Giới thiệu
Hiện tại, các điều kiện phù hợp của bạn có thể quá rộng. Tuy nhiên, bạn có thể sử dụng khoảng cách levenshtein để kiểm tra các từ của mình. Nó có thể không quá dễ dàng để thực hiện tất cả các mục tiêu mong muốn với nó, giống như sự tương đồng về âm thanh. Vì vậy, tôi khuyên bạn nên tách vấn đề của bạn thành một số vấn đề khác.
Ví dụ:bạn có thể tạo một số trình kiểm tra tùy chỉnh sẽ sử dụng đầu vào có thể gọi được đã chuyển qua, có hai chuỗi và sau đó trả lời câu hỏi về chúng có giống nhau không (đối với levenshtein đó sẽ là khoảng cách nhỏ hơn một số giá trị, cho similar_text - một số phần trăm của sự giống nhau e t.c. - tùy thuộc vào bạn để xác định các quy tắc).
Tương tự, dựa trên các từ
Tất cả các hàm tích hợp sẽ không thành công nếu chúng ta đang nói về trường hợp khi bạn đang tìm kiếm đối sánh từng phần - đặc biệt nếu đó là về đối sánh không theo thứ tự. Do đó, bạn sẽ cần tạo công cụ so sánh phức tạp hơn. Bạn có:
- Chuỗi dữ liệu (ví dụ:sẽ có trong DB). Có vẻ như D =D 0 D 1 D 2 ... D n
- Chuỗi tìm kiếm (sẽ là đầu vào của người dùng). Có vẻ như S =S 0 S 1 ... S m
Ở đây các ký hiệu không gian chỉ có nghĩa là bất kỳ khoảng trắng nào (tôi cho rằng các ký hiệu không gian sẽ không ảnh hưởng đến sự tương đồng). Ngoài ra n > m . Với định nghĩa này, vấn đề của bạn là - tìm bộ m các từ trong D sẽ tương tự như S . Bởi set Ý tôi là bất kỳ chuỗi không có thứ tự nào. Do đó, nếu chúng tôi tìm thấy bất kỳ trình tự nào như vậy trong D , rồi đến S tương tự như D .
Rõ ràng, nếu n < m thì đầu vào chứa nhiều từ hơn chuỗi dữ liệu. Trong trường hợp này, bạn có thể nghĩ rằng chúng không giống nhau hoặc hoạt động giống như trên, nhưng hãy chuyển đổi dữ liệu và đầu vào (tuy nhiên, điều đó trông hơi kỳ quặc, nhưng có thể áp dụng theo một cách nào đó)
Thực hiện
Để thực hiện công việc này, bạn cần có khả năng tạo tập hợp chuỗi là các phần từ m từ D . Dựa trên câu hỏi này
của tôi bạn có thể làm điều này với:
protected function nextAssoc($assoc)
{
if(false !== ($pos = strrpos($assoc, '01')))
{
$assoc[$pos] = '1';
$assoc[$pos+1] = '0';
return substr($assoc, 0, $pos+2).
str_repeat('0', substr_count(substr($assoc, $pos+2), '0')).
str_repeat('1', substr_count(substr($assoc, $pos+2), '1'));
}
return false;
}
protected function getAssoc(array $data, $count=2)
{
if(count($data)<$count)
{
return null;
}
$assoc = str_repeat('0', count($data)-$count).str_repeat('1', $count);
$result = [];
do
{
$result[]=array_intersect_key($data, array_filter(str_split($assoc)));
}
while($assoc=$this->nextAssoc($assoc));
return $result;
}
-so với bất kỳ mảng nào, getAssoc() sẽ trả về mảng các lựa chọn không có thứ tự bao gồm từ m từng mục.
