Tất cả chúng ta đều trở nên hư hỏng bởi khả năng "giải quyết" của các công cụ tìm kiếm như lỗi chính tả, sự khác biệt về chính tả tên hoặc bất kỳ tình huống nào khác trong đó cụm từ tìm kiếm có thể khớp trên các trang mà tác giả có thể thích sử dụng cách viết khác của một từ. Việc thêm các tính năng như vậy vào các ứng dụng hướng cơ sở dữ liệu của riêng chúng tôi có thể làm phong phú và nâng cao các ứng dụng của chúng tôi một cách tương tự, và trong khi các hệ thống quản lý cơ sở dữ liệu quan hệ thương mại (RDBMS) cung cấp các giải pháp tùy chỉnh được phát triển đầy đủ của riêng họ cho vấn đề này, thì chi phí cấp phép của các công cụ này có thể không phải tiếp cận các nhà phát triển nhỏ hơn hoặc các công ty phát triển phần mềm nhỏ.
Người ta có thể tranh luận rằng điều này có thể được thực hiện bằng cách sử dụng một trình kiểm tra chính tả. Tuy nhiên, công cụ kiểm tra chính tả thường không được sử dụng khi đối sánh chính tả đúng, nhưng có thể thay thế, của tên hoặc từ khác. Kết hợp bằng âm thanh lấp đầy khoảng trống chức năng này. Đó là chủ đề của hướng dẫn lập trình ngày hôm nay:cách truy vấn âm thanh với Python bằng Metaphones.
Soundex là gì?
Soundex được phát triển vào đầu thế kỷ 20 như một phương tiện cho Điều tra dân số Hoa Kỳ để khớp các tên dựa trên cách chúng phát âm. Sau đó, nó được các công ty điện thoại khác nhau sử dụng để ghép tên khách hàng. Nó tiếp tục được sử dụng để đối sánh dữ liệu ngữ âm cho đến ngày nay mặc dù nó bị giới hạn trong cách viết và phát âm tiếng Anh Mỹ. Nó cũng được giới hạn trong các chữ cái tiếng Anh. Hầu hết các RDBMS, chẳng hạn như SQL Server và Oracle, cùng với MySQL và các biến thể của nó, triển khai một hàm Soundex và mặc dù có những hạn chế, nó vẫn tiếp tục được sử dụng để đối sánh với nhiều từ không phải tiếng Anh.
Siêu âm đôi là gì?
Metaphone thuật toán được phát triển vào năm 1990 và nó khắc phục được một số hạn chế của Soundex. Vào năm 2000, một bản tiếp theo được cải tiến, Double Metaphone , đã được phát triển. Double Metaphone trả về một giá trị chính và phụ tương ứng với hai cách mà một từ đơn có thể được phát âm. Cho đến ngày nay, thuật toán này vẫn là một trong những thuật toán ngữ âm mã nguồn mở tốt hơn. Metaphone 3 được phát hành vào năm 2009 như một cải tiến của Double Metaphone, nhưng đây là một sản phẩm thương mại.
Thật không may, nhiều RDBMS nổi bật được đề cập ở trên không triển khai Double Metaphone và hầu hết ngôn ngữ kịch bản nổi bật không cung cấp triển khai Double Metaphone được hỗ trợ. Tuy nhiên, Python cung cấp một mô-đun triển khai Double Metaphone.
Các ví dụ được trình bày trong hướng dẫn lập trình Python này sử dụng MariaDB phiên bản 10.5.12 và Python 3.9.2, cả hai đều chạy trên Kali / Debian Linux.
