng để triển khai chỉ mục, một số cấu trúc dữ liệu được đa số cơ sở dữ liệu chấp nhận rộng rãi là B-Tree và Hash.
Chỉ mục PostgreSQL là gì?
PostgreSQL chỉ hỗ trợ chỉ mục không phân cụm. Điều đó có nghĩa là dữ liệu chỉ mục và dữ liệu đầy đủ (ở đây trở đi được gọi là dữ liệu đống ) được lưu trữ trong một kho riêng. Các chỉ mục không phân cụm giống như “Mục lục” trong bất kỳ tài liệu nào, trong đó trước tiên chúng tôi kiểm tra số trang và sau đó kiểm tra các số trang đó để đọc toàn bộ nội dung. Để có được dữ liệu hoàn chỉnh dựa trên một chỉ mục, nó duy trì một con trỏ tới dữ liệu heap tương ứng. Nó cũng giống như sau khi biết số trang, nó cần phải đi đến trang đó và lấy nội dung thực của trang đó.
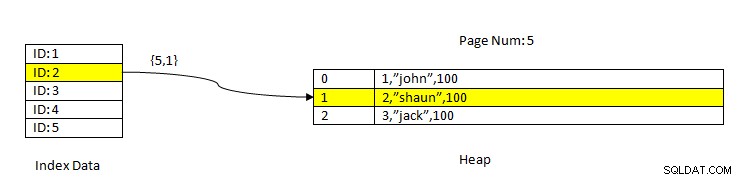 PostgreSQL:Đọc dữ liệu bằng Chỉ mục
PostgreSQL:Đọc dữ liệu bằng Chỉ mục Ví dụ:hãy xem xét một bảng có ba cột và một chỉ mục trên cột ID . Để ĐỌC dữ liệu dựa trên khóa ID =2, trước tiên, dữ liệu được lập chỉ mục với giá trị ID 2 được tìm kiếm. Điều này chứa một con trỏ (được gọi là Con trỏ mục) về số trang (tức là số khối) và phần bù của dữ liệu trong trang đó. Trong ví dụ hiện tại, chỉ mục trỏ đến trang số 5 và mục hàng thứ hai trong trang, đến lượt nó, chúng sẽ giữ phần bù cho toàn bộ dữ liệu (2, ”Shaun”, 100). Lưu ý rằng toàn bộ dữ liệu cũng chứa dữ liệu được lập chỉ mục, có nghĩa là cùng một dữ liệu được lặp lại trong hai kho lưu trữ.
INDEX giúp cải thiện hiệu suất như thế nào? Chà, để chọn bất kỳ bản ghi INDEX nào, nó không quét tuần tự tất cả các trang, thay vào đó nó chỉ cần quét một phần một số trang bằng cách sử dụng cấu trúc dữ liệu Chỉ mục cơ bản. Nhưng có một điểm khó khăn, vì mỗi bản ghi được tìm thấy từ dữ liệu Chỉ mục, nó cần phải tìm trong dữ liệu Heap cho toàn bộ dữ liệu, điều này gây ra nhiều I / O ngẫu nhiên và nó được coi là hoạt động chậm hơn I / O tuần tự. Vì vậy, chỉ khi một tỷ lệ phần trăm nhỏ các bản ghi được chọn (được quyết định dựa trên Chi phí trình tối ưu hóa PostgreSQL), thì chỉ PostgreSQL chọn Quét chỉ mục, nếu không thì mặc dù có chỉ mục trên bảng, nó vẫn tiếp tục sử dụng Quét theo trình tự.
Tóm lại, mặc dù việc tạo Chỉ mục giúp tăng tốc hiệu suất, nó nên được lựa chọn cẩn thận vì nó có chi phí lưu trữ, hiệu suất INSERT bị giảm sút.
