SQL DISTINCT tốt (hay xấu) khi bạn cần loại bỏ các bản sao trong kết quả?
Một số người nói rằng nó tốt và thêm DISTINCT khi các bản sao xuất hiện. Một số người cho rằng điều đó thật tệ và đề xuất sử dụng GROUP BY mà không có hàm tổng hợp. Những người khác nói rằng DISTINCT và GROUP BY giống nhau khi bạn cần xóa các bản sao.
Bài đăng này sẽ đi sâu vào chi tiết để có câu trả lời chính xác. Vì vậy, cuối cùng, bạn sẽ sử dụng từ khóa tốt nhất dựa trên nhu cầu. Hãy bắt đầu.
Lời nhắc ngắn gọn về kiến thức cơ bản của câu lệnh SQL SELECT DISTINCT
Trước khi chúng ta đi sâu hơn, hãy nhớ lại câu lệnh SQL SELECT DISTINCT là gì. Một bảng cơ sở dữ liệu có thể bao gồm các giá trị trùng lặp vì nhiều lý do, nhưng chúng tôi có thể chỉ muốn lấy các giá trị duy nhất. Trong trường hợp này, SELECT DISTINCT rất hữu ích. Mệnh đề DISTINCT này làm cho câu lệnh SELECT chỉ tìm nạp các bản ghi duy nhất.
Cú pháp của câu lệnh rất đơn giản:
SELECT DISTINCT column
FROM table_name
WHERE [condition];Ở đây, điều kiện WHERE là tùy chọn.
Câu lệnh áp dụng cho cả một cột và nhiều cột. Cú pháp của câu lệnh này áp dụng cho nhiều cột như sau:
SELECT DISTINCT
column_name1,
column_name2,
column_nameN.
FROM
table_name;Lưu ý rằng kịch bản truy vấn một số cột sẽ đề xuất sử dụng kết hợp các giá trị trong tất cả các cột được xác định bởi câu lệnh để xác định tính duy nhất.
Và bây giờ, hãy khám phá cách sử dụng thực tế và những lợi ích khi áp dụng câu lệnh SELECT DISTINCT.
Cách hoạt động của SQL DISTINCT để loại bỏ trùng lặp
Nhận được câu trả lời không phải là quá khó để tìm thấy. SQL Server đã cung cấp cho chúng tôi các kế hoạch thực thi để xem cách một truy vấn sẽ được xử lý để cung cấp cho chúng tôi kết quả cần thiết.
Phần sau tập trung vào kế hoạch thực thi khi sử dụng DISTINCT. Bạn cần nhấn Ctrl-M trong SQL Server Management Studio trước khi thực hiện các truy vấn bên dưới. Hoặc, nhấp vào Bao gồm kế hoạch thực thi thực tế từ thanh công cụ.
Kế hoạch Truy vấn trong SQL DISTINCT
Hãy bắt đầu bằng cách so sánh 2 truy vấn. Truy vấn đầu tiên sẽ không sử dụng DISTINCT và truy vấn thứ hai sẽ.
USE AdventureWorks
GO
-- Without DISTINCT. Duplicates included
SELECT Lastname FROM Person.Person;
-- With DISTINCT. Duplicates removed
SELECT DISTINCT Lastname FROM Person.Person;
Đây là kế hoạch thực hiện:
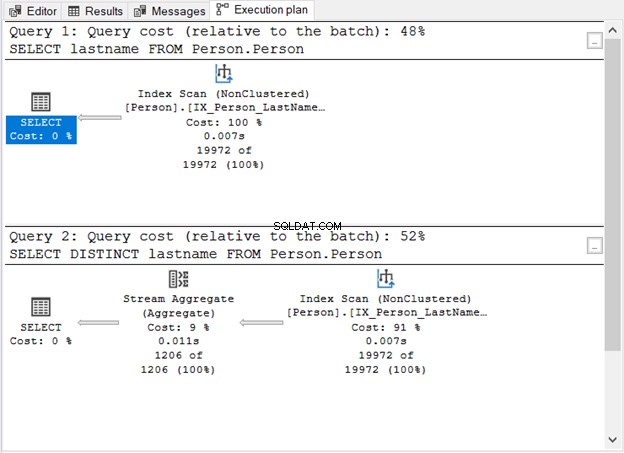
Hình 1 cho chúng ta thấy điều gì?