Cách thêm Double Metaphone vào Python
Giống như bất kỳ mô-đun Python nào, công cụ pip có thể được sử dụng để cài đặt Double Metaphone. Cú pháp phụ thuộc vào cài đặt Python của bạn. Cài đặt Double Metaphone thông thường trông giống như ví dụ sau:
# Typical if you have only Python 3 installed $ pip install doublemetaphone # If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install DoubleMetaphone
Lưu ý rằng việc viết hoa thêm là có chủ ý. Đoạn mã sau là một ví dụ về cách sử dụng Double Metaphone trong Python:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 1 - Demo script to verify functionality
Tập lệnh Python ở trên cung cấp kết quả sau khi chạy trong môi trường phát triển tích hợp (IDE) hoặc trình soạn thảo mã của bạn:
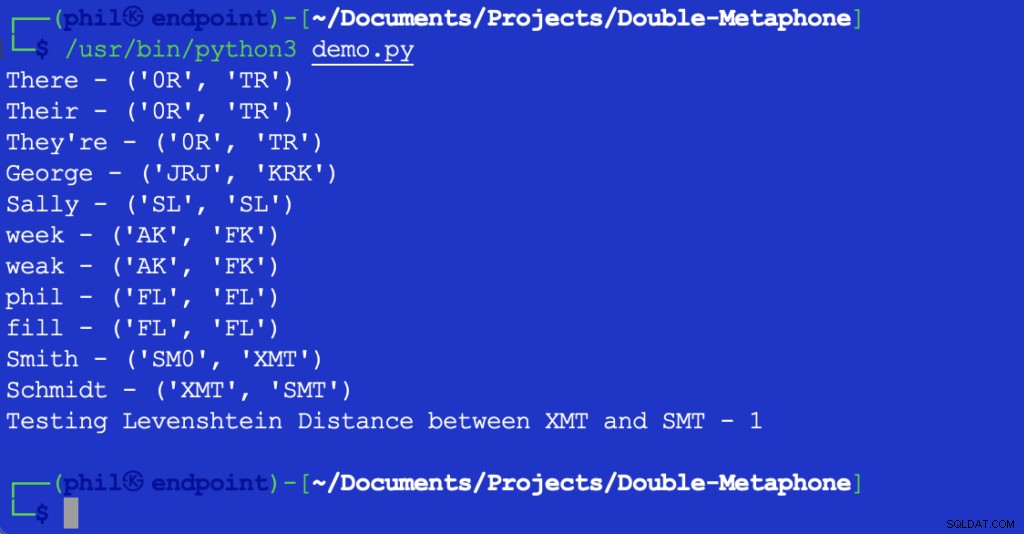
Hình 1 - Đầu ra của Tập lệnh Demo
Có thể thấy ở đây, mỗi từ đều có giá trị ngữ âm chính và phụ. Các từ khớp trên cả giá trị chính hoặc phụ được cho là khớp ngữ âm. Các từ chia sẻ ít nhất một giá trị ngữ âm hoặc có chung một vài ký tự đầu tiên trong bất kỳ giá trị ngữ âm nào, được cho là gần nhau về mặt ngữ âm.
Hầu hết các chữ cái được hiển thị tương ứng với cách phát âm tiếng Anh của họ. X có thể tương ứng với KS , SH hoặc C . 0 tương ứng với th âm thanh trong the hoặc ở đó . Các nguyên âm chỉ được ghép ở đầu từ. Do số lượng khác biệt không thể đếm được trong giọng vùng miền, không thể nói rằng các từ có thể khớp chính xác một cách khách quan, ngay cả khi chúng có cùng giá trị ngữ âm.
So sánh giá trị ngữ âm với Python
Có rất nhiều tài nguyên trực tuyến có thể mô tả toàn bộ hoạt động của thuật toán Double Metaphone; tuy nhiên, điều này là không cần thiết để sử dụng vì chúng tôi quan tâm hơn đến việc so sánh các giá trị được tính toán, nhiều hơn chúng ta quan tâm đến việc tính toán các giá trị. Như đã nêu trước đó, nếu có ít nhất một giá trị chung giữa hai từ, thì có thể nói rằng các giá trị này là khớp phiên âm và các giá trị ngữ âm tương tự gần về mặt ngữ âm .
So sánh các giá trị tuyệt đối rất dễ dàng, nhưng làm thế nào để xác định các chuỗi là giống nhau? Mặc dù không có giới hạn kỹ thuật nào ngăn bạn so sánh các chuỗi nhiều từ, nhưng những so sánh này thường không đáng tin cậy. Bám sát vào việc so sánh các từ đơn.
Khoảng cách Levenshtein là gì?
Khoảng cách Levenshtein giữa hai chuỗi là số ký tự đơn phải được thay đổi trong một chuỗi để làm cho nó khớp với chuỗi thứ hai. Cặp dây có khoảng cách Levenshtein thấp hơn tương đồng với nhau hơn cặp dây có khoảng cách Levenshtein cao hơn. Khoảng cách Levenshtein tương tự như Khoảng cách Hamming , nhưng cái sau được giới hạn ở các chuỗi có cùng độ dài, vì các giá trị ngữ âm của Siêu âm đôi có thể khác nhau về độ dài, sẽ hợp lý hơn nếu so sánh các chuỗi này bằng Khoảng cách Levenshtein.