Bây giờ chúng ta có thể tự hỏi, trong trường hợp chúng ta chỉ cần phần dữ liệu chỉ mục, chúng ta có thể tìm nạp chỉ từ trang lưu trữ chỉ mục không? Chà, câu trả lời cho điều này liên quan trực tiếp đến cách MVCC hoạt động trên bộ lưu trữ chỉ mục như được giải thích tiếp theo.
Sử dụng MVCC để lập chỉ mục
Giống như các trang Heap, trang chỉ mục duy trì nhiều phiên bản của bộ chỉ mục nhưng nó không duy trì thông tin hiển thị. Như đã giải thích trong MVCC trước của tôi blog, để quyết định phiên bản bộ giá trị hiển thị phù hợp, nó yêu cầu so sánh giao dịch. Giao dịch đã chèn / cập nhật / xóa tuple được duy trì cùng với tuple heap nhưng điều tương tự không được duy trì với tuple chỉ mục. Điều này hoàn toàn được thực hiện để tiết kiệm bộ nhớ và đó là sự cân bằng giữa dung lượng và hiệu suất.
Bây giờ quay lại câu hỏi ban đầu, vì thông tin hiển thị trong bộ tuple chỉ mục không có ở đó, nó cần tham khảo bộ tuple đống tương ứng để xem liệu dữ liệu đã chọn có hiển thị hay không. Vì vậy, mặc dù các phần khác của dữ liệu từ heap tuple là không bắt buộc, bạn vẫn cần truy cập các trang heap để kiểm tra khả năng hiển thị. Nhưng một lần nữa, có một sự thay đổi trong trường hợp tất cả các bộ giá trị trên một trang nhất định (trang được trỏ bởi chỉ mục, tức là ItemPointer) đều hiển thị thì không cần tham chiếu đến từng mục của trang Heap để “kiểm tra mức độ hiển thị” và do đó dữ liệu chỉ có thể được trả về từ trang Chỉ mục. Trường hợp đặc biệt này được gọi là “Chỉ quét chỉ mục”. Để hỗ trợ điều này, PostgreSQL duy trì một bản đồ khả năng hiển thị cho mỗi trang để kiểm tra mức độ hiển thị của trang.
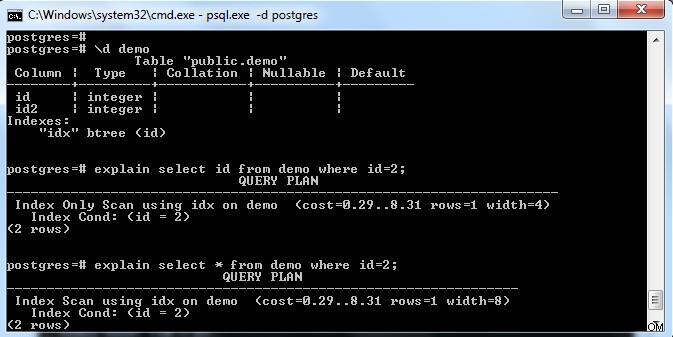
Như trong hình trên, có một chỉ mục trên bảng “demo” với một khóa trên cột “id”. Nếu chúng tôi cố gắng chỉ chọn trường chỉ mục (tức là id) thì nó đã chọn “Chỉ quét chỉ mục” (coi như trang giới thiệu hiển thị hoàn toàn).
Chỉ mục theo cụm
Không có sự hỗ trợ của chỉ mục phân cụm trực tiếp trong PostgreSQL nhưng có một cách gián tiếp để một phần đạt được điều tương tự. Điều này đạt được bằng các lệnh SQL dưới đây:
CLUSTER [VERBOSE] table_name [ USING index_name ]
CLUSTER [VERBOSE]Lệnh đầu tiên hướng dẫn cơ sở dữ liệu phân cụm một bảng (tức là sắp xếp bảng) bằng cách sử dụng chỉ mục đã cho. Chỉ mục này lẽ ra đã được tạo. Việc phân cụm này chỉ là hoạt động một lần và tác động của nó không còn sau thao tác tiếp theo trên bảng này, tức là nếu nhiều bản ghi được chèn / cập nhật, bảng có thể không được sắp xếp thứ tự. Nếu người dùng cần để vẫn giữ bảng được nhóm (có thứ tự) thì họ có thể sử dụng lệnh đầu tiên mà không cần đặt tên chỉ mục.
