Các hàm RANK, DENSE_RANK và ROW_NUMBER được sử dụng để truy xuất một giá trị số nguyên ngày càng tăng. Chúng bắt đầu bằng một giá trị dựa trên điều kiện được áp đặt bởi mệnh đề ORDER BY. Tất cả các chức năng này yêu cầu mệnh đề ORDER BY để hoạt động bình thường. Trong trường hợp dữ liệu được phân vùng, bộ đếm số nguyên được đặt lại thành 1 cho mỗi phân vùng.
Trong bài viết này, chúng ta sẽ nghiên cứu chi tiết các hàm RANK, DENSE_RANK và ROW_NUMBER, nhưng trước đó, hãy tạo dữ liệu giả mà các hàm này có thể được sử dụng trừ khi cơ sở dữ liệu của bạn được sao lưu đầy đủ.
Chuẩn bị dữ liệu giả
Thực thi tập lệnh sau để tạo cơ sở dữ liệu có tên ShowRoom và chứa một bảng có tên Ô tô (chứa 15 bản ghi ngẫu nhiên về ô tô):
CREATE Database ShowRoom; GO USE ShowRoom; CREATE TABLE Cars ( id INT, name VARCHAR(50) NOT NULL, company VARCHAR(50) NOT NULL, power INT NOT NULL ) USE ShowRoom INSERT INTO Cars VALUES (1, 'Corrolla', 'Toyota', 1800), (2, 'City', 'Honda', 1500), (3, 'C200', 'Mercedez', 2000), (4, 'Vitz', 'Toyota', 1300), (5, 'Baleno', 'Suzuki', 1500), (6, 'C500', 'Mercedez', 5000), (7, '800', 'BMW', 8000), (8, 'Mustang', 'Ford', 5000), (9, '208', 'Peugeot', 5400), (10, 'Prius', 'Toyota', 3200), (11, 'Atlas', 'Volkswagen', 5000), (12, '110', 'Bugatti', 8000), (13, 'Landcruiser', 'Toyota', 3000), (14, 'Civic', 'Honda', 1800), (15, 'Accord', 'Honda', 2000)
Hàm RANK
Hàm RANK được sử dụng để truy xuất các hàng được xếp hạng dựa trên điều kiện của mệnh đề ORDER BY. Ví dụ:nếu bạn muốn tìm tên của chiếc ô tô có công suất cao thứ ba, bạn có thể sử dụng Hàm RANK.
Hãy xem hoạt động của Hàm RANK:
SELECT name,company, power, RANK() OVER(ORDER BY power DESC) AS PowerRank FROM Cars
Tập lệnh trên tìm và xếp hạng tất cả các bản ghi trong bảng Cars và sắp xếp chúng theo thứ tự sức mạnh giảm dần. Đầu ra trông giống như sau:
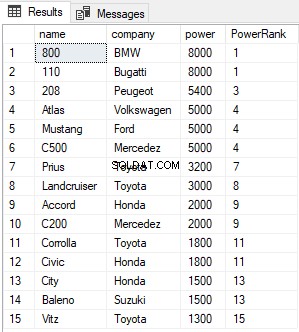
Cột PowerRank trong bảng trên chứa RANK của những chiếc xe được sắp xếp theo thứ tự giảm dần sức mạnh của chúng. Một điều thú vị về hàm RANK là nếu có sự ràng buộc giữa N bản ghi trước đó cho giá trị trong cột ORDER BY, thì các hàm RANK sẽ bỏ qua N-1 vị trí tiếp theo trước khi tăng bộ đếm. Ví dụ, trong kết quả trên, có một sự ràng buộc cho các giá trị trong cột nguồn giữa hàng 1 và hàng 2, do đó hàm RANK bỏ qua (2-1 =1) một bản ghi tiếp theo và nhảy trực tiếp đến hàng thứ 3.
Hàm RANK có thể được sử dụng kết hợp với mệnh đề PARTITION BY. Trong trường hợp đó, thứ hạng sẽ được đặt lại cho mỗi phân vùng mới. Hãy xem tập lệnh sau:
SELECT name,company, power, RANK() OVER(PARTITION BY company ORDER BY power DESC) AS PowerRank FROM Cars
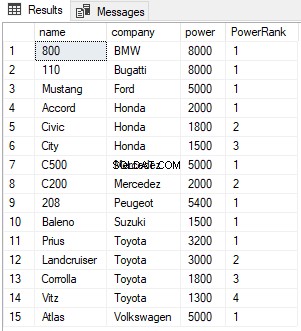
Trong tập lệnh trên, chúng tôi phân vùng kết quả theo cột công ty. Bây giờ đối với mỗi công ty, RANK sẽ được đặt lại thành 1 như hình dưới đây:
Hàm DENSE_RANK
Hàm DENSE_RANK tương tự như hàm RANK tuy nhiên hàm DENSE_RANK không bỏ qua bất kỳ cấp nào nếu có sự ràng buộc giữa các cấp của các bản ghi trước đó. Hãy xem tập lệnh sau.
