Để triển khai hỗ trợ đa ngôn ngữ trong mô hình dữ liệu của bạn, bạn không cần phải phát minh lại bánh xe. Bài viết này sẽ chỉ cho bạn các cách khác nhau để thực hiện và giúp bạn chọn cách phù hợp nhất với mình.
Khái niệm bản địa hóa rất quan trọng đối với sự phát triển của một ứng dụng phần mềm, đặc biệt khi phạm vi của ứng dụng đó là toàn cầu. Hỗ trợ cho nhiều ngôn ngữ là khía cạnh chính cần xem xét; thiết kế cơ sở dữ liệu hỗ trợ ứng dụng đa ngôn ngữ cho phép bạn đa dạng hóa thị trường mục tiêu và do đó tiếp cận được nhiều khách hàng hơn. Bên cạnh đó, thiết kế cơ sở dữ liệu như vậy có thể là một phần trong chiến lược dài hạn của bạn để thiết kế các hệ thống sẵn sàng bản địa hóa.
Chìa khóa để kết hợp hỗ trợ đa ngôn ngữ vào ứng dụng của bạn là thực hiện theo cách không làm tăng đáng kể chi phí phát triển hoặc bảo trì. Vì mô hình hóa cơ sở dữ liệu là một phần không thể tách rời của quá trình phát triển phần mềm, bạn cần phải suy nghĩ về chiến lược thiết kế mô hình dữ liệu tốt nhất để cung cấp cho ứng dụng của bạn hỗ trợ đa ngôn ngữ.
Một mô hình dữ liệu thích hợp sẽ cho phép bạn sửa đổi ứng dụng hoặc thêm chức năng mới trong khi vẫn duy trì hỗ trợ đa ngôn ngữ - mà không cần thêm nỗ lực hoặc chi phí. Nó cũng sẽ cho phép bạn kết hợp các ngôn ngữ mới mà không cần chạm vào ứng dụng; bạn chỉ cần thêm dữ liệu dịch tương ứng vào cơ sở dữ liệu.
Triển khai đơn giản so với Tính linh hoạt và Chức năng
Có nhiều cách tiếp cận khác nhau để tạo một thiết kế cơ sở dữ liệu cho các ứng dụng đa ngôn ngữ. Mỗi loại đều có ưu điểm và nhược điểm. Những công cụ dễ triển khai hơn cung cấp ít tính linh hoạt hơn và ít chức năng hơn; những thứ cung cấp tính linh hoạt hơn và chức năng có cách triển khai phức tạp hơn.
Lời khuyên của tôi ở đây là luôn chọn những cái cung cấp nhiều chức năng và linh hoạt hơn , ngay cả khi chúng đắt hơn để thực hiện. Đôi khi chúng ta mắc sai lầm khi nghĩ rằng một ứng dụng quá nhỏ, rằng nó không có giá trị thực hiện các lược đồ phức tạp để giải quyết những việc như hỗ trợ đa ngôn ngữ. Nhưng cuối cùng, ứng dụng đó sẽ phát triển và chúng tôi sẽ rất tiếc khi chọn cách tiếp cận "nhanh chóng và tiện lợi" có vẻ đơn giản hơn và ít tốn kém hơn.
Lý tưởng để triển khai chức năng phụ kiện cho một ứng dụng - có thể là hỗ trợ đa ngôn ngữ, ghi nhật ký thay đổi, xác thực người dùng hoặc một cái gì đó khác - là để chức năng đó có địa chỉ con riêng và logic của nó được gói gọn trong các thành phần có thể tái sử dụng. Bằng cách này, cả chức năng phụ kiện và tiểu vùng phụ của nó có thể được kết hợp vào bất kỳ ứng dụng mới nào với nỗ lực tối thiểu.
Một công cụ tạo mô hình dữ liệu và thiết kế cơ sở dữ liệu thông minh như Vertabelo là một trợ giúp đắc lực cho việc quản lý hiệu quả các lược đồ và biểu đồ con của bạn. Ngoài ra, hãy xem các mẹo này để thiết kế cơ sở dữ liệu tốt hơn và đảm bảo rằng bạn làm theo tất cả chúng. Trước khi bạn bắt đầu vẽ sơ đồ ER của mình, tôi khuyên bạn nên xem xét loạt mẹo thiết yếu về mô hình cơ sở dữ liệu này.
Một số giải pháp thiết kế cơ sở dữ liệu đa ngôn ngữ hấp dẫn (nhưng không thể dự đoán được)
Dễ nhất - Nhưng Ít được Đề xuất nhất
Hãy bắt đầu với cách ít được đề xuất nhất nhưng dễ nhất để triển khai cơ sở dữ liệu ứng dụng đa ngôn ngữ. Nó cho phép bạn nhanh chóng giải quyết nhu cầu hỗ trợ một ứng dụng đa ngôn ngữ, nhưng nó sẽ mang lại cho bạn những vấn đề khi ứng dụng phát triển về chức năng hoặc phạm vi địa lý.
