Trong Phần 2 của loạt bài này, bạn đã thêm khả năng lưu các thay đổi được thực hiện thông qua REST API vào cơ sở dữ liệu bằng SQLAlchemy và học cách tuần tự hóa dữ liệu đó cho REST API bằng Marshmallow. Việc kết nối API REST với cơ sở dữ liệu để ứng dụng có thể thực hiện các thay đổi đối với dữ liệu hiện có và tạo dữ liệu mới là điều tuyệt vời và làm cho ứng dụng trở nên hữu ích và mạnh mẽ hơn nhiều.
Tuy nhiên, đó chỉ là một phần sức mạnh mà cơ sở dữ liệu cung cấp. Một tính năng thậm chí còn mạnh mẽ hơn là R một phần của RDBMS hệ thống: mối quan hệ . Trong cơ sở dữ liệu, mối quan hệ là khả năng kết nối hai hoặc nhiều bảng với nhau theo một cách có ý nghĩa. Trong bài viết này, bạn sẽ tìm hiểu cách triển khai các mối quan hệ và biến Person của bạn cơ sở dữ liệu thành một ứng dụng web mini-blog.
Trong bài viết này, bạn sẽ tìm hiểu:
- Tại sao nhiều bảng trong cơ sở dữ liệu lại hữu ích và quan trọng
- Các bảng liên quan với nhau như thế nào
- Cách SQLAlchemy có thể giúp bạn quản lý các mối quan hệ
- Cách các mối quan hệ giúp bạn xây dựng ứng dụng viết blog nhỏ
Bài viết này dành cho ai
Phần 1 của loạt bài này đã hướng dẫn bạn cách xây dựng API REST và Phần 2 đã hướng dẫn bạn cách kết nối API REST đó với cơ sở dữ liệu.
Bài viết này mở rộng thêm vành đai công cụ lập trình của bạn. Bạn sẽ học cách tạo cấu trúc dữ liệu phân cấp được biểu thị dưới dạng mối quan hệ một-nhiều bởi SQLAlchemy. Ngoài ra, bạn sẽ mở rộng REST API mà bạn đã xây dựng để cung cấp hỗ trợ CRUD (Tạo, Đọc, Cập nhật và Xóa) cho các phần tử trong cấu trúc phân cấp này.
Ứng dụng web được trình bày trong Phần 2 sẽ có các tệp HTML và JavaScript được sửa đổi theo những cách chính để tạo ra một ứng dụng viết blog mini đầy đủ chức năng hơn. Bạn có thể xem lại phiên bản cuối cùng của mã từ Phần 2 trong kho lưu trữ GitHub cho bài viết đó.
Hãy chờ đợi khi bạn bắt đầu tạo các mối quan hệ và ứng dụng viết blog nhỏ của mình!
Phụ thuộc bổ sung
Không có phụ thuộc Python mới nào ngoài những gì được yêu cầu cho bài viết Phần 2. Tuy nhiên, bạn sẽ sử dụng hai mô-đun JavaScript mới trong ứng dụng web để làm cho mọi thứ dễ dàng và nhất quán hơn. Hai mô-đun như sau:
- Handlebars.js là một công cụ tạo khuôn mẫu cho JavaScript, giống như Jinja2 cho Flask.
- Moment.js là một mô-đun phân tích cú pháp và định dạng ngày giờ giúp hiển thị dấu thời gian UTC dễ dàng hơn.
Bạn không phải tải xuống một trong hai thứ này, vì ứng dụng web sẽ tải chúng trực tiếp từ Cloudflare CDN (Mạng phân phối nội dung), như bạn đã làm cho mô-đun jQuery.
Dữ liệu người được mở rộng để viết blog
Trong Phần 2, People dữ liệu tồn tại dưới dạng từ điển trong build_database.py Mã Python. Đây là những gì bạn đã sử dụng để điền vào cơ sở dữ liệu với một số dữ liệu ban đầu. Bạn sẽ sửa đổi People cấu trúc dữ liệu để cung cấp cho mỗi người một danh sách các ghi chú liên quan đến họ. People mới cấu trúc dữ liệu sẽ như thế này:
# Data to initialize database with
PEOPLE = [
{
"fname": "Doug",
"lname": "Farrell",
"notes": [
("Cool, a mini-blogging application!", "2019-01-06 22:17:54"),
("This could be useful", "2019-01-08 22:17:54"),
("Well, sort of useful", "2019-03-06 22:17:54"),
],
},
{
"fname": "Kent",
"lname": "Brockman",
"notes": [
(
"I'm going to make really profound observations",
"2019-01-07 22:17:54",
),
(
"Maybe they'll be more obvious than I thought",
"2019-02-06 22:17:54",
),
],
},
{
"fname": "Bunny",
"lname": "Easter",
"notes": [
("Has anyone seen my Easter eggs?", "2019-01-07 22:47:54"),
("I'm really late delivering these!", "2019-04-06 22:17:54"),
],
},
]
Mỗi người trong People từ điển hiện bao gồm một khóa được gọi là notes , được liên kết với một danh sách chứa nhiều bộ dữ liệu. Mỗi bộ trong notes danh sách đại diện cho một ghi chú chứa nội dung và dấu thời gian. Dấu thời gian được khởi tạo (thay vì được tạo động) để chứng minh thứ tự sau này trong REST API.
Mỗi người được liên kết với nhiều ghi chú và mỗi ghi chú chỉ được liên kết với một người. Hệ thống phân cấp dữ liệu này được gọi là mối quan hệ một-nhiều, trong đó một đối tượng cha duy nhất có liên quan đến nhiều đối tượng con. Bạn sẽ thấy mối quan hệ một-nhiều này được quản lý như thế nào trong cơ sở dữ liệu với SQLAlchemy.
Phương pháp tiếp cận vũ phu
Cơ sở dữ liệu bạn đã tạo đã lưu trữ dữ liệu trong bảng và bảng là một mảng hai chiều gồm các hàng và cột. Có thể People từ điển trên được biểu diễn trong một bảng hàng và cột? Theo cách sau đây, trong person của bạn bảng cơ sở dữ liệu. Thật không may, việc bao gồm tất cả dữ liệu thực tế trong ví dụ sẽ tạo ra một thanh cuộn cho bảng, như bạn sẽ thấy bên dưới:
person_id | lname | fname | timestamp | content | note_timestamp |
|---|---|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01 | Tuyệt vời, một ứng dụng viết blog nhỏ! | 2019-01-06 22:17:54 |
| 2 | Farrell | Doug | 2018-08-08 21:16:01 | Điều này có thể hữu ích | 2019-01-08 22:17:54 |
| 3 | Farrell | Doug | 2018-08-08 21:16:01 | Chà, loại hữu ích | 2019-03-06 22:17:54 |
| 4 | Brockman | Kent | 2018-08-08 21:16:01 | Tôi sẽ đưa ra những quan sát thực sự sâu sắc | 2019-01-07 22:17:54 |
| 5 | Brockman | Kent | 2018-08-08 21:16:01 | Có lẽ chúng sẽ rõ ràng hơn tôi nghĩ | 2019-02-06 22:17:54 |
| 6 | Lễ Phục sinh | Chú thỏ | 2018-08-08 21:16:01 | Có ai nhìn thấy những quả trứng Phục sinh của tôi không? | 2019-01-07 22:47:54 |
| 7 | Lễ Phục sinh | Chú thỏ | 2018-08-08 21:16:01 | Tôi thực sự giao những thứ này muộn! | 2019-04-06 22:17:54 |
Bảng trên sẽ thực sự hoạt động. Tất cả dữ liệu được thể hiện và một người duy nhất được liên kết với một bộ sưu tập các ghi chú khác nhau.