Thư viện khoảng cách Levenshtein trong Python
Python có thể được mở rộng để hỗ trợ tính toán Khoảng cách Levenshtein thông qua Mô-đun Python:
# If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install python-Levenshtein
Lưu ý rằng, cũng như cài đặt DoubleMetaphone ở trên, cú pháp của lệnh gọi tới pip có thể thay đổi. Mô-đun python-Levenshtein cung cấp nhiều chức năng hơn là chỉ tính toán Khoảng cách Levenshtein.
Đoạn mã dưới đây hiển thị một bài kiểm tra tính toán Khoảng cách Levenshtein bằng Python:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 2 - Demo extended to verify Levenshtein Distance calculation functionality
Việc thực thi tập lệnh này cho kết quả sau:
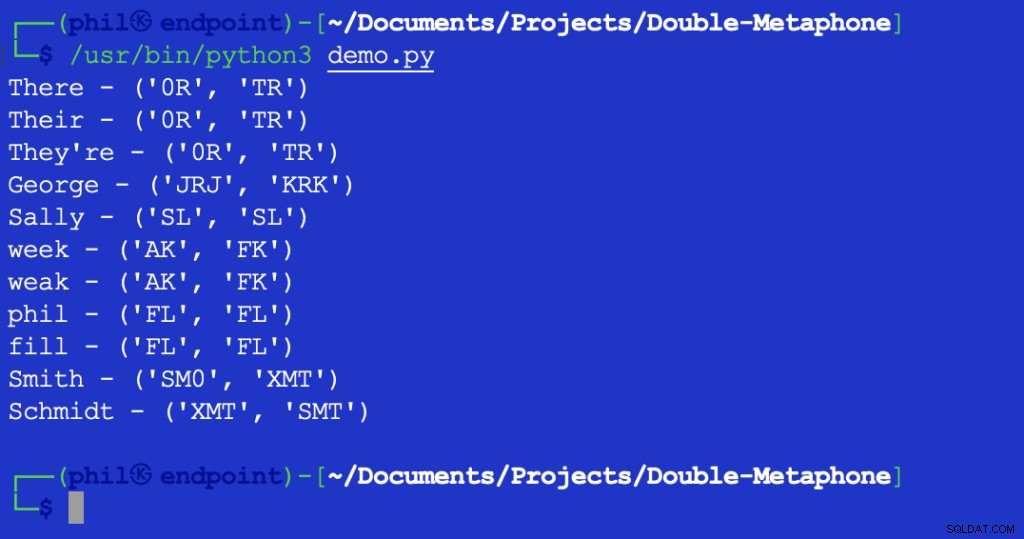
Hình 2 - Đầu ra của bài kiểm tra Khoảng cách Levenshtein
Giá trị trả về của 1 cho biết rằng có một ký tự giữa XMT và SMT đó là khác nhau. Trong trường hợp này, nó là ký tự đầu tiên trong cả hai chuỗi.
So sánh phép ẩn dụ kép trong Python
Những gì sau đây không phải là tất cả và cuối cùng của tất cả các so sánh ngữ âm. Nó chỉ đơn giản là một trong nhiều cách để thực hiện một phép so sánh như vậy. Để so sánh hiệu quả độ gần ngữ âm của hai chuỗi nhất định bất kỳ, thì mỗi giá trị ngữ âm của Siêu âm đôi của một chuỗi phải được so sánh với giá trị ngữ âm của Siêu âm đôi tương ứng của chuỗi khác. Vì cả hai giá trị ngữ âm của một chuỗi nhất định đều có trọng số bằng nhau, nên giá trị trung bình của các giá trị so sánh này sẽ cho giá trị gần đúng về mặt ngữ âm một cách hợp lý:
PN = [ Dist(DM11, DM21,) + Dist(DM12, DM22,) ] / 2.0
Ở đâu:
- DM1 (1) :Giá trị siêu âm đôi đầu tiên của chuỗi 1,
- DM1 (2) :Giá trị siêu âm kép thứ hai của chuỗi 1
- DM2 (1) :Giá trị Metaphone Đôi đầu tiên của Chuỗi 2
- DM2 (2) :Giá trị siêu âm kép thứ hai của chuỗi 2
- PN :Độ gần ngữ âm, với các giá trị thấp hơn gần hơn các giá trị cao hơn. Giá trị 0 cho biết sự giống nhau về ngữ âm. Giá trị cao nhất của giá trị này là số chữ cái trong chuỗi ngắn nhất.
