Chỉ mục là công cụ tăng tốc độ trong cơ sở dữ liệu SQL. Chúng có thể được phân cụm hoặc không theo nhóm. Nhưng nó có nghĩa là gì và bạn nên áp dụng từng loại ở đâu?
Tôi biêt cám giác này. Tôi đã từng ở đó. Những người lần đầu tiên thường nhầm lẫn về việc sử dụng chỉ mục nào trên các cột nào. Tuy nhiên, ngay cả các chuyên gia cũng cần phải suy nghĩ kỹ vấn đề này trước khi đưa ra quyết định, và các tình huống khác nhau đòi hỏi các quyết định khác nhau. Như bạn sẽ thấy ở phần sau, có những truy vấn trong đó chỉ mục được phân nhóm sẽ tỏa sáng so với chỉ mục không được phân nhóm và ngược lại.
Tuy nhiên, trước tiên, chúng ta phải biết từng người trong số họ. Nếu bạn đang tìm kiếm thông tin tương tự, hôm nay là ngày may mắn của bạn.
Bài viết này sẽ cho bạn biết những chỉ mục này là gì và khi nào sử dụng từng chỉ mục. Tất nhiên, sẽ có các mẫu mã để bạn dùng thử trong thực tế. Vì vậy, hãy lấy khoai tây chiên hoặc bánh pizza của bạn và một ít soda hoặc cà phê và sẵn sàng đắm mình trong hành trình sâu sắc này.
Sẵn sàng chưa?
Chỉ mục theo cụm là gì
Chỉ mục được phân nhóm là chỉ mục xác định thứ tự sắp xếp vật lý của các hàng trong bảng hoặc chế độ xem.
Để xem điều này ở dạng thực tế, hãy xem Nhân viên bảng trong AdventureWorks2017 cơ sở dữ liệu.
Khóa chính cũng là một chỉ mục được phân nhóm và khóa dựa trên BusinessEntityID cột. Khi bạn thực hiện CHỌN trên bảng này mà không có LỆNH THEO, bạn sẽ thấy rằng nó được sắp xếp theo khóa chính.
Hãy thử nó cho chính mình bằng cách sử dụng mã bên dưới:
USE AdventureWorks2017
GO
SELECT TOP 10 * FROM HumanResources.Employee
GO
Bây giờ, hãy xem kết quả trong Hình 1:
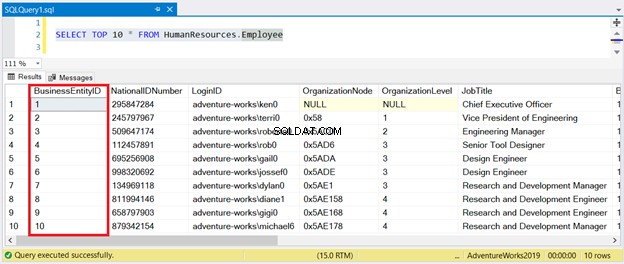
Như bạn có thể thấy, bạn không cần phải sắp xếp tập hợp kết quả với BusinessEntityID . Chỉ mục được phân nhóm đảm nhiệm việc đó.
Không giống như các chỉ mục không được phân cụm, bạn chỉ có thể có 1 chỉ mục được phân nhóm cho mỗi bảng. Điều gì sẽ xảy ra nếu chúng tôi thử điều này trên Nhân viên bảng?
CREATE CLUSTERED INDEX IX_Employee_NationalID
ON HumanResources.Employee (NationalIDNumber)
GO
Chúng tôi gặp một lỗi tương tự bên dưới:
Msg 1902, Level 16, State 3, Line 4
Cannot create more than one clustered index on table 'HumanResources.Employee'. Drop the existing clustered index 'PK_Employee_BusinessEntityID' before creating another.
Khi nào thì sử dụng chỉ mục theo cụm?