Ưu điểm
Về mặt khái niệm, cấu trúc bảng trên có ưu điểm là tương đối đơn giản để hiểu. Bạn thậm chí có thể đặt ra trường hợp dữ liệu có thể được lưu giữ trong một tệp phẳng thay vì cơ sở dữ liệu.
Do cấu trúc bảng hai chiều, bạn có thể lưu trữ và sử dụng dữ liệu này trong bảng tính. Bảng tính đã được đưa vào dịch vụ lưu trữ dữ liệu khá nhiều.
Nhược điểm
Mặc dù cấu trúc bảng trên có thể hoạt động, nhưng nó có một số nhược điểm thực sự.
Để biểu diễn tập hợp các ghi chú, tất cả dữ liệu của mỗi người được lặp lại cho mỗi ghi chú duy nhất, dữ liệu về người do đó là dư thừa. Đây không phải là vấn đề lớn đối với dữ liệu con người của bạn vì không có nhiều cột như vậy. Nhưng hãy tưởng tượng nếu một người có nhiều cột hơn. Ngay cả với các ổ đĩa lớn, điều này có thể trở thành mối quan tâm về bộ nhớ nếu bạn đang xử lý hàng triệu hàng dữ liệu.
Việc có dữ liệu dư thừa như thế này có thể dẫn đến các vấn đề bảo trì theo thời gian. Ví dụ, điều gì sẽ xảy ra nếu Chú thỏ Phục sinh quyết định đổi tên là một ý kiến hay. Để làm được điều này, mọi bản ghi có chứa tên của chú thỏ Phục sinh sẽ phải được cập nhật để giữ cho dữ liệu được nhất quán. Loại công việc này đối với cơ sở dữ liệu có thể dẫn đến sự không nhất quán về dữ liệu, đặc biệt nếu công việc được thực hiện bởi một người đang chạy truy vấn SQL bằng tay.
Đặt tên cho các cột trở nên khó hiểu. Trong bảng trên, có timestamp cột dùng để theo dõi thời gian tạo và cập nhật của một người trong bảng. Bạn cũng muốn có chức năng tương tự để tạo và cập nhật thời gian cho ghi chú, nhưng vì timestamp đã được sử dụng, tên nguyên bản của note_timestamp được sử dụng.
Điều gì sẽ xảy ra nếu bạn muốn thêm các mối quan hệ bổ sung một-nhiều vào person bàn? Ví dụ:để bao gồm con cái hoặc số điện thoại của một người. Mỗi người có thể có nhiều con và nhiều số điện thoại. Điều này có thể được thực hiện tương đối dễ dàng với Python People từ điển bên trên bằng cách thêm children và phone_numbers khóa với danh sách mới chứa dữ liệu.
Tuy nhiên, đại diện cho các mối quan hệ một-nhiều mới đó trong person của bạn bảng cơ sở dữ liệu trên trở nên khó hơn đáng kể. Mỗi mối quan hệ một-nhiều mới sẽ làm tăng số lượng hàng cần thiết để biểu diễn nó cho mỗi mục nhập trong dữ liệu con một cách đáng kể. Ngoài ra, các vấn đề liên quan đến dư thừa dữ liệu ngày càng lớn hơn và khó xử lý hơn.
Cuối cùng, dữ liệu bạn lấy lại từ cấu trúc bảng ở trên sẽ không phải là Pythonic:nó sẽ chỉ là một danh sách lớn các danh sách. SQLAlchemy sẽ không thể giúp bạn nhiều vì mối quan hệ không có ở đó.
Phương pháp tiếp cận cơ sở dữ liệu quan hệ
Dựa trên những gì bạn đã thấy ở trên, rõ ràng là việc cố gắng biểu diễn ngay cả một tập dữ liệu phức tạp vừa phải trong một bảng đơn lẻ sẽ trở nên không thể quản lý được nhanh chóng. Với điều đó, cơ sở dữ liệu cung cấp giải pháp thay thế nào? Đây là nơi R một phần của RDBMS cơ sở dữ liệu phát huy tác dụng. Biểu diễn các mối quan hệ loại bỏ các nhược điểm đã nêu ở trên.
Thay vì cố gắng biểu diễn dữ liệu phân cấp trong một bảng, dữ liệu được chia thành nhiều bảng, với cơ chế liên kết chúng với nhau. Các bảng được chia theo các dòng thu thập, vì vậy đối với People của bạn từ điển ở trên, điều này có nghĩa là sẽ có một bảng đại diện cho mọi người và một bảng khác đại diện cho các ghi chú. Điều này mang lại person ban đầu của bạn bảng trông giống như sau:
person_id | lname | fname | timestamp |
|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01.888444 |
| 2 | Brockman | Kent | 2018-08-08 21:16:01.889060 |
| 3 | Lễ Phục sinh | Chú thỏ | 2018-08-08 21:16:01.886834 |
Để trình bày thông tin ghi chú mới, bạn sẽ tạo một bảng mới có tên là note . (Hãy nhớ quy ước đặt tên bảng số ít của chúng tôi.) Bảng trông như thế này:
note_id | person_id | content | timestamp |
|---|---|---|---|
| 1 | 1 | Tuyệt vời, một ứng dụng viết blog nhỏ! | 2019-01-06 22:17:54 |
| 2 | 1 | Điều này có thể hữu ích | 2019-01-08 22:17:54 |
| 3 | 1 | Chà, loại hữu ích | 2019-03-06 22:17:54 |
| 4 | 2 | Tôi sẽ đưa ra những quan sát thực sự sâu sắc | 2019-01-07 22:17:54 |
| 5 | 2 | Có lẽ chúng sẽ rõ ràng hơn tôi nghĩ | 2019-02-06 22:17:54 |
| 6 | 3 | Có ai nhìn thấy những quả trứng Phục sinh của tôi không? | 2019-01-07 22:47:54 |
| 7 | 3 | Tôi thực sự giao những thứ này muộn! | 2019-04-06 22:17:54 |
Lưu ý rằng, giống như person bảng, notes bảng có một số nhận dạng duy nhất được gọi là note_id , là khóa chính cho note bàn. Một điều không rõ ràng là việc bao gồm person_id giá trị trong bảng. Cái đó được dùng để làm gì? Đây là những gì tạo ra mối quan hệ với person bàn. Trong khi note_id là khóa chính cho bảng, person_id là thứ được gọi là khóa ngoại.