- Không có từ khoá DISTINCT, truy vấn rất đơn giản.
- Một bước bổ sung sẽ xuất hiện sau khi thêm DISTINCT.
- Chi phí truy vấn khi sử dụng DISTINCT cao hơn so với khi không sử dụng.
- Cả hai đều có toán tử Quét chỉ mục. Điều này có thể hiểu được vì không có mệnh đề WHERE cụ thể nào trong các truy vấn của chúng tôi.
- Bước bổ sung, toán tử Tổng hợp luồng, được sử dụng để loại bỏ các bản sao.
Số lần đọc logic là như nhau (107) nếu bạn kiểm tra IO THỐNG KÊ. Tuy nhiên, số lượng hồ sơ là rất khác nhau. 19,972 hàng được trả về bởi truy vấn đầu tiên. Trong khi đó, 1.206 hàng được trả về bởi truy vấn thứ hai.
Do đó, bạn không thể thêm DISTINCT bất cứ lúc nào bạn muốn. Nhưng nếu bạn cần các giá trị duy nhất, thì đây là chi phí cần thiết.
Có các toán tử được sử dụng để xuất ra các giá trị duy nhất. Hãy xem xét một số trong số chúng.
STREAM TỔNG HỢP
Đây là toán tử bạn đã thấy trong Hình 1. Nó chấp nhận một đầu vào duy nhất và xuất ra một kết quả tổng hợp. Trong Hình 1, đầu vào đến từ toán tử Quét chỉ mục. Tuy nhiên, Tổng hợp luồng cần một đầu vào được sắp xếp.
Như bạn có thể thấy trong Hình 1, nó sử dụng IX_Person_LastName_FirstName_MiddleName , một chỉ mục không phải là duy nhất trên tên. Vì chỉ mục đã sắp xếp các bản ghi theo tên, Tổng hợp Luồng chấp nhận đầu vào. Nếu không có chỉ mục, trình tối ưu hóa truy vấn có thể chọn sử dụng thêm toán tử Sắp xếp trong kế hoạch. Và điều đó sẽ đắt hơn. Hoặc, nó có thể sử dụng Hash Match.
TRẬN ĐẤU HASH (TỔNG HỢP)
Một toán tử khác được DISTINCT sử dụng là Hash Match. Toán tử này được sử dụng để kết hợp và tổng hợp.
Khi sử dụng DISTINCT, Hash Match tổng hợp các kết quả để tạo ra các giá trị duy nhất. Đây là một ví dụ.
USE AdventureWorks
GO
-- Get unique first names
SELECT DISTINCT Firstname FROM Person.Person;
Và đây là kế hoạch thực hiện:
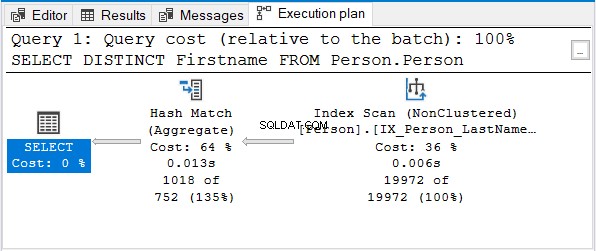
Nhưng tại sao không phải là Stream Aggregate?
Chú ý rằng chỉ mục cùng tên được sử dụng. Chỉ mục đó sắp xếp theo Họ Đầu tiên. Vì vậy, một Tên đầu tiên chỉ truy vấn sẽ không được sắp xếp.
Kết hợp băm (Tổng hợp) là lựa chọn hợp lý tiếp theo để loại bỏ các trùng lặp.
