Để trả lời câu hỏi này, trước tiên chúng ta phải phân tích thực vấn đề bạn đang gặp phải.
Vấn đề thực sự sẽ là sự kết hợp hiệu quả nhất giữa việc ghi và truy xuất dữ liệu.
Hãy xem lại kết luận của bạn:
-
hàng nghìn bảng - tốt, điều đó vi phạm mục đích của cơ sở dữ liệu và khiến nó khó làm việc hơn. Bạn cũng chẳng đạt được gì. Vẫn có liên quan đến việc tìm kiếm đĩa, lần này có nhiều bộ mô tả tệp được sử dụng. Bạn cũng phải biết tên bảng, và có hàng ngàn bảng trong số đó. Cũng rất khó để trích xuất dữ liệu, vốn là cơ sở dữ liệu - để cấu trúc dữ liệu theo cách mà bạn có thể dễ dàng tham chiếu chéo các bản ghi. Hàng nghìn bảng - không hiệu quả từ perf. quan điểm. Không hiệu quả từ quan điểm sử dụng. Lựa chọn tồi.
-
tệp csv - nó có thể là tuyệt vời để tìm nạp dữ liệu, nếu bạn cần toàn bộ nội dung cùng một lúc. Nhưng nó không tốt cho việc thao tác hoặc chuyển đổi dữ liệu từ xa. Với thực tế là bạn dựa vào một bố cục cụ thể - bạn phải hết sức cẩn thận khi viết cho CSV. Nếu điều này phát triển đến hàng nghìn tệp CSV, bạn đã không làm được gì cho mình. Bạn đã loại bỏ tất cả chi phí của SQL (điều này không lớn lắm) nhưng bạn không làm gì để truy xuất các phần của tập dữ liệu. Bạn cũng gặp sự cố khi tìm nạp dữ liệu lịch sử hoặc tham chiếu chéo bất kỳ thứ gì. Lựa chọn tồi.
Kịch bản lý tưởng là có thể truy cập bất kỳ phần nào của tập dữ liệu một cách hiệu quả và nhanh chóng mà không có bất kỳ loại thay đổi cấu trúc nào.
Và đây chính xác là lý do tại sao chúng tôi sử dụng cơ sở dữ liệu quan hệ và tại sao chúng tôi dành toàn bộ máy chủ có nhiều RAM cho các cơ sở dữ liệu đó.
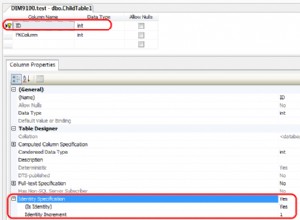
Trong trường hợp của bạn, bạn đang sử dụng bảng MyISAM (phần mở rộng tệp .MYD). Đó là một định dạng lưu trữ cũ hoạt động tốt cho phần cứng cấp thấp đã được sử dụng trước đây. Nhưng ngày nay, chúng ta có những chiếc máy tính nhanh và xuất sắc. Đó là lý do tại sao chúng tôi sử dụng InnoDB và cho phép nó sử dụng nhiều RAM để giảm chi phí I / O. Biến được đề cập kiểm soát nó được gọi là innodb_buffer_pool_size - googling sẽ tạo ra kết quả có ý nghĩa.
Để trả lời câu hỏi - một giải pháp hiệu quả, thỏa đáng sẽ là sử dụng một bảng nơi bạn lưu trữ thông tin cảm biến (id, tiêu đề, mô tả) và một bảng khác nơi bạn lưu trữ các kết quả đọc của cảm biến. Bạn phân bổ đủ RAM hoặc bộ nhớ đủ nhanh (SSD). Các bảng sẽ trông như thế này:
CREATE TABLE sensors (
id int unsigned not null auto_increment,
sensor_title varchar(255) not null,
description varchar(255) not null,
date_created datetime,
PRIMARY KEY(id)
) ENGINE = InnoDB DEFAULT CHARSET = UTF8;
CREATE TABLE sensor_readings (
id int unsigned not null auto_increment,
sensor_id int unsigned not null,
date_created datetime,
reading_value varchar(255), -- note: this column's value might vary, I do not know what data type you need to hold value(s)
PRIMARY KEY(id),
FOREIGN KEY (sensor_id) REFERENCES sensors (id) ON DELETE CASCADE
) ENGINE = InnoDB DEFAULT CHARSET = UTF8;
InnoDB, theo mặc định, sử dụng một tệp phẳng cho toàn bộ cơ sở dữ liệu / cài đặt. Điều đó làm giảm bớt vấn đề vượt quá giới hạn bộ mô tả tệp của hệ điều hành / hệ thống tệp. Một vài, thậm chí hàng chục triệu bản ghi sẽ không thành vấn đề nếu bạn phân bổ 5-6 GB RAM để giữ tập dữ liệu đang hoạt động trong bộ nhớ - điều đó sẽ cho phép bạn truy cập nhanh vào dữ liệu.
Nếu tôi thiết kế một hệ thống như vậy, đây là cách tiếp cận đầu tiên tôi thực hiện (cá nhân). Từ đó, bạn có thể dễ dàng điều chỉnh tùy thuộc vào những gì bạn cần làm với thông tin đó.