Khóa ngoại cung cấp cho mỗi mục nhập trong notes bảng khóa chính của person ghi lại nó được liên kết với. Sử dụng điều này, SQLAlchemy có thể thu thập tất cả các ghi chú được liên kết với từng người bằng cách kết nối person.person_id khóa chính của note.person_id khóa ngoại, tạo mối quan hệ.
Ưu điểm
Bằng cách chia nhỏ tập dữ liệu thành hai bảng và giới thiệu khái niệm khóa ngoại, bạn đã làm cho dữ liệu phức tạp hơn một chút để suy nghĩ, bạn đã giải quyết được những nhược điểm của một biểu diễn bảng. SQLAlchemy sẽ giúp bạn mã hóa độ phức tạp tăng lên một cách khá dễ dàng.
Dữ liệu không còn dư thừa trong cơ sở dữ liệu. Chỉ có một mục nhập người cho mỗi người mà bạn muốn lưu trữ trong cơ sở dữ liệu. Điều này giải quyết mối quan tâm về lưu trữ ngay lập tức và đơn giản hóa đáng kể các mối quan tâm về bảo trì.
Nếu Thỏ Phục sinh vẫn muốn đổi tên, thì bạn chỉ phải thay đổi một hàng duy nhất trong person bảng và bất kỳ thứ gì khác liên quan đến hàng đó (như notes bảng) sẽ ngay lập tức tận dụng sự thay đổi.
Đặt tên cột phù hợp và có ý nghĩa hơn. Bởi vì dữ liệu người và ghi chú tồn tại trong các bảng riêng biệt, dấu thời gian tạo và cập nhật có thể được đặt tên nhất quán trong cả hai bảng, vì không có xung đột về tên giữa các bảng.
Ngoài ra, bạn không còn phải tạo các hoán vị của mỗi hàng cho các mối quan hệ một-nhiều mới mà bạn có thể muốn đại diện. Lấy children của chúng tôi và phone_numbers ví dụ từ trước đó. Việc triển khai điều này sẽ yêu cầu children và phone_number những cái bàn. Mỗi bảng sẽ chứa một khóa ngoại person_id liên hệ nó lại với person bảng.
Sử dụng SQLAlchemy, dữ liệu bạn lấy lại từ các bảng trên sẽ hữu ích ngay lập tức, vì những gì bạn nhận được là một đối tượng cho mỗi hàng người. Đối tượng đó có các thuộc tính được đặt tên tương đương với các cột trong bảng. Một trong những thuộc tính đó là danh sách Python chứa các đối tượng ghi chú có liên quan.
Nhược điểm
Khi mà cách tiếp cận brute force đơn giản hơn để hiểu, khái niệm về các khóa ngoại và các mối quan hệ làm cho việc suy nghĩ về dữ liệu trở nên trừu tượng hơn. Sự trừu tượng này cần được suy nghĩ về mọi mối quan hệ mà bạn thiết lập giữa các bảng.
Tận dụng các mối quan hệ có nghĩa là cam kết sử dụng một hệ thống cơ sở dữ liệu. Đây là một công cụ khác để cài đặt, tìm hiểu và duy trì bên trên và bên ngoài ứng dụng thực sự sử dụng dữ liệu.
Mô hình SQLAlchemy
Để sử dụng hai bảng trên và mối quan hệ giữa chúng, bạn sẽ cần tạo các mô hình SQLAlchemy nhận biết được cả hai bảng và mối quan hệ giữa chúng. Đây là Person của SQLAlchemy mô hình từ Phần 2, được cập nhật để bao gồm mối quan hệ với tập hợp các notes :
1class Person(db.Model):
2 __tablename__ = 'person'
3 person_id = db.Column(db.Integer, primary_key=True)
4 lname = db.Column(db.String(32))
5 fname = db.Column(db.String(32))
6 timestamp = db.Column(
7 db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow
8 )
9 notes = db.relationship(
10 'Note',
11 backref='person',
12 cascade='all, delete, delete-orphan',
13 single_parent=True,
14 order_by='desc(Note.timestamp)'
15 )
Các dòng từ 1 đến 8 của lớp Python ở trên trông giống hệt như những gì bạn đã tạo trước đó trong Phần 2. Các dòng từ 9 đến 16 tạo một thuộc tính mới trong Person lớp được gọi là notes . notes mới này các thuộc tính được xác định trong các dòng mã sau:
-
Dòng 9: Giống như các thuộc tính khác của lớp, dòng này tạo một thuộc tính mới được gọi là
notesvà đặt nó bằng một phiên bản của đối tượng có tên làdb.relationship. Đối tượng này tạo ra mối quan hệ mà bạn đang thêm vàoPersonvà được tạo với tất cả các tham số được xác định trong các dòng tiếp theo. -
Dòng 10: Tham số chuỗi
'Note'xác định lớp SQLAlchemy màPersonlớp học sẽ liên quan đến.Notelớp chưa được xác định, đó là lý do tại sao nó là một chuỗi ở đây. Đây là tài liệu tham khảo chuyển tiếp và giúp xử lý các vấn đề mà thứ tự các định nghĩa có thể gây ra khi cần một thứ gì đó chưa được xác định cho đến sau này trong mã.'Note'chuỗi cho phépPersonlớp để tìmNotelớp trong thời gian chạy, sau cảPersonvàNoteđã được xác định. -
Dòng 11:
backref='person'tham số phức tạp hơn. Nó tạo ra những gì được gọi là tham chiếu ngược trongNotecác đối tượng. Mỗi phiên bản của mộtNoteđối tượng sẽ chứa một thuộc tính có tên làperson.personthuộc tính tham chiếu đến đối tượng mẹ mà mộtNotecụ thể trường hợp được liên kết với. Có tham chiếu đến đối tượng mẹ (persontrong trường hợp này) trong phần con có thể rất hữu ích nếu mã của bạn lặp lại qua các ghi chú và phải bao gồm thông tin về cha mẹ. Điều này xảy ra thường xuyên một cách đáng ngạc nhiên trong mã hiển thị. -
Dòng 12:
cascade='all, delete, delete-orphan'tham số xác định cách xử lý các trường hợp đối tượng ghi chú khi các thay đổi được thực hiện đối vớiPersonchính ví dụ. Ví dụ:khi mộtPersonđối tượng bị xóa, SQLAlchemy sẽ tạo SQL cần thiết để xóaPersontừ cơ sở dữ liệu. Ngoài ra, tham số này yêu cầu nó xóa tất cảNotecác trường hợp liên quan đến nó. Bạn có thể đọc thêm về các tùy chọn này trong tài liệu SQLAlchemy. -
Dòng 13:
single_parent=Truetham số là bắt buộc nếudelete-orphanlà một phần củacascadetrước đó tham số. Điều này cho SQLAlchemy không cho phépNotemồ côi phiên bản (mộtNotekhông có cha mẹPersonđối tượng) tồn tại vì mỗiNotecó một phụ huynh duy nhất. -
Dòng 14:
order_by='desc(Note.timestamp)'tham số cho SQLAlchemy biết cách sắp xếpNotecác trường hợp được liên kết với mộtPerson. Khi mộtPersonđối tượng được truy xuất, theo mặc định lànotesdanh sách thuộc tính sẽ chứaNotecác đối tượng theo một thứ tự không xác định. SQLAlchemydesc(...)chức năng sẽ sắp xếp các ghi chú theo thứ tự giảm dần từ mới nhất đến cũ nhất. Nếu dòng này thay vào đó làorder_by='Note.timestamp', SQLAlchemy sẽ mặc định sử dụngasc(...)và sắp xếp các ghi chú theo thứ tự tăng dần, cũ nhất đến mới nhất.