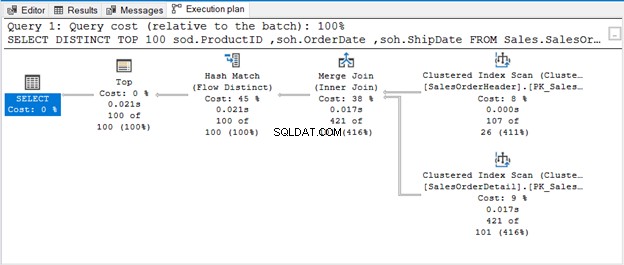
TRẬN ĐẤU HASH (FLOW DISTINCT)
Kết hợp băm (Tổng hợp) là một toán tử chặn. Do đó, nó sẽ không tạo ra đầu ra mà nó đã xử lý toàn bộ luồng đầu vào. Nếu chúng ta hạn chế số lượng hàng (như sử dụng TOP với DISTINCT), nó sẽ tạo ra một đầu ra duy nhất ngay khi những hàng đó có sẵn. Đó là nội dung của Đối sánh băm (Phân biệt luồng).
USE AdventureWorks
GO
SELECT DISTINCT TOP 100
sod.ProductID
,soh.OrderDate
,soh.ShipDate
FROM Sales.SalesOrderDetail sod
INNER JOIN Sales.SalesOrderHeader soh ON sod.SalesOrderID = soh.SalesOrderID;
Truy vấn sử dụng TOP 100 cùng với DISTINCT. Đây là kế hoạch thực hiện:
KHI KHÔNG CÓ BỘ ĐIỀU HÀNH ĐỂ XÓA DUPLICATES
Chuẩn rồi. Điều này có thể xảy ra. Hãy xem xét ví dụ bên dưới.
USE AdventureWorks
GO
SELECT DISTINCT
BusinessEntityID
FROM Person.Person;
Sau đó, kiểm tra kế hoạch thực hiện:
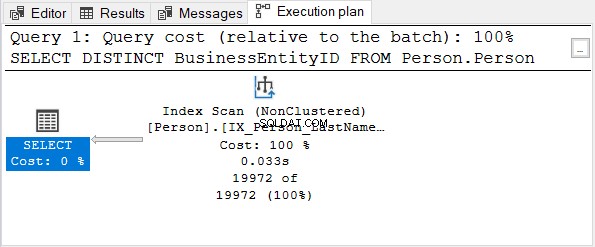
BusinessEntityID cột là khóa chính. Vì cột đó đã là duy nhất nên không có tác dụng khi áp dụng DISTINCT. Thử xóa DISTINCT khỏi câu lệnh SELECT - kế hoạch thực thi giống như trong Hình 4.
Điều này cũng đúng khi sử dụng DISTINCT trên các cột có chỉ mục duy nhất.
SQL DISTINCT Hoạt động trên TẤT CẢ các cột trong danh sách CHỌN
Cho đến nay, chúng tôi chỉ sử dụng 1 cột trong các ví dụ của chúng tôi. Tuy nhiên, DISTINCT hoạt động trên TẤT CẢ các cột bạn chỉ định trong danh sách CHỌN.
Đây là một ví dụ. Truy vấn này sẽ đảm bảo rằng các giá trị của cả 3 cột sẽ là duy nhất.
USE AdventureWorks
GO
SELECT DISTINCT
Lastname
,FirstName
,MiddleName
FROM Person.Person;
Lưu ý một số hàng đầu tiên trong tập hợp kết quả trong Hình 5.
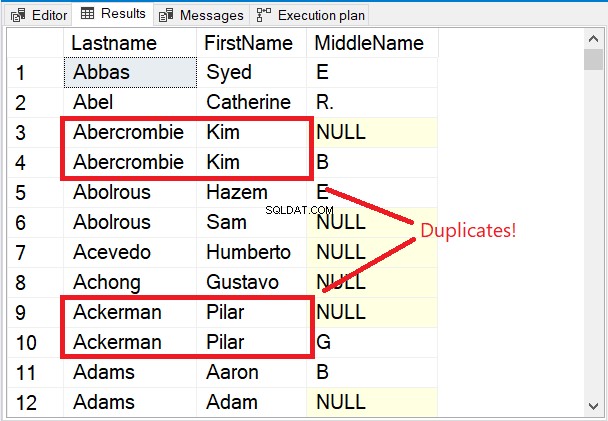
Một vài hàng đầu tiên đều là duy nhất. Từ khóa DISTINCT đảm bảo rằng Tên đệm cột cũng được xem xét. Chú ý 2 cái tên được đóng hộp màu đỏ. Xem xét Họ và Tên đầu tiên chỉ sẽ làm cho chúng trùng lặp. Nhưng thêm Tên đệm kết hợp đã thay đổi mọi thứ.