Một cột là ứng cử viên tốt nhất cho chỉ mục theo nhóm nếu một trong những điều sau là đúng:
- Nó được sử dụng trong một số lượng lớn các truy vấn trong mệnh đề WHERE và các phép nối.
- Nó sẽ được sử dụng làm khóa ngoại cho một bảng khác và cuối cùng là để tham gia.
- Giá trị cột duy nhất.
- Giá trị sẽ ít có khả năng thay đổi hơn.
- Cột đó được sử dụng để truy vấn một dải giá trị. Các toán tử như>, <,> =, <=hoặc BETWEEN được sử dụng với cột trong mệnh đề WHERE.
Nhưng các chỉ mục được phân nhóm sẽ không tốt nếu cột hoặc các cột
- thường xuyên thay đổi
- là các khóa rộng hoặc sự kết hợp của các cột có kích thước khóa lớn.
Ví dụ
Các chỉ mục được phân cụm có thể được tạo bằng cách sử dụng mã T-SQL hoặc bất kỳ công cụ GUI nào của SQL Server. Bạn có thể làm điều đó trong T-SQL khi tạo bảng, như sau:
CREATE TABLE [Person].[Person](
[BusinessEntityID] [int] NOT NULL,
[PersonType] [nchar](2) NOT NULL,
[NameStyle] [dbo].[NameStyle] NOT NULL,
[Title] [nvarchar](8) NULL,
[FirstName] [dbo].[Name] NOT NULL,
[MiddleName] [dbo].[Name] NULL,
[LastName] [dbo].[Name] NOT NULL,
[Suffix] [nvarchar](10) NULL,
[EmailPromotion] [int] NOT NULL,
[AdditionalContactInfo] [xml](CONTENT [Person].[AdditionalContactInfoSchemaCollection]) NULL,
[Demographics] [xml](CONTENT [Person].[IndividualSurveySchemaCollection]) NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED
(
[BusinessEntityID] ASC
)
GO
Hoặc, bạn có thể thực hiện việc này bằng cách sử dụng ALTER TABLE sau tạo bảng mà không có chỉ mục được phân nhóm:
ALTER TABLE Person.Person ADD CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED (BusinessEntityID)
GO
Một cách khác là sử dụng CREATE CLUSTERED INDEX:
CREATE CLUSTERED INDEX [PK_Person_BusinessEntityID] ON Person.Person (BusinessEntityID)
GO
Một giải pháp thay thế khác là sử dụng công cụ SQL Server như SQL Server Management Studio hoặc dbForge Studio cho SQL Server.
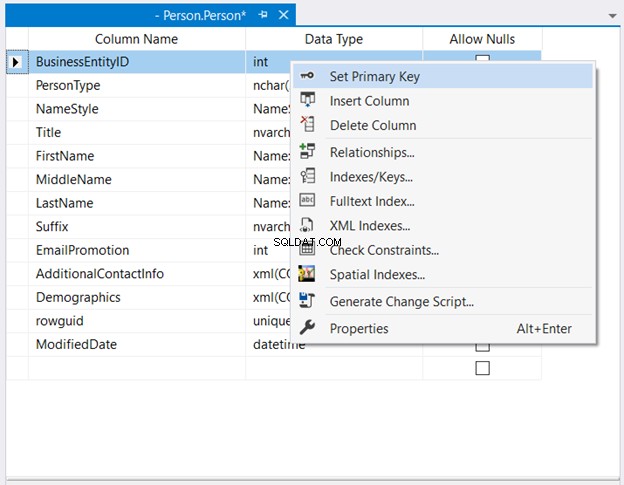
Trong Trình khám phá đối tượng , mở rộng cơ sở dữ liệu và các nút bảng. Sau đó, nhấp chuột phải vào bảng mong muốn và chọn Thiết kế . Cuối cùng, nhấp chuột phải vào cột bạn muốn làm khóa chính> Đặt khóa chính > Lưu các thay đổi vào bảng.