Bây giờ Person của bạn mô hình có notes mới và điều này thể hiện mối quan hệ một-nhiều đối với Note các đối tượng, bạn sẽ cần xác định mô hình SQLAlchemy cho Note :
1class Note(db.Model):
2 __tablename__ = 'note'
3 note_id = db.Column(db.Integer, primary_key=True)
4 person_id = db.Column(db.Integer, db.ForeignKey('person.person_id'))
5 content = db.Column(db.String, nullable=False)
6 timestamp = db.Column(
7 db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow
8 )
Note lớp xác định các thuộc tính tạo nên một ghi chú như được thấy trong notes mẫu của chúng tôi bảng cơ sở dữ liệu từ phía trên. Các thuộc tính được xác định ở đây:
-
Dòng 1 tạo
Notelớp, kế thừa từdb.Model, chính xác như bạn đã làm trước đây khi tạoPersonlớp học. -
Dòng 2 cho lớp biết bảng cơ sở dữ liệu nào sẽ sử dụng để lưu trữ
Noteđối tượng. -
Dòng 3 tạo
note_id, xác định nó là một giá trị số nguyên và là khóa chính choNoteđối tượng. -
Dòng 4 tạo
person_idvà xác định nó là khóa ngoại, liên quan đếnNotelớp choPersonlớp sử dụngperson.person_idkhóa chính. Cái này vàPerson.notes, là cách SQLAlchemy biết phải làm gì khi tương tác vớiPersonvàNoteđối tượng. -
Dòng 5 tạo nội dung
contentthuộc tính này, chứa văn bản thực của ghi chú.nullable=Falsecho biết rằng bạn có thể tạo ghi chú mới không có nội dung. -
Dòng 6 tạo
timestampvà giống hệt như thuộc tínhPersonlớp này chứa thời gian tạo hoặc cập nhật cho bất kỳNotecụ thể nào ví dụ.
Khởi tạo cơ sở dữ liệu
Bây giờ bạn đã cập nhật Person và tạo Note , bạn sẽ sử dụng chúng để xây dựng lại cơ sở dữ liệu thử nghiệm people.db . Bạn sẽ thực hiện việc này bằng cách cập nhật build_database.py mã từ Phần 2. Đây là mã sẽ trông như thế nào:
1import os
2from datetime import datetime
3from config import db
4from models import Person, Note
5
6# Data to initialize database with
7PEOPLE = [
8 {
9 "fname": "Doug",
10 "lname": "Farrell",
11 "notes": [
12 ("Cool, a mini-blogging application!", "2019-01-06 22:17:54"),
13 ("This could be useful", "2019-01-08 22:17:54"),
14 ("Well, sort of useful", "2019-03-06 22:17:54"),
15 ],
16 },
17 {
18 "fname": "Kent",
19 "lname": "Brockman",
20 "notes": [
21 (
22 "I'm going to make really profound observations",
23 "2019-01-07 22:17:54",
24 ),
25 (
26 "Maybe they'll be more obvious than I thought",
27 "2019-02-06 22:17:54",
28 ),
29 ],
30 },
31 {
32 "fname": "Bunny",
33 "lname": "Easter",
34 "notes": [
35 ("Has anyone seen my Easter eggs?", "2019-01-07 22:47:54"),
36 ("I'm really late delivering these!", "2019-04-06 22:17:54"),
37 ],
38 },
39]
40
41# Delete database file if it exists currently
42if os.path.exists("people.db"):
43 os.remove("people.db")
44
45# Create the database
46db.create_all()
47
48# Iterate over the PEOPLE structure and populate the database
49for person in PEOPLE:
50 p = Person(lname=person.get("lname"), fname=person.get("fname"))
51
52 # Add the notes for the person
53 for note in person.get("notes"):
54 content, timestamp = note
55 p.notes.append(
56 Note(
57 content=content,
58 timestamp=datetime.strptime(timestamp, "%Y-%m-%d %H:%M:%S"),
59 )
60 )
61 db.session.add(p)
62
63db.session.commit()
Đoạn mã trên đến từ Phần 2, với một vài thay đổi để tạo mối quan hệ một-nhiều giữa Person và Note . Dưới đây là các dòng được cập nhật hoặc mới được thêm vào mã:
-
Dòng 4 đã được cập nhật để nhập
Notelớp đã xác định trước đó. -
Dòng 7 đến dòng 39 chứa
PEOPLEđã cập nhật từ điển chứa dữ liệu người của chúng tôi, cùng với danh sách các ghi chú liên quan đến từng người. Dữ liệu này sẽ được chèn vào cơ sở dữ liệu. -
Dòng 49 đến 61 lặp qua
PEOPLEtừ điển, nhận từngpersonlần lượt và sử dụng nó để tạo mộtPersonvật. -
Dòng 53 lặp qua
person.notesdanh sách, nhận từngnotesđến lượt mình. -
Dòng 54 giải nén nội dung
contentvàtimestamptừ mỗinotestuple. -
Dòng 55 đến 60 tạo một
Notevà gắn nó vào bộ sưu tập ghi chú cá nhân bằng cách sử dụngp.notes.append(). -
Dòng 61 thêm
Personđối tượngpđến phiên cơ sở dữ liệu. -
Dòng 63 cam kết tất cả hoạt động trong phiên vào cơ sở dữ liệu. Tại thời điểm này, tất cả dữ liệu được ghi vào
personvànotecác bảng trongpeople.dbtệp cơ sở dữ liệu.
