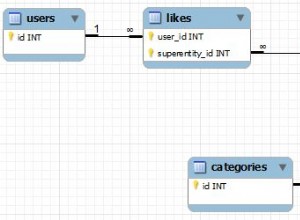
Bạn có thể thử một cái gì đó như thế này (mặc dù nó không thực tế đối với tôi để kiểm tra điều này)
SELECT
sac.surveyId,
q.cat,
SUM((sac.answer_id*q.weight))/SUM(q.weight) AS score,
user.division_id,
user.unit_id,
user.department_id,
user.team_id,
division.division_name,
unit.unit_name,
dpt.department_name,
team.team_name
FROM survey_answers_cache sac
JOIN
(
SELECT
s.surveyId,
sc.subcluster_id
FROM
surveys s
JOIN subcluster sc ON s.subcluster_id = sc.subcluster_id
JOIN cluster c ON sc.cluster_id = c.cluster_id
WHERE
c.cluster_id=? AND sc.subcluster_id=? AND s.active=0 AND s.prepare=0
) AS v ON v.surveyid = sac.surveyid
JOIN user ON user.user_id = sac.user_id
JOIN questions q ON q.question_id = sac.question_id
JOIN division ON division.division_id = user.division_id
LEFT JOIN unit ON unit.unit_id = user.unit_id
LEFT JOIN department dpt ON dpt.department_id = user.department_id
LEFT JOIN team ON team.team_id = user.team_id
GROUP BY user.team_id, v.surveyId, q.cat
ORDER BY v.surveyId, user.team_id, q.cat ASC
Vì vậy, tôi hy vọng mình đã không làm hỏng bất cứ điều gì.
Dù sao, ý tưởng là trong truy vấn bên trong, bạn chỉ chọn các hàng bạn cần dựa trên điều kiện vị trí của bạn. Điều này sẽ tạo một bảng tmp nhỏ hơn vì nó chỉ kéo 2 trường cả hai int.
Sau đó, trong truy vấn bên ngoài, bạn tham gia vào các bảng mà bạn thực sự lấy phần còn lại của dữ liệu từ đó, sắp xếp và nhóm. Bằng cách này, bạn đang sắp xếp và nhóm trên một tập dữ liệu nhỏ hơn. Và mệnh đề where của bạn có thể chạy theo cách tối ưu nhất.
Bạn thậm chí có thể bỏ qua một số bảng này vì bạn chỉ lấy dữ liệu từ một vài trong số chúng, nhưng không nhìn thấy toàn bộ lược đồ và khó có thể nói nó liên quan như thế nào.
Nhưng chỉ nói chung chung phần này (Truy vấn phụ)
SELECT
s.surveyId,
sc.subcluster_id
FROM
surveys s
JOIN subcluster sc ON s.subcluster_id = sc.subcluster_id
JOIN cluster c ON sc.cluster_id = c.cluster_id
WHERE
c.cluster_id=? AND sc.subcluster_id=? AND s.active=0 AND s.prepare=0
Là điều bị ảnh hưởng trực tiếp bởi mệnh đề WHERE của bạn. Hãy xem để chúng tôi có thể tối ưu hóa phần này, sau đó sử dụng nó để kết hợp phần còn lại của dữ liệu bạn cần.
Ví dụ về việc xóa bảng có thể dễ dàng suy ra từ những điều trên, hãy xem xét điều này
SELECT
s.surveyId,
sc.subcluster_id
FROM
surveys s
JOIN subcluster sc ON s.subcluster_id = sc.subcluster_id
WHERE
sc.cluster_id=? AND sc.subcluster_id=? AND s.active=0 AND s.prepare=0
c bảng cluster không bao giờ được sử dụng để lấy dữ liệu từ, chỉ dành cho nơi. Như vậy là không
JOIN cluster c ON sc.cluster_id = c.cluster_id
WHERE
c.cluster_id=?
Giống hoặc tương đương với
WHERE
sc.cluster_id=?
Và do đó, chúng tôi có thể loại bỏ hoàn toàn sự tham gia đó.