Hình 2 bên dưới cho thấy nơi BusinessEntityID được đặt làm khóa chính.
Ngoài việc tạo chỉ mục nhóm một cột, bạn có thể sử dụng nhiều cột. Xem ví dụ trong T-SQL:
CREATE CLUSTERED INDEX [IX_Person_LastName_FirstName_MiddleName] ON [Person].[Person]
(
[LastName] ASC,
[FirstName] ASC,
[MiddleName] ASC
)
GO
Sau khi tạo chỉ mục được nhóm này, Người bảng sẽ được sắp xếp vật lý theo Họ , Tên họ và MiddleName .
Một trong những ưu điểm của phương pháp này là cải thiện hiệu suất truy vấn dựa trên tên. Bên cạnh đó, nó sắp xếp kết quả theo tên mà không chỉ định ORDER BY. Nhưng lưu ý rằng nếu tên thay đổi, bảng sẽ phải được sắp xếp lại. Mặc dù điều này sẽ không xảy ra hàng ngày, nhưng tác động có thể rất lớn nếu bảng quá lớn.
Chỉ mục không phân cụm là gì
Chỉ mục không phân cụm là chỉ mục có khóa và con trỏ đến các hàng hoặc các khóa chỉ mục được phân cụm. Chỉ mục này có thể áp dụng cho cả bảng và dạng xem.
Không giống như các chỉ mục được phân cụm, ở đây cấu trúc tách biệt với bảng. Vì nó riêng biệt, nó cần một con trỏ đến các hàng trong bảng còn được gọi là bộ định vị hàng. Do đó, mỗi mục nhập trong chỉ mục không phân cụm chứa một bộ định vị và một giá trị khóa.
Các chỉ mục không phân cụm không sắp xếp bảng dựa trên khóa.
Khóa chỉ mục cho các chỉ mục không phân cụm có kích thước tối đa là 1700 byte. Bạn có thể bỏ qua giới hạn này bằng cách thêm các cột được bao gồm. Phương pháp này tốt nếu truy vấn của bạn cần bao gồm nhiều cột hơn mà không tăng kích thước khóa.
Bạn cũng có thể tạo các chỉ mục không phân cụm đã lọc. Điều này sẽ giảm chi phí duy trì chỉ mục và bộ nhớ trong khi cải thiện hiệu suất truy vấn.
Khi nào sử dụng Chỉ mục không phân cụm?
Một hoặc các cột là ứng cử viên tốt cho các chỉ mục không phân cụm nếu điều sau là đúng:
- Cột hoặc các cột được sử dụng trong mệnh đề WHERE hoặc phép nối.
- Truy vấn sẽ không trả về một tập hợp kết quả lớn.
- Đối sánh chính xác trong mệnh đề WHERE sử dụng toán tử bình đẳng là cần thiết.
Ví dụ
Lệnh này sẽ tạo một chỉ mục duy nhất, không phân cụm trong Nhân viên bảng:
CREATE UNIQUE NONCLUSTERED INDEX [AK_Employee_NationalIDNumber] ON [HumanResources].[Employee]
(
[NationalIDNumber] ASC
)
GO
Ngoài bảng, bạn có thể tạo chỉ mục không phân cụm cho chế độ xem:
CREATE NONCLUSTERED INDEX [IDX_vProductAndDescription_ProductModel] ON [Production].[vProductAndDescription]
(
[ProductModel] ASC
)
GO
Các câu hỏi phổ biến khác và các câu trả lời hài lòng
Sự khác biệt giữa Chỉ mục được phân nhóm và không được phân nhóm là gì?