Bước tiếp theo là về thứ tự trong lựa chọn sản xuất. Chúng ta nên tìm kiếm cả Niels Andersen và Andersen Niels trong D của chúng tôi sợi dây. Do đó, bạn sẽ cần có khả năng tạo hoán vị cho mảng. Đây là vấn đề rất phổ biến, nhưng tôi cũng sẽ đưa phiên bản của mình vào đây:
protected function getPermutations(array $input)
{
if(count($input)==1)
{
return [$input];
}
$result = [];
foreach($input as $key=>$element)
{
foreach($this->getPermutations(array_diff_key($input, [$key=>0])) as $subarray)
{
$result[] = array_merge([$element], $subarray);
}
}
return $result;
}
Sau đó, bạn sẽ có thể tạo các lựa chọn của m và sau đó, hoán vị từng từ trong số chúng, lấy tất cả các biến thể để so sánh với chuỗi tìm kiếm S . Việc so sánh đó mỗi lần sẽ được thực hiện thông qua một số lệnh gọi lại, chẳng hạn như levenshtein . Đây là mẫu:
public function checkMatch($search, callable $checker=null, array $args=[], $return=false)
{
$data = preg_split('/\s+/', strtolower($this->data), -1, PREG_SPLIT_NO_EMPTY);
$search = trim(preg_replace('/\s+/', ' ', strtolower($search)));
foreach($this->getAssoc($data, substr_count($search, ' ')+1) as $assoc)
{
foreach($this->getPermutations($assoc) as $ordered)
{
$ordered = join(' ', $ordered);
$result = call_user_func_array($checker, array_merge([$ordered, $search], $args));
if($result<=$this->distance)
{
return $return?$ordered:true;
}
}
}
return $return?null:false;
}
Điều này sẽ kiểm tra tính tương tự, dựa trên lệnh gọi lại của người dùng, phải chấp nhận ít nhất hai tham số (tức là các chuỗi được so sánh). Ngoài ra, bạn có thể muốn trả về chuỗi đã kích hoạt trả về tích cực gọi lại. Xin lưu ý rằng mã này sẽ không khác biệt chữ hoa và chữ thường - nhưng có thể bạn không muốn hành vi như vậy (sau đó chỉ cần thay thế strtolower() ).
Mẫu mã đầy đủ có sẵn trong danh sách này (Tôi đã không sử dụng hộp cát vì tôi không chắc về danh sách mã sẽ có sẵn ở đó trong bao lâu). Với mẫu sử dụng này:
$data = 'Niels Faurskov Andersen';
$search = [
'Niels Andersen',
'Niels Faurskov',
'Niels Faurskov Andersen',
'Nils Faurskov Andersen',
'Nils Andersen',
'niels faurskov',
'niels Faurskov',
'niffddels Faurskovffre'//I've added this crap
];
$checker = new Similarity($data, 2);
echo(sprintf('Testing "%s"'.PHP_EOL.PHP_EOL, $data));
foreach($search as $name)
{
echo(sprintf(
'Name "%s" has %s'.PHP_EOL,
$name,
($result=$checker->checkMatch($name, 'levenshtein', [], 1))
?sprintf('matched with "%s"', $result)
:'mismatched'
)
);
}
bạn sẽ nhận được kết quả như sau:
Testing "Niels Faurskov Andersen" Name "Niels Andersen" has matched with "niels andersen" Name "Niels Faurskov" has matched with "niels faurskov" Name "Niels Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Andersen" has matched with "niels andersen" Name "niels faurskov" has matched with "niels faurskov" Name "niels Faurskov" has matched with "niels faurskov" Name "niffddels Faurskovffre" has mismatched
- tại đây là bản demo cho mã này, đề phòng.
Độ phức tạp
Vì bạn không chỉ quan tâm đến bất kỳ phương thức nào, mà còn về - nó tốt đến mức nào, bạn có thể nhận thấy rằng mã như vậy sẽ tạo ra các hoạt động khá quá mức. Ý tôi là, ít nhất, thế hệ các phần của chuỗi. Sự phức tạp ở đây bao gồm hai phần:
- Chuỗi phần tạo bộ phận. Nếu bạn muốn tạo tất cả các phần chuỗi - bạn sẽ phải thực hiện việc này như tôi đã mô tả ở trên. Điểm có thể cải thiện - tạo các tập chuỗi không có thứ tự (có trước hoán vị). Nhưng tôi vẫn nghi ngờ điều đó có thể được thực hiện bởi vì phương thức trong mã được cung cấp sẽ tạo ra chúng không phải bằng "brute-force", mà vì chúng được tính toán bằng toán học (với số lượng là
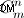 )
) - Phần kiểm tra độ giống nhau. Ở đây độ phức tạp của bạn phụ thuộc vào trình kiểm tra độ tương tự nhất định. Ví dụ:
similar_text()có độ phức tạp O (N), do đó với các tập hợp so sánh lớn, nó sẽ cực kỳ chậm.
Nhưng bạn vẫn có thể cải thiện giải pháp hiện tại bằng cách kiểm tra nhanh. Bây giờ mã này đầu tiên sẽ tạo tất cả các chuỗi con chuỗi và sau đó bắt đầu kiểm tra từng chuỗi một. Trong trường hợp phổ biến, bạn không cần phải làm điều đó, vì vậy bạn có thể muốn thay thế điều đó bằng hành vi, khi sau khi tạo chuỗi tiếp theo, nó sẽ được kiểm tra ngay lập tức. Sau đó, bạn sẽ tăng hiệu suất cho các chuỗi có câu trả lời tích cực (nhưng không phải cho những chuỗi không có câu trả lời phù hợp).