SELECT name,company, power, RANK() OVER(PARTITION BY company ORDER BY power DESC) AS PowerRank FROM Cars
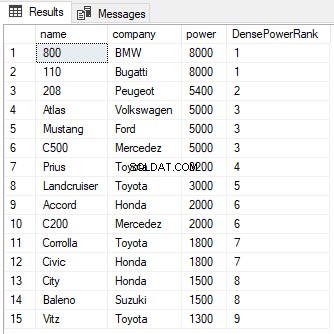
Bạn có thể thấy từ đầu ra rằng mặc dù có sự ràng buộc giữa các cấp bậc của hai hàng đầu tiên, nhưng xếp hạng tiếp theo không bị bỏ qua và đã được gán giá trị là 2 thay vì 3. Cũng như với hàm RANK, mệnh đề PARTITION BY có thể cũng được sử dụng với hàm DENSE_RANK như được hiển thị bên dưới:
SELECT name,company, power, DENSE_RANK() OVER(PARTITION BY company ORDER BY power DESC) AS DensePowerRank FROM Cars
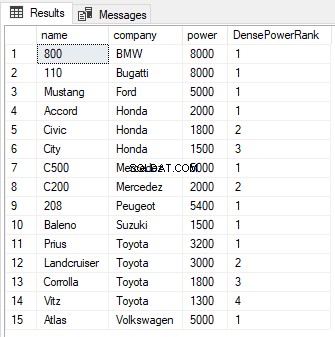
ROW_NUMBER Hàm
Không giống như các hàm RANK và DENSE_RANK, hàm ROW_NUMBER chỉ trả về số hàng của các bản ghi được sắp xếp bắt đầu bằng 1. Ví dụ:nếu các hàm RANK và DENSE_RANK của hai bản ghi đầu tiên trong cột ORDER BY bằng nhau, thì cả hai đều được gán 1 dưới dạng RANK và DENSE_RANK của họ. Tuy nhiên, hàm ROW_NUMBER sẽ gán giá trị 1 và 2 cho các hàng đó mà không tính đến việc chúng được tính như nhau. Thực thi tập lệnh sau để xem hàm ROW_NUMBER đang hoạt động.
SELECT name,company, power, ROW_NUMBER() OVER(ORDER BY power DESC) AS RowRank FROM Cars
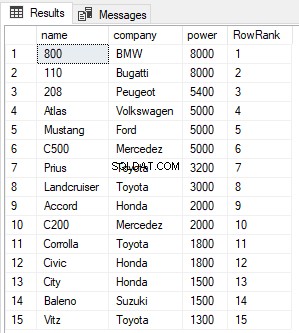
Từ đầu ra, bạn có thể thấy rằng hàm ROW_NUMBER chỉ cần gán một số hàng mới cho mỗi bản ghi bất kể giá trị của nó.
Mệnh đề PARTITION BY cũng có thể được sử dụng với hàm ROW_NUMBER như được hiển thị bên dưới:
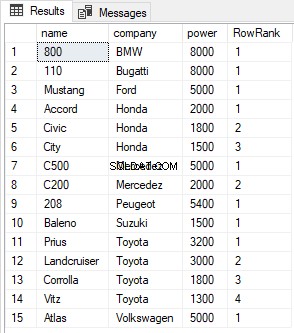
SELECT name, company, power, ROW_NUMBER() OVER(PARTITION BY company ORDER BY power DESC) AS RowRank FROM Cars
Đầu ra trông giống như sau:
Điểm tương đồng giữa các Hàm RANK, DENSE_RANK và ROW_NUMBER
Các Hàm RANK, DENSE_RANK và ROW_NUMBER có những điểm giống nhau sau:
1- Tất cả chúng đều yêu cầu thứ tự theo mệnh đề.
2- Tất cả chúng đều trả về một số nguyên tăng dần với giá trị cơ bản là 1.
> 3- Khi được kết hợp với mệnh đề PARTITION BY, tất cả các hàm này đặt lại giá trị số nguyên trả về thành 1 như chúng ta đã thấy.
4- Nếu không có giá trị trùng lặp nào trong cột được mệnh đề ORDER BY sử dụng, các các hàm trả về cùng một đầu ra.
