Muốn tham gia với tùy chọn giải quyết công việc của bạn bằng BigQuery thuần túy (SQL chuẩn)
Điều kiện tiên quyết / giả định :dữ liệu nguồn nằm trong sandbox.temp.id1_id2_pairs
Bạn nên thay thế bảng này bằng dữ liệu của riêng bạn hoặc nếu bạn muốn kiểm tra bằng dữ liệu giả từ câu hỏi của mình - bạn có thể tạo bảng này như bên dưới (tất nhiên là thay thế sandbox.temp với project.dataset của riêng bạn )
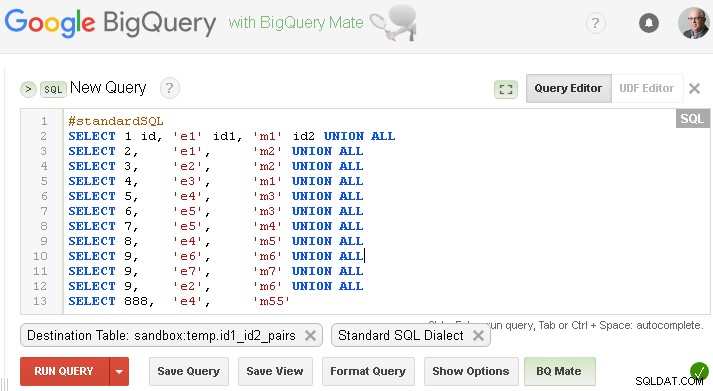
Đảm bảo rằng bạn đặt bảng đích tương ứng
Lưu ý :bạn có thể tìm thấy tất cả các Truy vấn tương ứng (dưới dạng văn bản) ở cuối câu trả lời này, nhưng hiện tại tôi đang minh họa câu trả lời của mình bằng ảnh chụp màn hình - vì vậy tất cả đều được trình bày - các tùy chọn truy vấn, kết quả và sử dụng
Vì vậy, sẽ có ba bước:
Bước 1 - Khởi tạo
Ở đây, chúng tôi chỉ thực hiện nhóm ban đầu của id1 dựa trên các kết nối với id2:
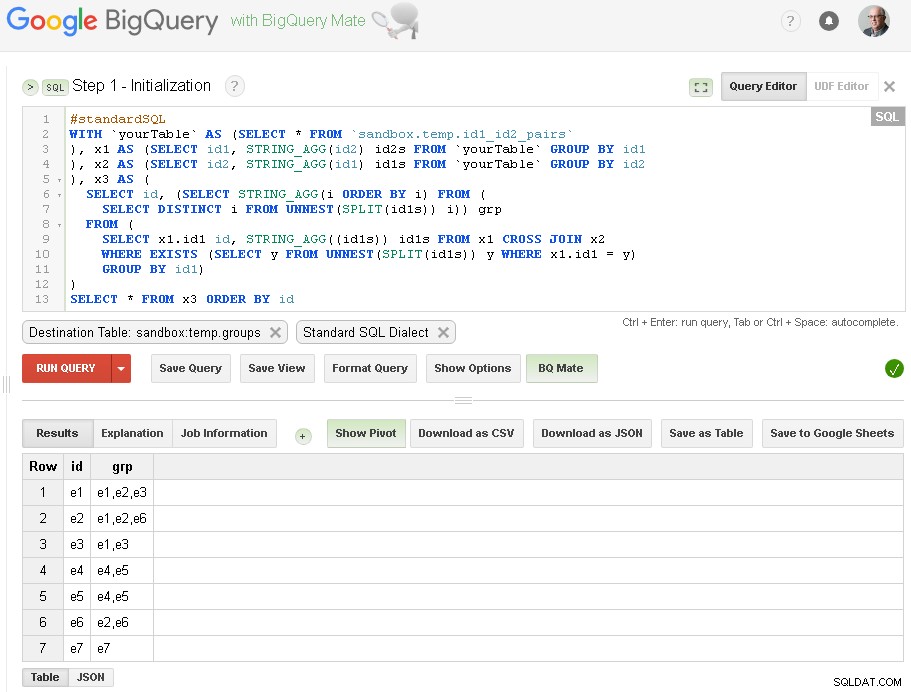
Như bạn có thể thấy ở đây - chúng tôi đã tạo danh sách tất cả các giá trị id1 với các kết nối tương ứng dựa trên kết nối một cấp đơn giản thông qua id2
Bảng đầu ra là sandbox.temp.groups
Bước 2 - Lặp lại nhóm
Trong mỗi lần lặp lại, chúng tôi sẽ làm phong phú thêm nhóm dựa trên các nhóm đã được thiết lập.