Từ những gì bạn đã thấy trước đó, bạn đã có thể hình thành ý tưởng về các chỉ mục được phân nhóm và không phân nhóm khác nhau như thế nào. Nhưng hãy để nó trên bàn để dễ tham khảo.
| Thông tin | Chỉ mục theo cụm | Chỉ mục không theo nhóm |
| Áp dụng cho | Bảng và chế độ xem | Bảng và chế độ xem |
| Được phép trên mỗi Bảng | 1 | 999 |
| Kích thước khóa | 900 byte | 1700 byte |
| Các cột trên mỗi khóa chỉ mục | 32 | 32 |
| Tốt cho | Truy vấn phạm vi (>, <,> =, <=, GIỮA) | Đối sánh chính xác (=) |
| Các cột được bao gồm không phải khóa | Không được phép | Được phép |
| Lọc với điều kiện | Không được phép | Được phép |
Khóa chính nên được nhóm hay chỉ mục không theo nhóm?
Khóa chính là một ràng buộc. Sau khi bạn đặt một cột làm khóa chính, một chỉ mục được nhóm sẽ tự động được tạo ra từ nó, trừ khi một chỉ mục được nhóm hiện có đã có sẵn.
Đừng nhầm lẫn giữa khóa chính với chỉ mục được phân nhóm! Khóa chính cũng có thể là khóa chỉ mục được phân cụm. Nhưng khóa chỉ mục được phân nhóm có thể là một cột khác không phải là khóa chính.
Hãy lấy một ví dụ khác. Trong Người bảng của AdventureWorks201 7, chúng tôi có BusinessEntityID khóa chính. Nó cũng là khóa chỉ mục được phân cụm. Bạn có thể bỏ chỉ mục theo nhóm đó. Sau đó, tạo chỉ mục theo nhóm dựa trên Họ , Tên họ và Tên đệm . Khóa chính vẫn là BusinessEntityID cột.
Nhưng các khóa chính của bạn có nên luôn được nhóm lại không?
Nó phụ thuộc. Xem lại câu hỏi về thời điểm sử dụng chỉ mục theo nhóm.
Nếu một cột hoặc các cột xuất hiện trong mệnh đề WHERE của bạn trong rất nhiều truy vấn, thì đây là một ứng cử viên cho chỉ mục được phân cụm. Nhưng một vấn đề khác được xem xét là độ rộng của khóa chỉ mục được phân cụm. Quá rộng - và kích thước của mỗi chỉ mục không phân cụm sẽ tăng lên nếu chúng tồn tại. Hãy nhớ rằng các chỉ mục không phân cụm cũng sử dụng khóa chỉ mục được phân cụm làm con trỏ. Vì vậy, hãy giữ khóa chỉ mục nhóm của bạn càng thu hẹp càng tốt.
Nếu một số lượng lớn các truy vấn sử dụng khóa chính trong mệnh đề WHERE, hãy để nó làm khóa chỉ mục nhóm. Nếu không, hãy tạo khóa chính của bạn dưới dạng chỉ mục không phân cụm.
Nhưng nếu bạn vẫn không chắc chắn thì sao? Sau đó, bạn có thể đánh giá lợi ích hiệu suất của một cột khi nó được nhóm hoặc không nhóm. Vì vậy, hãy theo dõi phần tiếp theo về nó.
Cái nào nhanh hơn:Chỉ mục theo cụm hay không theo nhóm?
Câu hỏi hay. Không có quy tắc chung. Bạn cần kiểm tra các lần đọc logic và kế hoạch thực thi các truy vấn của mình.