Công thức này được chia nhỏ trong các trường hợp như Schmidt (XMT, SMT) và Smith (SM0, XMT) trong đó giá trị ngữ âm đầu tiên của chuỗi thứ nhất khớp với giá trị ngữ âm thứ hai của chuỗi thứ hai. Trong những tình huống như vậy, cả Schmidt và Smith có thể được coi là tương đồng về mặt ngữ âm vì giá trị được chia sẻ. Mã cho hàm độ gần chỉ nên áp dụng công thức trên khi cả bốn giá trị ngữ âm đều khác nhau. Công thức cũng có điểm yếu khi so sánh các chuỗi có độ dài khác nhau.
Lưu ý, không có cách nào hiệu quả đặc biệt để so sánh các chuỗi có độ dài khác nhau, ngay cả khi tính toán Khoảng cách Levenshtein giữa hai yếu tố chuỗi có sự khác biệt về độ dài chuỗi. Một giải pháp khả thi là so sánh cả hai chuỗi với độ dài của chuỗi ngắn hơn trong hai chuỗi.
Dưới đây là đoạn mã mẫu triển khai mã ở trên, cùng với một số mẫu thử nghiệm:
# demo2.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testwords = ["Philippe", "Phillip", "Sallie", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt", "Harold", "Herald"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
print ("Distance between AK and AK - " + str(distance('AK', 'AK')) + "]")
print ("Comparing week and weak - [" + str(Nearness("week", "weak")) + "]")
print ("Comparing Harold and Herald - [" + str(Nearness("Harold", "Herald")) + "]")
print ("Comparing Smith and Schmidt - [" + str(Nearness("Smith", "Schmidt")) + "]")
print ("Comparing Philippe and Phillip - [" + str(Nearness("Philippe", "Phillip")) + "]")
print ("Comparing Phil and Phillip - [" + str(Nearness("Phil", "Phillip")) + "]")
print ("Comparing Robert and Joseph - [" + str(Nearness("Robert", "Joseph")) + "]")
print ("Comparing Samuel and Elizabeth - [" + str(Nearness("Samuel", "Elizabeth")) + "]")
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 3 - Implementation of the Nearness Algorithm Above