Lệnh thứ hai chỉ hữu ích để phân nhóm lại bảng (tức là bảng đã được phân nhóm bằng cách sử dụng một số chỉ mục). Lệnh này nhóm lại tất cả các bảng trong cơ sở dữ liệu hiện tại hiển thị cho người dùng được kết nối hiện tại.
Ví dụ trong hình bên dưới, SELECT đầu tiên trả về các bản ghi theo thứ tự không được sắp xếp vì không có chỉ mục được phân cụm. Mặc dù đã có chỉ mục không phân cụm nhưng các bản ghi được chọn từ vùng đống nơi các bản ghi không được sắp xếp.
SELECT thứ hai trả về các bản ghi được sắp xếp theo cột “id” vì nó đã được phân nhóm bằng cách sử dụng chỉ mục chứa cột “id”.
SELECT thứ ba trả về các bản ghi từng phần theo thứ tự được sắp xếp nhưng các bản ghi mới được chèn vào không được sắp xếp. SELECT thứ tư một lần nữa trả về tất cả các bản ghi theo thứ tự đã sắp xếp vì bảng đã được nhóm lại
 Lệnh cụm PostgreSQL
Lệnh cụm PostgreSQL Loại chỉ mục
PostgreSQL cung cấp một số loại chỉ mục như sau:
- B-Tree
- Băm
- GiST
- GIN
- BRIN
Mỗi loại chỉ mục thực hiện các loại cấu trúc dữ liệu cơ bản khác nhau, phù hợp nhất cho các loại truy vấn khác nhau. Theo mặc định, chỉ mục B-Tree được tạo, đây là chỉ mục được sử dụng rộng rãi. Chi tiết của từng loại chỉ mục sẽ được đề cập trong một blog trong tương lai.
Khác:Chỉ mục một phần và biểu hiện
Chúng ta mới chỉ thảo luận về các chỉ mục trên một hoặc nhiều cột của bảng nhưng có hai cách khác để tạo chỉ mục trên PostgreSQL
- Chỉ mục một phần: Chỉ mục từng phần là chỉ mục được xây dựng bằng cách sử dụng tập hợp con của cột khóa cho một bảng cụ thể. Tập hợp con được xác định bởi biểu thức điều kiện được đưa ra trong quá trình tạo chỉ mục. Vì vậy, với chỉ mục một phần, không gian lưu trữ để lưu trữ dữ liệu chỉ mục sẽ được tiết kiệm. Vì vậy, người dùng nên chọn điều kiện sao cho đó không phải là các giá trị phổ biến, vì dù sao thì đối với các giá trị thường xuyên (phổ biến) hơn, quét chỉ mục sẽ không được chọn. Phần còn lại của chức năng vẫn giống như đối với một chỉ mục thông thường. Ví dụ:Chỉ mục một phần
- Chỉ mục Biểu thức: Các chỉ mục biểu thức cung cấp một loại tính linh hoạt khác trong PostgreSQL. Tất cả các chỉ mục được thảo luận cho đến bây giờ, bao gồm cả các chỉ mục một phần, đều nằm trên một tập hợp các cột cụ thể. Nhưng điều gì sẽ xảy ra nếu một truy vấn liên quan đến quyền truy cập của một bảng dựa trên biểu thức (biểu thức liên quan đến một hoặc nhiều cột), không có chỉ mục biểu thức, nó sẽ không chọn quét chỉ mục. Vì vậy, để truy cập nhanh loại truy vấn này, PostgreSQL cho phép tạo chỉ mục trên một biểu thức. Phần còn lại của chức năng vẫn giống như đối với một chỉ mục thông thường.