Thử nghiệm ngắn của chúng tôi sẽ bao gồm các bản sao của các bảng sau từ AdventureWorks2017 cơ sở dữ liệu:
- Người
- BusinessEntityAddress
- Địa chỉ
- AddressType
Đây là tập lệnh:
IF NOT EXISTS(SELECT name FROM sys.databases WHERE name = 'TestDatabase')
BEGIN
CREATE DATABASE TestDatabase
END
USE TestDatabase
GO
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkClustered FROM AdventureWorks2017.Person.Person
ALTER TABLE Person_pkClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID2] PRIMARY KEY CLUSTERED (BusinessEntityID)
CREATE NONCLUSTERED INDEX [IX_Person_Name2] ON Person_pkClustered (LastName, FirstName, MiddleName, Suffix)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkNonClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkNonClustered FROM AdventureWorks2017.Person.Person
CREATE CLUSTERED INDEX [IX_Person_Name1] ON Person_pkNonClustered (LastName, FirstName, MiddleName, Suffix)
ALTER TABLE Person_pkNonClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID1] PRIMARY KEY NONCLUSTERED (BusinessEntityID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'AddressType')
BEGIN
SELECT * INTO AddressType FROM AdventureWorks2017.Person.AddressType
ALTER TABLE AddressType
ADD CONSTRAINT [PK_AddressType] PRIMARY KEY CLUSTERED (AddressTypeID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Address')
BEGIN
SELECT * INTO Address FROM AdventureWorks2017.Person.Address
ALTER TABLE Address
ADD CONSTRAINT [PK_Address] PRIMARY KEY CLUSTERED (AddressID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'BusinessEntityAddress')
BEGIN
SELECT * INTO BusinessEntityAddress FROM AdventureWorks2017.Person.BusinessEntityAddress
ALTER TABLE BusinessEntityAddress
ADD CONSTRAINT [PK_BusinessEntityAddress] PRIMARY KEY CLUSTERED (BusinessEntityID, AddressID, AddressTypeID)
END
GO
Sử dụng cấu trúc trên, chúng tôi sẽ so sánh tốc độ truy vấn cho các chỉ mục được phân nhóm và không phân nhóm.
Chúng tôi có 2 bản sao của Người bàn. Đầu tiên sẽ sử dụng BusinessEntityID làm khóa chỉ mục chính và theo cụm. Thứ hai vẫn sử dụng BusinessEntityID làm khóa chính. Chỉ mục được nhóm dựa trên Họ , Tên họ , Tên đệm và Hậu tố .
Hãy bắt đầu.
CÁC TRẬN ĐẤU CHÍNH XÁC DỰA TRÊN TÊN CUỐI CÙNG
Đầu tiên, hãy có một truy vấn đơn giản. Ngoài ra, cần bật STATISTICS IO. Sau đó, chúng tôi dán kết quả vào Statisticsticsparser.com để trình bày dạng bảng.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, p.Title
FROM Person_pkClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SET STATISTICS IO OFF
GO
Kỳ vọng là SELECT đầu tiên sẽ chậm hơn vì mệnh đề WHERE không khớp với khóa chỉ mục được phân cụm. Nhưng hãy kiểm tra các lần đọc hợp lý.
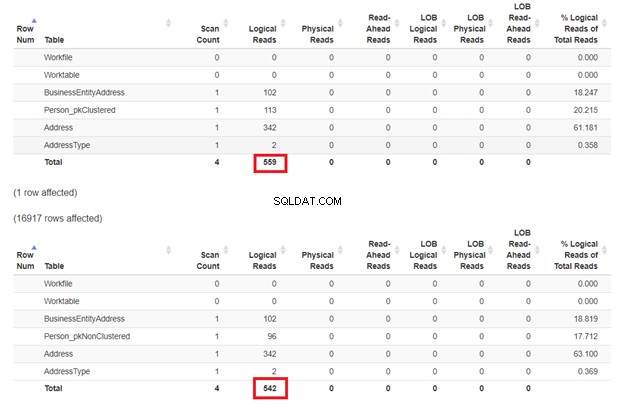
Như mong đợi trong Hình 3, Person_pkClustered đã đọc hợp lý hơn. Do đó, truy vấn cần nhiều I / O hơn. Nguyên nhân? Bảng được sắp xếp theo BusinessEntityID . Tuy nhiên, bảng thứ hai có chỉ mục được phân nhóm dựa trên tên. Vì truy vấn muốn có kết quả dựa trên tên nên Person_pkNonClustered chiến thắng. Đọc càng ít logic, truy vấn càng nhanh.