Để minh họa điểm cuối cùng, hãy tạo một bảng mới Car1 trong cơ sở dữ liệu ShowRoom không có giá trị trùng lặp trong cột nguồn. Thực thi tập lệnh sau:
USE ShowRoom; CREATE TABLE Cars1 ( id INT, name VARCHAR(50) NOT NULL, company VARCHAR(50) NOT NULL, power INT NOT NULL ) INSERT INTO Cars1 VALUES (1, 'Corrolla', 'Toyota', 1800), (2, 'City', 'Honda', 1500), (3, 'C200', 'Mercedez', 2000), (4, 'Vitz', 'Toyota', 1300), (5, 'Baleno', 'Suzuki', 2500), (6, 'C500', 'Mercedez', 5000), (7, '800', 'BMW', 8000), (8, 'Mustang', 'Ford', 4000), (9, '208', 'Peugeot', 5400), (10, 'Prius', 'Toyota', 3200) The cars1 table has no duplicate values. Now let’s execute the RANK, DENSE_RANK and ROW_NUMBER functions on the Cars1 table ORDER BY power column. Execute the following script: SELECT name,company, power, RANK() OVER(ORDER BY power DESC) AS [Rank], DENSE_RANK() OVER(ORDER BY power DESC) AS [Dense Rank], ROW_NUMBER() OVER(ORDER BY power DESC) AS [Row Number] FROM Cars1
Đầu ra trông giống như sau:
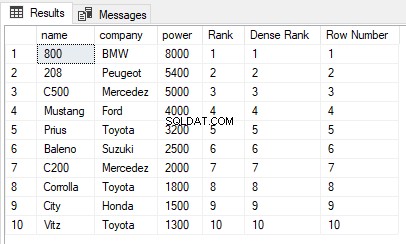
Bạn có thể thấy rằng không có giá trị trùng lặp nào trong cột nguồn đang được sử dụng trong mệnh đề ORDER BY, do đó đầu ra của các hàm RANK, DENSE_RANK và ROW_NUMBER đều giống nhau.
Sự khác biệt giữa các Hàm RANK, DENSE_RANK và ROW_NUMBER
Sự khác biệt duy nhất giữa hàm RANK, DENSE_RANK và ROW_NUMBER là khi có các giá trị trùng lặp trong cột được sử dụng trong Mệnh đề ORDER BY.
Nếu bạn quay lại bảng Cars trong cơ sở dữ liệu ShowRoom, bạn có thể thấy nó chứa rất nhiều các giá trị trùng lặp. Hãy thử tìm RANK, DENSE_RANK và ROW_NUMBER của bảng Cars1 được sắp xếp theo sức mạnh. Thực thi tập lệnh sau:
CHỌN tên, công ty, quyền lực,
RANK() OVER(ORDER BY power DESC) AS [Rank], DENSE_RANK() OVER(ORDER BY power DESC) AS [Dense Rank], ROW_NUMBER() OVER(ORDER BY power DESC) AS [Row Number] FROM Cars
Đầu ra trông giống như sau:
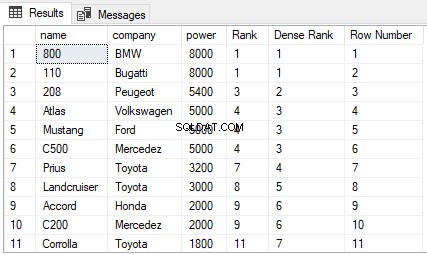
Từ đầu ra, bạn có thể thấy rằng hàm RANK bỏ qua N-1 cấp tiếp theo nếu có sự ràng buộc giữa N cấp trước đó. Mặt khác, hàm DENSE_RANK không bỏ qua các cấp nếu có sự ràng buộc giữa các cấp. Cuối cùng, hàm ROW_NUMBER không liên quan đến xếp hạng. Nó chỉ trả về số hàng của các bản ghi đã được sắp xếp. Ngay cả khi có các bản ghi trùng lặp trong cột được sử dụng trong mệnh đề ORDER BY, hàm ROW_NUMBER sẽ không trả về các giá trị trùng lặp. Thay vào đó, nó sẽ tiếp tục tăng bất kể các giá trị trùng lặp.
Các liên kết hữu ích:
Để tìm hiểu thêm về các hàm ROW_NUMBER (), RANK () và DENSE_RANK (), hãy đọc bài viết tuyệt vời của Ahmad Yaseen:
Phương thức xếp hạng các hàng trong SQL Server:ROW_NUMBER (), RANK (), DENSE_RANK () và NTILE ()