Bạn có thể thấy điều đó hoạt động với notes bộ sưu tập trong Person cá thể đối tượng p giống như làm việc với bất kỳ danh sách nào khác trong Python. SQLAlchemy xử lý thông tin mối quan hệ một-nhiều cơ bản khi db.session.commit() cuộc gọi được thực hiện.
Ví dụ:giống như một Person cá thể có trường khóa chính person_id được khởi tạo bởi SQLAlchemy khi nó được cam kết với cơ sở dữ liệu, các bản sao của Note sẽ khởi tạo các trường khóa chính của chúng. Ngoài ra, Note khóa ngoại person_id cũng sẽ được khởi tạo bằng giá trị khóa chính của Person ví dụ nó được liên kết với.
Đây là một ví dụ về Person trước đối tượng db.session.commit() trong một loại mã giả:
Person (
person_id = None
lname = 'Farrell'
fname = 'Doug'
timestamp = None
notes = [
Note (
note_id = None
person_id = None
content = 'Cool, a mini-blogging application!'
timestamp = '2019-01-06 22:17:54'
),
Note (
note_id = None
person_id = None
content = 'This could be useful'
timestamp = '2019-01-08 22:17:54'
),
Note (
note_id = None
person_id = None
content = 'Well, sort of useful'
timestamp = '2019-03-06 22:17:54'
)
]
)
Đây là ví dụ về Person đối tượng sau db.session.commit() :
Person (
person_id = 1
lname = 'Farrell'
fname = 'Doug'
timestamp = '2019-02-02 21:27:10.336'
notes = [
Note (
note_id = 1
person_id = 1
content = 'Cool, a mini-blogging application!'
timestamp = '2019-01-06 22:17:54'
),
Note (
note_id = 2
person_id = 1
content = 'This could be useful'
timestamp = '2019-01-08 22:17:54'
),
Note (
note_id = 3
person_id = 1
content = 'Well, sort of useful'
timestamp = '2019-03-06 22:17:54'
)
]
)
Sự khác biệt quan trọng giữa cả hai là khóa chính của Person và Note các đối tượng đã được khởi tạo. Công cụ cơ sở dữ liệu đã giải quyết vấn đề này khi các đối tượng được tạo ra nhờ tính năng tự động tăng dần của các khóa chính được thảo luận trong Phần 2.
Ngoài ra, person_id khóa ngoại trong tất cả Note cá thể đã được khởi tạo để tham chiếu cha mẹ của nó. Điều này xảy ra do thứ tự mà Person và Note các đối tượng được tạo trong cơ sở dữ liệu.
SQLAlchemy nhận thức được mối quan hệ giữa Person và Note các đối tượng. Khi một Person đối tượng được cam kết với person bảng cơ sở dữ liệu, SQLAlchemy lấy person_id giá trị khóa chính. Giá trị đó được sử dụng để khởi tạo giá trị khóa ngoại của person_id trong một Note đối tượng trước khi nó được cam kết với cơ sở dữ liệu.
SQLAlchemy đảm nhận công việc quản lý cơ sở dữ liệu này vì thông tin bạn đã chuyển khi Person.notes thuộc tính được khởi tạo bằng db.relationship(...) đối tượng.
Ngoài ra, Person.timestamp thuộc tính đã được khởi tạo với dấu thời gian hiện tại.
Chạy build_database.py chương trình từ dòng lệnh (trong môi trường ảo sẽ tạo lại cơ sở dữ liệu với các bổ sung mới, chuẩn bị sẵn sàng để sử dụng với ứng dụng web. Dòng lệnh này sẽ xây dựng lại cơ sở dữ liệu:
$ python build_database.py
build_database.py chương trình tiện ích không xuất bất kỳ thông báo nào nếu nó chạy thành công. Nếu nó ném ra một ngoại lệ, thì một lỗi sẽ được in trên màn hình.
Cập nhật API REST
Bạn đã cập nhật mô hình SQLAlchemy và sử dụng chúng để cập nhật people.db cơ sở dữ liệu. Bây giờ đã đến lúc cập nhật REST API để cung cấp quyền truy cập vào thông tin ghi chú mới. Đây là API REST bạn đã xây dựng trong Phần 2:
| Hành động | Động từ HTTP | Đường dẫn URL | Mô tả |
|---|---|---|---|
| Tạo | POST | /api/people | URL để tạo người mới |
| Đọc | GET | /api/people | URL để đọc một tập hợp nhiều người |
| Đọc | GET | /api/people/{person_id} | URL để đọc một người theo person_id |
| Cập nhật | PUT | /api/people/{person_id} | URL để cập nhật một người hiện có theo person_id |
| Xóa | DELETE | /api/people/{person_id} | URL để xóa một người hiện có theo person_id |
API REST ở trên cung cấp các đường dẫn URL HTTP đến các bộ sưu tập của mọi thứ và đến chính những thứ đó. Bạn có thể lấy danh sách người hoặc tương tác với một người từ danh sách người đó. Kiểu đường dẫn này tinh chỉnh những gì được trả về theo cách từ trái sang phải, trở nên chi tiết hơn khi bạn đi.
Bạn sẽ tiếp tục mô hình từ trái sang phải này để hiểu chi tiết hơn và truy cập các bộ sưu tập ghi chú. Đây là API REST mở rộng mà bạn sẽ tạo để cung cấp các ghi chú cho ứng dụng web blog nhỏ:
| Hành động | Động từ HTTP | Đường dẫn URL | Mô tả |
|---|---|---|---|
| Tạo | POST | /api/people/{person_id}/notes | URL để tạo ghi chú mới |
| Đọc | GET | /api/people/{person_id}/notes/{note_id} | URL để đọc ghi chú của một người |
| Cập nhật | PUT | api/people/{person_id}/notes/{note_id} | URL để cập nhật ghi chú của một người |
| Xóa | DELETE | api/people/{person_id}/notes/{note_id} | URL để xóa ghi chú của một người |
| Đọc | GET | /api/notes | URL để nhận tất cả ghi chú cho tất cả mọi người được sắp xếp theo note.timestamp |
Có hai biến thể trong notes một phần của REST API so với quy ước được sử dụng trong people phần:
-
Không có URL nào được xác định để nhận tất cả các
notesliên kết với một người, chỉ một URL để có được một ghi chú duy nhất. Điều này sẽ làm cho API REST hoàn thiện theo một cách nào đó, nhưng ứng dụng web bạn sẽ tạo sau này không cần chức năng này. Do đó, nó đã bị loại bỏ. -
There is the inclusion of the last URL
/api/notes. This is a convenience method created for the web application. It will be used in the mini-blog on the home page to show all the notes in the system. There isn’t a way to get this information readily using the REST API pathing style as designed, so this shortcut has been added.