Mã Python mẫu cho kết quả sau:
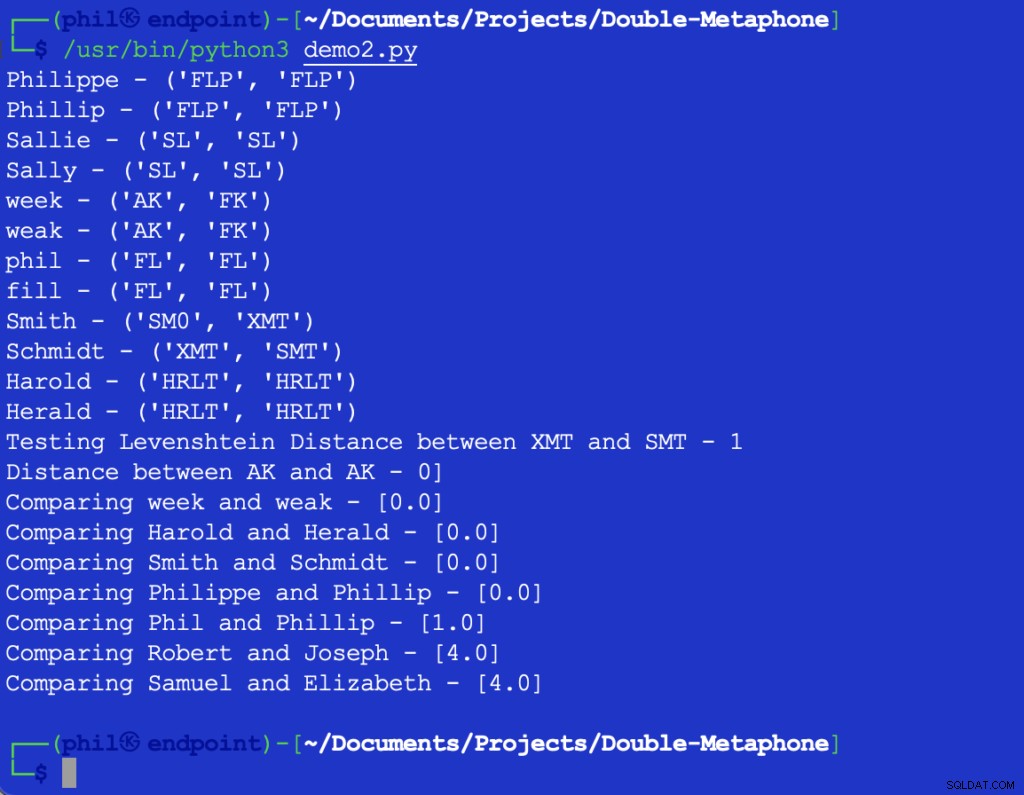
Hình 3 - Đầu ra của thuật toán độ gần
Tập hợp mẫu xác nhận xu hướng chung rằng sự khác biệt về từ ngữ càng lớn thì đầu ra của Độ gần càng cao chức năng.
Tích hợp cơ sở dữ liệu bằng Python
Đoạn mã trên vi phạm khoảng cách chức năng giữa một RDBMS nhất định và một triển khai Siêu âm đôi. Trên hết, bằng cách triển khai Sự gần gũi trong Python, nó trở nên dễ thay thế nếu một thuật toán so sánh khác được ưu tiên.
Hãy xem xét bảng MySQL / MariaDB sau:
create table demo_names (record_id int not null auto_increment, lastname varchar(100) not null default '', firstname varchar(100) not null default '', primary key(record_id)); Listing 4 - MySQL/MariaDB CREATE TABLE statement
Trong hầu hết các ứng dụng hướng cơ sở dữ liệu, phần mềm trung gian soạn các Câu lệnh SQL để quản lý dữ liệu, bao gồm cả việc chèn nó. Đoạn mã sau sẽ chèn một số tên mẫu vào bảng này, nhưng trên thực tế, bất kỳ mã nào từ ứng dụng web hoặc máy tính để bàn thu thập dữ liệu như vậy đều có thể làm điều tương tự.
# demo3.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testNames = ["Smith, Jane", "Williams, Tim", "Adams, Richard", "Franks, Gertrude", "Smythe, Kim", "Daniels, Imogen", "Nguyen, Nancy",
"Lopez, Regina", "Garcia, Roger", "Diaz, Catalina"]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
for name in testNames:
nameParts = name.split(',')
# Normally one should do bounds checking here.
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
sql = "insert into demo_names (lastname, firstname) values(%s, %s)"
values = (lastname, firstname)
insertCursor = mydb.cursor()
insertCursor.execute (sql, values)
mydb.commit()
mydb.close()
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Inserting sample data into a database.