Điều gì sẽ xảy ra nếu bạn muốn lấy họ và tên duy nhất nhưng lại bao gồm tên đệm trong kết quả?
Bạn có 2 lựa chọn:
- Thêm mệnh đề WHERE để xóa tên đệm NULL. Thao tác này sẽ xóa tất cả các tên có tên đệm NULL.
- Hoặc, thêm mệnh đề GROUP BY trên Họ và Tên đầu tiên cột. Sau đó, sử dụng hàm tổng hợp MIN trên Tên đệm cột. Việc này sẽ nhận được 1 tên đệm có họ và tên giống nhau.
SQL DISTINCT so với GROUP BY
Khi sử dụng GROUP BY mà không có hàm tổng hợp, nó hoạt động giống như DISTINCT. Làm sao mà chúng ta biết được? Một cách để tìm hiểu là sử dụng một ví dụ.
USE AdventureWorks
GO
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID;
-- using GROUP BY
SELECT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID
GROUP BY
soh.TerritoryID
,st.Name;
Chạy chúng và kiểm tra kế hoạch thực hiện. Nó có giống như ảnh chụp màn hình bên dưới không?
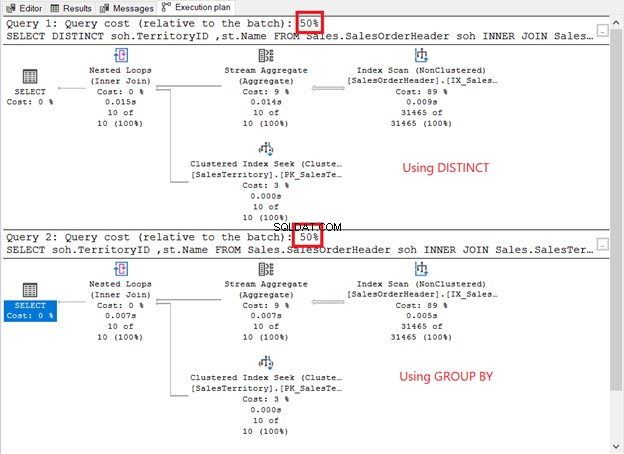
Làm thế nào để họ so sánh?
- Chúng có trình tự và toán tử kế hoạch giống nhau.
- Chi phí điều hành của mỗi loại và chi phí truy vấn là như nhau.
Nếu bạn chọn QueryPlanHash thuộc tính của 2 toán tử SELECT, chúng giống nhau. Do đó, trình tối ưu hóa truy vấn đã sử dụng cùng một quy trình để trả về cùng một kết quả.
Cuối cùng, chúng tôi không thể nói rằng sử dụng GROUP BY tốt hơn DISTINCT trong việc trả về các giá trị duy nhất. Bạn có thể chứng minh điều này bằng cách sử dụng các ví dụ trên để thay thế DISTINCT bằng GROUP BY.
Bây giờ nó là một vấn đề tùy chọn mà bạn sẽ sử dụng. Tôi thích DISTINCT hơn. Nó cho biết rõ ràng mục đích trong truy vấn - để tạo ra các kết quả duy nhất. Và đối với tôi, GROUP BY là để nhóm các kết quả bằng cách sử dụng một hàm tổng hợp. Ý định đó cũng rõ ràng và phù hợp với chính từ khóa. Tôi không biết liệu một ngày nào đó có người khác sẽ duy trì các truy vấn của tôi hay không. Vì vậy, mã phải rõ ràng.
Nhưng đó không phải là kết thúc của câu chuyện.