Nguồn của Truy vấn là bảng đầu ra của Bước trước đó (sandbox.temp.groups ) và Đích là cùng một bảng (sandbox.temp.groups ) với Ghi đè
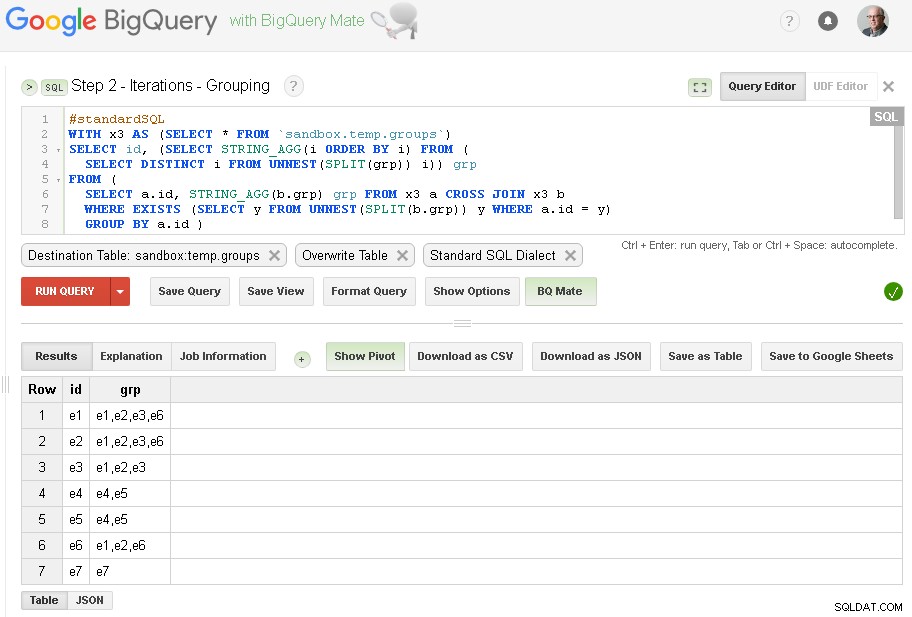
Chúng tôi sẽ tiếp tục lặp lại cho đến khi số lượng các nhóm được tìm thấy sẽ giống như trong lần lặp trước
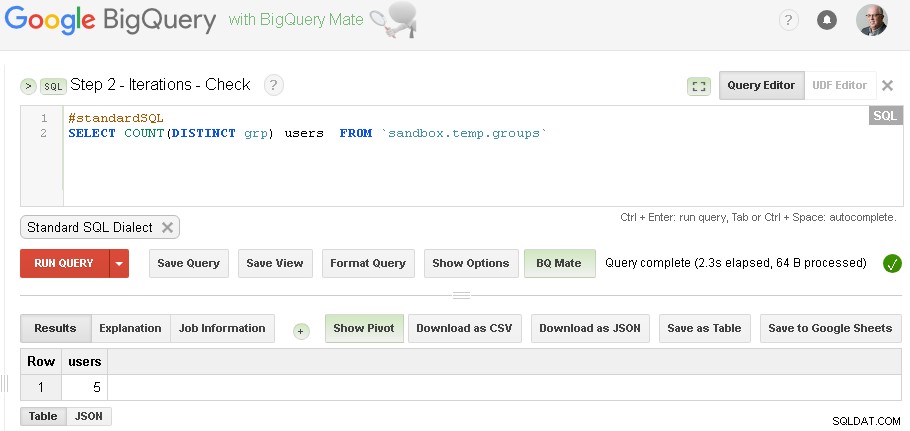
Lưu ý :bạn chỉ có thể mở hai Tab giao diện người dùng Web BigQuery (như được hiển thị ở trên) và không cần thay đổi bất kỳ mã nào, chỉ cần chạy Nhóm và sau đó Kiểm tra lại nhiều lần cho đến khi hội tụ lặp lại
(đối với dữ liệu cụ thể mà tôi đã sử dụng trong phần điều kiện tiên quyết - tôi có ba lần lặp - lần lặp đầu tiên tạo ra 5 người dùng, lần lặp thứ hai tạo ra 3 người dùng và lần lặp thứ ba tạo lại 3 người dùng - điều này cho thấy rằng chúng tôi đã thực hiện với các lần lặp.
Tất nhiên, trong trường hợp thực tế - số lần lặp có thể nhiều hơn chỉ ba - vì vậy chúng tôi cần một số loại tự động hóa (xem phần tương ứng ở cuối câu trả lời).
