Điều này cố gắng giữ cho giải pháp có thể dễ dàng bảo trì mà không cần hoàn thành toàn bộ truy vấn cuối cùng trong cùng một lần, điều này sẽ khiến kích thước của nó tăng gần gấp đôi (theo suy nghĩ của tôi). Điều này là do các kết quả cần phải khớp và được trình bày trên một hàng với các sự kiện Vào và Ra đã khớp. Vì vậy, cuối cùng, tôi sử dụng một vài bảng làm việc. Nó được triển khai trong một thủ tục được lưu trữ.
Thủ tục được lưu trữ sử dụng một số biến được đưa vào với cross join . Hãy nghĩ về phép nối chéo chỉ là một cơ chế để khởi tạo các biến. Các biến được duy trì một cách an toàn, vì vậy tôi tin rằng, theo tinh thần của điều này tài liệu
thường được tham chiếu trong các truy vấn biến. Các phần quan trọng của tham chiếu là việc xử lý an toàn các biến trên một dòng buộc chúng phải được đặt trước khi các cột khác sử dụng chúng. Điều này đạt được thông qua greatest() và least() các hàm có mức độ ưu tiên cao hơn các biến được đặt mà không sử dụng các hàm đó. Cũng lưu ý rằng coalesce() thường được sử dụng cho cùng một mục đích. Nếu việc sử dụng chúng có vẻ lạ, chẳng hạn như lấy số lớn nhất được biết là lớn hơn 0 hoặc 0, thì đó là điều có chủ ý. Cố ý buộc đặt thứ tự ưu tiên của các biến.
Các cột trong truy vấn có tên những thứ như dummy2 vv là các cột mà đầu ra không được sử dụng, nhưng chúng được sử dụng để đặt các biến bên trong, chẳng hạn, greatest() hay cách khác. Điều này đã được đề cập ở trên. Đầu ra như 7777 là một trình giữ chỗ trong vị trí thứ 3, vì một số giá trị là cần thiết cho if() đã được sử dụng. Vì vậy, hãy bỏ qua tất cả những điều đó.
Tôi đã bao gồm một số ảnh chụp màn hình của mã khi nó tiến triển theo từng lớp để giúp bạn hình dung kết quả đầu ra. Và cách các bước phát triển lặp đi lặp lại này dần được chuyển sang giai đoạn tiếp theo để mở rộng so với giai đoạn trước.
Tôi chắc chắn rằng các đồng nghiệp của tôi có thể cải thiện điều này trong một lần truy vấn. Tôi có thể đã hoàn thành nó theo cách đó. Nhưng tôi tin rằng nó sẽ dẫn đến một mớ hỗn độn khó hiểu và sẽ vỡ ra nếu chạm vào.
Lược đồ:
create table attendance2(Id int, DateTime datetime, Door char(20), Active_door char(20));
INSERT INTO attendance2 VALUES
( 1, '2016-01-01 08:00:00', 'In', ''),
( 2, '2016-01-01 09:00:00', 'Out', ''),
( 3, '2016-01-01 09:15:00', 'In', ''),
( 4, '2016-01-01 09:30:00', 'In', ''),
( 5, '2016-01-01 09:35:00', '', 'On'),
( 6, '2016-01-01 10:00:00', 'Out', ''),
( 7, '2016-01-01 16:00:00', '', 'Off');
drop table if exists oneLinersDetail;
create table oneLinersDetail
( -- architect this depending on multi-user concurrency
id int not null,
dt datetime not null,
door int not null,
grpIn int not null,
grpInSeq int not null,
grpOut int not null,
grpOutSeq int not null
);
drop table if exists oneLinersSummary;
create table oneLinersSummary
( -- architect this depending on multi-user concurrency
id int not null,
grpInSeq int null,
grpOutSeq int null,
checkIn datetime null, -- we are hoping in the end it is not null
checkOut datetime null -- ditto
);
Quy trình được lưu trữ:
DROP PROCEDURE IF EXISTS fetchOneLiners;
DELIMITER $$