Những gì đang diễn ra? Xem Hình 4.
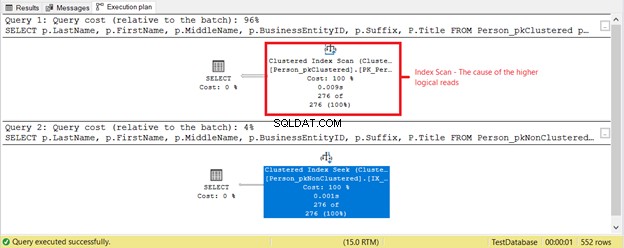
Một cái gì đó khác đã xảy ra dựa trên kế hoạch thực thi trong Hình 4. Tại sao Quét chỉ mục theo cụm lại nằm trong lần CHỌN đầu tiên thay vì Tìm kiếm chỉ mục? Thủ phạm là Tiêu đề trong cột CHỌN. Nó không được bao phủ bởi bất kỳ chỉ mục hiện có nào. Trình tối ưu hóa SQL Server cho rằng sử dụng chỉ mục nhóm dựa trên BusinessEntityID. Sau đó, SQL Server quét nó để tìm đúng họ và có tên, tên đệm và chức danh.
Xóa Tiêu đề và toán tử được sử dụng sẽ là Tìm kiếm chỉ mục . Tại sao? Bởi vì phần còn lại của các trường được bao phủ bởi chỉ mục không phân cụm dựa trên Họ , Tên họ , Tên đệm và Hậu tố . Nó cũng bao gồm BusinessEntityID làm công cụ định vị khóa chỉ mục được phân cụm.
RANGE QUERY DỰA TRÊN ID DOANH NGHIỆP
Các chỉ mục được phân cụm có thể tốt cho các truy vấn phạm vi. Có phải luôn luôn như vậy không? Hãy cùng tìm hiểu bằng cách sử dụng mã bên dưới.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SET STATISTICS IO OFF
GO
Danh sách cần các hàng dựa trên một loạt BusinessEntityIDs từ 285 đến 290. Một lần nữa, các chỉ mục được phân nhóm và không phân nhóm của 2 bảng là nguyên vẹn. Bây giờ, hãy đọc logic trong Hình 5. Người chiến thắng dự kiến là Person_pkClustered vì khóa chính cũng là khóa chỉ mục được phân nhóm.

Bạn có thấy số lần đọc logic thấp hơn trên Person_pkClustered ? Các chỉ mục được phân nhóm đã chứng minh giá trị của chúng đối với các truy vấn phạm vi trong trường hợp này. Hãy xem kế hoạch thực hiện sẽ tiết lộ thêm điều gì trong Hình 6.
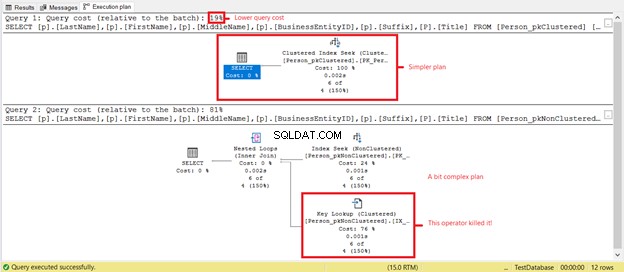
SELECT đầu tiên có một kế hoạch đơn giản hơn và chi phí truy vấn thấp hơn dựa trên Hình 7. Điều này cũng hỗ trợ các lần đọc logic thấp hơn. Trong khi đó, SELECT thứ hai có toán tử Tra cứu khóa làm chậm truy vấn. Thủ phạm? Một lần nữa, đó là Tiêu đề cột. Xóa cột trong truy vấn hoặc thêm nó dưới dạng cột Được bao gồm trong chỉ mục không phân cụm. Sau đó, bạn sẽ có một kế hoạch tốt hơn và đọc logic thấp hơn.