Bước 3 - Nhóm cuối cùng
Khi hoàn thành nhóm id1 - chúng tôi có thể thêm nhóm cuối cùng cho id2
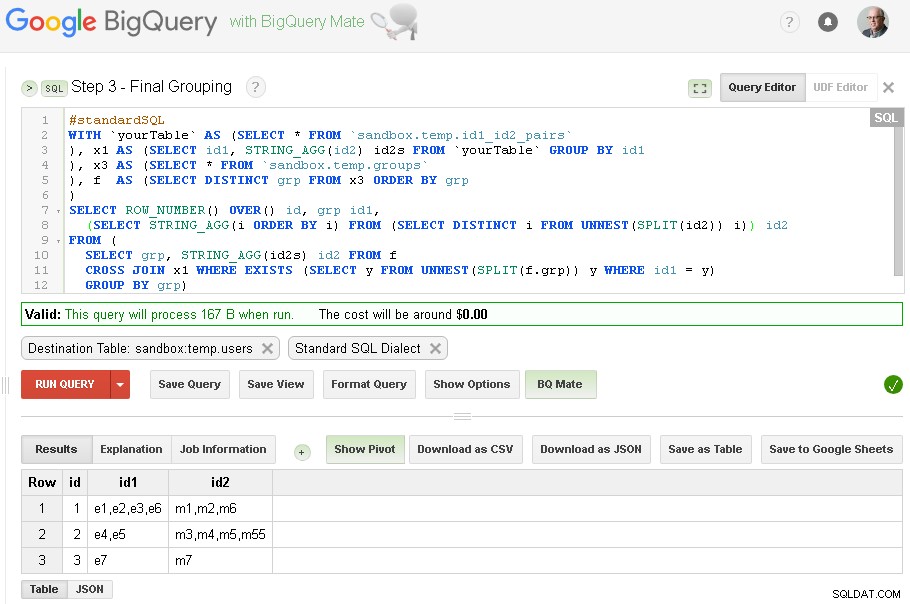
Kết quả cuối cùng bây giờ là trong sandbox.temp.users bảng
Truy vấn đã sử dụng (đừng quên đặt bảng đích tương ứng và ghi đè khi cần theo logic và ảnh chụp màn hình được mô tả ở trên):
Điều kiện tiên quyết:
#standardSQL
SELECT 1 id, 'e1' id1, 'm1' id2 UNION ALL
SELECT 2, 'e1', 'm2' UNION ALL
SELECT 3, 'e2', 'm2' UNION ALL
SELECT 4, 'e3', 'm1' UNION ALL
SELECT 5, 'e4', 'm3' UNION ALL
SELECT 6, 'e5', 'm3' UNION ALL
SELECT 7, 'e5', 'm4' UNION ALL
SELECT 8, 'e4', 'm5' UNION ALL
SELECT 9, 'e6', 'm6' UNION ALL
SELECT 9, 'e7', 'm7' UNION ALL
SELECT 9, 'e2', 'm6' UNION ALL
SELECT 888, 'e4', 'm55'
Bước 1
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x2 AS (SELECT id2, STRING_AGG(id1) id1s FROM `yourTable` GROUP BY id2
), x3 AS (
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(id1s)) i)) grp
FROM (
SELECT x1.id1 id, STRING_AGG((id1s)) id1s FROM x1 CROSS JOIN x2
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(id1s)) y WHERE x1.id1 = y)
GROUP BY id1)
)
SELECT * FROM x3
Bước 2 - Phân nhóm
#standardSQL
WITH x3 AS (select * from `sandbox.temp.groups`)
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(grp)) i)) grp
FROM (
SELECT a.id, STRING_AGG(b.grp) grp FROM x3 a CROSS JOIN x3 b
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(b.grp)) y WHERE a.id = y)
GROUP BY a.id )
Bước 2 - Kiểm tra
Người dùng#standardSQL
SELECT COUNT(DISTINCT grp) users FROM `sandbox.temp.groups`
Bước 3
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x3 as (select * from `sandbox.temp.groups`
), f AS (SELECT DISTINCT grp FROM x3 ORDER BY grp
)
SELECT ROW_NUMBER() OVER() id, grp id1,
(SELECT STRING_AGG(i ORDER BY i) FROM (SELECT DISTINCT i FROM UNNEST(SPLIT(id2)) i)) id2
FROM (
SELECT grp, STRING_AGG(id2s) id2 FROM f
CROSS JOIN x1 WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(f.grp)) y WHERE id1 = y)
GROUP BY grp)
Tự động hóa :
Tất nhiên, "quy trình" ở trên có thể được thực hiện theo cách thủ công trong trường hợp nếu các lần lặp hội tụ nhanh - vì vậy bạn sẽ kết thúc với 10-20 lần chạy. Nhưng trong nhiều trường hợp thực tế hơn, bạn có thể dễ dàng tự động hóa việc này với bất kỳ ứng dụng khách
nào sự lựa chọn của bạn