 Ví dụ:Chỉ số biểu thức
Ví dụ:Chỉ số biểu thức
Lưu trữ chỉ mục trong InnoDB
Cách sử dụng và chức năng của Chỉ mục hầu hết giống như trong PostgreSQL với sự khác biệt lớn về Chỉ mục được phân cụm.
InnoDB hỗ trợ hai loại Chỉ mục:
- Chỉ mục theo cụm
- Chỉ mục phụ
Chỉ mục theo cụm
Clustered Index là một loại chỉ mục đặc biệt trong InnoDB. Ở đây, dữ liệu được lập chỉ mục không được lưu trữ riêng lẻ mà nó là một phần của toàn bộ dữ liệu hàng. Nói cách khác, chỉ mục được phân cụm chỉ buộc dữ liệu bảng được sắp xếp vật lý bằng cách sử dụng cột chính của chỉ mục. Nó có thể được coi là "Từ điển", nơi dữ liệu được sắp xếp dựa trên bảng chữ cái.
Vì chỉ mục được phân nhóm sắp xếp các hàng bằng cách sử dụng khóa chỉ mục, nên chỉ có thể có một chỉ mục được phân nhóm. Ngoài ra, phải có một chỉ mục được phân nhóm do InnoDB sử dụng giống nhau để thao tác dữ liệu một cách tối ưu trong các hoạt động dữ liệu khác nhau.
Chỉ mục theo cụm được tạo tự động (như một phần của tạo bảng) bằng cách sử dụng một trong các cột của bảng theo mức độ ưu tiên bên dưới:
- Sử dụng khóa chính nếu khóa chính được đề cập như một phần của quá trình tạo bảng.
- Chọn bất kỳ cột duy nhất nào trong đó tất cả các cột chính KHÔNG ĐẦY ĐỦ.
- Nếu không, nội bộ sẽ tạo chỉ mục nhóm ẩn trên cột hệ thống chứa ID hàng của mỗi hàng.
Không giống như chỉ mục không phân cụm của PostgreSQL, InnoDB truy cập vào một hàng bằng cách sử dụng chỉ mục được phân cụm nhanh hơn vì tìm kiếm chỉ mục dẫn trực tiếp đến trang có tất cả dữ liệu hàng và do đó tránh được I / O ngẫu nhiên.
Ngoài ra, việc lấy dữ liệu bảng theo thứ tự đã sắp xếp bằng cách sử dụng chỉ mục nhóm cũng rất nhanh vì tất cả dữ liệu đã được sắp xếp và toàn bộ dữ liệu cũng có sẵn.
Chỉ mục phụ
Chỉ mục được tạo rõ ràng trong InnoDB được coi là Chỉ mục phụ, tương tự như chỉ mục không phân cụm của PostgreSQL. Mỗi bản ghi trong kho lưu chỉ mục phụ chứa các cột khóa chính của các hàng (được sử dụng để tạo Chỉ mục được phân cụm) và cả các cột được chỉ định để tạo chỉ mục phụ.
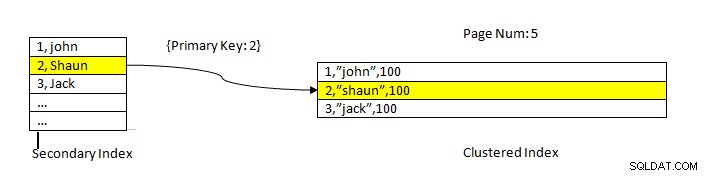 InnoDB:Đọc dữ liệu bằng chỉ mục
InnoDB:Đọc dữ liệu bằng chỉ mục Tìm nạp dữ liệu bằng cách sử dụng chỉ mục phụ tương tự như trong trường hợp của PostgreSQL ngoại trừ việc tra cứu chỉ mục thứ cấp của InnoDB cung cấp khóa chính làm con trỏ để tìm nạp dữ liệu còn lại từ chỉ mục được phân cụm.