CÁC TRẬN ĐẤU CHÍNH XÁC CÓ THAM GIA
Nhiều câu lệnh SELECT bao gồm các phép nối. Hãy làm một số bài kiểm tra. Ở đây chúng tôi bắt đầu với các kết quả phù hợp chính xác:
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SET STATISTICS IO OFF
GO
Chúng tôi mong đợi rằng LỰA CHỌN thứ hai từ Person_pkNonClustered với một chỉ mục được phân cụm trên tên sẽ có ít lần đọc hợp lý hơn. Nhưng nó là? Xem Hình 7.
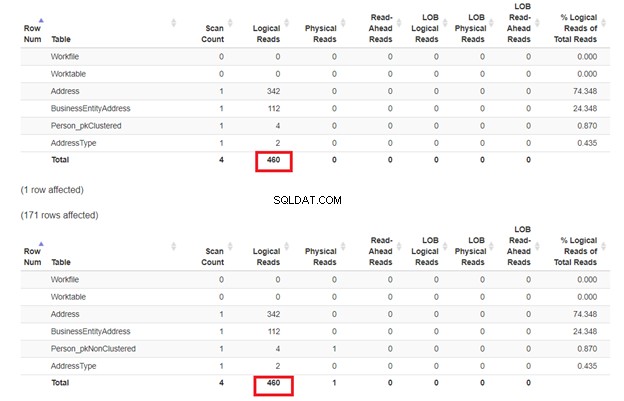
Có vẻ như chỉ mục không phân cụm trên tên đã hoạt động tốt. Các bài đọc hợp lý là như nhau. Nếu bạn kiểm tra kế hoạch thực thi, sự khác biệt trong các toán tử là Tìm kiếm chỉ mục theo cụm trên Person_pkNonClustered và Tìm kiếm chỉ mục trên Person_pkClustered .
Vì vậy, chúng ta cần kiểm tra các lần đọc và kế hoạch thực thi logic để chắc chắn.
RANGE QUERY VỚI THAM GIA
Vì kỳ vọng của chúng ta có thể khác với thực tế, hãy thử với các truy vấn phạm vi. Các chỉ mục được phân nhóm thường tốt với nó. Nhưng điều gì sẽ xảy ra nếu bạn bao gồm một tham gia?
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SET STATISTICS IO OFF
GO
Bây giờ, hãy kiểm tra các lần đọc logic của 2 truy vấn này trong Hình 8:
Chuyện gì đã xảy ra? Trong Hình 9, thực tế cắn vào Person_pkClustered . Chi phí I / O cao hơn được quan sát thấy trong đó so với Person_pkNonClustered . Điều đó khác với những gì chúng tôi mong đợi. Nhưng dựa trên câu trả lời của diễn đàn này, tìm kiếm chỉ mục không phân cụm có thể nhanh hơn tìm kiếm chỉ mục theo cụm khi tất cả các cột trong truy vấn được bao phủ 100% trong chỉ mục. Trong trường hợp của chúng tôi, truy vấn cho Person_pkNonClustered che các cột bằng cách sử dụng chỉ mục không phân cụm ( BusinessEntityID - Chìa khóa; Họ , Tên họ , Tên đệm , Hậu tố - con trỏ đến khóa chỉ mục được phân cụm).
CHÈN HIỆU SUẤT
Sau đó, hãy thử kiểm tra hiệu suất INSERT trên các bảng giống nhau.
SET STATISTICS IO ON
GO
INSERT INTO Person_pkClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
INSERT INTO Person_pkNonClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
SET STATISTICS IO OFF
GO
Hình 9 cho thấy các lần đọc logic INSERT:

Cả hai đều tạo ra I / O giống nhau. Do đó, cả hai đều hoạt động như nhau.