CREATE PROCEDURE fetchOneLiners()
BEGIN
truncate table oneLinersDetail; -- architect this depending on multi-user concurrency
insert oneLinersDetail(id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq)
select id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq
from
( select id,dt,door,
if(@lastEvt!=door and door=1,
greatest(@grpIn:example@sqldat.com+1,0),
7777) as dummy2, -- this output column we don't care about (we care about the variable being set)
if(@lastEvt!=door and door=2,
greatest(@grpOut:example@sqldat.com+1,0),
7777) as dummy3, -- this output column we don't care about (we care about the variable being set)
if (@lastEvt!=door,greatest(@flip:=1,0),least(@flip:=0,1)) as flip,
if (door=1 and @flip=1,least(@grpOutSeq:=0,1),7777) as dummy4,
if (door=1 and @flip=1,greatest(@grpInSeq:=1,0),7777) as dummy5,
if (door=1 and @flip!=1,greatest(@grpInSeq:example@sqldat.comnSeq+1,0),7777) as dummy6,
if (door=2 and @flip=1,least(@grpInSeq:=0,1),7777) as dummy7,
if (door=2 and @flip=1,greatest(@grpOutSeq:=1,0),7777) as dummy8,
if (door=2 and @flip!=1,greatest(@grpOutSeq:example@sqldat.com+1,0),7777) as dummy9,
@grpIn as grpIn,
@grpInSeq as grpInSeq,
@grpOut as grpOut,
@grpOutSeq as grpOutSeq,
@lastEvt:=door as lastEvt
from
( select id,`datetime` as dt,
CASE
WHEN Door='in' or Active_door='on' THEN 1
ELSE 2
END as door
from attendance2
order by id
) xD1 -- derived table #1
cross join (select @grpIn:=0,@grpInSeq:=0,@grpOut:=0,@grpOutSeq:=0,@lastEvt:=-1,@flip:=0) xParams
order by id
) xD2 -- derived table #2
order by id;
-- select * from oneLinersDetail;
truncate table oneLinersSummary; -- architect this depending on multi-user concurrency
insert oneLinersSummary (id,grpInSeq,grpOutSeq,checkIn,checkOut)
select distinct grpIn,null,null,null,null
from oneLinersDetail
order by grpIn;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpIn,max(grpInSeq) m
from oneLinersDetail
where door=1
group by grpIn
) d1
on d1.grpIn=ols.id
set ols.grpInSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpOut,max(grpOutSeq) m
from oneLinersDetail
where door=2
group by grpOut
) d1
on d1.grpOut=ols.id
set ols.grpOutSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=1 and old.grpIn=ols.id and old.grpInSeq=ols.grpInSeq
set ols.checkIn=old.dt;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=2 and old.grpOut=ols.id and old.grpOutSeq=ols.grpOutSeq
set ols.checkOut=old.dt;
-- select * from oneLinersSummary;
-- dump out the results
select id,checkIn,checkOut
from oneLinersSummary
order by id;
-- rows are left in those two tables (oneLinersDetail,oneLinersSummary)
END$$
DELIMITER ;
Kiểm tra:
call fetchOneLiners();
+----+---------------------+---------------------+
| id | checkIn | checkOut |
+----+---------------------+---------------------+
| 1 | 2016-01-01 08:00:00 | 2016-01-01 09:00:00 |
| 2 | 2016-01-01 09:35:00 | 2016-01-01 16:00:00 |
+----+---------------------+---------------------+
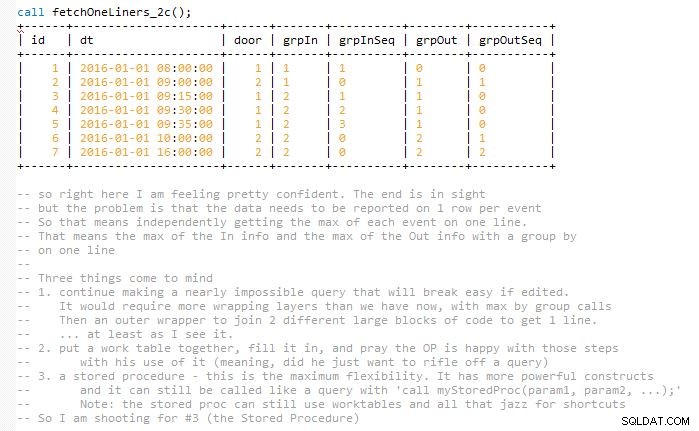
Đây là phần cuối của Câu trả lời. Dưới đây là hình ảnh của nhà phát triển về các bước dẫn đến hoàn thành quy trình được lưu trữ.