As in Part 2, the REST API is configured in the swagger.yml file.
Lưu ý:
The idea of designing a REST API with a path that gets more and more granular as you move from left to right is very useful. Thinking this way can help clarify the relationships between different parts of a database. Just be aware that there are realistic limits to how far down a hierarchical structure this kind of design should be taken.
For example, what if the Note object had a collection of its own, something like comments on the notes. Using the current design ideas, this would lead to a URL that went something like this:/api/people/{person_id}/notes/{note_id}/comments/{comment_id}
There is no practical limit to this kind of design, but there is one for usefulness. In actual use in real applications, a long, multilevel URL like that one is hardly ever needed. A more common pattern is to get a list of intervening objects (like notes) and then use a separate API entry point to get a single comment for an application use case.
Implement the API
With the updated REST API defined in the swagger.yml file, you’ll need to update the implementation provided by the Python modules. This means updating existing module files, like models.py and people.py , and creating a new module file called notes.py to implement support for Notes in the extended REST API.
Update Response JSON
The purpose of the REST API is to get useful JSON data out of the database. Now that you’ve updated the SQLAlchemy Person and created the Note models, you’ll need to update the Marshmallow schema models as well. As you may recall from Part 2, Marshmallow is the module that translates the SQLAlchemy objects into Python objects suitable for creating JSON strings.
The updated and newly created Marshmallow schemas are in the models.py module, which are explained below, and look like this:
1class PersonSchema(ma.ModelSchema):
2 class Meta:
3 model = Person
4 sqla_session = db.session
5 notes = fields.Nested('PersonNoteSchema', default=[], many=True)
6
7class PersonNoteSchema(ma.ModelSchema):
8 """
9 This class exists to get around a recursion issue
10 """
11 note_id = fields.Int()
12 person_id = fields.Int()
13 content = fields.Str()
14 timestamp = fields.Str()
15
16class NoteSchema(ma.ModelSchema):
17 class Meta:
18 model = Note
19 sqla_session = db.session
20 person = fields.Nested('NotePersonSchema', default=None)
21
22class NotePersonSchema(ma.ModelSchema):
23 """
24 This class exists to get around a recursion issue
25 """
26 person_id = fields.Int()
27 lname = fields.Str()
28 fname = fields.Str()
29 timestamp = fields.Str()
There are some interesting things going on in the above definitions. The PersonSchema class has one new entry:the notes attribute defined in line 5. This defines it as a nested relationship to the PersonNoteSchema . It will default to an empty list if nothing is present in the SQLAlchemy notes mối quan hệ. The many=True parameter indicates that this is a one-to-many relationship, so Marshmallow will serialize all the related notes .
The PersonNoteSchema class defines what a Note object looks like as Marshmallow serializes the notes danh sách. The NoteSchema defines what a SQLAlchemy Note object looks like in terms of Marshmallow. Notice that it has a person thuộc tính. This attribute comes from the SQLAlchemy db.relationship(...) definition parameter backref='person' . The person Marshmallow definition is nested, but because it doesn’t have the many=True parameter, there is only a single person được kết nối.
The NotePersonSchema class defines what is nested in the NoteSchema.person attribute.
Lưu ý:
You might be wondering why the PersonSchema class has its own unique PersonNoteSchema class to define the notes collection attribute. By the same token, the NoteSchema class has its own unique NotePersonSchema class to define the person thuộc tính. You may be wondering whether the PersonSchema class could be defined this way:
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
notes = fields.Nested('NoteSchema', default=[], many=True)
Additionally, couldn’t the NoteSchema class be defined using the PersonSchema to define the person attribute? A class definition like this would each refer to the other, and this causes a recursion error in Marshmallow as it will cycle from PersonSchema to NoteSchema until it runs out of stack space. Using the unique schema references breaks the recursion and allows this kind of nesting to work.
People
Now that you’ve got the schemas in place to work with the one-to-many relationship between Person and Note , you need to update the person.py and create the note.py modules in order to implement a working REST API.
The people.py module needs two changes. The first is to import the Note class, along with the Person class at the top of the module. Then only read_one(person_id) needs to change in order to handle the relationship. That function will look like this:
1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: Id of person to find
7 :return: person matching id
8 """
9 # Build the initial query
10 person = (
11 Person.query.filter(Person.person_id == person_id)
12 .outerjoin(Note)
13 .one_or_none()
14 )
15
16 # Did we find a person?
17 if person is not None:
18
19 # Serialize the data for the response
20 person_schema = PersonSchema()
21 data = person_schema.dump(person).data
22 return data
23
24 # Otherwise, nope, didn't find that person
25 else:
26 abort(404, f"Person not found for Id: {person_id}")
The only difference is line 12:.outerjoin(Note) . An outer join (left outer join in SQL terms) is necessary for the case where a user of the application has created a new person object, which has no notes related to it. The outer join ensures that the SQL query will return a person object, even if there are no note rows to join with.
At the start of this article, you saw how person and note data could be represented in a single, flat table, and all of the disadvantages of that approach. You also saw the advantages of breaking that data up into two tables, person and note , with a relationship between them.
Until now, we’ve been working with the data as two distinct, but related, items in the database. But now that you’re actually going to use the data, what we essentially want is for the data to be joined back together. This is what a database join does. It combines data from two tables together using the primary key to foreign key relationship.
A join is kind of a boolean and operation because it only returns data if there is data in both tables to combine. If, for example, a person row exists but has no related note row, then there is nothing to join, so nothing is returned. This isn’t what you want for read_one(person_id) .
This is where the outer join comes in handy. It’s a kind of boolean or hoạt động. It returns person data even if there is no associated note data to combine with. This is the behavior you want for read_one(person_id) to handle the case of a newly created Person object that has no notes yet.
You can see the complete people.py in the article repository.
Notes
You’ll create a notes.py module to implement all the Python code associated with the new note related REST API definitions. In many ways, it works like the people.py module, except it must handle both a person_id and a note_id as defined in the swagger.yml configuration file. As an example, here is read_one(person_id, note_id) :
1def read_one(person_id, note_id):
2 """
3 This function responds to a request for
4 /api/people/{person_id}/notes/{note_id}
5 with one matching note for the associated person
6
7 :param person_id: Id of person the note is related to
8 :param note_id: Id of the note
9 :return: json string of note contents
10 """
11 # Query the database for the note
12 note = (
13 Note.query.join(Person, Person.person_id == Note.person_id)
14 .filter(Person.person_id == person_id)
15 .filter(Note.note_id == note_id)
16 .one_or_none()
17 )
18
19 # Was a note found?