Khi SQL DISTINCT không giống GROUP BY
Tôi chỉ bày tỏ ý kiến của mình, và sau đó là điều này?
Đúng rồi. Không phải lúc nào chúng cũng giống nhau. Hãy xem xét ví dụ này.
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh;
-- using GROUP BY
SELECT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh
GROUP BY
soh.TerritoryID;
Mặc dù tập kết quả không được sắp xếp, các hàng vẫn giống như trong ví dụ trước. Sự khác biệt duy nhất là việc sử dụng một truy vấn con:
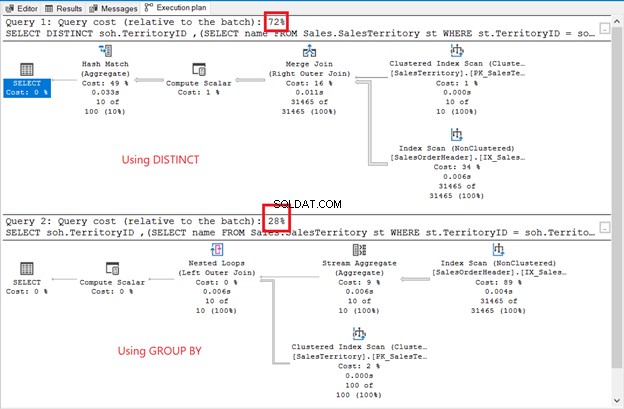
Sự khác biệt là rõ ràng:toán tử, chi phí truy vấn, kế hoạch tổng thể. Lần này, GROUP BY giành chiến thắng với chi phí truy vấn chỉ 28%. Nhưng đây là vấn đề.
Mục đích là để cho bạn thấy rằng họ có thể khác nhau. Đó là tất cả. Đây hoàn toàn không phải là một khuyến nghị. Sử dụng phép nối có kế hoạch thực thi tốt hơn (xem lại Hình 6).
Tóm tắt
Đây là những gì chúng tôi đã học được cho đến nay:
- DISTINCT thêm toán tử kế hoạch để loại bỏ các bản sao.
- DISTINCT và GROUP BY không có hàm tổng hợp dẫn đến cùng một kế hoạch. Nói tóm lại, hầu hết thời gian chúng đều giống nhau.
- Đôi khi, DISTINCT và GROUP BY có thể có các kế hoạch khác nhau khi truy vấn con tham gia vào danh sách CHỌN.
Vì vậy, SQL DISTINCT tốt hay xấu trong việc loại bỏ các bản sao trong kết quả?
Các kết quả nói rằng điều đó là tốt. Nó không tốt hơn hoặc kém hơn GROUP BY vì các kế hoạch đều giống nhau. Nhưng đó là một thói quen tốt để kiểm tra kế hoạch thực hiện. Hãy nghĩ đến việc tối ưu hóa ngay từ đầu. Bằng cách đó, nếu bạn vấp phải bất kỳ sự khác biệt nào trong DISTINCT và GROUP BY, bạn sẽ phát hiện ra chúng.
Bên cạnh đó, các công cụ hiện đại giúp công việc này trở nên đơn giản hơn rất nhiều. Ví dụ:sản phẩm phổ biến dbForge SQL Complete từ Devart có một tính năng cụ thể tính toán các giá trị trong các hàm tổng hợp trong tập kết quả sẵn sàng của lưới kết quả SSMS. Các giá trị DISTINCT cũng có ở đó.
Thích bài viết? Sau đó, hãy quảng bá bằng cách chia sẻ nó trên các nền tảng mạng xã hội yêu thích của bạn.
Các bài viết liên quan để biết thêm thông tin
- NHÓM SQL BẰNG:3 mẹo dễ dàng để nhóm kết quả giống như một chuyên gia
- CHÈN SQL VÀO CHỌN LỰA CHỌN:5 cách dễ dàng để xử lý các bản trùng lặp
- Các hàm tổng hợp trong SQL là gì? (Mẹo dễ dàng cho người mới)
- Tối ưu hóa truy vấn SQL:5 sự kiện cốt lõi để tăng cường truy vấn