Các phiên bản phát triển dẫn đầu cho đến khi kết thúc. Hy vọng rằng điều này hỗ trợ trong việc trực quan hóa thay vì chỉ bỏ một đoạn mã gây nhầm lẫn kích thước trung bình.
Bước A
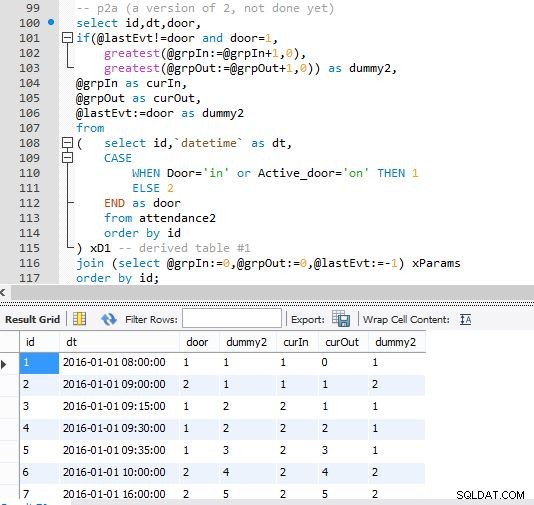
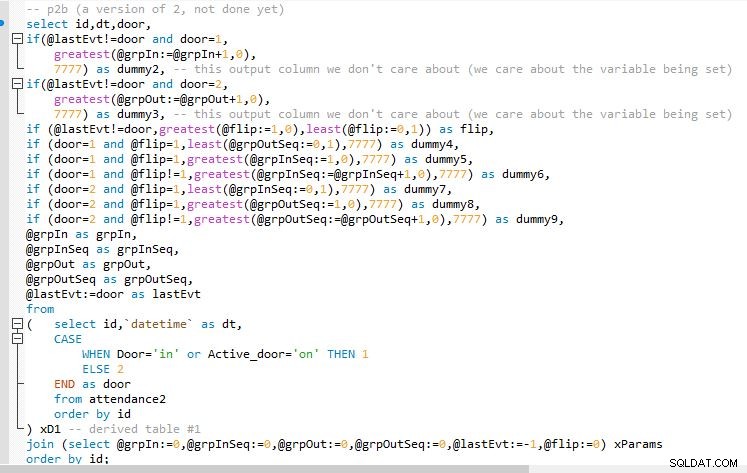
Bước B
Đầu ra của bước B

Bước C
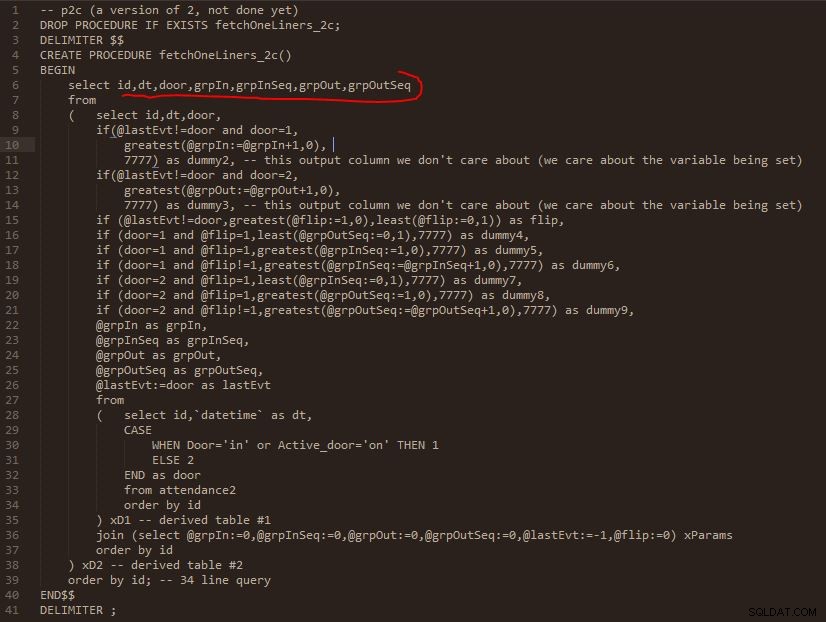
Đầu ra của bước C