20 if note is not None:
21 note_schema = NoteSchema()
22 data = note_schema.dump(note).data
23 return data
24
25 # Otherwise, nope, didn't find that note
26 else:
27 abort(404, f"Note not found for Id: {note_id}")
The interesting parts of the above code are lines 12 to 17:
- Line 13 begins a query against the
NoteSQLAlchemy objects and joins to the relatedPersonSQLAlchemy object comparingperson_idfrom bothPersonandNote. - Line 14 filters the result down to the
Noteobjects that has aPerson.person_idequal to the passed inperson_idparameter. - Line 15 filters the result further to the
Noteobject that has aNote.note_idequal to the passed innote_idparameter. - Line 16 returns the
Noteobject if found, orNoneif nothing matching the parameters is found.
You can check out the complete notes.py .
Updated Swagger UI
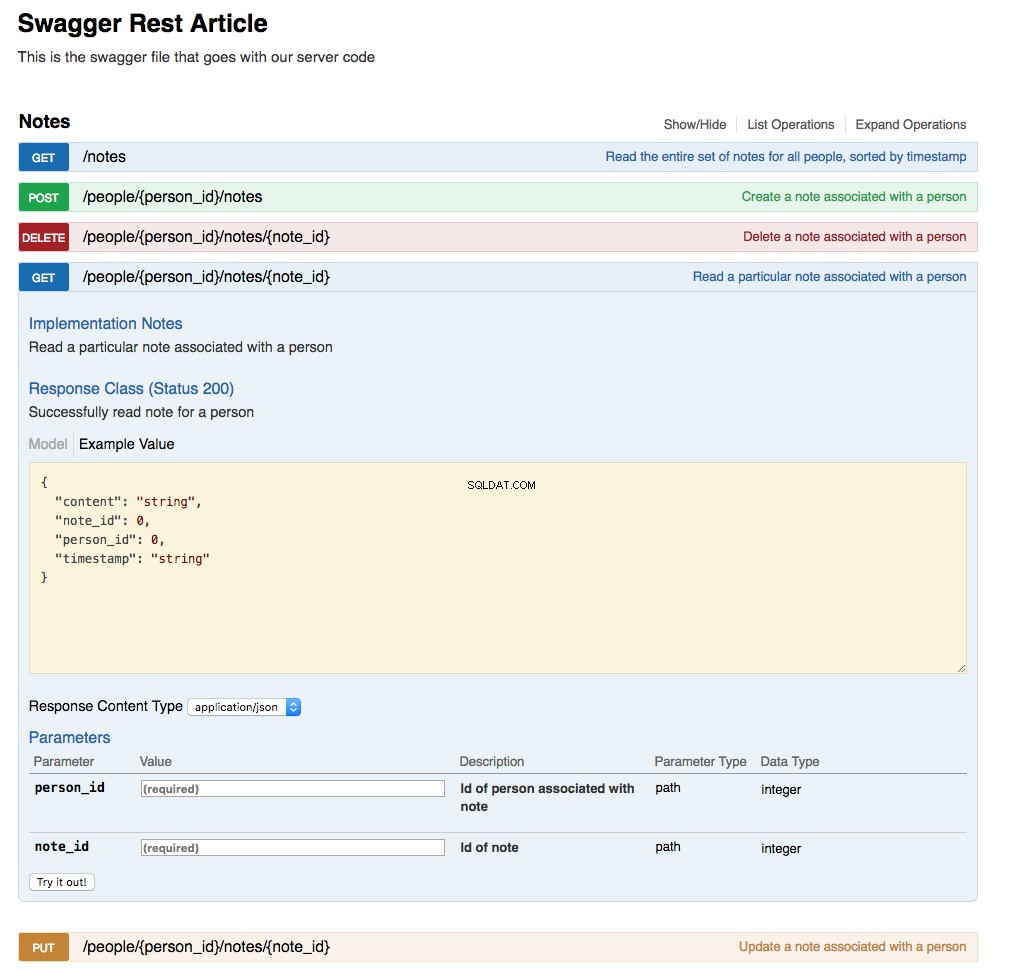
The Swagger UI has been updated by the action of updating the swagger.yml file and creating the URL endpoint implementations. Below is a screenshot of the updated UI showing the Notes section with the GET /api/people/{person_id}/notes/{note_id} expanded:
Mini-Blogging Web Application
The web application has been substantially changed to show its new purpose as a mini-blogging application. It has three pages:
-
The home page (
localhost:5000/) , which shows all of the blog messages (notes) sorted from newest to oldest -
The people page (
localhost:5000/people) , which shows all the people in the system, sorted by last name, and also allows the user to create a new person and update or delete an existing one -
The notes page (
localhost:5000/people/{person_id}/notes) , which shows all the notes associated with a person, sorted from newest to oldest, and also allows the user to create a new note and update or delete an existing one
Navigation
There are two buttons on every page of the application:
- The Home button will navigate to the home screen.
- The People button navigates to the
/peoplescreen, showing all people in the database.
These two buttons are present on every screen in the application as a way to get back to a starting point.
Home Page
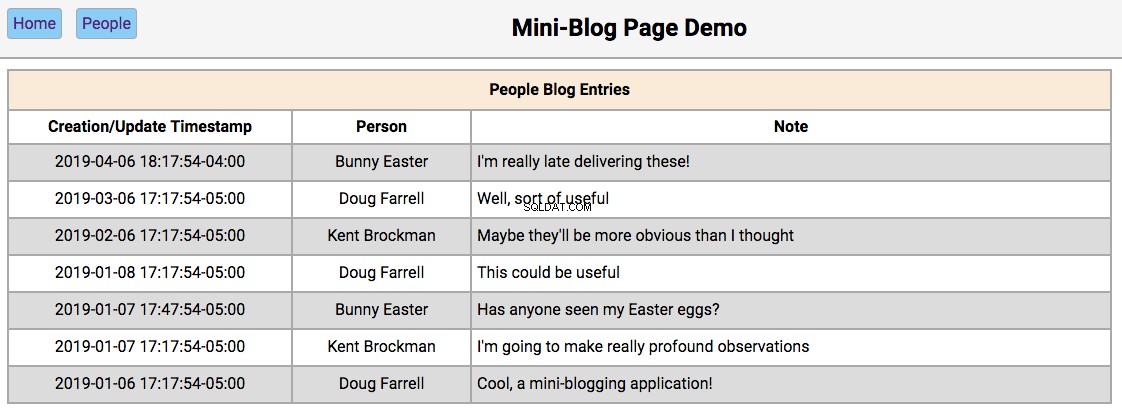
Below is a screenshot of the home page showing the initialized database contents:
The functionality of this page works like this:
-
Double-clicking on a person’s name will take the user to the
/people/{person_id}page, with the editor section filled in with the person’s first and last names and the update and reset buttons enabled. -
Double-clicking on a person’s note will take the user to the
/people/{person_id}/notes/{note_id}page, with the editor section filled in with the note’s contents and the Update and Reset buttons enabled.