Chạy mã này không in ra bất kỳ thứ gì, nhưng nó điền bảng kiểm tra trong cơ sở dữ liệu cho danh sách tiếp theo để sử dụng. Truy vấn bảng trực tiếp trong máy khách MySQL có thể xác minh rằng mã trên đã hoạt động:
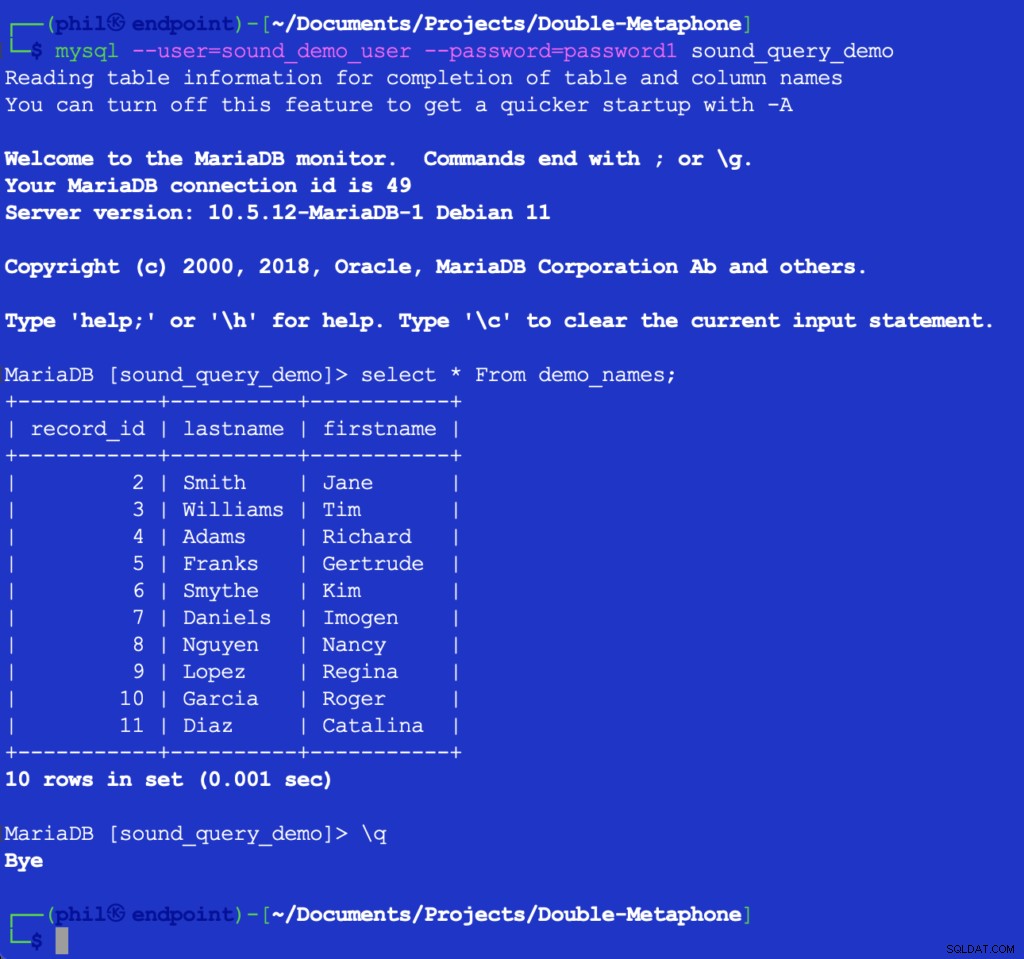
Hình 4- Dữ liệu bảng đã chèn
Đoạn mã dưới đây sẽ cung cấp một số dữ liệu so sánh vào dữ liệu bảng ở trên và thực hiện so sánh gần giống với nó:
# demo4.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
comparisonNames = ["Smith, John", "Willard, Tim", "Adamo, Franklin" ]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
sql = "select lastname, firstname from demo_names order by lastname, firstname"
cursor1 = mydb.cursor()
cursor1.execute (sql)
results1 = cursor1.fetchall()
cursor1.close()
mydb.close()
for comparisonName in comparisonNames:
nameParts = comparisonName.split(",")
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
print ("Comparison for " + firstname + " " + lastname + ":")
for result in results1:
firstnameNearness = Nearness (firstname, result[1])
lastnameNearness = Nearness (lastname, result[0])
print ("\t[" + firstname + "] vs [" + result[1] + "] - " + str(firstnameNearness)
+ ", [" + lastname + "] vs [" + result[0] + "] - " + str(lastnameNearness))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Nearness Comparison Demo
Chạy mã này sẽ cho chúng tôi kết quả bên dưới:
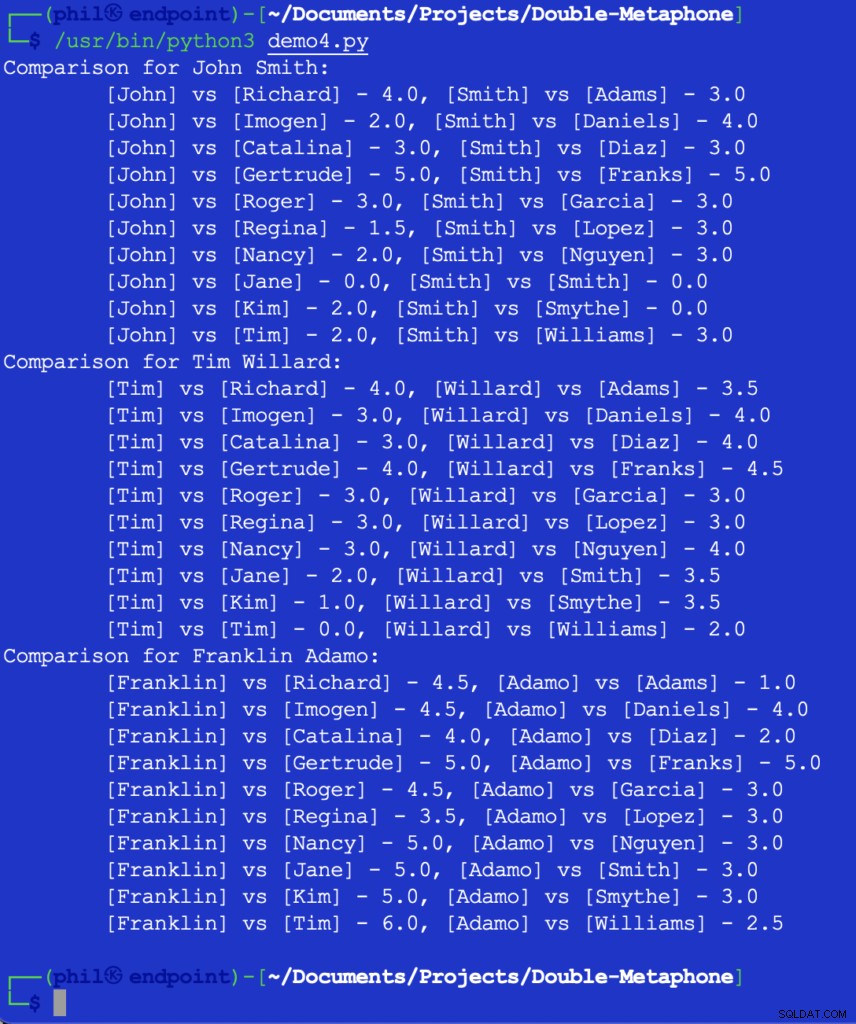
Hình 5 - Kết quả so sánh độ gần