Chiến lược đơn giản này bao gồm việc thêm một cột bổ sung cho mỗi cột văn bản cần dịch và cho mỗi ngôn ngữ mà văn bản phải được dịch.
Ví dụ:trong Movies bảng bên dưới, có một OriginalTitle đồng ruộng. Một cột tiêu đề bổ sung được thêm vào cho mỗi ngôn ngữ sẽ được dịch:
| MovieId | OriginalTitle | Title_sp | Title_it | Title_fr |
|---|---|---|---|---|
| 1 | Chết cứng | Duro de matar | Trappola di cristallo | Piege de cristal |
| 2 | Quay lại tương lai | Volver al futuro | Ritorno al futuro | Retour so le futur |
| 3 | Công viên kỷ Jura | Parque jurásico | Giurassico parco | Parc jurassique |
Ứng dụng phải lấy dữ liệu mô tả từ cột tương ứng với ngôn ngữ mà người dùng đã chọn. Khi bạn cần thêm một ngôn ngữ mới, bạn phải thêm một cột bổ sung vào bảng để chứa các văn bản được dịch sang ngôn ngữ mới. Bạn cũng phải điều chỉnh ứng dụng để xác nhận ngôn ngữ và cột được thêm vào.
Giải pháp này không yêu cầu các JOIN phức tạp để lấy các văn bản đã dịch, cũng như không yêu cầu các bản ghi trùng lặp - chỉ sao chép các cột nội dung văn bản. Nhưng khả năng ứng dụng của nó bị giới hạn trong những trường hợp chỉ cần dịch một số bảng.
Ví dụ:giả sử bạn có Products bảng và một Processes bàn. Mỗi người trong số họ có một trường Mô tả cần dịch; có vẻ dễ dàng, phải không? Nhưng nếu toàn bộ ứng dụng (bao gồm tất cả các tùy chọn menu, thông báo lỗi, v.v.) của nó cần phải đa ngôn ngữ, thì giải pháp này không thể áp dụng được.
Đa năng hơn, nhưng cũng không thể áp dụng
Tiếp tục với ý tưởng giữ các bản dịch trong cùng một bảng, một giải pháp thay thế cho tùy chọn trước đó là phóng to các trường văn bản. Điều này sẽ cho phép chúng tôi lưu trữ tất cả các bản dịch trong cùng một trường, sắp xếp chúng trong một cấu trúc dữ liệu (ví dụ:một tài liệu XML hoặc một đối tượng JSON). Dưới đây chúng tôi có một ví dụ:
| MovieId | OriginalTitle | Bản dịch |
| 1 | Chết cứng | [ {"language":"sp", "title":"Duro de matar"}, {"language":"it", "title":"Trappola di cristallo"}, {"language":"fr", "title":"Piège de cristal"} ] |
| 2 | Quay lại Tương lai | [ {"language":"sp", "title":"Volver al futuro"}, {"language":"it", "title":"Ritorno al futuro"}, {"language":"fr", "title":"Retour so le futur"} ] |
| 3 | Công viên kỷ Jura | [ {"language":"sp", "title":"Parque jurásico"}, {"language":"it", "title":"Giurassico parco"}, {"language":"fr", "title":"Parc jurassique"} ] |
Tùy chọn này không yêu cầu cột bổ sung, nhưng tăng thêm độ phức tạp. Các truy vấn dữ liệu bây giờ phải có khả năng xử lý và diễn giải chính xác cấu trúc dữ liệu được sử dụng để hỗ trợ đa ngôn ngữ. Ví dụ:nếu JSON hoặc XML được sử dụng để lưu trữ bản dịch, các truy vấn SQL phải sử dụng phiên bản SQL hỗ trợ kiểu dữ liệu đã chọn.
