Giờ đây, cộng đồng phân tích dữ liệu lớn của chúng tôi đã bắt đầu sử dụng Apache Spark để xử lý dữ liệu lớn. Quá trình xử lý có thể cho các truy vấn đặc biệt, các truy vấn tạo sẵn, xử lý đồ thị, học máy và thậm chí cả cho luồng dữ liệu.
Do đó, sự hiểu biết về Spark Job Submission là rất quan trọng đối với cộng đồng. Rất vui khi được chia sẻ với bạn những kiến thức về các bước liên quan đến Apache Spark Job Submission.
Về cơ bản, nó có hai bước,

Nộp đơn xin việc
Lệnh Spark được gửi tự động khi một hành động như count () được thực hiện trên RDD.
Nội bộ runJob () sẽ được gọi trên SparkContext và sau đó gọi đến bộ lập lịch chạy như một phần của bộ dẫn xuất.
Bộ lập lịch bao gồm 2 phần - Bộ lập lịch DAG và Bộ lập lịch tác vụ.
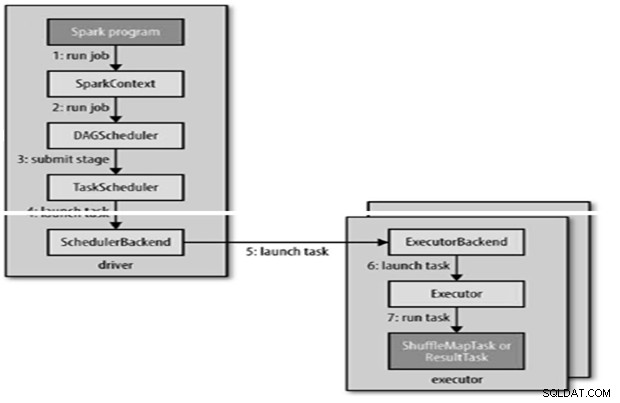
Xây dựng DAG
Có hai loại cấu trúc DAG,

- Công việc Spark đơn giản là công việc không cần xáo trộn và chỉ có một giai đoạn duy nhất bao gồm các tác vụ kết quả, chẳng hạn như công việc chỉ lập bản đồ trong MapReduce
- Công việc Spark phức tạp bao gồm các hoạt động nhóm và yêu cầu một hoặc nhiều giai đoạn xáo trộn.
- Bộ lập lịch DAG của Spark biến công việc thành hai giai đoạn.
- Bộ lập lịch DAG chịu trách nhiệm chia một giai đoạn thành các nhiệm vụ để gửi cho bộ lập lịch tác vụ.
- Mỗi tác vụ được bộ lập lịch DAG đưa ra tùy chọn vị trí để cho phép bộ lập lịch tác vụ tận dụng lợi thế của vị trí dữ liệu.
- Các giai đoạn con chỉ được gửi sau khi cha mẹ của chúng đã hoàn thành thành công.
Lập lịch tác vụ
- Bộ lập lịch tác vụ sẽ gửi một nhóm tác vụ; nó sử dụng danh sách những người thực thi đang chạy cho ứng dụng và xây dựng ánh xạ các nhiệm vụ tới những người thực thi có tính đến các tùy chọn vị trí.
- Bộ lập lịch tác vụ chỉ định cho những người thực thi có lõi miễn phí, mỗi tác vụ được cấp phát một lõi theo mặc định. Nó có thể được thay đổi bằng tham số spark.task.cpus.
- Spark sử dụng Akka, là nền tảng dựa trên diễn viên để xây dựng các ứng dụng phân tán theo hướng sự kiện có khả năng mở rộng cao.
- Spark không sử dụng Hadoop RPC cho các cuộc gọi từ xa.
Thực thi Tác vụ
Người thực thi chạy một tác vụ như sau,
- Nó đảm bảo rằng JAR và tệp phụ thuộc cho nhiệm vụ được cập nhật.
- Hủy tuần tự hóa mã tác vụ.
- Mã tác vụ được thực thi.
- Tác vụ trả về kết quả cho trình điều khiển, kết quả này sẽ tổng hợp thành kết quả cuối cùng để trả lại cho người dùng.
Tham chiếu
- Hướng dẫn cuối cùng về Hadoop
- Cộng đồng nguồn mở Analytics &Dữ liệu lớn
Bài viết này ban đầu xuất hiện ở đây. Được phép xuất bản lại. Gửi khiếu nại bản quyền của bạn tại đây.