Tại thời điểm này, nhà phát triển sẽ tùy thuộc vào quyết định ngưỡng nào cho những gì tạo thành một phép so sánh hữu ích. Một số con số ở trên có vẻ bất ngờ hoặc đáng ngạc nhiên, nhưng một bổ sung có thể có cho mã có thể là IF để lọc ra bất kỳ giá trị so sánh nào lớn hơn 2 .
Có thể cần lưu ý rằng bản thân các giá trị ngữ âm không được lưu trữ trong cơ sở dữ liệu. Điều này là do chúng được tính như một phần của mã Python và không có nhu cầu thực sự để lưu trữ chúng ở bất kỳ đâu vì chúng sẽ bị loại bỏ khi chương trình thoát, tuy nhiên, nhà phát triển có thể tìm thấy giá trị trong việc lưu trữ chúng trong cơ sở dữ liệu và sau đó thực hiện so sánh chức năng trong cơ sở dữ liệu một thủ tục được lưu trữ. Tuy nhiên, một nhược điểm lớn của điều này là làm mất tính di động của mã.
Những suy nghĩ cuối cùng về Truy vấn Dữ liệu bằng Âm thanh với Python
So sánh dữ liệu bằng âm thanh dường như không nhận được sự “yêu thích” hoặc sự chú ý mà so sánh dữ liệu bằng phân tích hình ảnh có thể nhận được, nhưng nếu một ứng dụng phải xử lý nhiều biến thể có âm giống nhau của các từ trong nhiều ngôn ngữ, thì nó có thể rất hữu ích dụng cụ. Một tính năng hữu ích của loại phân tích này là nhà phát triển không cần phải là một chuyên gia ngôn ngữ học hoặc ngữ âm học để sử dụng các công cụ này. Nhà phát triển cũng rất linh hoạt trong việc xác định cách so sánh các dữ liệu đó; các so sánh có thể được điều chỉnh dựa trên nhu cầu ứng dụng hoặc logic nghiệp vụ.
Hy vọng rằng lĩnh vực nghiên cứu này sẽ được chú ý nhiều hơn trong lĩnh vực nghiên cứu và sẽ có nhiều công cụ phân tích có năng lực và mạnh mẽ hơn trong tương lai.