Ví dụ:như được hiển thị trong hình trên, chỉ mục được nhóm nằm trên cột ID, vì vậy dữ liệu bảng được sắp xếp giống nhau. Chỉ mục phụ nằm trên cột “ tên ”, Như chúng ta có thể thấy chỉ mục phụ có cả giá trị ID và tên. Khi chúng tôi tra cứu bằng cách sử dụng chỉ mục phụ, nó sẽ tìm thấy vị trí thích hợp với giá trị khóa tương ứng. Sau đó, khóa chính tương ứng được sử dụng để tham chiếu đến phần còn lại của dữ liệu từ chỉ mục được phân nhóm.
MVCC cho chỉ mục
Chỉ mục phân cụm MVCC sử dụng Mô hình hoàn tác InnoDB truyền thống (Thực tế giống với MVCC toàn bộ dữ liệu, vì chỉ mục được phân nhóm không là gì ngoài toàn bộ dữ liệu).
Nhưng chỉ số thứ cấp MVCC sử dụng một cách tiếp cận khác nhau một chút để duy trì MVCC. Khi cập nhật chỉ mục phụ, mục nhập chỉ mục cũ được đánh dấu xóa và các bản ghi mới được chèn vào cùng một bộ lưu trữ, tức là CẬP NHẬT không ở đúng vị trí. Cuối cùng, các mục chỉ mục cũ bị xóa. Đến đây, bạn có thể nhận thấy rằng MVCC chỉ mục thứ cấp của InnoDB gần giống với chỉ mục MVCC của mô hình PostgreSQL.
Loại chỉ mục
InnoDB chỉ hỗ trợ loại B-Tree của chỉ mục và do đó không bắt buộc phải được chỉ định trong khi tạo chỉ mục.
Khác:Chỉ số băm thích ứng
Như đã đề cập trong phần trước rằng chỉ loại B-Tree chỉ mục được hỗ trợ bởi InnoDB nhưng có một sự thay đổi. InnoDB có chức năng tự động phát hiện xem truy vấn có thể được lợi từ việc xây dựng chỉ mục băm và toàn bộ dữ liệu của bảng có thể vừa với bộ nhớ hay không, sau đó nó sẽ tự động làm như vậy.
Chỉ mục băm được xây dựng bằng cách sử dụng chỉ mục B-Tree hiện có tùy thuộc vào truy vấn. Nếu có nhiều chỉ mục B-Tree phụ, thì nó sẽ chọn chỉ mục đủ điều kiện theo truy vấn. Chỉ mục băm được tạo chưa hoàn chỉnh, nó chỉ xây dựng chỉ mục một phần theo kiểu sử dụng dữ liệu.
Đây là một trong những tính năng thực sự mạnh mẽ để cải thiện động hiệu suất truy vấn.
Kết luận
Việc sử dụng bất kỳ chỉ mục nào trong bất kỳ cơ sở dữ liệu nào thực sự hữu ích để cải thiện hiệu suất ĐỌC nhưng đồng thời, nó làm giảm hiệu suất CHÈN / CẬP NHẬT do cần ghi thêm dữ liệu. Vì vậy, chỉ mục nên được chọn rất khôn ngoan và chỉ nên được tạo khi các khóa chỉ mục được sử dụng như một vị từ để tìm nạp dữ liệu.
InnoDB cung cấp một tính năng rất tốt về chỉ mục nhóm, có thể rất hữu ích tùy thuộc vào các trường hợp sử dụng. Ngoài ra, lập chỉ mục băm thích ứng của nó rất mạnh mẽ.
Trong khi PostgreSQL cung cấp nhiều loại chỉ mục khác nhau, có thể thực sự cung cấp các tùy chọn phạm vi tiếp cận tính năng và một hoặc tất cả có thể được sử dụng tùy thuộc vào trường hợp sử dụng của doanh nghiệp. Ngoài ra, chỉ mục một phần và chỉ mục biểu thức cũng khá hữu ích tùy thuộc vào trường hợp sử dụng.