XÓA HIỆU SUẤT
Bài kiểm tra cuối cùng của chúng tôi liên quan đến XÓA:
SET STATISTICS IO ON
GO
DELETE FROM Person_pkClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
DELETE FROM Person_pkNonClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
SET STATISTICS IO OFF
GO
Hình 10 cho thấy các lần đọc logic. Lưu ý sự khác biệt.

Tại sao chúng tôi có lượt đọc logic cao hơn trên Person_pkClustered ? Vấn đề là, điều kiện câu lệnh DELETE dựa trên một tên khớp chính xác. Trình tối ưu hóa sẽ phải sử dụng chỉ mục không phân cụm trước. Nó có nghĩa là nhiều I / O hơn. Hãy xác nhận bằng cách sử dụng kế hoạch thực hiện trong Hình 11.
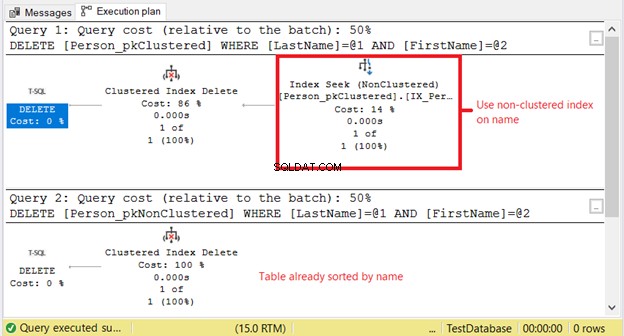
SELECT đầu tiên cần một Tìm kiếm Chỉ mục trên chỉ mục không phân cụm. Lý do là mệnh đề WHERE trên Họ và Tên đầu tiên . Trong khi đó, Person_pkNonClustered đã được sắp xếp vật lý theo tên do chỉ mục được phân nhóm.
Bài học rút ra
Việc hình thành các truy vấn có hiệu suất cao không phải là do may mắn. Bạn không thể chỉ đặt một chỉ mục được phân cụm và không được phân cụm và sau đó đột nhiên, các truy vấn của bạn có tốc độ nhanh. Bạn cần tiếp tục sử dụng các công cụ làm ống kính của mình để tập trung vào các chi tiết nhỏ khác với tập hợp kết quả.
Nhưng đôi khi bạn không có thời gian để làm tất cả những điều này. Tôi nghĩ đó là điều bình thường. Nhưng miễn là bạn không làm lộn xộn quá nhiều, bạn có công việc của mình vào ngày hôm sau và bạn có thể giải quyết công việc đó. Điều này sẽ không dễ dàng lúc đầu. Nó thực sự sẽ gây nhầm lẫn. Bạn cũng sẽ có rất nhiều câu hỏi. Nhưng với sự luyện tập liên tục, bạn có thể đạt được nó. Vì vậy, hãy luôn ngẩng cao đầu.
Hãy nhớ rằng, cả chỉ mục được phân nhóm và không được phân cụm đều để thúc đẩy các truy vấn. Biết những điểm khác biệt chính, các trường hợp sử dụng và các công cụ sẽ giúp bạn trong công cuộc viết mã các truy vấn hiệu suất cao.
Tôi hy vọng bài đăng này trả lời những câu hỏi cấp bách nhất của bạn về các chỉ mục được phân nhóm và không phân cụm. Bạn có điều gì khác để thêm cho độc giả của chúng tôi? Phần Nhận xét đang mở.
Và nếu bạn thấy bài đăng này thú vị, hãy chia sẻ nó trên các nền tảng mạng xã hội yêu thích của bạn.
Thông tin thêm về chỉ mục và hiệu suất truy vấn có trong các bài viết dưới đây:
- 22 Ví dụ về chỉ mục SQL Nifty để tăng tốc độ truy vấn của bạn
- Tối ưu hóa truy vấn SQL:5 sự kiện cốt lõi để tăng cường truy vấn của bạn