Cập nhật :bắt đầu bằng gấu trúc 0,15, to_sql hỗ trợ viết NaN giá trị (chúng sẽ được viết là NULL trong cơ sở dữ liệu), vì vậy giải pháp được mô tả bên dưới sẽ không còn cần thiết nữa (xem https:// github.com/pydata/pandas/pull/8208
).
Pandas 0.15 sẽ được phát hành vào tháng 10 tới và tính năng này được hợp nhất trong phiên bản phát triển.
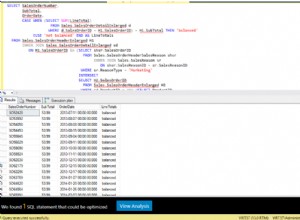
Điều này có thể là do NaN các giá trị trong bảng của bạn và đây là một thiếu sót đã biết tại thời điểm này mà các hàm sql của gấu trúc không xử lý tốt các NaN ( https://github.com/pydata/pandas/issues/2754
, https://github.com/pydata/pandas/issues/4199
)
Để giải quyết vấn đề này tại thời điểm này (đối với gấu trúc phiên bản 0.14.1 trở xuống), bạn có thể chuyển đổi nan theo cách thủ công giá trị thành Không với:
df2 = df.astype(object).where(pd.notnull(df), None)
và sau đó ghi khung dữ liệu vào sql. Tuy nhiên, điều này sẽ chuyển đổi tất cả các cột thành kiểu đối tượng. Do đó, bạn phải tạo bảng cơ sở dữ liệu dựa trên khung dữ liệu ban đầu. Ví dụ:nếu hàng đầu tiên của bạn không chứa NaN s:
df[:1].to_sql('table_name', con)
df2[1:].to_sql('table_name', con, if_exists='append')