Lệnh SQL sau sử dụng MS SQL Server OPENJSON() chức năng sử dụng nội dung của Translations trường dưới dạng bảng phụ:
SELECT m.MovieId, m.OriginalTitle, t.TranslatedTitle FROM Movies AS m CROSS APPLY OPENJSON(m.Translations) WITH ( language char(2) '$.language', TranslatedTitle varchar(100) '$.title’ ) AS t WHERE t.language = 'fr';
Vì không có hàm hoặc toán tử nào để thao tác dữ liệu định dạng JSON hoặc XML trong SQL chuẩn, bạn buộc phải viết các truy vấn của mình cho một RDBMS cụ thể nếu bạn muốn sử dụng kỹ thuật này để lưu trữ văn bản đã dịch. Ví dụ:truy vấn trước đó không được MySQL hỗ trợ. Nếu bạn cần đọc dữ liệu JSON trong Movies với MySQL, bạn sẽ viết truy vấn sau:
SELECT m.MovieId, m.OriginalTitle, JSON_EXTRACT(m.Translations, '$.title') AS TranslatedTitle FROM Movies AS m WHERE JSON_EXTRACT(m.Translations. '$.language') = 'fr';
Lưu trữ văn bản đã dịch trong các bản ghi khác nhau
Bạn cũng có thể chọn sử dụng các bản ghi khác nhau cho mỗi ngôn ngữ. Tuy nhiên, bạn phải từ bỏ việc mất chuẩn hóa:cùng một dữ liệu được lặp lại trong một số bản ghi, trong đó chỉ có bản dịch khác nhau.
| MovieId | LanguageId | Tiêu đề |
|---|---|---|
| 1 | vi | Chết cứng |
| 1 | sp | Duro de matar |
| 1 | nó | Trappola di cristallo |
| 1 | fr | Piege de cristal |
| 2 | vi | Quay lại tương lai |
| 2 | sp | Volver al futuro |
| 2 | nó | Ritorno al futuro |
Với tùy chọn này, bạn có thể tạo các dạng xem của mỗi bảng chỉ trả về các hàng bằng một ngôn ngữ nhất định:
CREATE VIEW Movies_en AS SELECT MovieId, Title FROM Movies WHERE LanguageId = 'en'; CREATE VIEW Movies_sp as SELECT MovieId, Title FROM Movies WHERE LanguageId = 'sp';
Sau đó, để truy vấn bảng, bạn có thể sử dụng một dạng xem khác tùy theo ngôn ngữ dịch đích. Nhưng việc chuẩn hóa mô hình bị mất và việc bảo trì bảng phức tạp không cần thiết.
Lưu trữ văn bản đã dịch trong các bảng riêng biệt
Một cách để lưu trữ các văn bản đã dịch mà không phá vỡ mô hình quan hệ là có một bảng chi tiết cho mỗi bảng chứa các văn bản được dịch. Bảng phụ chứa các bản dịch phải có các trường khóa giống như bảng mẹ, cộng với một trường chỉ ra ngôn ngữ dịch.
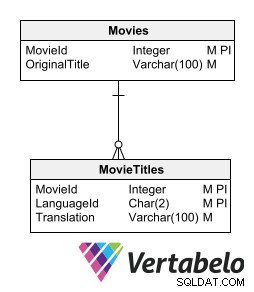
Bảng phụ có bản dịch phải có các trường khóa giống như bảng mẹ, cộng với trường chỉ ra ngôn ngữ dịch.
Tùy chọn này cho phép kết hợp các ngôn ngữ mới mà không làm thay đổi cấu trúc bảng. Nó không yêu cầu tạo thông tin dư thừa hoặc phá vỡ quá trình chuẩn hóa mô hình.
Hạn chế của tùy chọn này là nó yêu cầu tạo một bảng cấp dưới cho mỗi bảng lưu trữ dữ liệu văn bản yêu cầu dịch. Tuy nhiên, ý tưởng lưu trữ bản dịch trong các bảng liên quan đưa chúng ta đến gần hơn với cách thiết kế cơ sở dữ liệu đa ngôn ngữ được khuyến khích nhất.
Giải pháp Toàn cầu:Một tiểu địa chỉ bản dịch
Để một ứng dụng và cơ sở dữ liệu của nó thực sự đa ngôn ngữ, tất cả các văn bản phải có bản dịch ở mỗi ngôn ngữ được hỗ trợ - không chỉ dữ liệu văn bản trong một bảng cụ thể. Điều này đạt được với một danh mục dịch thuật nơi lưu trữ tất cả dữ liệu có nội dung dạng văn bản mà người dùng có thể nhìn thấy.
Trong các ứng dụng web được thiết kế để sử dụng trong các ngôn ngữ khác nhau, một địa chỉ con dịch thuật là một điều cần thiết, không phải là một tùy chọn. Bất kỳ điều gì khác sẽ dẫn đến sự phức tạp khiến việc bảo trì ứng dụng đúng cách là không thể.
Chìa khóa của việc giữ các bản dịch trong một lược đồ riêng biệt là duy trì một danh mục được lập chỉ mục với tất cả các văn bản cần dịch, cho dù chúng là mô tả thực thể, thông báo lỗi hoặc tùy chọn menu. Ý tưởng là không có văn bản nào có thể đến mắt người dùng được lưu trữ trong bất kỳ bảng nào bên ngoài địa chỉ con này.