People Page
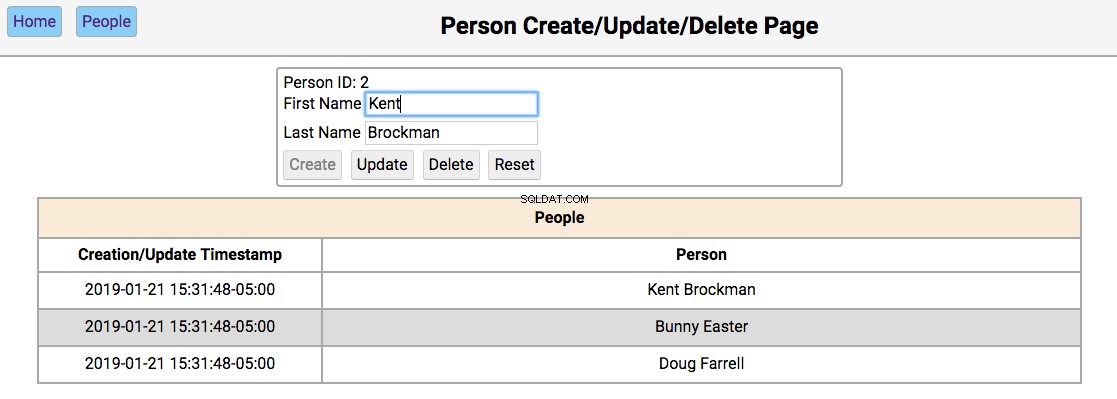
Below is a screenshot of the people page showing the people in the initialized database:
The functionality of this page works like this:
-
Single-clicking on a person’s name will populate the editor section of the page with the person’s first and last name, disabling the Create button, and enabling the Update and Delete nút.
-
Double clicking on a person’s name will navigate to the notes pages for that person.
The functionality of the editor works like this:
-
If the first and last name fields are empty, the Create and Reset buttons are enabled. Entering a new name in the fields and clicking Create will create a new person and update the database and re-render the table below the editor. Clicking Reset will clear the editor fields.
-
If the first and last name fields have data, the user navigated here by double-clicking the person’s name from the home screen. In this case, the Update , Delete , and Reset buttons are enabled. Changing the first or last name and clicking Update will update the database and re-render the table below the editor. Clicking Delete will remove the person from the database and re-render the table.
Notes Page
Below is a screenshot of the notes page showing the notes for a person in the initialized database:
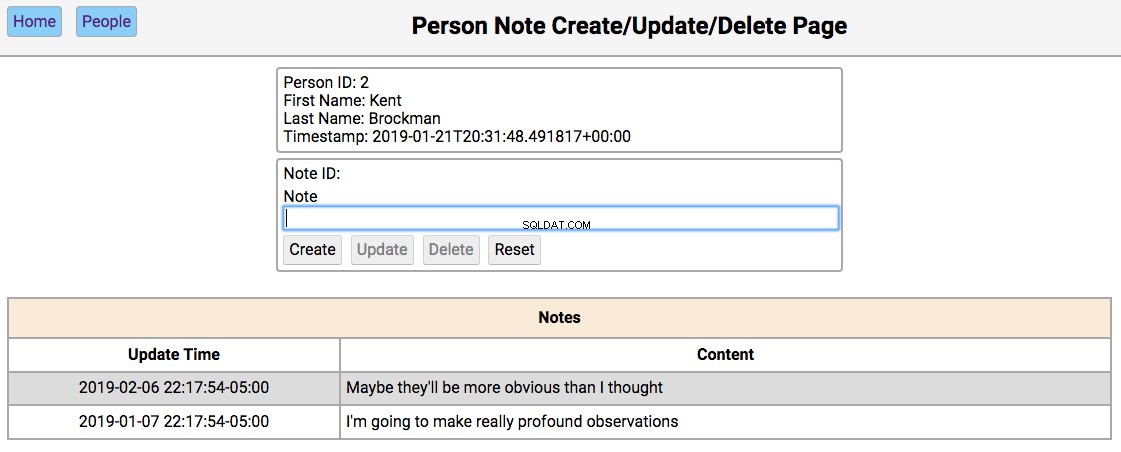
The functionality of this page works like this:
-
Single-clicking on a note will populate the editor section of the page with the notes content, disabling the Create button, and enabling the Update and Delete nút.
-
All other functionality of this page is in the editor section.
The functionality of the editor works like this:
-
If the note content field is empty, then the Create and Reset buttons are enabled. Entering a new note in the field and clicking Create will create a new note and update the database and re-render the table below the editor. Clicking Reset will clear the editor fields.
-
If the note field has data, the user navigated here by double-clicking the person’s note from the home screen. In this case, the Update , Delete , and Reset buttons are enabled. Changing the note and clicking Update will update the database and re-render the table below the editor. Clicking Delete will remove the note from the database and re-render the table.
Web Application
This article is primarily focused on how to use SQLAlchemy to create relationships in the database, and how to extend the REST API to take advantage of those relationships. As such, the code for the web application didn’t get much attention. When you look at the web application code, keep an eye out for the following features:
-
Each page of the application is a fully formed single page web application.
-
Each page of the application is driven by JavaScript following an MVC (Model/View/Controller) style of responsibility delegation.
-
The HTML that creates the pages takes advantage of the Jinja2 inheritance functionality.
-
The hardcoded JavaScript table creation has been replaced by using the Handlebars.js templating engine.
-
The timestamp formating in all of the tables is provided by Moment.js.
You can find the following code in the repository for this article:
- The HTML for the web application
- The CSS for the web application
- The JavaScript for the web application
All of the example code for this article is available in the GitHub repository for this article. This contains all of the code related to this article, including all of the web application code.
Conclusion
Congratulations are in order for what you’ve learned in this article! Knowing how to build and use database relationships gives you a powerful tool to solve many difficult problems. There are other relationship besides the one-to-many example from this article. Other common ones are one-to-one, many-to-many, and many-to-one. All of them have a place in your toolbelt, and SQLAlchemy can help you tackle them all!
For more information about databases, you can check out these tutorials. You can also set up Flask to use SQLAlchemy. You can check out Model-View-Controller (MVC) more information about the pattern used in the web application JavaScript code.
In Part 4 of this series, you’ll focus on the HTML, CSS, and JavaScript files used to create the web application.
« Part 2:Database PersistencePart 3:Database RelationshipsPart 4:Simple Web Applications »