Một cách để tổ chức danh mục bản dịch là sử dụng ba bảng:
- Một bảng chính về các ngôn ngữ.
- Một bảng văn bản bằng ngôn ngữ gốc.
- Một bảng các văn bản đã dịch.
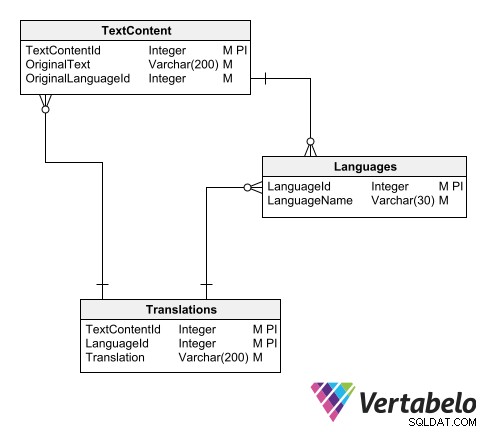
Lược đồ cho một danh mục bản dịch phổ quát.
Trong bảng ngôn ngữ chính, chúng tôi chỉ cần chèn một bản ghi cho từng ngôn ngữ được mô hình dữ liệu hỗ trợ. Mỗi người có một mã ID và tên:
| LanguageId | LanguageName |
|---|---|
| vi | Tiếng Anh |
| sp | Tiếng Tây Ban Nha |
| nó | Ý |
| fr | Tiếng Pháp |
Bảng văn bản ghi lại tất cả các văn bản yêu cầu dịch. Mỗi bản ghi có một ID tùy ý, văn bản gốc và ID của ngôn ngữ gốc.
Trong TextContent bảng, văn bản gốc và ID của ngôn ngữ gốc không hoàn toàn cần thiết. Nhưng chúng đơn giản hóa các truy vấn không yêu cầu dịch. Ví dụ:khi thực hiện phân tích thống kê hoặc truy vấn kiểm soát quản lý (thường chỉ có sẵn cho người dùng hiểu ngôn ngữ gốc), các truy vấn có thể được đơn giản hóa bằng cách sử dụng văn bản mặc định (không được dịch).
Các văn bản gốc cũng hữu ích cho những người phải điền vào bảng các văn bản đã dịch. Việc nhập dữ liệu dịch có thể được thực hiện bằng một ứng dụng nhỏ hiển thị văn bản gốc và các bản dịch bằng tất cả các ngôn ngữ có sẵn. Cũng có thể tạo thông tin cho địa chỉ con bản dịch thông qua một quy trình tự động bằng cách sử dụng API dịch.
Liên kết với Lược đồ chính
Trong lược đồ chính của ứng dụng, các cột có giá trị văn bản cần dịch được thay thế bằng ID trỏ đến bảng văn bản đã dịch:
Lược đồ chính được liên kết với lược đồ dịch thông qua các bảng có văn bản cần dịch.
Bạn có thể để trường văn bản gốc trong một số bảng lược đồ chính để tạo điều kiện thuận lợi cho các truy vấn không cần dịch, ngay cả khi điều này tạo ra thông tin dư thừa. Ví dụ:chúng tôi có thể giữ ProductDescription trong trường Products bảng để tạo điều kiện thuận lợi cho các truy vấn thống kê hoặc để điền vào các kích thước của kho dữ liệu, bỏ qua một bên trong danh mục dịch thuật khi không cần thiết.
- Thiết kế cơ sở dữ liệu đa ngôn ngữ:Làm một lần và làm ngay
Chúng tôi đã thấy một số lựa chọn thay thế để tạo thiết kế cơ sở dữ liệu đa ngôn ngữ. Một số dễ dàng hơn và nhanh hơn để thực hiện. Giải pháp cuối cùng phức tạp hơn một chút, nhưng nó mang lại cho bạn sự linh hoạt hơn nhiều. Nó cũng sẽ giúp bạn đỡ rắc rối khi đến lúc phải bảo trì ứng dụng và cơ sở dữ liệu. Như vậy về lâu dài sẽ đỡ tốn kém hơn nhiều.
Đôi khi, con đường ngắn nhất trong thiết kế cơ sở dữ liệu khiến bạn tin rằng bạn sẽ tiết kiệm được thời gian và công sức. Nhưng khi bạn chọn nó, bạn đang bỏ qua một thực tế rằng bạn có thể sẽ phải gỡ xuống nó nhiều lần. Nếu bạn bỏ qua các phương pháp hay nhất để thiết kế cơ sở dữ liệu đa ngôn ngữ, bạn có thể sẽ phải làm đi làm lại cùng một công việc.